






DisCoM-KD: Cross-Modal KnowledgeDistillation via DisentanglementRepresentation and Adversarial Lea**
摘要
引入了一个新的跨模态知识蒸馏框架,名为 DisCoM-KD (Disentanglement-learning based Cross-modal Knowledge Distillation),它明确地模拟了不同类型的每模态信息,目的是将知识从多模态数据转移到单模态分类器。
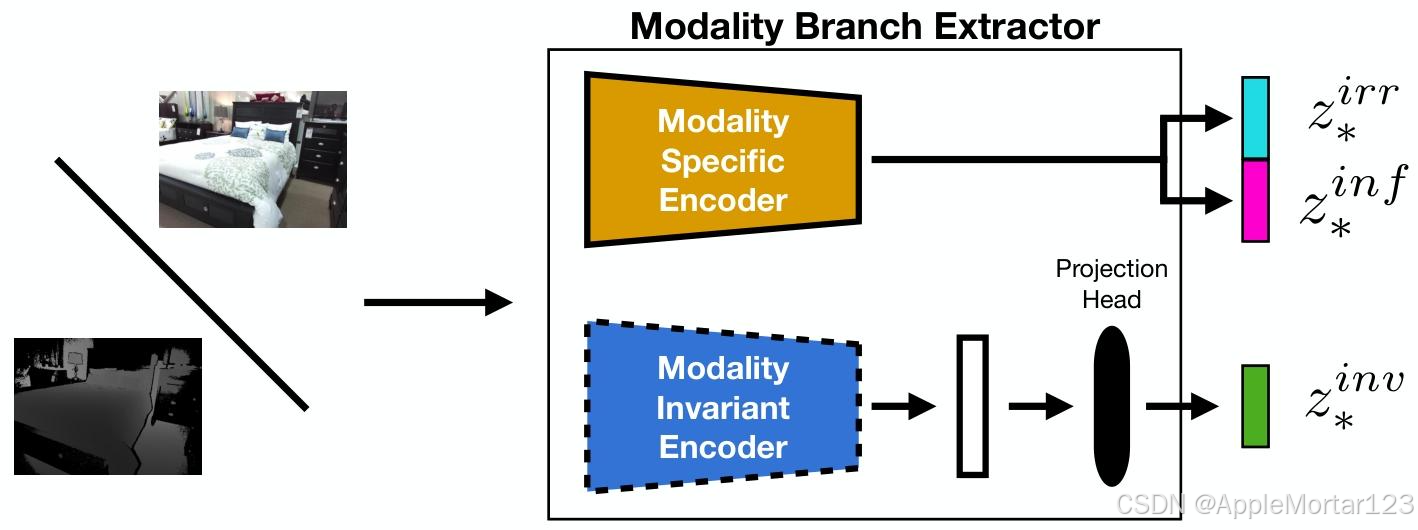
整体架构流程

技术细节
目标函数:
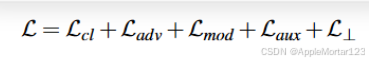
1.分类损失函数:
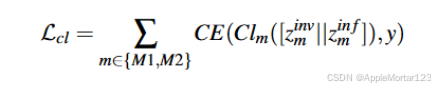
2.让分类器区分来自不同模态的样本表示:
该损失用于学习模态不变的嵌入,通过对抗训练策略(Gradient Reversal Layer, GRL)来混淆模态信息,使模态不变嵌入不能被轻易区分模态类别。
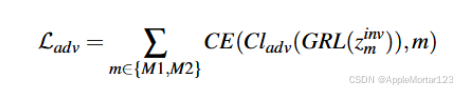

3.预测嵌入来自哪个分支:
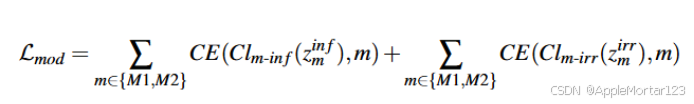


4.增强 permodality 嵌入所携带的任务判别信息:
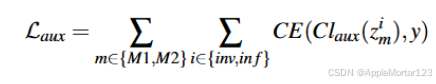
5.嵌入之间强制执行正交性:
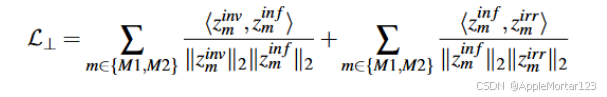
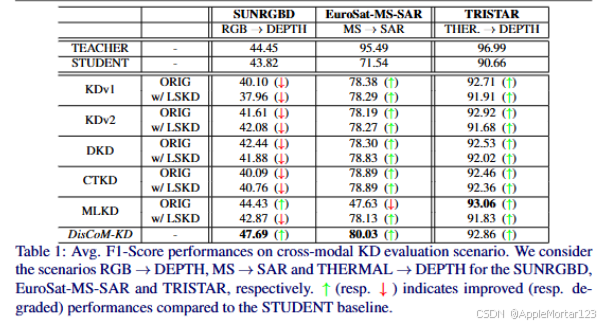
实验结果

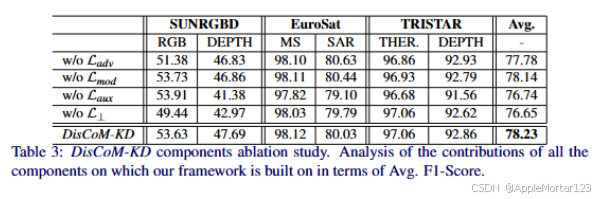
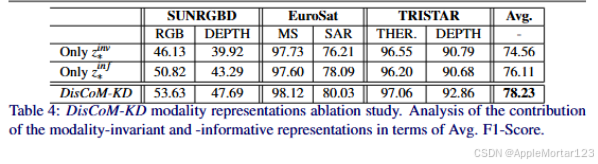
代码
https://github.com/tanodino/CMKD_Disentangle/blob/master/model_pytorch.py
Segment Any Events via Weighted Adaptation of Pivotal Tokens
摘要
Segment Any Events(SAE)是一个用于 事件检测和分割 的模型





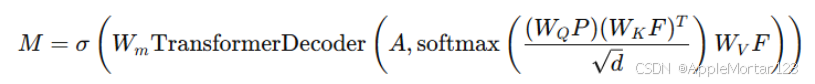
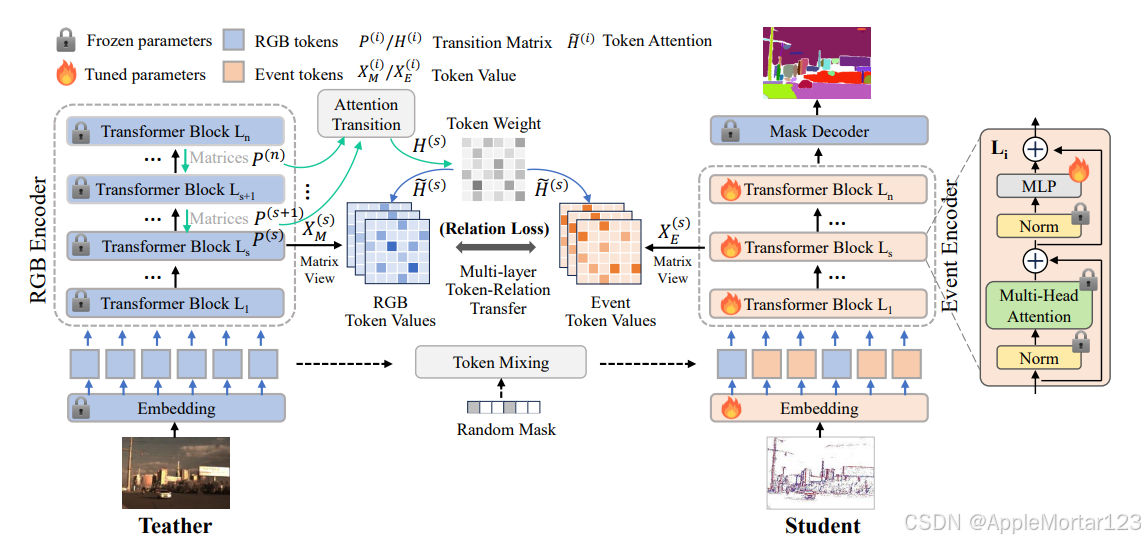
整体架构流程
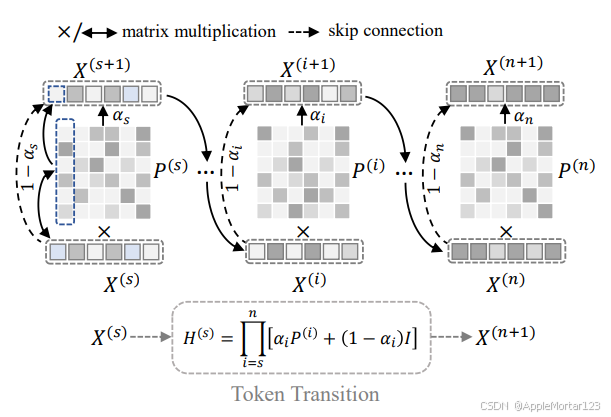
目标函数:
标量 α i表示归一化层和 MLP 的缩放影响。这导致来自注意力机制和残差连接的信息比率发生变化。由于正确估计所有 α i相当耗时,甚至难以理解,我们建议通过假设多层自注意力机制的嵌入过渡过程实际上是一个具有平稳分布的马尔可夫链来简化它。
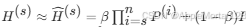
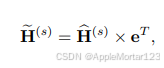
我们正则化了四层嵌入,其相应深度为
Si = {0, 3, 6, 9, 12}


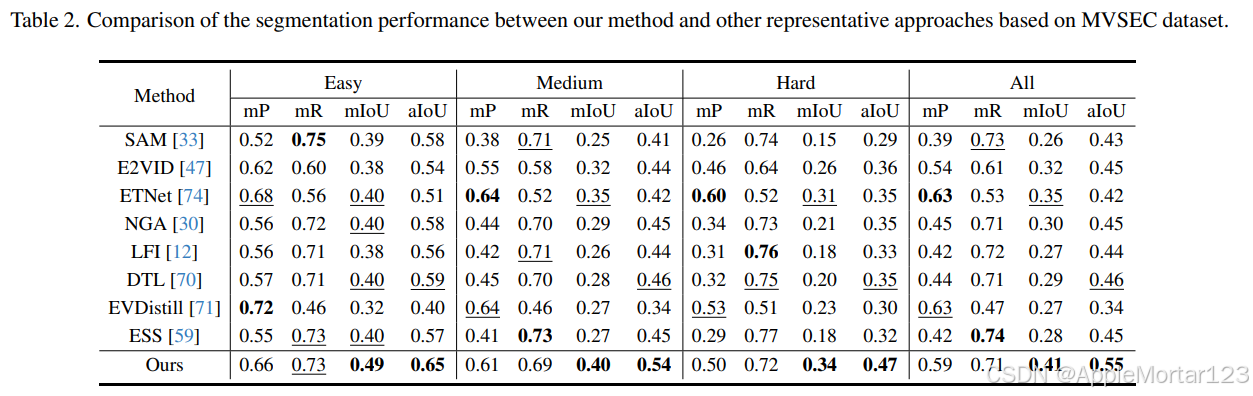
实验结果

(h)为此蒸馏方法得到的分割图像
附录


















 129
129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









