







大模型的开源,使得每位小伙伴都能获得AI的加持,包括你可以通过AIGC完成工作总结,图片生成等。这种加持是通用性的,并不会对个人的工作带来定制的影响,因此各个行业都出现了垂直领域大模型。
垂直大模型是如何训练出来的
简单来说,就是各个大模型公司通过大量的数据集,训练出一个base模型或SFT模型,就是下图的Pre-trained LLM预训练大模型,这个大模型就是通用大模型。
在基于垂直领域的数据集Custom knowledge进行微调Fine tuning,微调的过程也是一个训练的过程,最终获得一个微调后的垂直领域大模型Fine-tuned LLM。
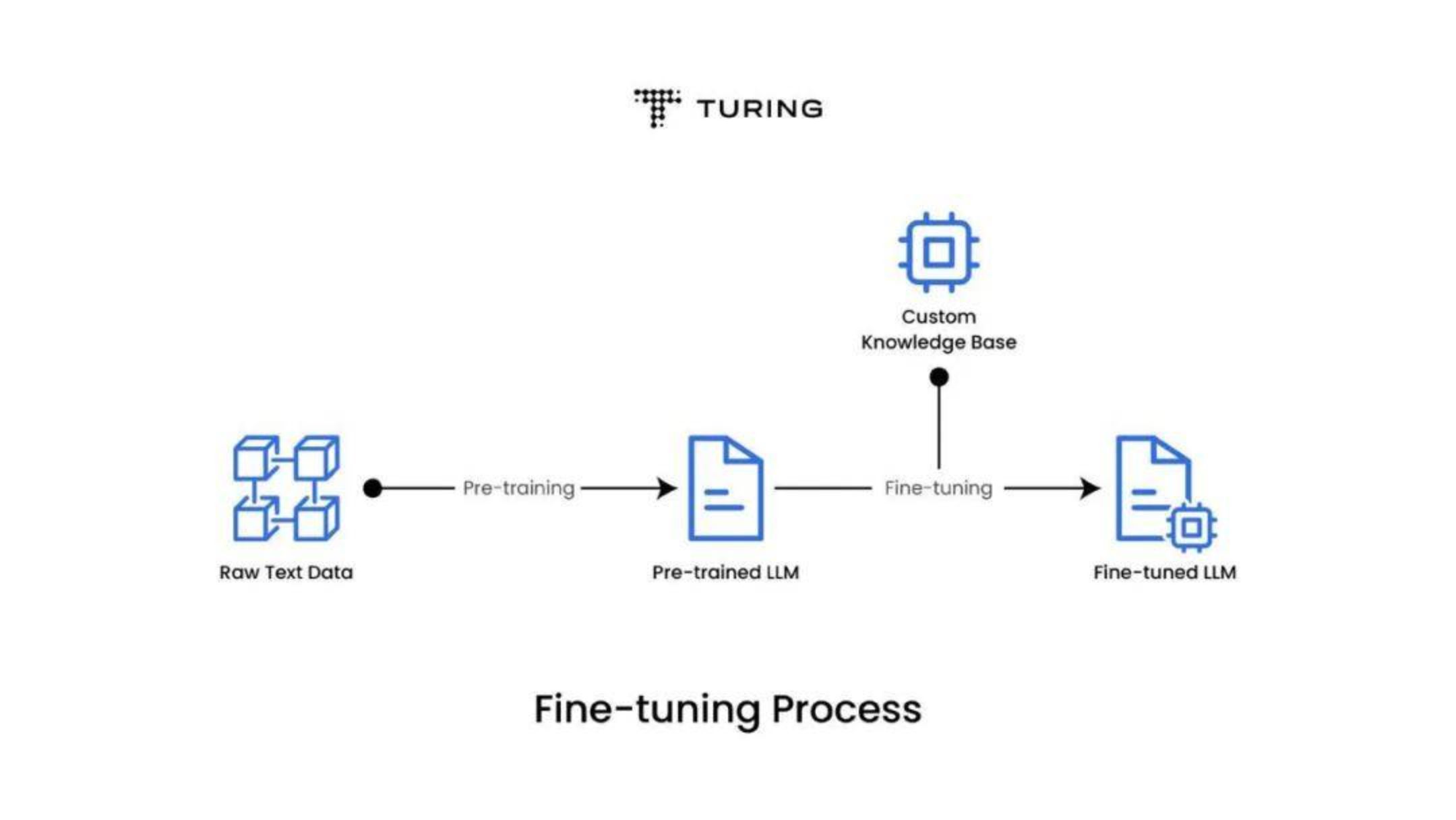
如果想制作一个与书籍相关的垂直领域大模型,就需要大量的书籍数据,这时就需要获得相关数据,以下通过亮数据(Bright Data) 完成书籍相关数据的获取工作。
如果获取AI书籍大模型的数据集
想构建一个AI书籍大模型,完成一个更懂人类书籍的大模型,为喜欢阅读书籍的朋友提供定制服务,比如可以更懂古代文献,更懂专业书籍的大模型。首先就需要获取书籍的相关数据,包括评论数据和书籍内容。
数据采集技术很多,基于Python的框架也是足够的丰富,如requests和selenium,这就要求读者会进行网页解析。
对于想快速获取数据集的同学来说,可以基于一个数据采集工具,🌰,本文基于亮数据(Bright Data)获取相关数据集,链接如下:
书籍领域的数据获取
数据获取平台-亮数据(Bright Data)介绍
亮数据(Bright Data) ,是一款低代码爬虫平台,既有现成的爬虫解锁框架,还提供IP代理服务。
亮数据首页
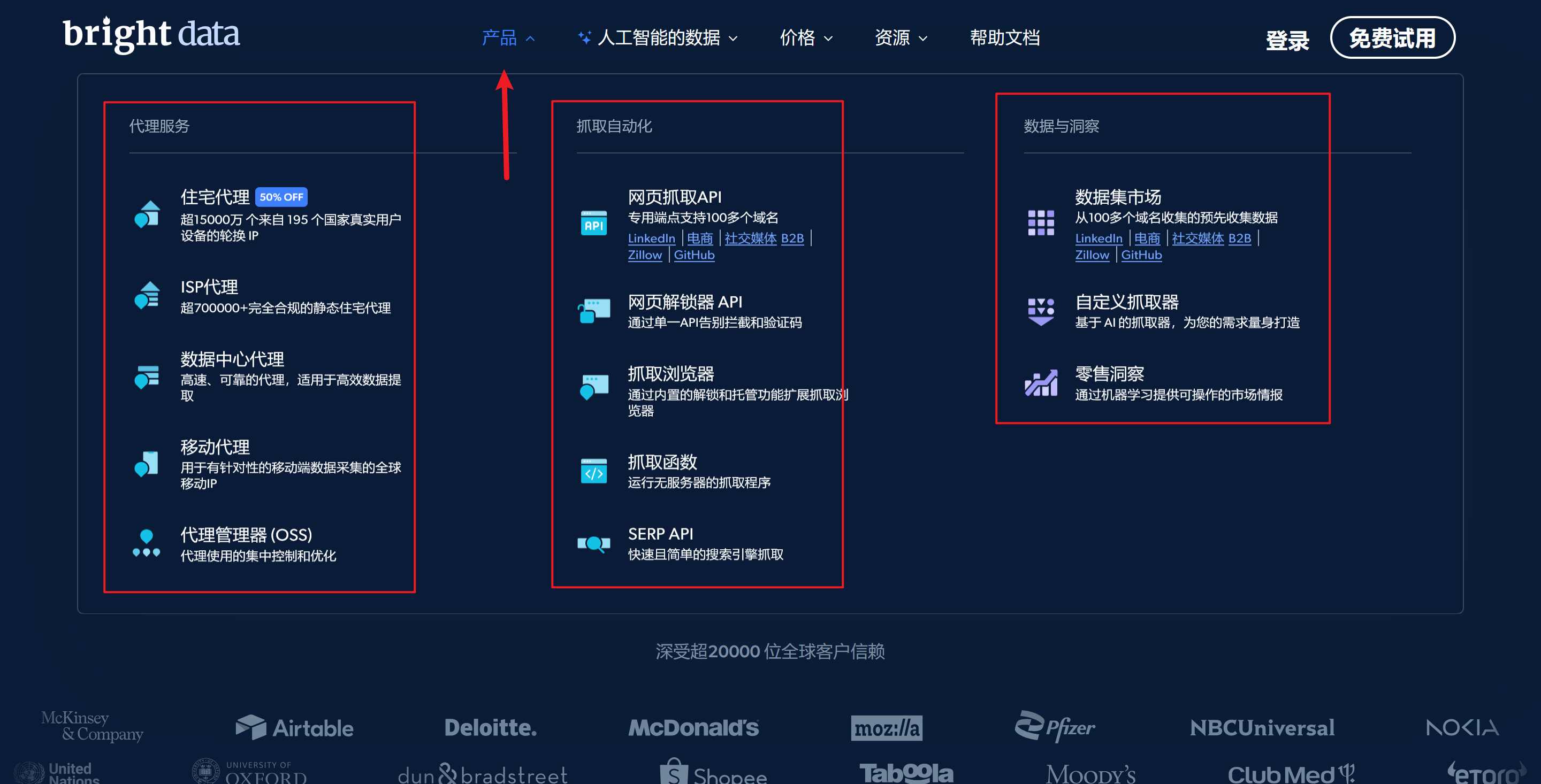
亮数据提供的产品主要包括代理服务,抓取自动化与数据洞察等
本文主要基于抓取自动化中的完成数据采集的测试与爬取
亮数据使用步骤
新用户有亮数据的免费赠送的$,可以率先体验下,比较友好。
1.注册亮数据
点击链接进入主页
亮数据(Bright Data)
单击登录
首次使用可以点击注册
输入必备的信息后,点击创建账户,创建完毕后,可进入控制台
2.创建爬虫任务
在控制台页面可以看到右上角提供了一个AI对话功能
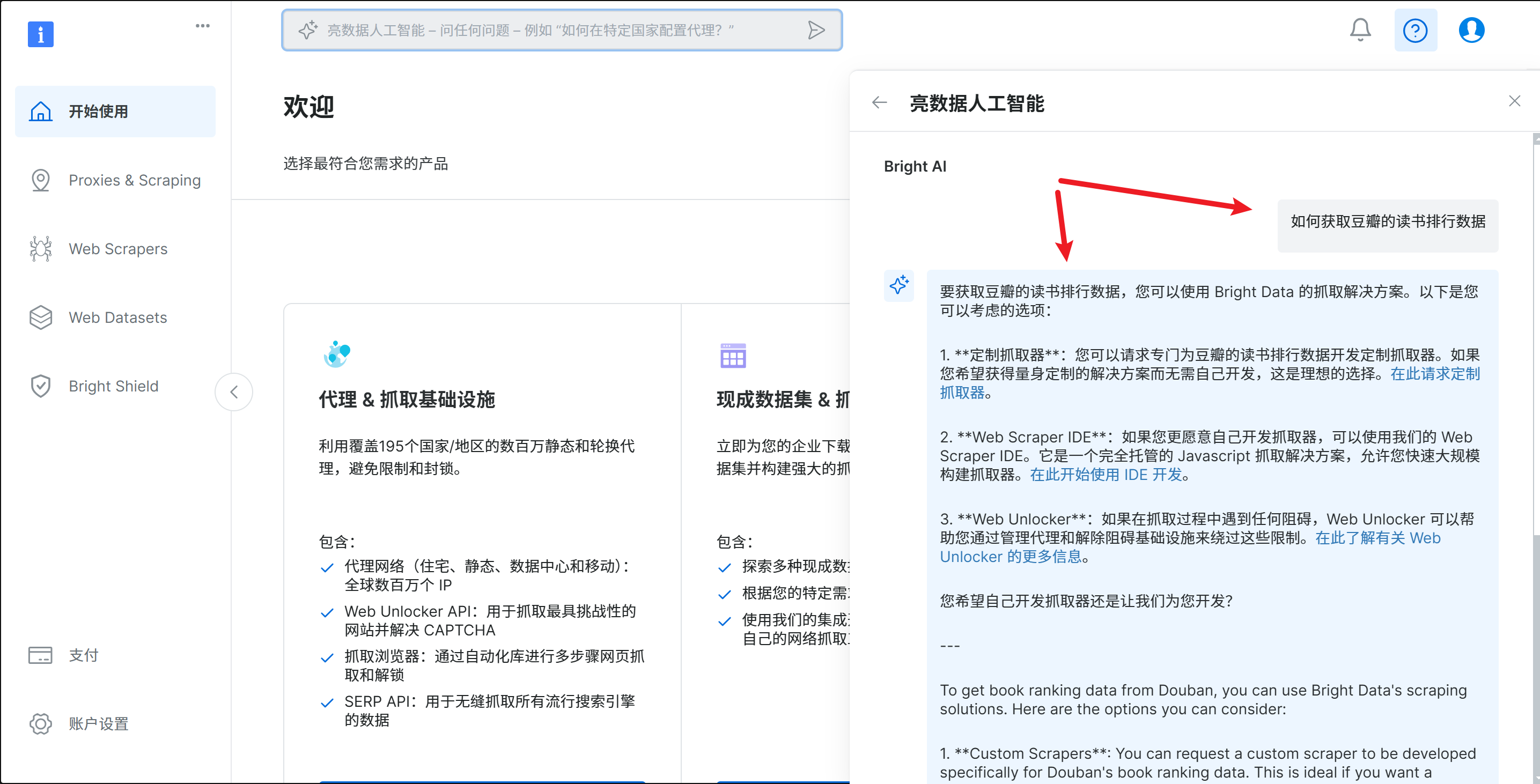
询问以下如何获取相关数据集
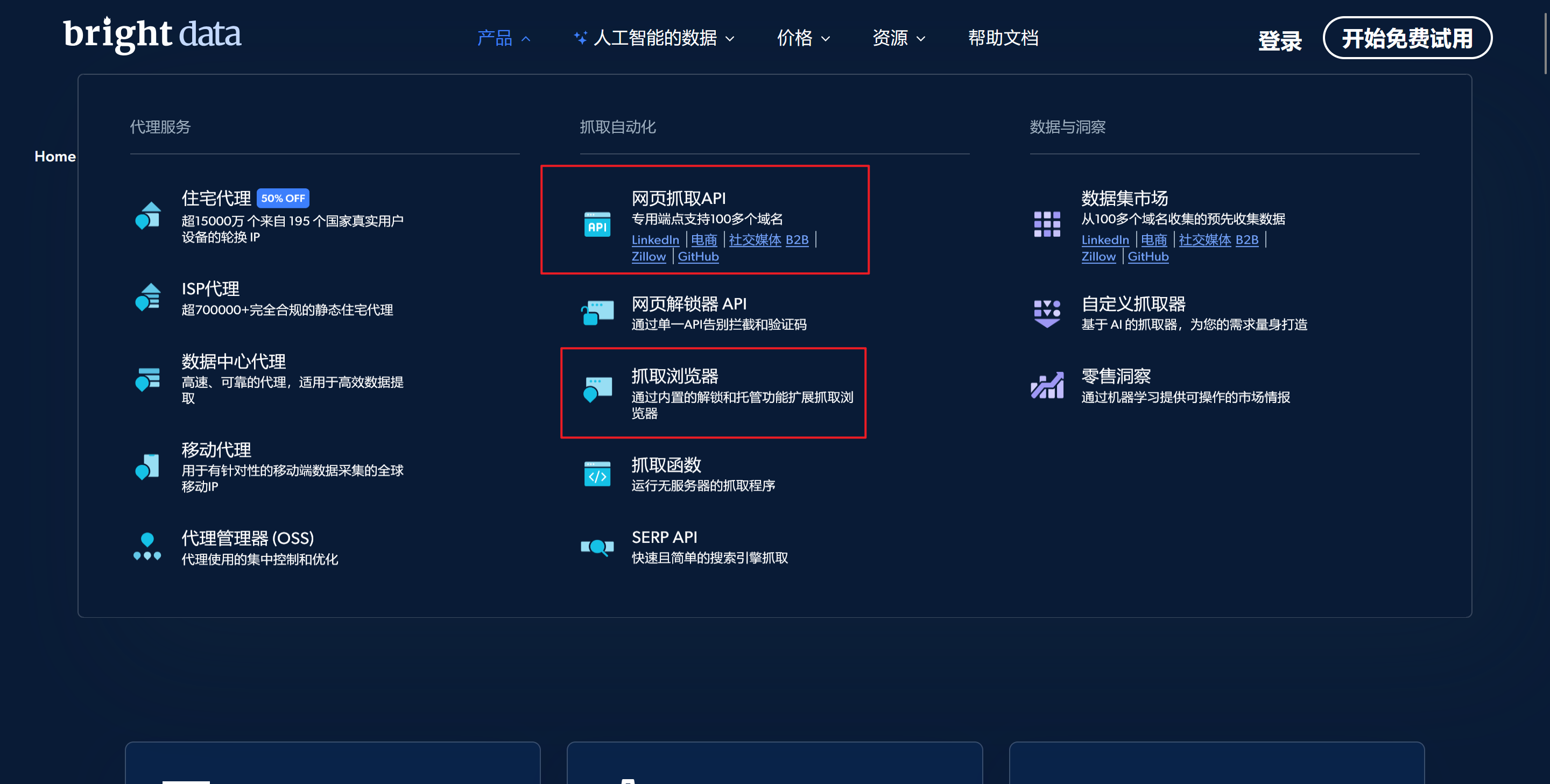
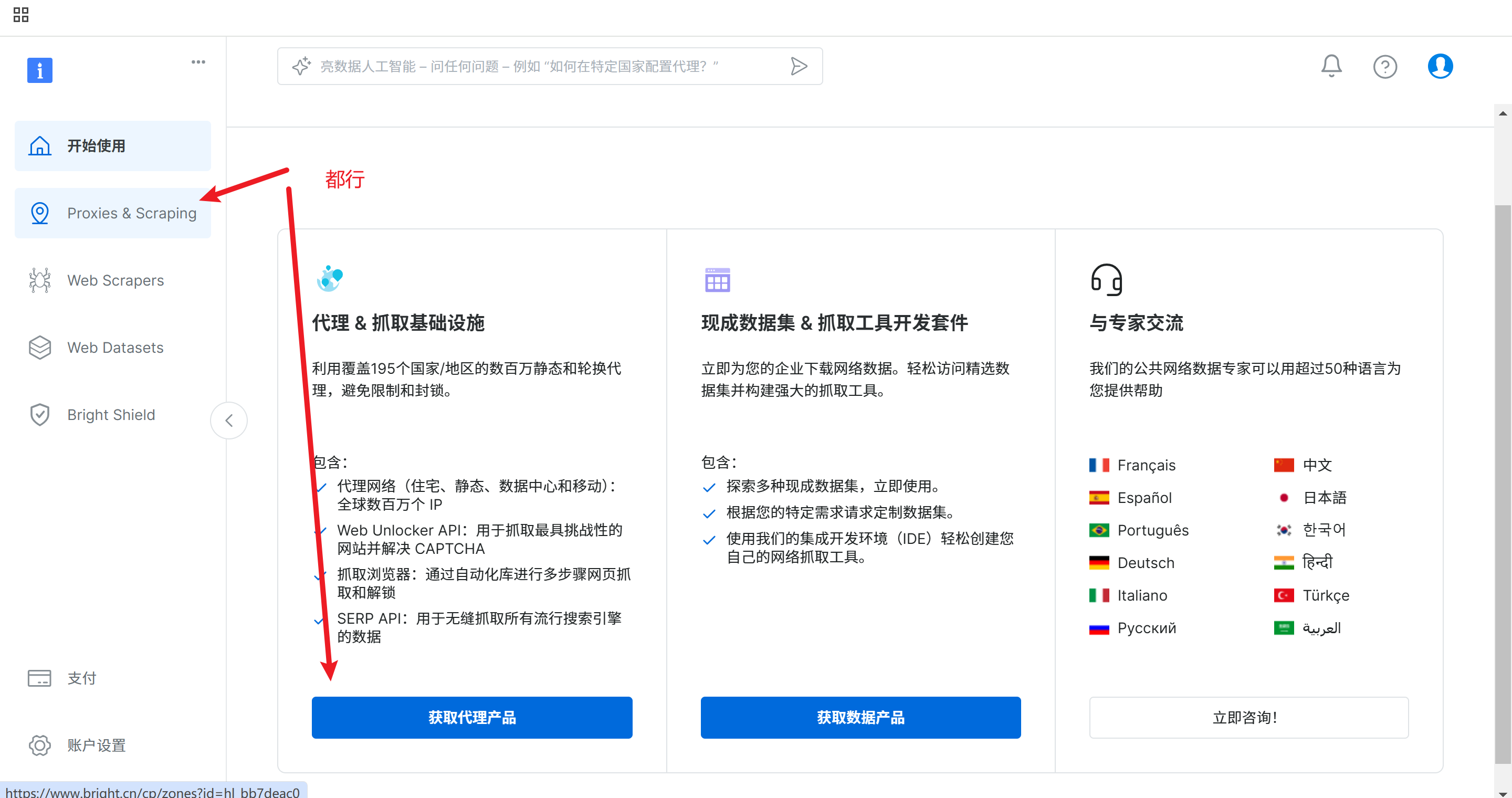
也可以直接单击代理&抓取集成设置下的代理产品
单击获取代理产品
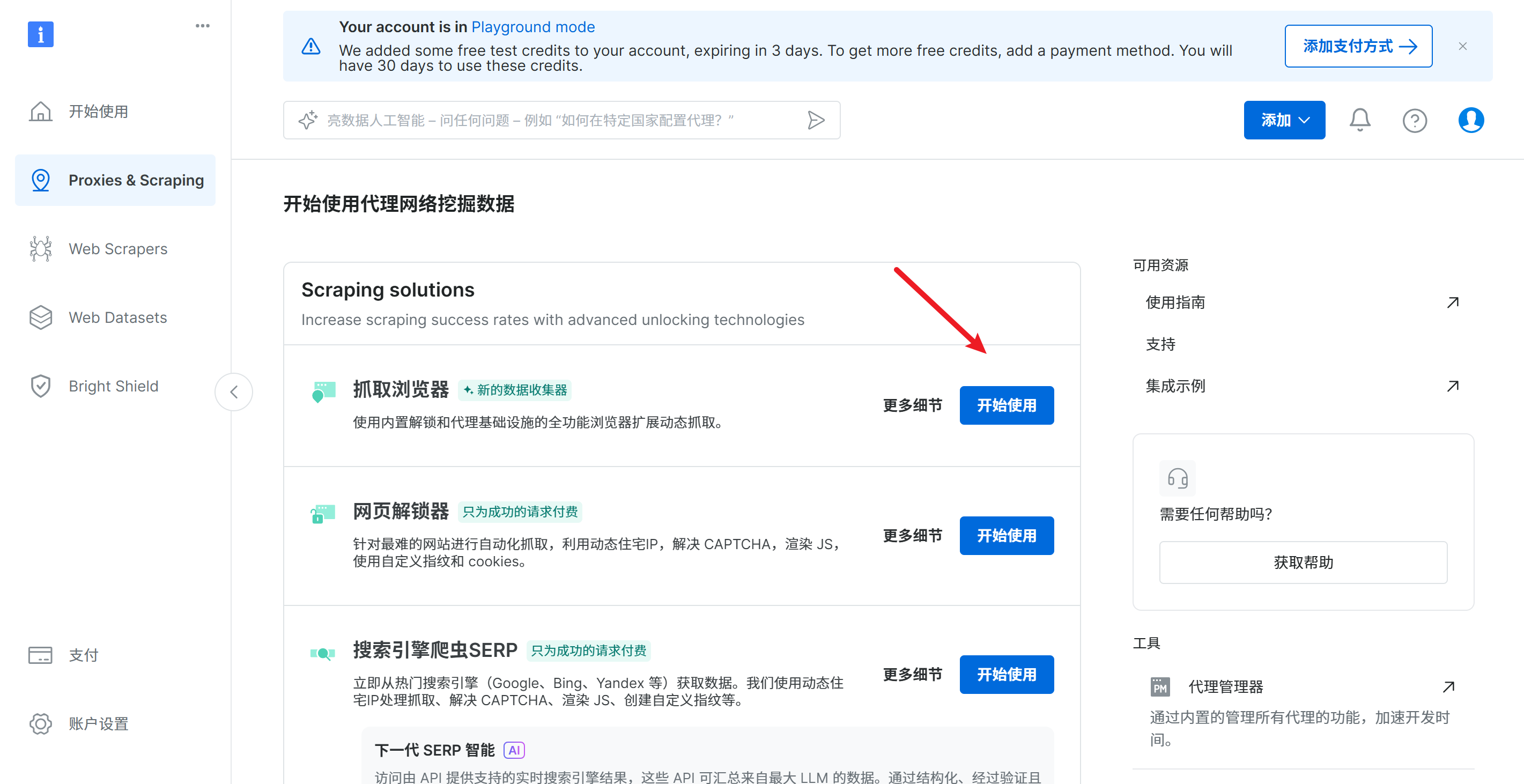
单击开始使用
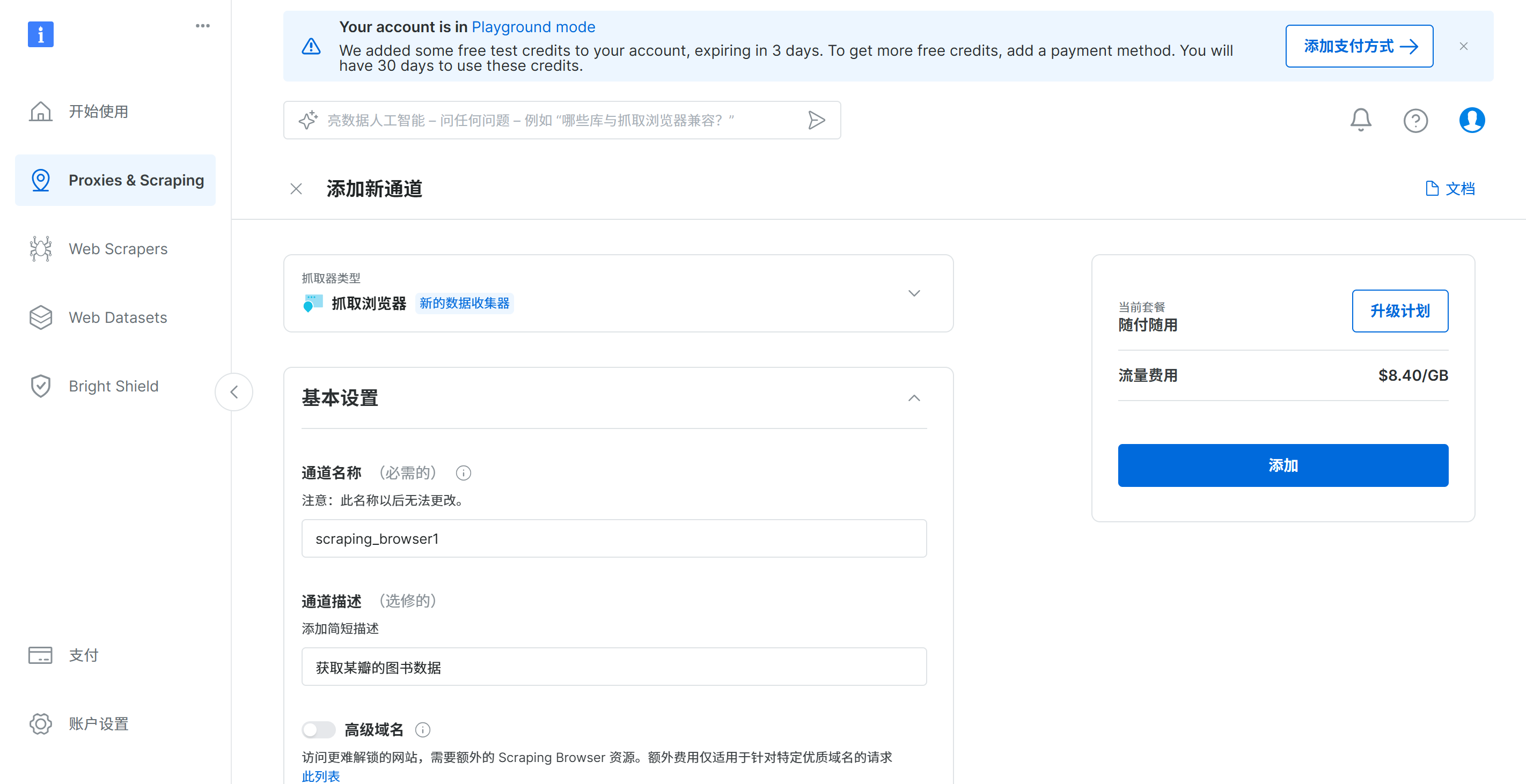
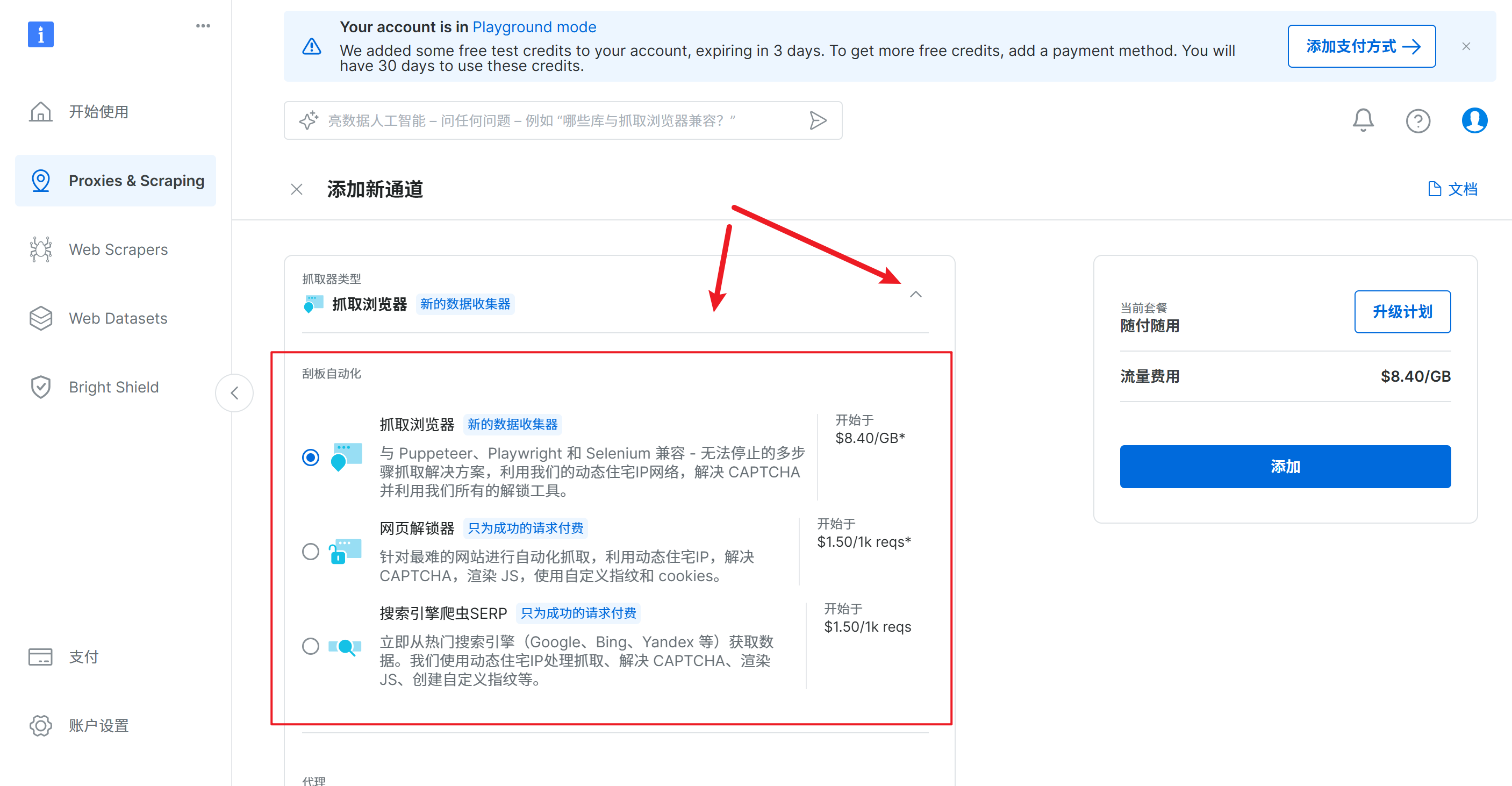
输入通道名称为:scraping_browser1_douban
通道描述为:获取某瓣的图书数据单击向下箭头,也可以切换抓取器类型,这里选择默认的抓取浏览器
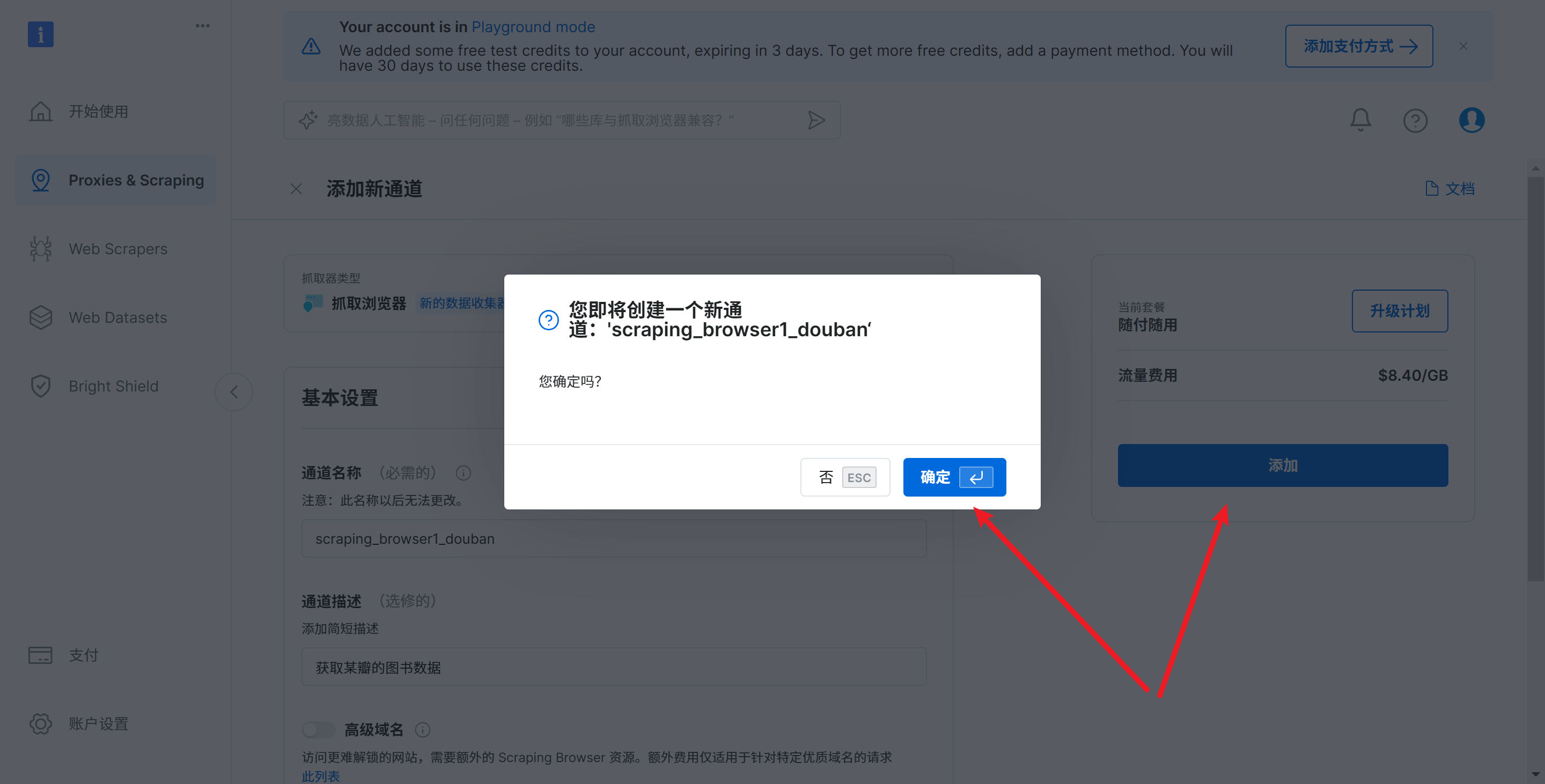
单击添加和确定,完成通道添加
会提示配置信息
单击 continue with Scraping browser playground,完成爬虫任务创建
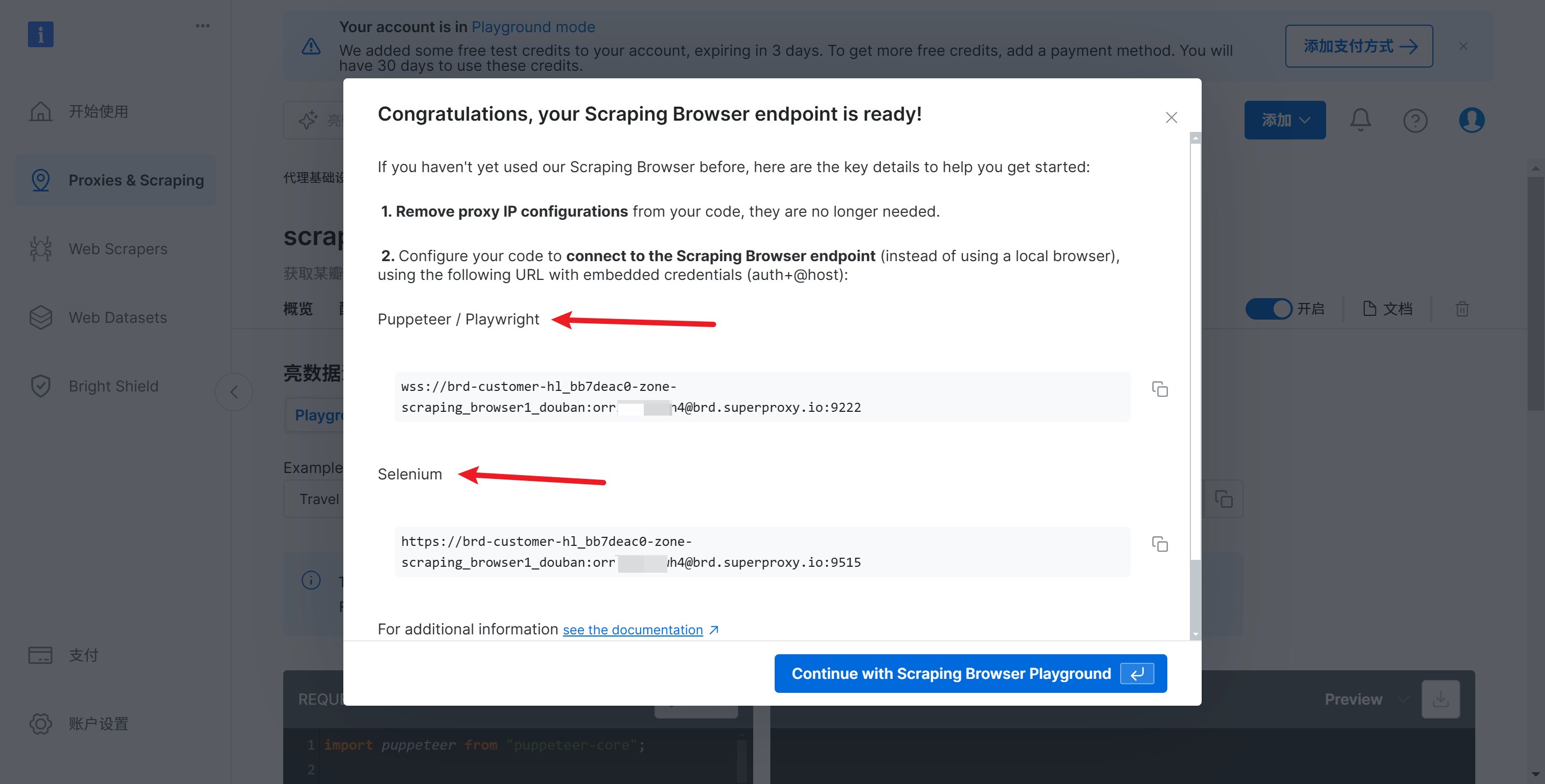
3.生成代码-测试亮数据的ip池
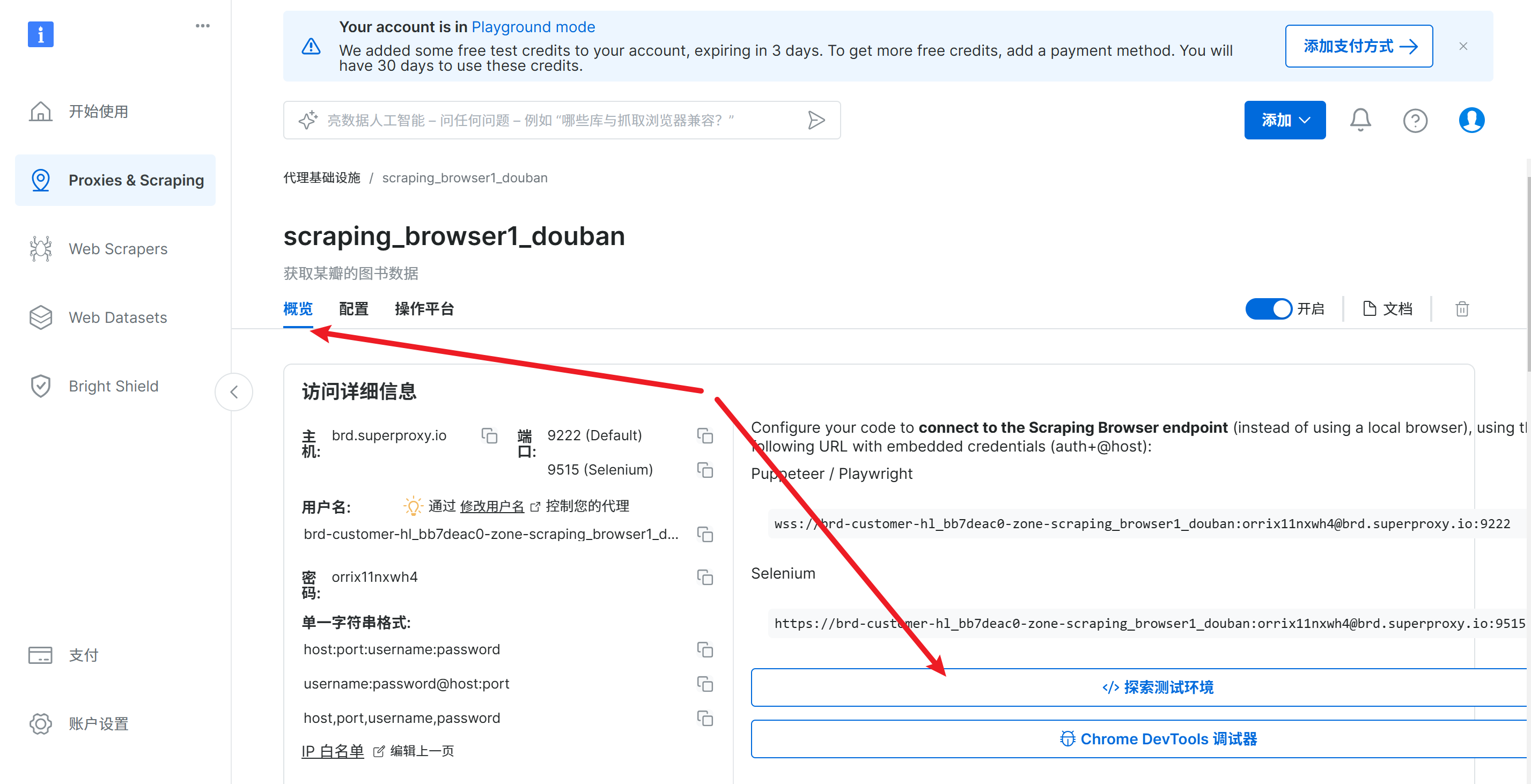
在弹出的页面配置中,选择概览,在选择探索测试环境
在操作平台中可以切换要生成的爬虫案例代码,这里选择python语言的selenium框架
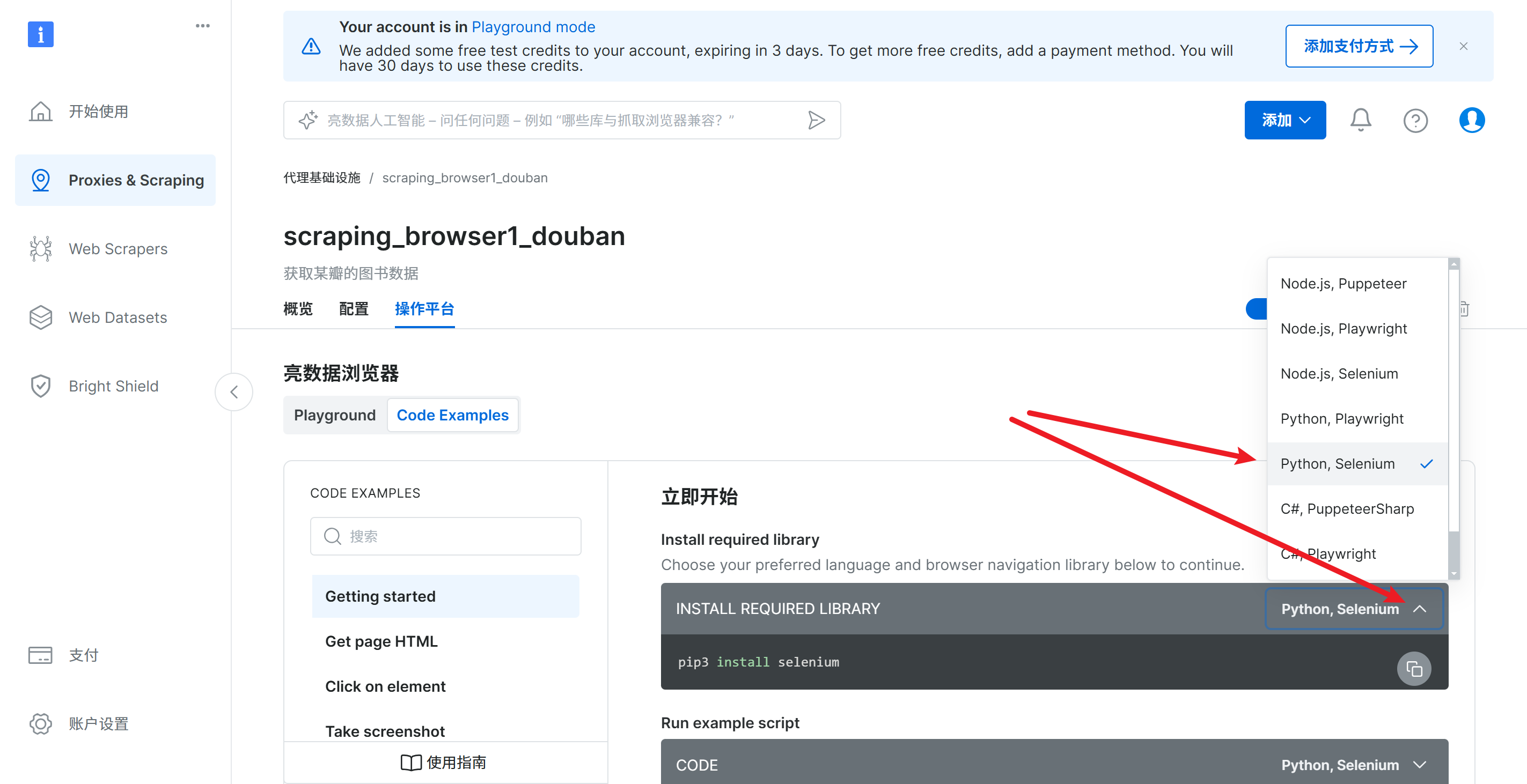
按照提示安装selenium依赖
pip3 install selenium
提示如下:
Successfully installed cffi-1.17.1 outcome-1.3.0.post0 pycparser-2.22 pysocks-1.7.1 selenium-4.31.0 sortedcontainers-2.4.0 trio-0.29.0 trio-websocket-0.12.2 wsproto-1.2.0
在本地创建 scrapydemo.py,复制代码到本地
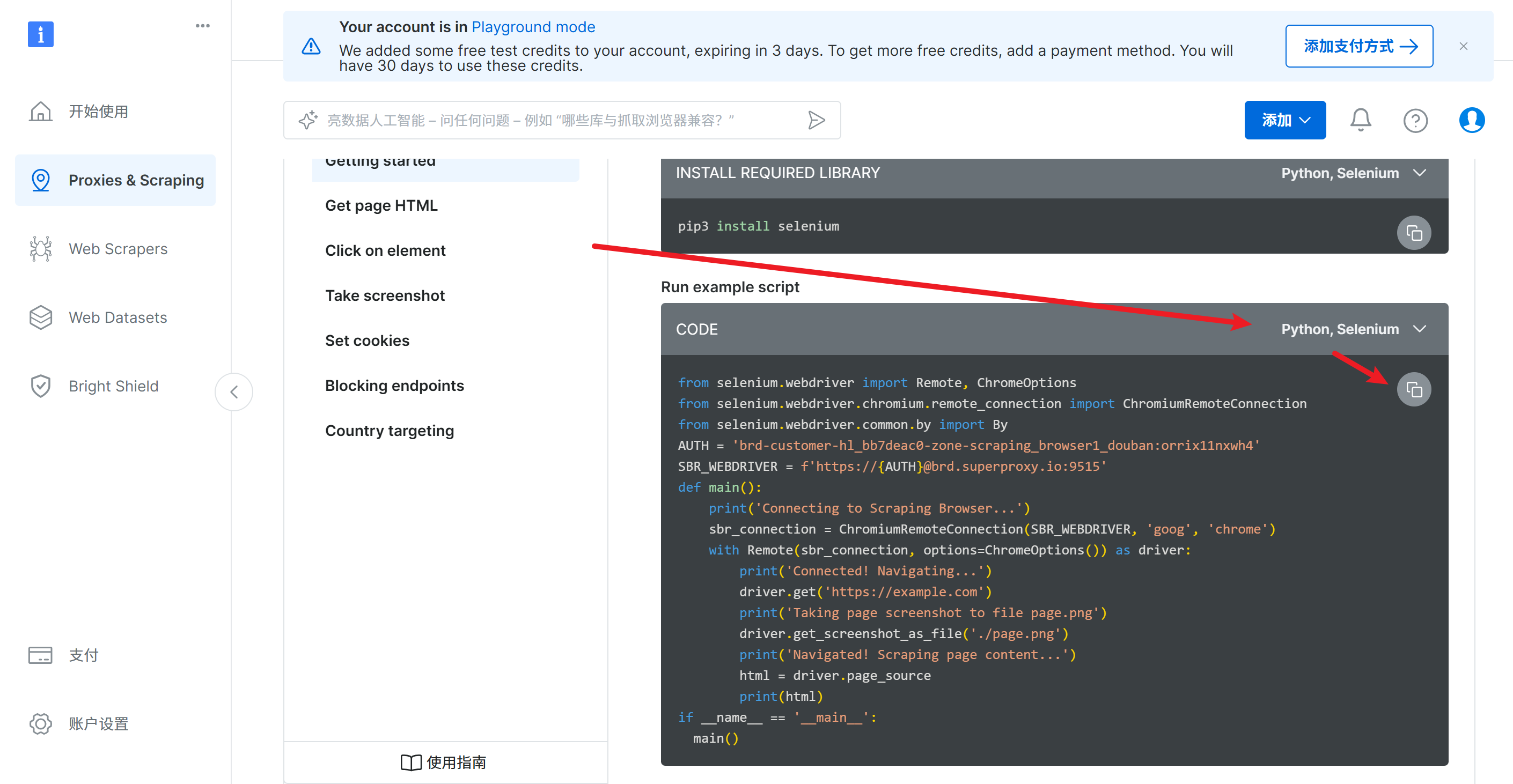
代码如下,这里的AUTH已经填充完毕,如果需要更改,可以在配置中复制用户名即可
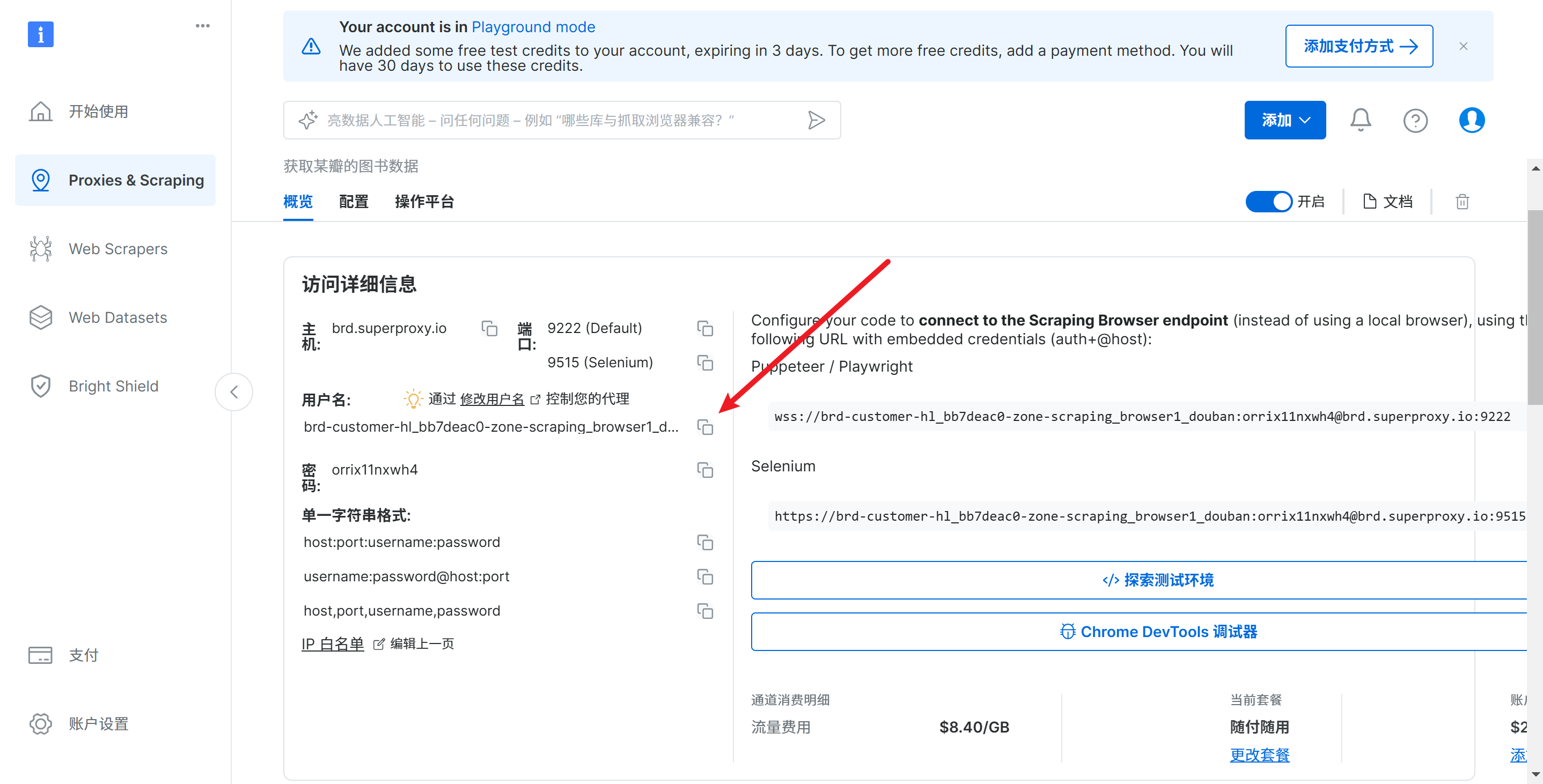
代码如下:
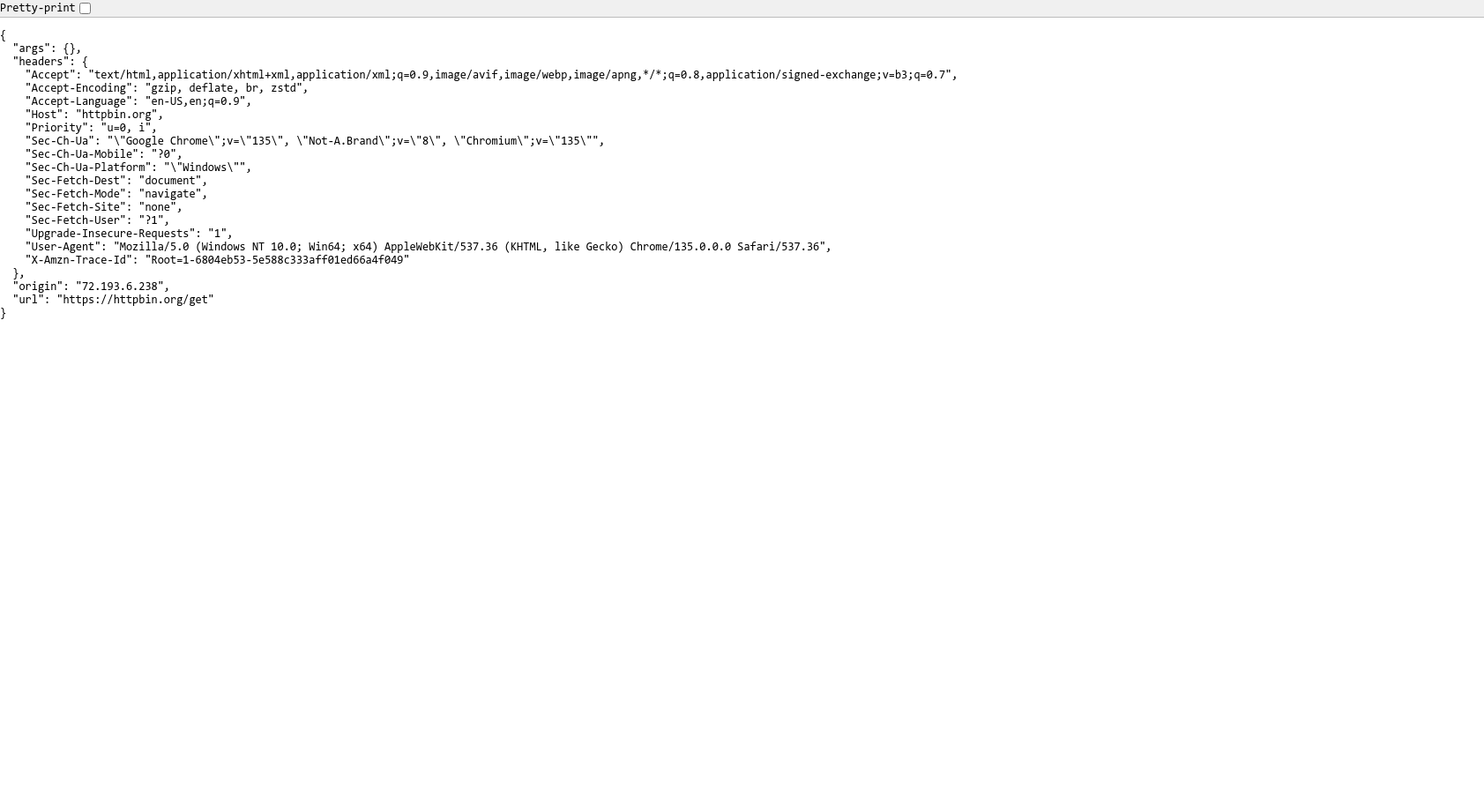
把测试的网址替换为: http://httpbin.org/get,该网站可以返回请求的信息
备注:这里的代理信息会在后文删除,在使用过程中,替换为自己的信息就好
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
AUTH = 'brd-customer-hl_bb7deac0-zone-scraping_browser1_douban:orrix11nxwh4'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'
def main():
print('Connecting to Scraping Browser...')
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('Connected! Navigating...')
# 这里把测试网站替换位 http://httpbin.org/get
url = "http://httpbin.org/get"
# url = "https://example.com"
driver.get(url)
print('Taking page screenshot to file page.png')
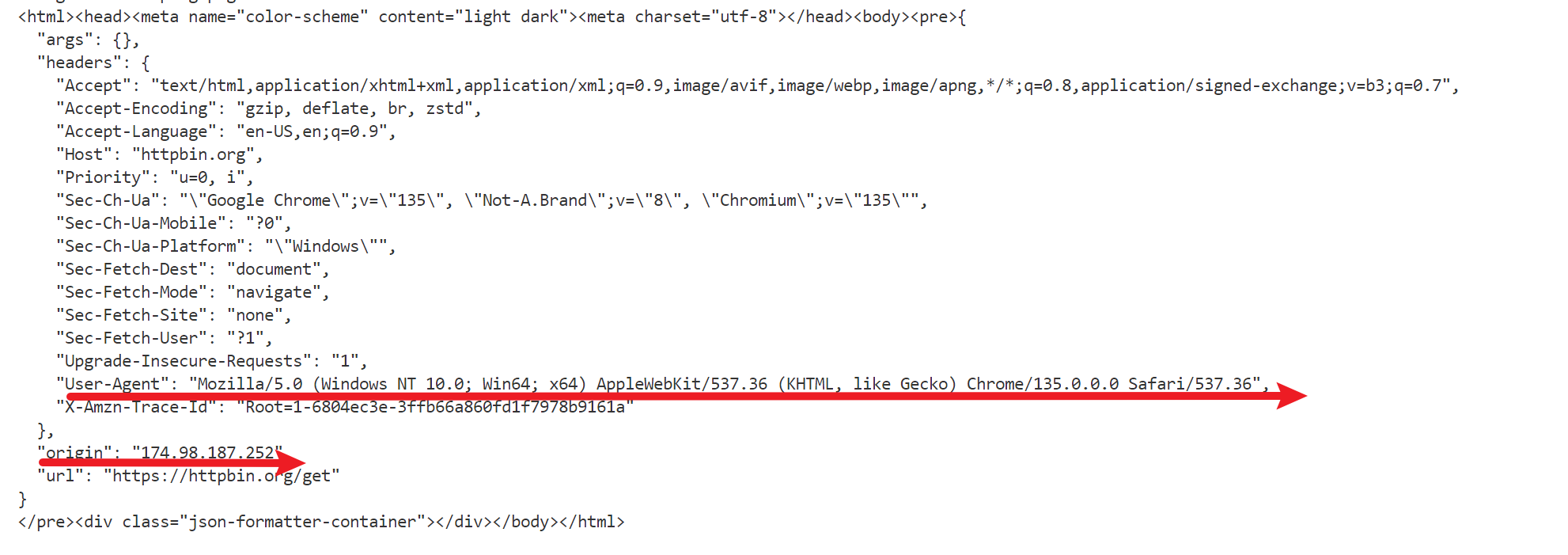
driver.get_screenshot_as_file('./page.png')
print('Navigated! Scraping page content...')
html = driver.page_source
print(html)
if __name__ == '__main__':
main()
运行测试,输出如下:
控制台输出
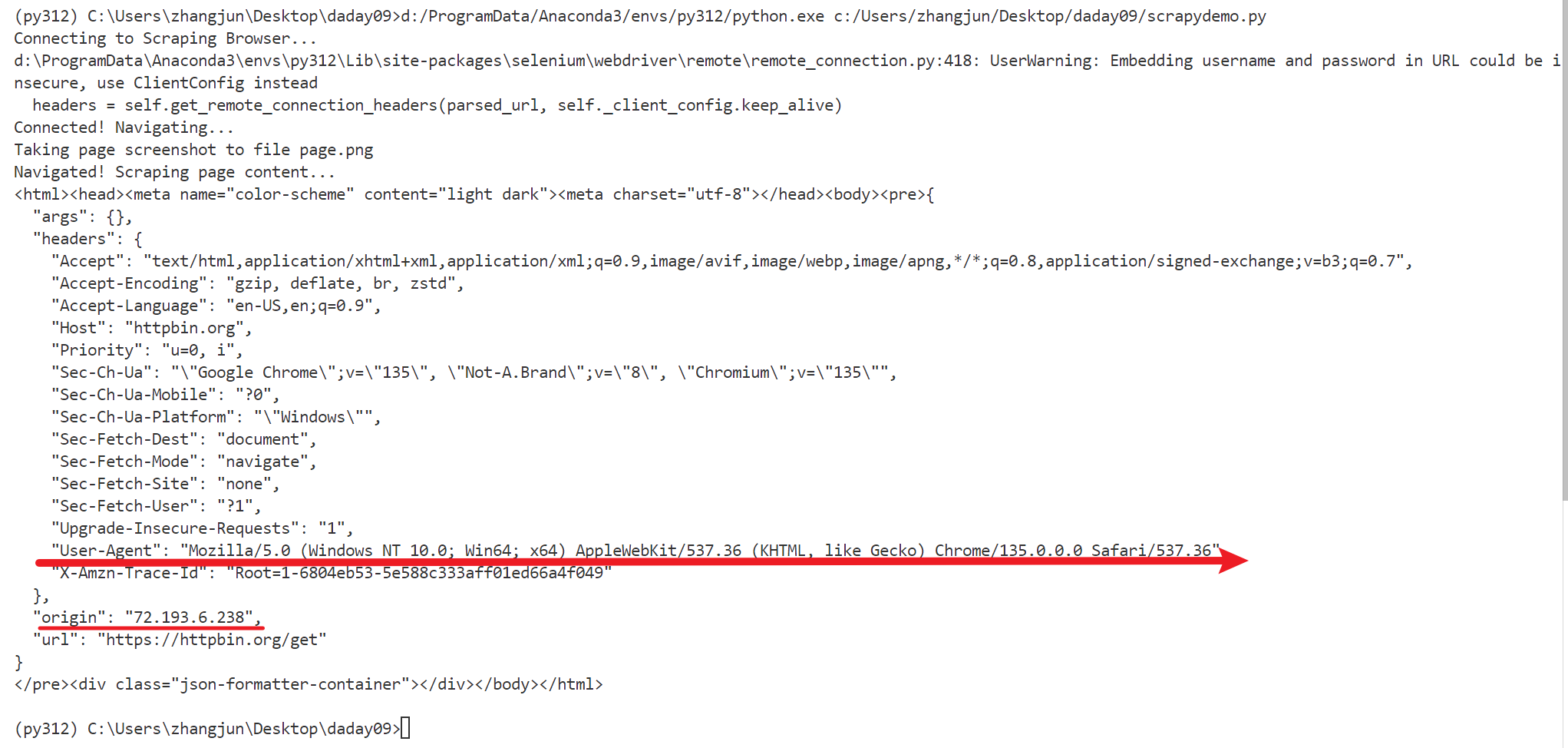
保存的页面png如下
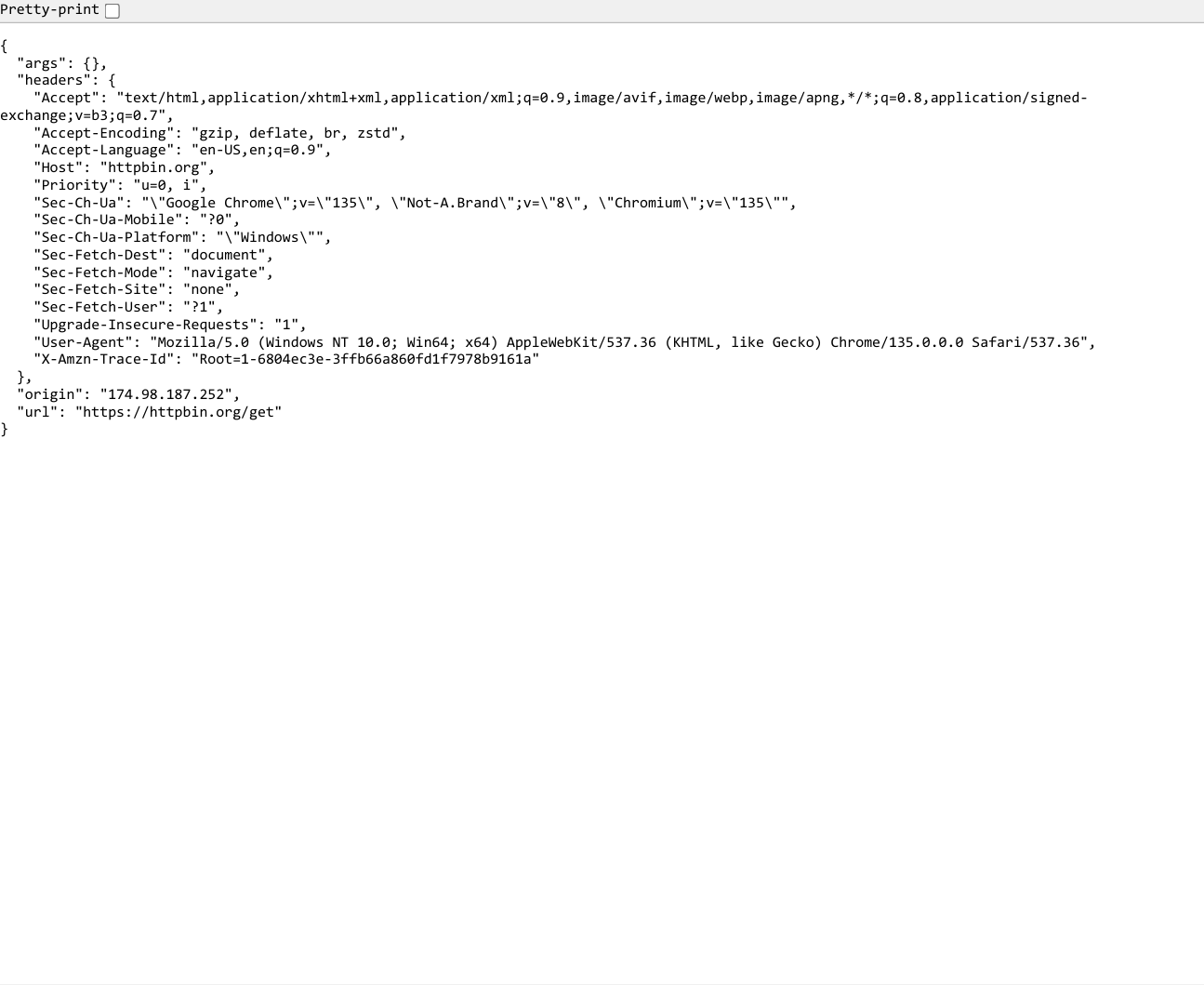
再次运行该代码,返回如下:
可以看到两次的地址发生了改变,可以减少被屏蔽ip的情况发生。
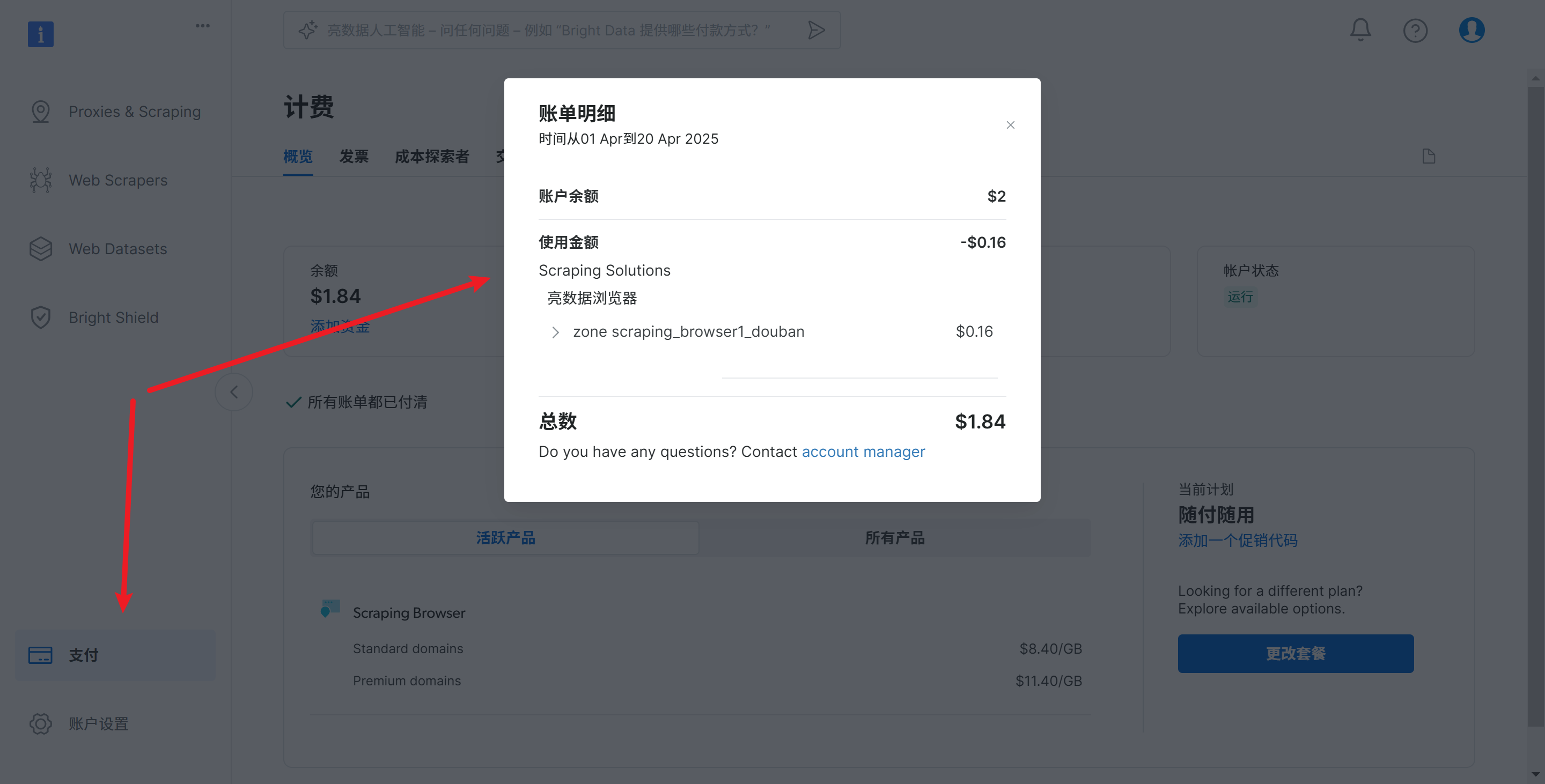
同时点击控制台中的左下角的支付,可以查看消费情况
4.修改代码获取豆瓣的书籍数据(可用代码)
import time
from lxml import etree
import csv
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
AUTH = 'brd-customer-hl_bb7deac0-zone-scraping_browser1_douban:orrix11nxwh4'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'
def main():
print('Connecting to Scraping Browser...')
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('Connected! Navigating...')
# url = "http://httpbin.org/get"
start_url = "https://book.douban.com/subject_search?search_text=python&cat=1001&start=%25s0"
# url = "https://example.com"
content = driver.get(start_url)
num=0
while True:
num+=1
# 停一下,等待加载完毕
time.sleep(2)
# 获取网页内容Elements
content = driver.page_source
# 提取数据
data_list = etree.HTML(content).xpath('//div[@class="item-root"]')[1:]
for data in data_list:
item = {}
item["name"] = data.xpath("./div/div[1]/a/text()")[0]
item["score"] = data.xpath("./div/div[2]/span[2]/text()")[0]
with open("./豆瓣图书.csv", "a", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(item.values())
print(item)
# 找到后页
next = driver.find_element(By.XPATH,'//a[contains(text(),"后页")]')
# 判断
if next.get_attribute("href"):
# 单击
next.click()
else:
# 跳出循环
break
if num>3:
break
print('Taking page screenshot to file page.png')
driver.get_screenshot_as_file(f'./page{num}.png')
print('Navigated! Scraping page content...',num)
# html = driver.page_source
# print(html)
if __name__ == '__main__':
main()
输出如下:
保存的页面快照如下
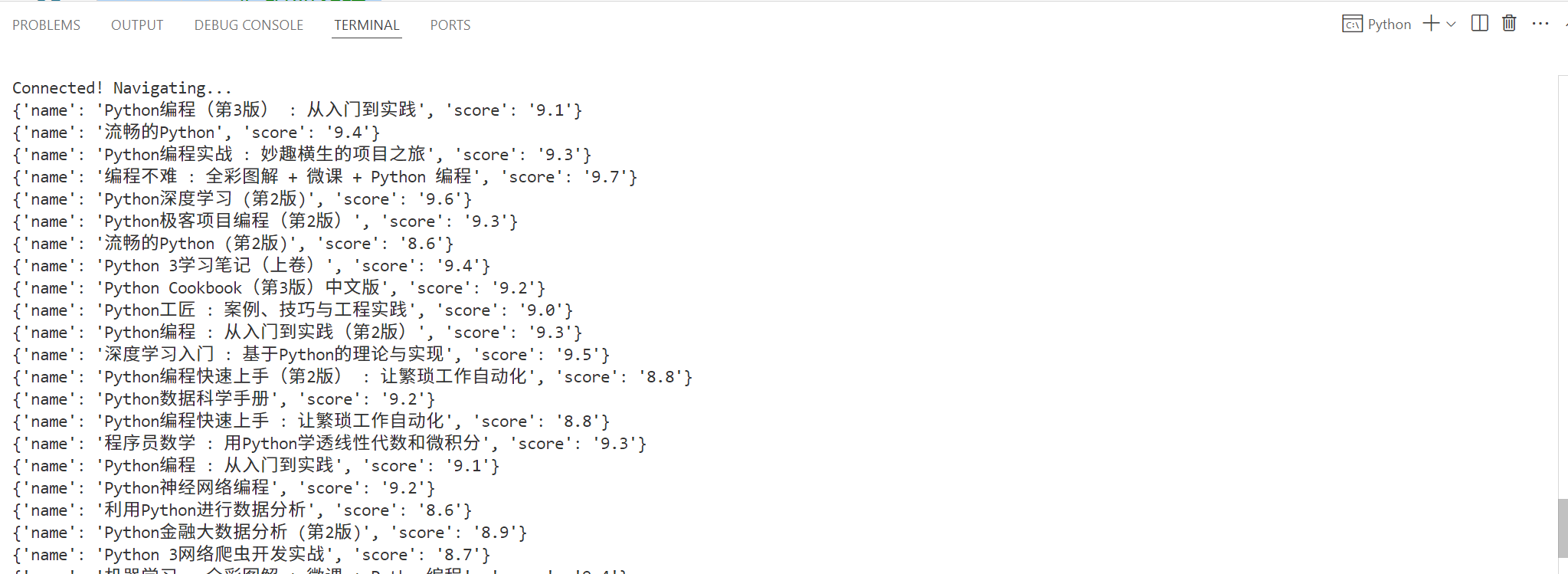
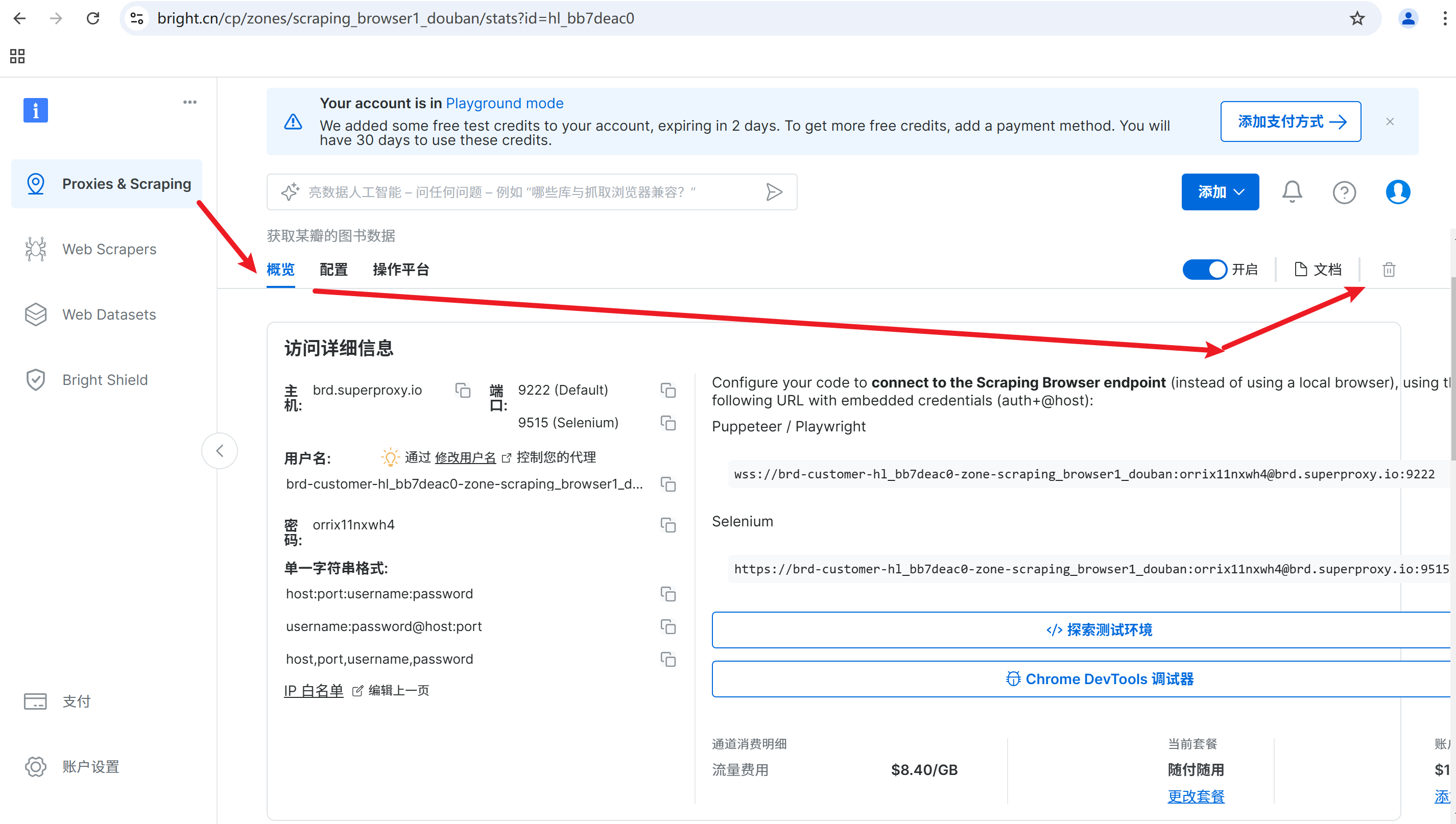
5.删除亮数据的代理
如果数据采集任务完成,我们可以选择删除代理,便于控制使用费用,这点是十分友好的,避免定时爬虫的反复消费。
删除后状态如下
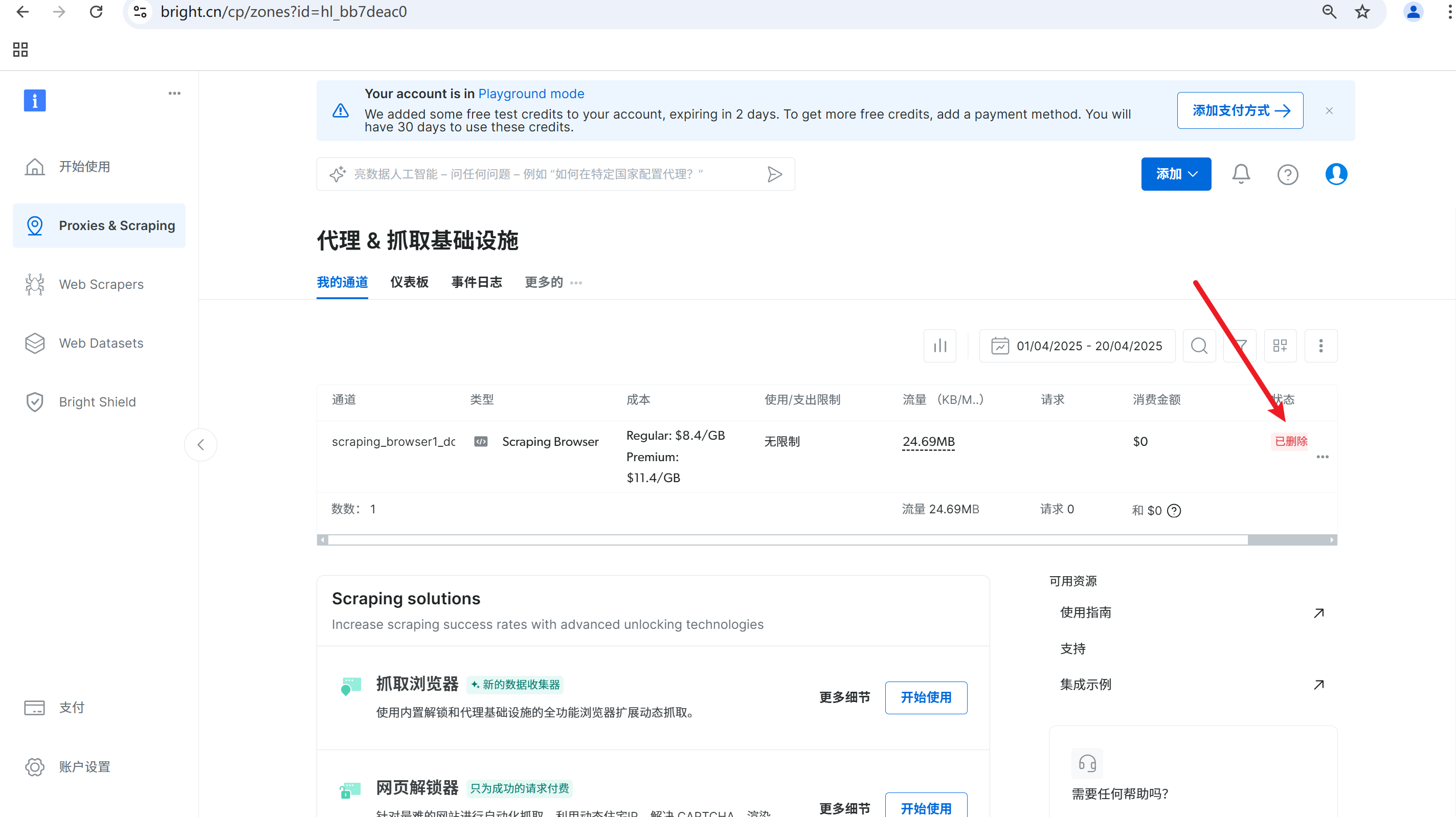
通过亮数据的WEB Datasets下载
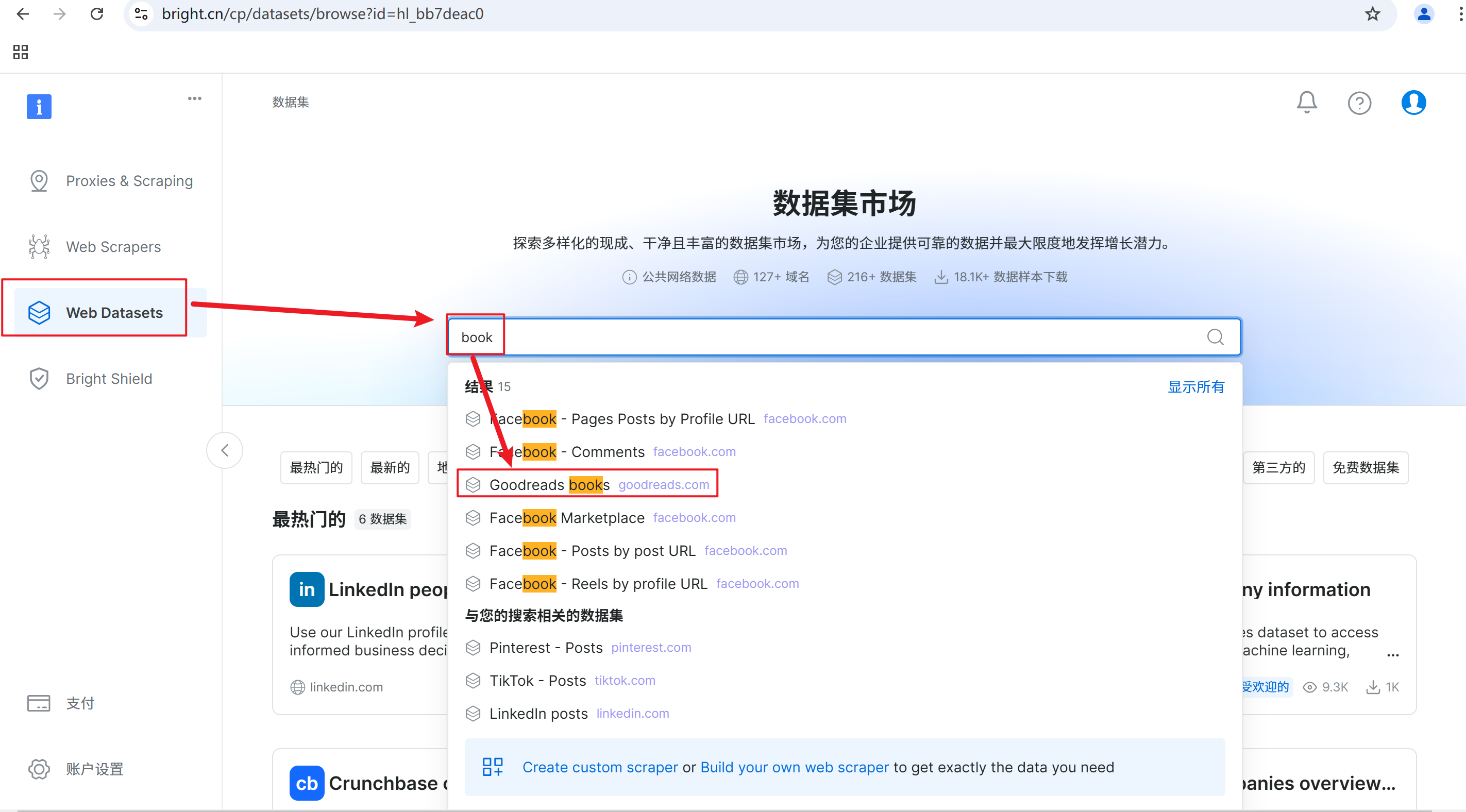
如果是对爬虫技术不了解的朋友,也可以在亮数据的WEB Datasets中下载数据,步骤如下:
单击Web Datasets -->输入book–>选择Goodreads books
Goodreads是“美国版豆瓣”。
它是全球最大的在线读者社区和图书推荐平台,拥有庞大的书籍数据库,涵盖各种类型的书籍。同时会员数量过亿,分布在全世界各地。Goodreads的用户们可以对读过的书籍撰写书评并打分,其他用户也可以进行点赞、评论,加入讨论、分享观点。
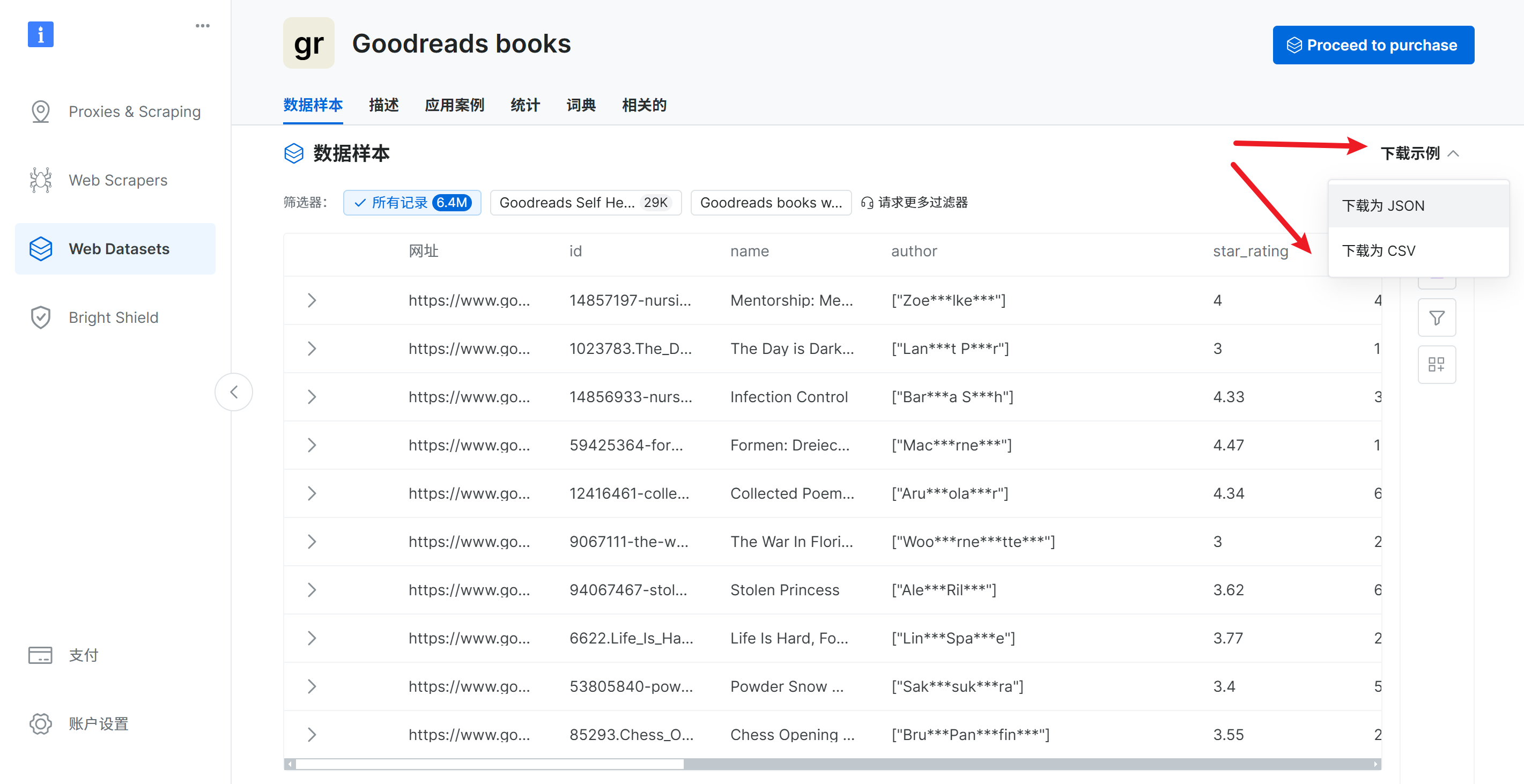
进入页面后,可以下载样例数据
下载后的样例如下:

数据获取总结
如果需要获取垂直领域的数据集,可以通过代理自行下载,也可以查找亮数据(Bright Data) 是否有现有的数据集,这两点可以满足不同的需求,比较友好💯。
垂直大模型举例
氢界专利大模型

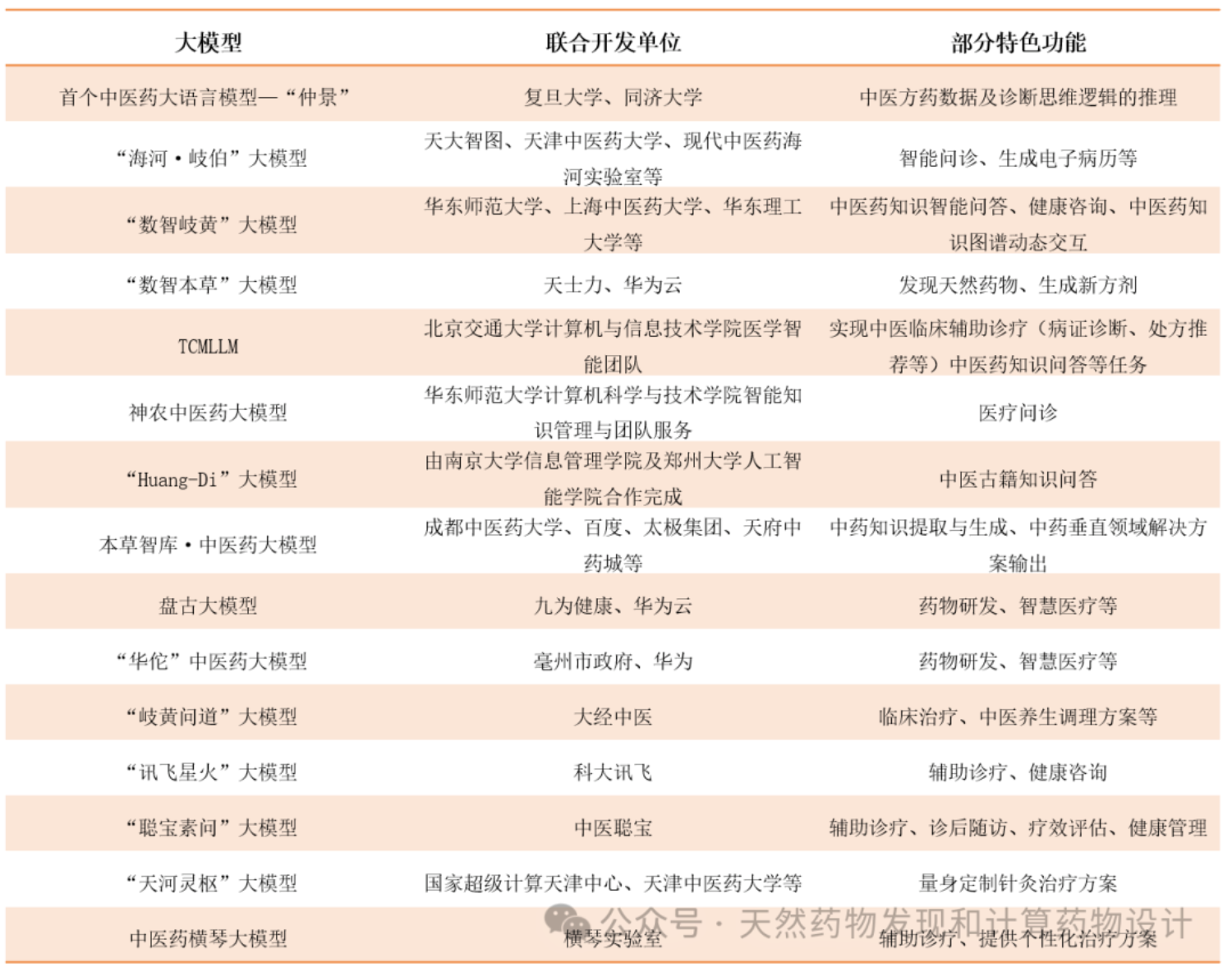
医疗领域大模型
链接:https://baijiahao.baidu.com/s?id=1808887323039887765


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











