







题目:The Modality Focusing Hypothesis: Towards Understanding Crossmodal Knowledge Distillation
论文链接:https://arxiv.org/abs/2206.06487
代码链接:https://github.com/zihuixue/MFH/tree/main/gauss
时间:2023
目录
3.跨模态知识蒸馏的效果
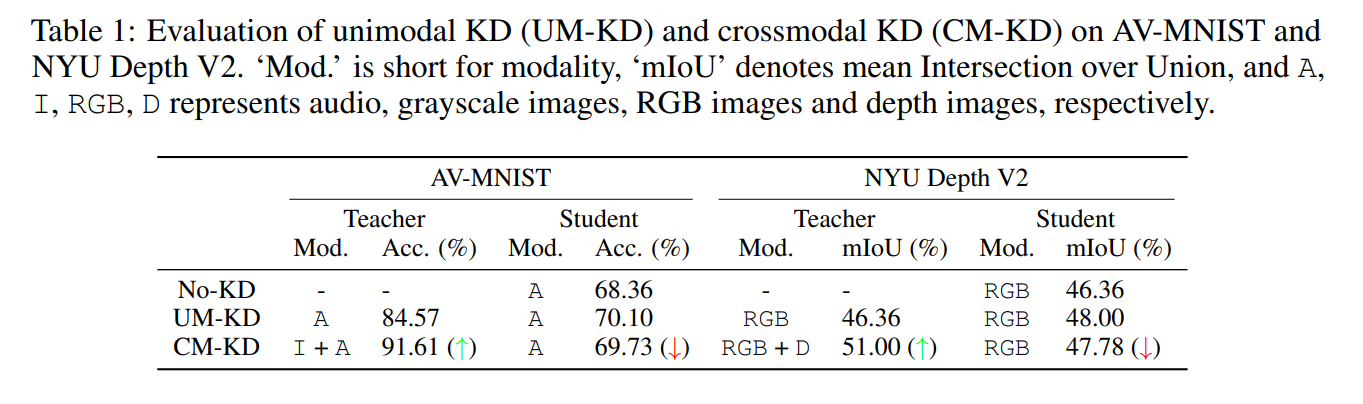
上表可以发现,从单模态教师网络到跨模态教师网络,分别对学生模型进行知识蒸馏的效果不增反降。
所以要思考决定跨模态知识蒸馏效果的核心是什么。
4.方法
4.1模态韦恩图
多模态数据生成的正式描述
接下来,提出了一个正式的多模态数据生成(MVD)描述,用以捕捉多模态数据的生成动态。
设 X a X_a Xa、 X b X_b Xb 和 Y Y Y 分别为模态 a a a、模态 b b b 和标签空间的特征空间,并且 ( x a , x b , y ) (x_a, x_b, y) (xa,xb,y) 是从未知分布 P P P 上采样得到的数据对,其中 P P P 定义在空间 X a × X b × Y X_a \times X_b \times Y Xa×Xb×Y 上。
MVD 假设
MVD 假设 ( x a , x b , y ) (x_a, x_b, y) (xa,xb,y) 是由四元组 ( z s a , z s b , z 0 , y ) ∈ Z s a × Z s b × Z 0 × Y (z_{sa}, z_{sb}, z_0, y) \in Z_{sa} \times Z_{sb} \times Z_0 \times Y (zsa,zsb,z0,y)∈Zsa×Zsb×Z0×Y 生成的,生成规则如下:
MVD 生成规则:
x
a
=
g
a
(
z
a
)
,
z
a
=
[
z
s
a
,
z
0
]
T
∈
Z
a
=
Z
s
a
×
Z
0
x_a = g_a(z_a), \quad z_a = [z_{sa}, z_0]^T \in Z_a = Z_{sa} \times Z_0
xa=ga(za),za=[zsa,z0]T∈Za=Zsa×Z0
x
b
=
g
b
(
z
b
)
,
z
b
=
[
z
s
b
,
z
0
]
T
∈
Z
b
=
Z
s
b
×
Z
0
x_b = g_b(z_b), \quad z_b = [z_{sb}, z_0]^T \in Z_b = Z_{sb} \times Z_0
xb=gb(zb),zb=[zsb,z0]T∈Zb=Zsb×Z0
其中, g u ( ⋅ ) : Z u → X u g_u(·) : Z_u \rightarrow X_u gu(⋅):Zu→Xu 表示一个未知的生成函数, u ∈ { a , b } u \in \{a, b\} u∈{a,b}。
为了完成 MVD,必须加入一个线性决策规则。
MVD 决策规则:
假设对于任意的 ( z s a , z s b , z 0 , y ) (z_{sa}, z_{sb}, z_0, y) (zsa,zsb,z0,y),以下公式成立:
∃ W u , arg max [ Softmax ( W u z u ) ] = arg max [ W u z u ] = y \exists W_u, \quad \arg \max [\text{Softmax}(W_u z_u)] = \arg \max [W_u z_u] = y ∃Wu,argmax[Softmax(Wuzu)]=argmax[Wuzu]=y
其中,用 arg max [ ⋅ ] \arg \max[\cdot] argmax[⋅],表示在参数中的最大元素的索引。实质上,MVD 指定了 x u x_u xu 是基于模态特定的决策特征向量 z s u z_{su} zsu 和模态通用的决策特征向量 z 0 z_0 z0 生成的(生成规则),并且 z u z_u zu 足以通过线性方法决定标签 y y y(决策规则)。
定量描述模态特征
接下来,量化模态通用决策特征和模态特定决策特征之间的相关性。设 Z s u ⊂ R d s u Z_{su} \subset \mathbb{R}^{d_{su}} Zsu⊂Rdsu 和 Z 0 ⊂ R d 0 Z_0 \subset \mathbb{R}^{d_0} Z0⊂Rd0,所以 Z u ⊂ R d u Z_u \subset \mathbb{R}^{d_u} Zu⊂Rdu,其中 d u = d s u + d 0 d_u = d_{su} + d_0 du=dsu+d0。
引入一个比率 γ = d 0 d 0 + d s a + d s b ∈ [ 0 , 1 ] \gamma = \frac{d_0}{d_0 + d_{sa} + d_{sb}} \in [0, 1] γ=d0+dsa+dsbd0∈[0,1],它描述了模态通用决策特征在所有决策特征中的比率。同样, α = d s a d 0 + d s a + d s b \alpha = \frac{d_{sa}}{d_0 + d_{sa} + d_{sb}} α=d0+dsa+dsbdsa 和 β = d s b d 0 + d s a + d s b \beta = \frac{d_{sb}}{d_0 + d_{sa} + d_{sb}} β=d0+dsa+dsbdsb 分别表示模态 a a a 和模态 b b b 在所有决策特征中的模态特定决策特征的比例,并且满足 α + β + γ = 1 \alpha + \beta + \gamma = 1 α+β+γ=1。
4.2MFH假设

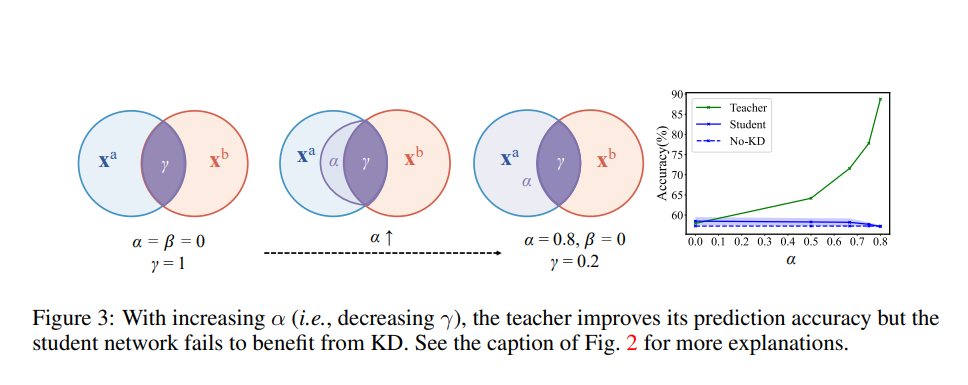
理论基础
定理 1:(线性二分类中的跨模态知识蒸馏)
在不失一般性的前提下,假设:
- 教师模型 f θ t ( ⋅ ) : X a → Y f_{\theta_t}(·) : X_a \rightarrow Y fθt(⋅):Xa→Y 和学生模型 f θ s ( ⋅ ) : X b → Y f_{\theta_s}(·) : X_b \rightarrow Y fθs(⋅):Xb→Y。
- 假设对于 u = a u = a u=a 或 u = b u = b u=b,满足: max { ∣ ∣ Z u Z u , T ∣ ∣ , ∣ ∣ ( Z u Z u , T ) − 1 ∣ ∣ } ≤ λ \max\{ ||Z_u Z_{u,T} ||, ||(Z_u Z_{u,T})^{-1} || \} \leq \lambda max{∣∣ZuZu,T∣∣,∣∣(ZuZu,T)−1∣∣}≤λ 始终成立,且 g u ( ⋅ ) g_u(·) gu(⋅) 是恒等函数。
如果存在 ( ϵ , δ ) (\epsilon, \delta) (ϵ,δ) 使得以下条件成立:
P r ( ∣ ∣ Z a , T Z a − Z b , T Z b ∣ ∣ ≤ ( 1 − γ ) ϵ ) ≥ 1 − δ P_r \left( ||Z_{a,T} Z_a - Z_{b,T} Z_b || \leq (1 - \gamma) \epsilon \right) \geq 1 - \delta Pr(∣∣Za,TZa−Zb,TZb∣∣≤(1−γ)ϵ)≥1−δ
那么,假设在初始化时满足 R dis n ( θ s ( 0 ) ) ≤ q R_{\text{dis}}^n(\theta_s(0)) \leq q Rdisn(θs(0))≤q,则有以下结论(以至少 1 − δ 1 - \delta 1−δ 的概率成立):
R dis n ( θ s ( t = + ∞ ) ) ≤ n ( ϵ ∗ 1 − e − ϵ ∗ − 1 − ln ( ϵ ∗ 1 − e − ϵ ∗ ) ) R_{\text{dis}}^n(\theta_s(t = +\infty)) \leq n \left( \frac{\epsilon^*}{1 - e^{-\epsilon^*}} - 1 - \ln \left( \frac{\epsilon^*}{1 - e^{-\epsilon^*}} \right) \right) Rdisn(θs(t=+∞))≤n(1−e−ϵ∗ϵ∗−1−ln(1−e−ϵ∗ϵ∗))
其中:
ϵ ∗ = λ 1.5 ( λ 2 + 1 ) ( 1 − γ ) ϵ \epsilon^* = \frac{\lambda^{1.5}}{(\lambda^2 + 1)(1 - \gamma)} \epsilon ϵ∗=(λ2+1)(1−γ)λ1.5ϵ
同时, R dis n ( θ s ) R_{\text{dis}}^n(\theta_s) Rdisn(θs) 是使用 KL 散度定义的经验风险,公式如下:
R dis n ( θ s ( t ) ) = ∑ i = 1 n [ − σ ( θ t T x a i ) ⋅ ln σ ( θ s T x b i ) − ( 1 − σ ( θ t T x a i ) ) ⋅ ln ( 1 − σ ( θ s T x b i ) ) ] R_{\text{dis}}^n(\theta_s(t)) = \sum_{i=1}^{n} \left[ -\sigma(\theta_t^T x_{a_i}) \cdot \ln \sigma(\theta_s^T x_{b_i}) - (1 - \sigma(\theta_t^T x_{a_i})) \cdot \ln (1 - \sigma(\theta_s^T x_{b_i})) \right] Rdisn(θs(t))=i=1∑n[−σ(θtTxai)⋅lnσ(θsTxbi)−(1−σ(θtTxai))⋅ln(1−σ(θsTxbi))]
说明
- P r P_r Pr:表示概率。
- R dis n ( θ s ) R_{\text{dis}}^n(\theta_s) Rdisn(θs):表示使用 KL 散度定义的经验风险。
- σ \sigma σ:是 Sigmoid 激活函数。
- λ \lambda λ:协方差矩阵上界
- λ 2 \lambda_2 λ2:正则项相关参数
- γ \gamma γ:通用特征占比因子
- ε \varepsilon ε:初始蒸馏误差
- n n n:训练样本数量
- δ \delta δ:控制不确定性的容忍度
多模态蒸馏中的经验风险上界解释
在多模态知识蒸馏中,希望学生模型能够从教师模型中学习跨模态知识。在理论分析中,关心学生模型在训练结束后,其经验风险是否有可控的收敛界限。本文将详细解释如下结论:
最终结论(以至少 1 − δ 1-\delta 1−δ 的概率成立)
若初始条件满足:
R n d i s ( θ s ( 0 ) ) ≤ q R_n^{dis}(\theta_s(0)) \leq q Rndis(θs(0))≤q
则有如下上界:
R n d i s ( θ s ( t = + ∞ ) ) ≤ n ( 1 − e − ε ∗ ε ∗ − 1 + ln ( 1 1 − e − ε ∗ ) ) R_n^{dis}(\theta_s(t = +\infty)) \leq n \left( \frac{1 - e^{-\varepsilon^*}}{\varepsilon^*} - 1 + \ln\left( \frac{1}{1 - e^{-\varepsilon^*}} \right) \right) Rndis(θs(t=+∞))≤n(ε∗1−e−ε∗−1+ln(1−e−ε∗1))
其中:
ε
∗
=
λ
1.5
(
1
−
γ
)
ε
λ
2
+
1
\varepsilon^* = \frac{\lambda^{1.5}(1 - \gamma)\varepsilon}{\lambda_2 + 1}
ε∗=λ2+1λ1.5(1−γ)ε
结论
这个结论说明:即使一开始学生模型与教师模型之间有一定的偏差,只要蒸馏误差 ε \varepsilon ε 控制得当,且超参数选择合理,最终学生模型的经验风险会以高概率收敛到一个可控的上界。这为多模态蒸馏的理论可靠性提供了保证。
4.3启发
提出了 MVD 和 MFH。在这一节中,结合交叉模态知识蒸馏(crossmodal KD)这一新视角,讨论了它们的启示和实际应用。对于交叉模态知识蒸馏,考虑两个具有相同架构和相似性能的教师模型:教师(a)主要依靠模态通用决策特征进行预测,而教师(b)则更多依赖模态特定的决策特征。预计,由教师(a)指导的学生将表现出比由教师(b)指导的学生更好的性能。
上述启示为验证 MFH 提供了思路。它也为改进交叉模态知识蒸馏提供了方向——可以训练一个更多依赖于模态通用决策特征的教师网络。与常规训练的教师相比,这个新教师更具模态通用性(即具有更大的 γ),因此更适合进行交叉模态知识转移。
注意事项:
-
教师的相同架构和性能:这里指出两个教师具有相同的架构和相似的性能,以便进行公平比较。两个教师的相似性能意味着它们在提取决策特征进行预测的能力上相似,因此唯一的区别在于模态通用决策特征的数量。这个设计排除了其他因素,有助于证明性能差异来源于 γ。
-
本研究的重点:本文的主要目的是提出 MFH 并通过理论分析、合成实验和真实世界多模态数据实验验证它。与常见的看法相反,剥离了教师性能在交叉模态知识蒸馏中的影响,并指出模态通用决策特征才是关键。开发从真实世界多模态数据中分离模态通用/特定决策特征的方法超出了本文的范围,留作未来的研究工作。
5.实验
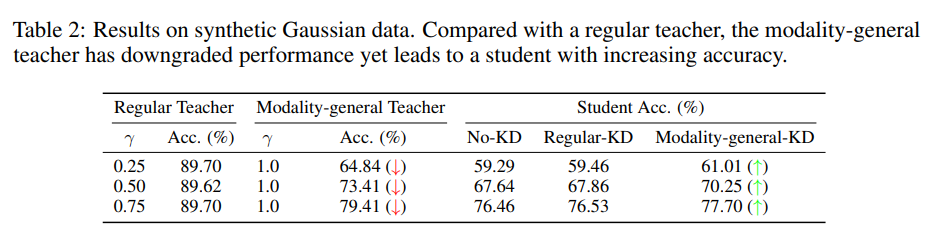
该表展示了在合成高斯数据上的实验结果,比较了常规教师和模态通用教师对学生准确率的影响。尽管模态通用教师的性能较差,但它仍能通过交叉模态知识蒸馏提高学生的准确率,验证了 MFH 的理论,强调模态通用决策特征的重要性。
6.结论
在这项工作中,对交叉模态知识蒸馏(crossmodal KD)进行了深入的研究。提出的MVD和MFH描述了多模态数据之间的关系,并揭示了模态通用决策特征在交叉模态知识蒸馏中的关键作用。提供了理论分析并进行了多种实验来验证MFH。希望MFH能够为交叉模态知识蒸馏的应用提供启示,并引发人们对多模态学习的更广泛理解。未来的工作包括:
(i) 推导交叉模态知识蒸馏的更深层次理论分析;
(ii) 区分实际数据中的模态通用/特定决策特征;
(iii) 基于MVD提高多模态融合的鲁棒性。

















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









