






https://pan.baidu.com/s/1uBtEI_cWiu9Cble35pRJUQ?pwd=1234
引言及灵感
在我发表这篇文章之前,我看到了一则新闻,三名乘客驾驶小米SU7在高速上开启了智能驾驶,之后从小米发布的检测结果来看,驾驶员似乎是因为开启了智能驾驶后就进入到疲劳驾驶状态,在高速上分心从而酿成了此次事故。观看这个新闻之后我调查了中国近10年因疲劳驾驶引发的交通事故发生率及相关数据:
疲劳驾驶是高速公路交通事故的主要成因之一,占事故总数的约20%,在高速公路上的比例更高,占伤亡事故的40%以上。全国范围内,每年因疲劳驾驶直接引发的交通事故超过10万起,造成约9万人死亡或重伤,其中货车事故占比高达54%。公安部统计显示,连续驾驶超过4小时的疲劳驾驶行为,是重特大交通事故的主要诱因,占此类事故的40%。
在高速公路上,疲劳驾驶4秒即可导致致命事故。2019-2023年韩国全罗北道类似统计显示,疲劳驾驶事故死亡率是酒驾的两倍(每100起事故死亡2.9人 vs 1.5人)。职业司机(如货车、网约车司机)是高风险群体。例如,重庆渝北一名网约车司机连续工作19小时后因疲劳驾驶撞车,承担全责。货车司机因经济压力大、睡眠不足,疲劳驾驶事故率显著高于普通车辆。
看来有一个疲劳驾驶警告系统至关重要,于是我决定开发一个可以放在车上,用摄像头检测的警告系统
YOLOv11,mediapipe,多线程运行方法等介绍
YOLO(You Only Look Once):是一种流行的目标检测算法,利用卷积神经网络对目标的动作,状态等进行检测,而YOLOv11是目前YOLO算法中最新版本,相交于之前版本,YOLOv11在检测的精度和速度上都有显著提升。YOLOv11采用了更深的网络结构,更复杂的网络提取模块以及更高效的训练策略,使其在复杂场景下的目标检测任务中表现出色。
YOLOv11网络结构图: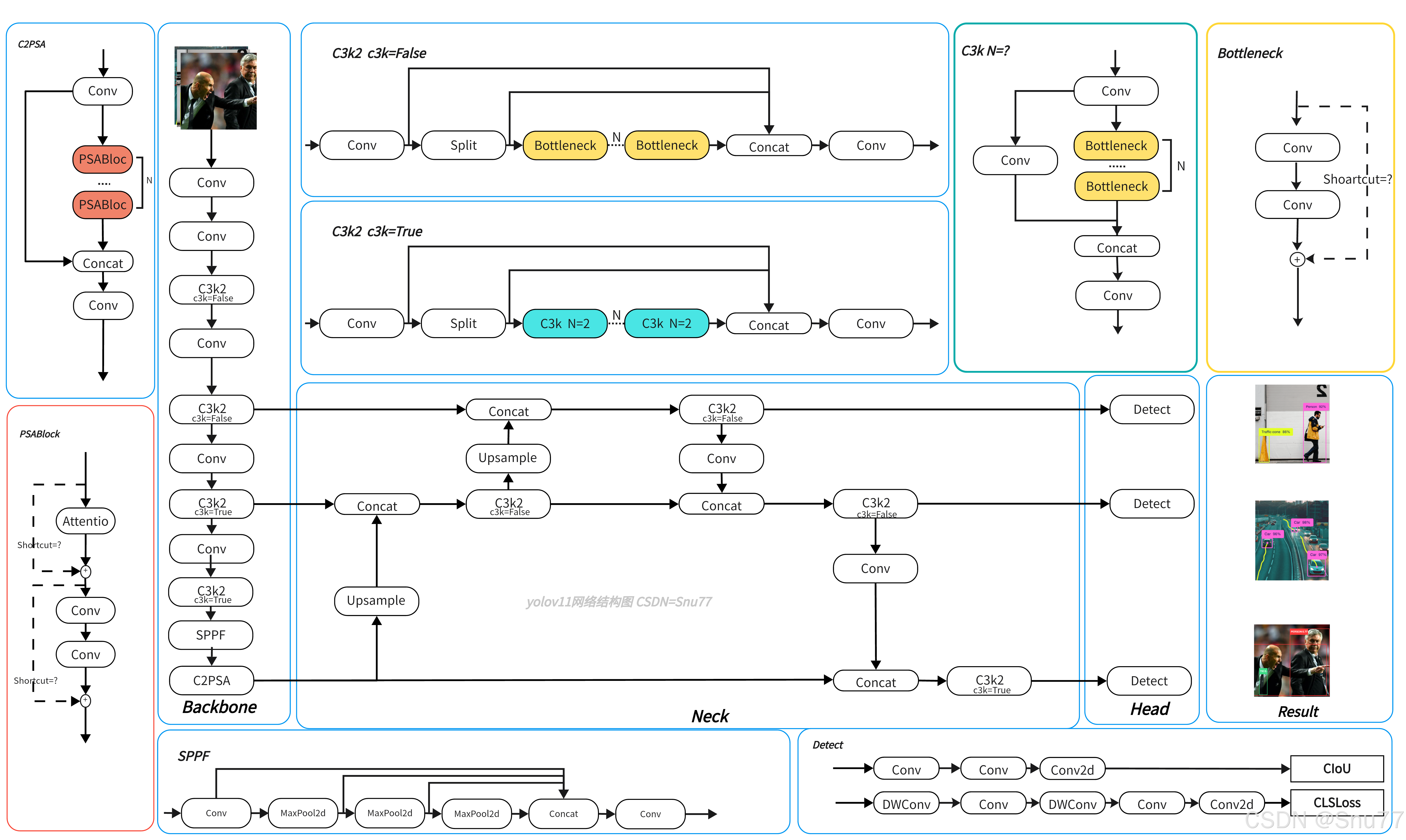
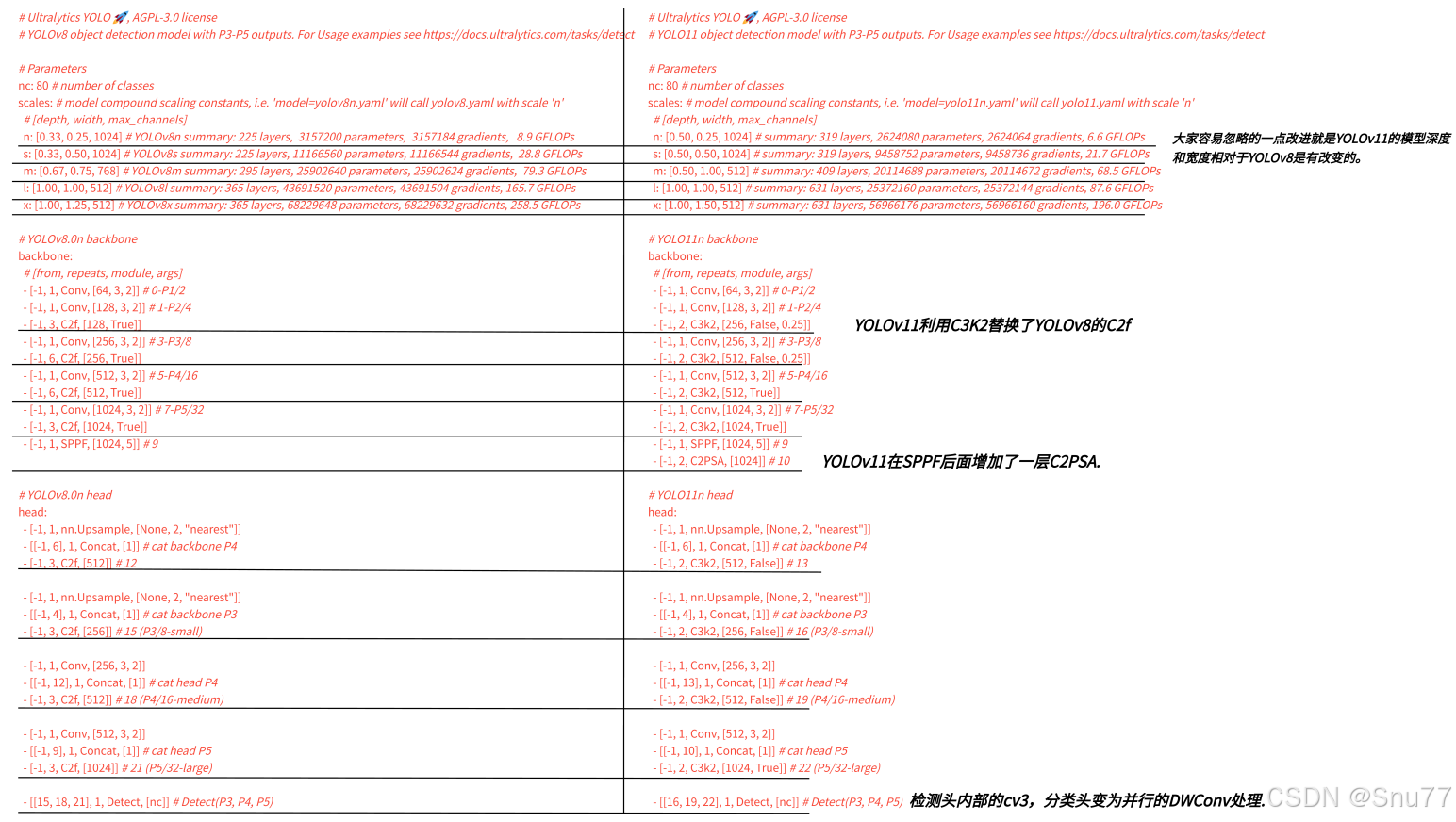
YOLOv11和YOLOv8的对比:
mediapipe:
作为一款跨平台框架,MediaPipe 不仅可以被部署在服务器端,更可以在多个移动端 (安卓和苹果 iOS)和嵌入式平台(Google Coral ,树莓派,Nvidia Jetson设备)中作为设备端机器学习推理 (On-device Machine Learning Inference)框架。
一款多媒体机器学习应用的成败除了依赖于模型本身的好坏,还取决于设备资源的有效调配、多个输入流之间的高效同步、跨平台部署上的便捷程度、以及应用搭建的快速与否。
基于这些需求,谷歌开发并开源了 MediaPipe 项目。除了上述的特性,MediaPipe 还支持 TensorFlow 和 TF Lite 的推理引擎(Inference Engine),任何 TensorFlow 和 TF Lite 的模型都可以在 MediaPipe 上使用。同时,在移动端和嵌入式平台,MediaPipe 也支持设备本身的 GPU 加速。

Opencv:
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法,涵盖了广泛的领域,如特征检测、图像处理、物体识别、运动跟踪等。它由一系列的C++库和Python接口组成,支持多种操作系统,包括Windows、Linux、Mac OS等,使其成为了学术界和工业界广泛使用的计算机视觉工具之一。
多线程架构:
⼀个线程就是⼀个 “执行流”. 每个线程之间都可以按照顺序执行自己的代码. 多个线程之间 “同时” 执行着多份代码,main()⼀般被称为主线程(Main Thread)。单核 CPU 的发展遇到了瓶颈. 要想提高算力, 就需要多核 CPU. 而并发编程能更充分利用多核 CPU 资源。
代码介绍(本文所用所有代码以及模型都可在开头链接中获取)
(一)Main.py主要运行代码:
1.导入模块
import sys
import cv2
import queue
from PyQt5.QtWidgets import (...)
from PyQt5.QtCore import (...)
from PyQt5.QtGui import (...)
import simpleaudio as sa
import config
from target_detector import TargetDetector
from concurrent.futures import ThreadPoolExecutor-
sys: 系统相关操作(如退出程序)。
-
cv2 (OpenCV): 处理视频流和图像。
-
queue: 线程安全的队列,用于生产者和消费者模型。
-
PyQt5 相关模块: 构建 GUI 界面。
-
simpleaudio: 播放警报声音。
-
config: 配置文件(阈值参数等)。
-
TargetDetector: 自定义的目标检测类(检测手机、抽烟等行为)。
-
ThreadPoolExecutor: 线程池,用于并行处理视频帧。
2.全局变量初始化
COUNTER = 0 # 眨眼帧计数器
TOTAL = 0 # 眨眼总数
mCOUNTER = 0 # 打哈欠帧计数器
mTOTAL = 0 # 打哈欠总数
Roll = 0 # 疲劳检测循环帧计数
Rolleye = 0 # 循环内闭眼帧数
Rollmouth = 0 # 循环内打哈欠帧数
targetDetector = TargetDetector(model_path="pt/best.engine")-
全局变量用于跨函数/线程共享数据。
-
targetDetector: 加载预训练模型(YOLO 引擎文件)进行目标检测。
3.视频捕获线程(生产者)
class VideoCaptureThread(QThread):
def __init__(self, frame_queue):
super().__init__()
self.frame_queue = frame_queue # 共享队列
self._run_flag = True # 控制线程运行
def run(self):
cap = cv2.VideoCapture(1) # 打开摄像头(设备号1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320) # 降低分辨率
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 240)
while self._run_flag:
ret, frame = cap.read() # 读取一帧
if ret:
if self.frame_queue.qsize() < 10: # 限制队列大小
self.frame_queue.put(frame) # 放入队列
cap.release() # 释放摄像头
def stop(self):
self._run_flag = False # 停止线程
self.wait()-
作用: 从摄像头捕获帧并存入队列。
-
优化: 降低分辨率减少计算量,限制队列大小防止内存溢出。
4.视频处理线程(消费者)
class VideoProcessThread(QThread):
change_pixmap_signal = pyqtSignal(object, object, object, object) # 自定义信号
def __init__(self, frame_queue):
super().__init__()
self.frame_queue = frame_queue
self._run_flag = True
self.executor = ThreadPoolExecutor(max_workers=2) # 线程池
def run(self):
while self._run_flag:
if not self.frame_queue.empty():
frame = self.frame_queue.get() # 从队列取帧
future = self.executor.submit(targetDetector.detect_target, frame) # 异步提交任务
ret, processed_frame = future.result() # 获取结果
lab, eye, mouth = ret
# 发送信号更新UI
self.change_pixmap_signal.emit(processed_frame, lab, eye, mouth)
def stop(self):
self._run_flag = False
self.wait()-
作用: 从队列取出帧,用线程池并行处理(检测目标、计算纵横比)。
-
信号机制: 将处理后的帧和结果通过信号发送到主线程更新UI。
5.主窗口类(VideoPlayerWindow)
5.1初始化
class VideoPlayerWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("疲劳检测系统")
self.setGeometry(100, 100, 800, 600) # 窗口位置和大小
self.initUI() # 初始化界面
self.alert_sound = sa.WaveObject.from_wave_file(config.ALERT_SOUND_FILE) # 加载警报音
self.red_frame_is_active = False # 红色边框状态
self.frame_counter = 0 # 帧计数器(控制更新频率)
# 初始化线程和队列
self.frame_queue = queue.Queue(maxsize=10)
self.video_capture_thread = VideoCaptureThread(self.frame_queue)
self.video_process_thread = VideoProcessThread(self.frame_queue)
self.video_process_thread.change_pixmap_signal.connect(self.update_image) # 连接信号
self.video_capture_thread.start()
self.video_process_thread.start()5.2界面布局(initUI)
def initUI(self):
main_widget = QWidget(self)
self.setCentralWidget(main_widget)
layout = QHBoxLayout(main_widget) # 水平布局
# 视频显示区域
self.video_widget = QWidget()
self.video_widget.setStyleSheet("border: 5px solid transparent;")
video_layout = QVBoxLayout(self.video_widget)
self.video_label = QLabel()
video_layout.addWidget(self.video_label)
layout.addWidget(self.video_widget)
# 右侧状态和日志区域(垂直分割)
splitter = QSplitter(Qt.Vertical)
status_widget, output_widget = self.createStatusAndOutputWidgets()
splitter.addWidget(status_widget)
splitter.addWidget(output_widget)
layout.addWidget(splitter)5.3状态和日志部件(createStatusAndOutputWidgets)
def createStatusAndOutputWidgets(self):
# 状态标签(网格布局)
status_widget = QWidget()
status_layout = QVBoxLayout(status_widget)
self.status_labels = {}
modules = ["手机", "抽烟", "喝水", "状态", "眨眼", "哈欠"]
self.initial_statuses = ["未使用", "未抽烟", "未喝水", "清醒", 0, 0]
grid_layout = QGridLayout()
for i, module in enumerate(modules):
label = QLabel(f"{module}: {self.initial_statuses[i]}")
self.status_labels[module] = label
grid_layout.addWidget(label, i // 2, i % 2) # 2列布局
status_layout.addLayout(grid_layout)
# 日志输出文本框
output_widget = QWidget()
output_layout = QVBoxLayout(output_widget)
self.output_textedit = QTextEdit()
self.output_textedit.setReadOnly(True)
output_layout.addWidget(self.output_textedit)
return status_widget, output_widget5.4更新视频帧(update_image)
def update_image(self, cv_img, labels, eye_ar, mouth_ar):
# 降低更新频率(每5帧更新一次)
self.frame_counter += 1
if self.frame_counter % 5 == 0:
# 转换OpenCV BGR图像为Qt RGB格式
show_image = QImage(
cv_img.data, cv_img.shape[1], cv_img.shape[0],
QImage.Format_RGB888
).rgbSwapped()
self.video_label.setPixmap(QPixmap.fromImage(show_image))
self.updateStatus(labels, eye_ar, mouth_ar) # 更新状态5.5红色边框警告(trigger_red_frame)
def trigger_red_frame(self, show):
if show:
self.video_widget.setStyleSheet("border: 5px solid red;")
self.alert_sound.play() # 播放警报声
# 单次定时器实现闪烁效果
QTimer.singleShot(500, self.hide_red_frame)
else:
self.video_widget.setStyleSheet("")
def hide_red_frame(self):
self.video_widget.setStyleSheet("")
QTimer.singleShot(500, self.show_red_frame)
def show_red_frame(self):
if self.red_frame_is_active:
self.video_widget.setStyleSheet("border: 5px solid red;")
QTimer.singleShot(500, self.hide_red_frame)5.6更新状态和检测逻辑(updateStatus)
def updateStatus(self, labels, eye_ar, mouth_ar):
# 更新分心行为状态
self.status_labels["手机"].setText(f"手机: {'使用中' if 'phone' in labels else '未使用'}")
self.status_labels["抽烟"].setText(f"抽烟: {'抽烟中' if 'smoke' in labels else '未抽烟'}")
self.status_labels["喝水"].setText(f"喝水: {'喝水中' if 'drink' in labels else '未喝水'}")
# 检测到分心行为时触发警报
distraction_detected = 'phone' in labels or 'smoke' in labels or 'drink' in labels
if distraction_detected:
self.red_frame_is_active = True
self.trigger_red_frame(True)
else:
self.red_frame_is_active = False
self.trigger_red_frame(False)
# 更新眨眼和哈欠计数(全局变量)
global COUNTER, TOTAL, mCOUNTER, mTOTAL
if eye_ar < config.EYE_AR_THRESH:
COUNTER += 1
else:
if COUNTER >= config.EYE_AR_CONSEC_FRAMES:
TOTAL += 1
COUNTER = 0
if mouth_ar > config.MAR_THRESH:
mCOUNTER += 1
else:
if mCOUNTER >= config.MOUTH_AR_CONSEC_FRAMES:
mTOTAL += 1
mCOUNTER = 0
self.status_labels["眨眼"].setText(f"眨眼: {TOTAL}")
self.status_labels["哈欠"].setText(f"哈欠: {mTOTAL}")
# 计算疲劳状态(PERCLOS算法)
global Roll, Rolleye, Rollmouth
Roll += 1
if eye_ar < config.EYE_AR_THRESH:
Rolleye += 1
if mouth_ar > config.MAR_THRESH:
Rollmouth += 1
if Roll >= config.FATIGUE_CALCULATION_FRAMES:
perclos = (Rolleye / Roll) + (Rollmouth / Roll) * 0.2 # 加权计算
status = '疲劳' if perclos > config.PERCLOS_THRESHOLD else '清醒'
self.status_labels["状态"].setText(f"状态: {status}")
self.output_textedit.append(f"过去 {Roll} 帧中,Perclos 得分为 {perclos:.3f}")
# 触发疲劳警报
if perclos > config.PERCLOS_THRESHOLD:
self.red_frame_is_active = True
self.trigger_red_frame(True)
else:
self.red_frame_is_active = False
self.trigger_red_frame(False)
# 重置计数器
Roll = Rolleye = Rollmouth = 0
TOTAL = mTOTAL = 0 # 可选:是否重置总数?眨眼检测算法(EYE_AR_THRESH)
-
原理:基于眼睛纵横比(Eye Aspect Ratio, EAR)
-
EAR 公式:
EAR= 2⋅∣∣p 1 −p 4 ∣∣∣∣p 2 −p 6 ∣∣+∣∣p 3 −p 5 ∣∣
(p1…p6p1…p6 为眼部关键点坐标) -
代码逻辑:
-
当
eye_ar < EYE_AR_THRESH时,开始计数连续闭眼帧(COUNTER)。 -
若连续闭眼帧数超过
EYE_AR_CONSEC_FRAMES,判定为一次有效眨眼,TOTAL累加。
-
-
作用:频繁眨眼可能反映疲劳。
-
哈欠检测算法(MAR_THRESH)
-
原理:基于嘴巴纵横比(Mouth Aspect Ratio, MAR)
-
MAR 公式:
MAR= 3⋅∣∣m 1 −m 5 ∣∣∣∣m 2 −m 8 ∣∣+∣∣m 3 −m 7 ∣∣+∣∣m 4 −m 6 ∣∣
(m1…m8m1…m8 为嘴部关键点坐标) -
代码逻辑:
-
当
mouth_ar > MAR_THRESH时,开始计数连续哈欠帧(mCOUNTER)。 -
若连续哈欠帧数超过
MOUTH_AR_CONSEC_FRAMES,判定为一次有效哈欠,mTOTAL累加。
-
-
作用:频繁打哈欠是疲劳的典型表现。
-
PERCLOS疲劳指数算法
-
原理:PERCLOS(Percentage of Eyelid Closure Over Time)是国际公认的疲劳指标,代码中改进为加权公式:
-
加权公式:
Perclos=(RolleyeRoll)+(RollmouthRoll)×0.2Perclos=(RollRolleye)+(RollRollmouth)×0.2-
Rolleye:周期内闭眼总帧数 -
Rollmouth:周期内打哈欠总帧数 -
Roll:检测周期总帧数(FATIGUE_CALCULATION_FRAMES)
-
-
判定逻辑:
若Perclos > PERCLOS_THRESHOLD,判定为疲劳状态。
-
5.7关闭事件处理
def closeEvent(self, event):
# 停止线程并等待结束
self.video_capture_thread.stop()
self.video_process_thread.stop()
event.accept()6.主程序入口
if __name__ == "__main__":
app = QApplication(sys.argv)
window = VideoPlayerWindow()
window.show()
sys.exit(app.exec_())7.关键逻辑总结
-
多线程架构:
-
生产者 (
VideoCaptureThread) 捕获帧到队列。 -
消费者 (
VideoProcessThread) 处理帧并发送信号到主线程。 -
主线程负责UI更新,避免阻塞。
-
-
疲劳检测算法:
-
眨眼检测: 基于眼睛纵横比 (
EYE_AR_THRESH) 和连续帧数。 -
哈欠检测: 基于嘴巴纵横比 (
MAR_THRESH) 和连续帧数。 -
PERCLOS: 结合闭眼和哈欠频率计算疲劳程度。
-
-
分心行为检测:
-
使用YOLO模型检测手机、抽烟、喝水行为。
-
-
UI交互:
-
实时视频显示。
-
状态标签动态更新。
-
红色边框和声音警报。
-
(二)config.py代码(配置文件,定义阀值参数及警报音效文件)
# config.py
# 阈值设置
EYE_AR_THRESH = 0.15 # 眼睛长宽比阈值,低于此值视为闭眼
EYE_AR_CONSEC_FRAMES = 2 # 连续多少帧闭眼才算一次眨眼
MAR_THRESH = 0.65 # 嘴巴长宽比阈值,高于此值视为打哈欠
MOUTH_AR_CONSEC_FRAMES = 3 # 连续多少帧打哈欠才算一次哈欠
# 计算疲劳的参数
FATIGUE_CALCULATION_FRAMES = 150 # 每150帧计算一次疲劳度
PERCLOS_THRESHOLD = 0.15 # 疲劳度阈值
# 模型路径
MODEL_PATH = "pt/633 and 0.98best.engine"
# RTMP URL
RTMP_URL = ""
# 视频帧处理间隔
VIDEO_FRAME_INTERVAL = 30 # 根据需要调整间隔
# 声音文件路径
ALERT_SOUND_FILE = "sound/alert.wav"
# 人脸识别模型路径
RECOGNIZER_MODEL_PATH = "face/trainer/trainer.yml"
# 人脸识别配置
FACE_RECOGNITION_ENABLED = True
# 哈尔级联分类器路径
CASCADE_CLASSIFIER_PATH = "face/haarcascade_frontalface_alt2.xml"
# 识别置信度阈值
RECOGNITION_CONFIDENCE_THRESHOLD = 80
# 图片路径
FACES_IMAGE_PATH = "face/jm"
# 人脸特征点预测器路径
SHAPE_PREDICTOR_PATH = "face/shape_predictor_68_face_landmarks.dat"
(三)target_detector.py代码(自定义的目标检测类 TargetDetector 的实现文件)
1.类初始化
class TargetDetector:
def __init__(self, model_path="pt/best.engine"):
# 定义物体名称(YOLO 模型的类别标签)
self.name = {0: "face", 1: "smoke", 2: "phone", 3: "drink"}
# 加载 YOLO 模型(使用 Ultralytics 库)
self.model = YOLO(model_path, task="detect")
print("YOLO 模型加载完成。")
# 初始化 MediaPipe 面部关键点检测
self.mp_face_mesh = mp.solutions.face_mesh
self.face_mesh = self.mp_face_mesh.FaceMesh(
static_image_mode=False, # 动态视频模式
max_num_faces=1, # 最多检测 1 张人脸
refine_landmarks=True # 使用更精细的关键点
)
print("MediaPipe 面部关键点检测模块加载完成。")
# 定义关键点索引(MediaPipe 的预定义索引)
self.LEFT_EYE_INDICES = [362, 385, 387, 263, 373, 380] # 左眼关键点
self.RIGHT_EYE_INDICES = [33, 160, 158, 133, 153, 144] # 右眼关键点
self.MOUTH_INDICES = [61, 291, 39, 181, 0, 17, 269, 405] # 嘴巴关键点
# 初始化帧队列(多线程缓冲)
self.frame_queue = queue.Queue(maxsize=10) # 限制队列大小
# 表情识别开关(默认关闭)
self.enable_expression_recognition = False
# 线程停止事件标志
self.stop_event = Event()2.核心算法方法
2.1眼睛纵横比计算(EAR)
def _eye_aspect_ratio(self, eye):
# 计算眼睛关键点之间的欧氏距离
A = dist.euclidean(eye[1], eye[5]) # 垂直方向距离 1
B = dist.euclidean(eye[2], eye[4]) # 垂直方向距离 2
C = dist.euclidean(eye[0], eye[3]) # 水平方向距离
ear = (A + B) / (2.0 * C) # EAR 公式
return ear公式:![]()
2.2嘴巴纵横比计算(MAR)
def _mouth_aspect_ratio(self, mouth):
A = dist.euclidean(mouth[2], mouth[6]) # 上下嘴唇垂直距离
B = dist.euclidean(mouth[0], mouth[4]) # 左右嘴角水平距离
mar = A / B # MAR 公式
return mar公式:![]()
3.疲劳检测流程
def _detect_fatigue(self, frame):
# 将 BGR 转换为 RGB(MediaPipe 要求)
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = self.face_mesh.process(frame_rgb) # 获取关键点
eyear = 0.0 # 默认眼睛纵横比
mouthar = 0.0 # 默认嘴巴纵横比
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
# 提取左眼、右眼、嘴巴关键点坐标
left_eye = np.array([(landmark.x * frame.shape[1], landmark.y * frame.shape[0])
for i in self.LEFT_EYE_INDICES])
right_eye = np.array([...]) # 同上
mouth = np.array([...]) # 同上
# 计算眼睛纵横比(取左右眼平均值)
left_ear = self._eye_aspect_ratio(left_eye)
right_ear = self._eye_aspect_ratio(right_eye)
eyear = (left_ear + right_ear) / 2.0
# 计算嘴巴纵横比
mouthar = self._mouth_aspect_ratio(mouth)
# 绘制关键点轮廓
cv2.drawContours(frame, [left_eye.astype("int")], -1, (0,255,0), 1)
cv2.drawContours(frame, [right_eye.astype("int")], -1, (0,255,0), 1)
cv2.drawContours(frame, [mouth.astype("int")], -1, (0,255,0), 1)
return frame, eyear, mouthar4.目标检测主逻辑
def detect_target(self, frame):
ret = [] # 返回结果列表
labellist = [] # 检测到的物体标签
# 使用 YOLO 检测目标(置信度阈值 0.5,GPU 设备)
results = self.model.predict(frame, conf=0.5, device=0)
# 遍历检测结果
for result in results:
if len(result.boxes.xyxy) > 0:
# 提取边界框坐标、置信度、类别
boxes_xyxy = result.boxes.xyxy.tolist()
boxes_cls = result.boxes.cls.tolist()
for i, box_xyxy in enumerate(boxes_xyxy):
class_label_index = int(boxes_cls[i])
modelname = self.name.get(class_label_index, "unknown")
labellist.append(modelname)
# 绘制边界框和标签
left, top, right, bottom = map(int, box_xyxy)
cv2.rectangle(frame, (left, top), (right, bottom), (0,255,0), 1)
cv2.putText(frame, modelname, (left, top-5),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 1)
# 如果检测到人脸,执行疲劳检测
if modelname == "face":
face_roi = frame[top:bottom, left:right]
face_roi, eye, mouth = self._detect_fatigue(face_roi)
frame[top:bottom, left:right] = face_roi # 回写处理后的 ROI
# 计算并显示 FPS
fps = 1 / (time.time() - tstart)
cv2.putText(frame, f"{fps:.2f} fps", (10,20), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 1)
# 返回结果
ret.append(labellist)
ret.append(round(eye, 3)) # 保留 3 位小数
ret.append(round(mouth, 3))
return ret, frame5.多线程管理
def start_capture(self, video_source=0):
# 启动视频捕获线程
def capture_frames():
cap = cv2.VideoCapture(video_source)
while not self.stop_event.is_set():
ret, frame = cap.read()
if ret:
self.frame_queue.put(frame) # 将帧存入队列
cap.release()
self.capture_thread = Thread(target=capture_frames)
self.capture_thread.start()
def process_frames(self):
# 处理队列中的帧
while not self.stop_event.is_set():
if not self.frame_queue.empty():
frame = self.frame_queue.get()
result, processed_frame = self.detect_target(frame)
cv2.imshow("Processed Frame", processed_frame)
if cv2.waitKey(1) & 0xFF == ord('q'): # 按 'q' 退出
self.stop_event.set()
cv2.destroyAllWindows()
def stop(self):
# 停止所有线程
self.stop_event.set()
self.capture_thread.join()系统运行结果
进入系统界面:

检测到人员正在吸烟,屏幕出现红色框框,并且伴随有嘀嘀嘀的警告声:

检测到人员正在玩手机,屏幕出现红色框框,并且伴随有嘀嘀嘀的警告声:

检测到人员正在喝水,屏幕出现红色框框,并且伴随有嘀嘀嘀的警告声:

同时,屏幕右侧栏目中会显示成员疲劳状态以及得分情况,警告驾驶员切勿疲劳驾驶
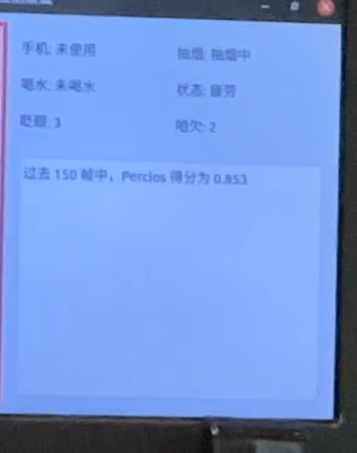

















 5508
5508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









