






核心技术思路
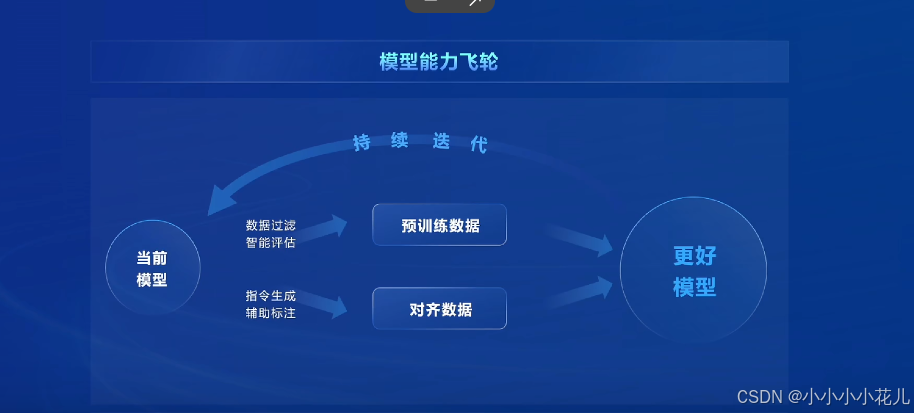
高质量合成数据(融合多种数据合成方案,提升合成数据质量)
1.基于规则的数据构造

2.基于模型的数据扩充
给一些简单的函数做一些注释
3.基于反馈的数据生成(标注困难)

领先的推理能力
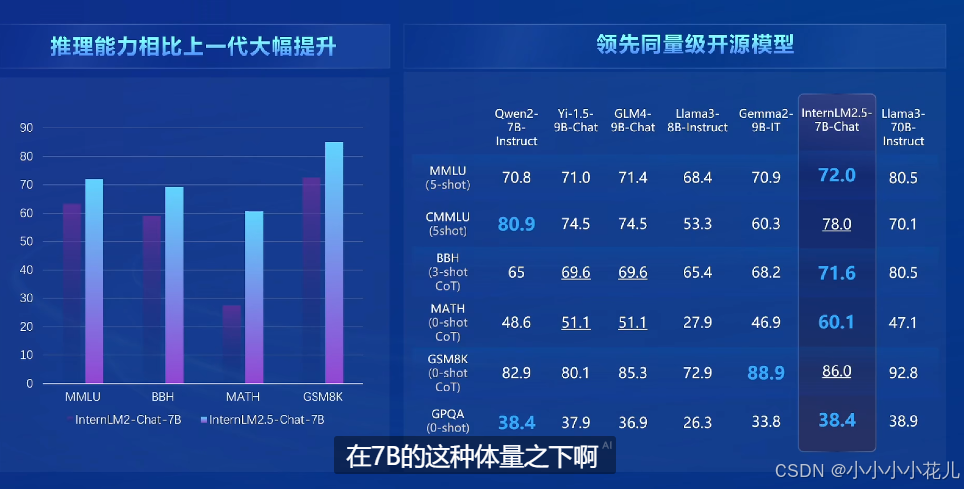
模型的原生具备推理能力,不需要特别多的提示词
大海捞针实验
大海捞针实验就是当你给模型提供一段非常长的背景知识的时候,模型是否能够去完整的定位这段超长背景知识中任何位置的任何信息。
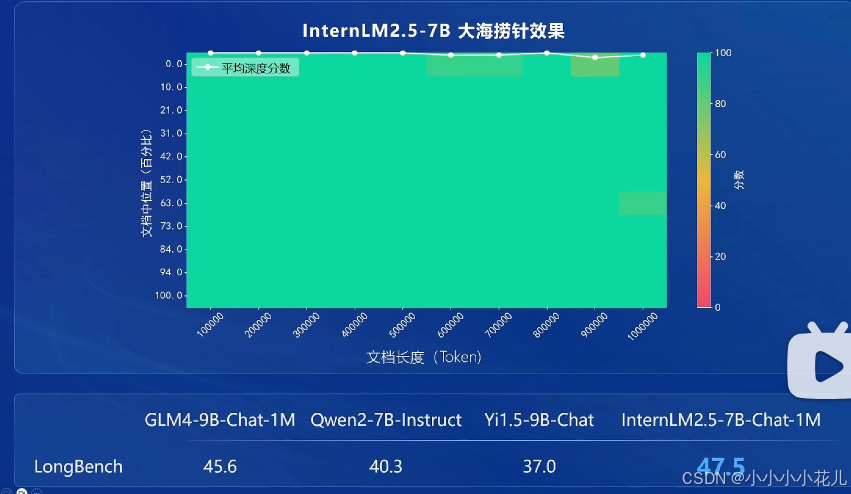
如上图的左边第一列,当给模型提供十万token的背景知识的时候,模型几乎能百分百定位到文章中任何位置的任何信息。那么随着背景知识长度的增加, 大海捞针模型的效果也会逐渐遗忘。
基于规划和搜索解决复杂问题
模拟人解决问题的思路,先对问题本身进行分析(由语言模型本身完成),分析成几个子问题后,分布解决这些子问题,然后判断是否需要调用外部工具,最后将所有的结果进行汇总整合

书生.浦语开源模型谱系

书生浦与全链条

模态数据方面

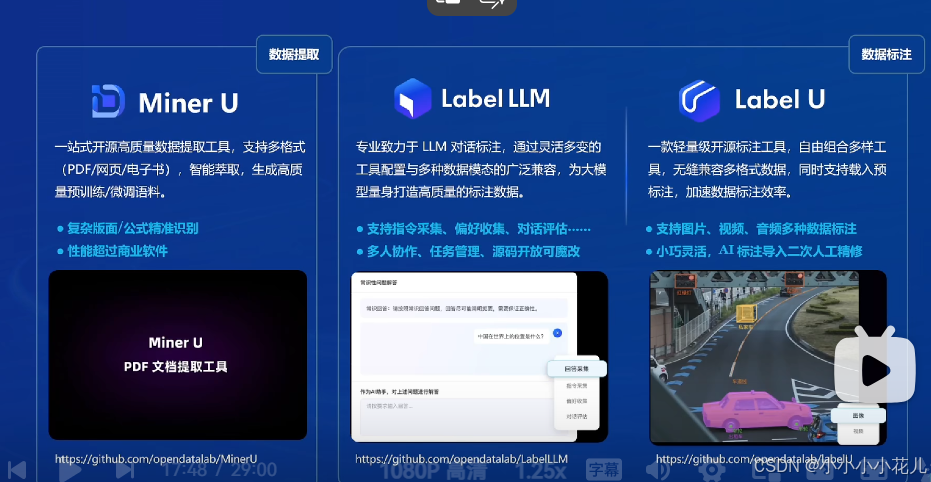
预训练 InternEvo相较于其他预训练主要是进行了一些显存优化和一些分布式训练,以及分布式训练之间的一些通信的优化,对企业来说非常节省成本及提高效率
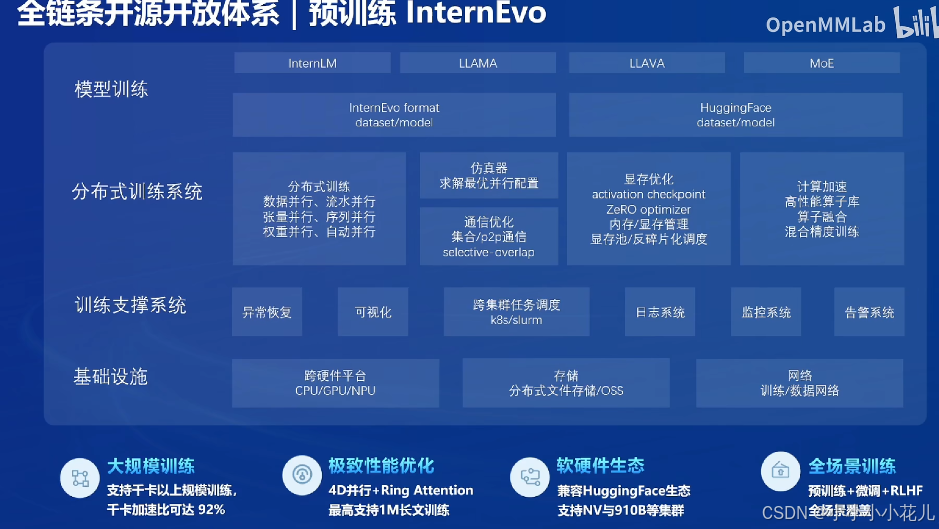
微调XTuner
微调XTuner 框架也是支持了市面上其他厂牌的开源模型,他的任务类型包括增量预训练指令微调,多模态微调以及对齐。这个X图的微调框架都是对齐的。数据格式就是兼容一些已经开源并且用得比较多的一些开源数据集的格式,其实它的内部都是化成统一格式,训练引擎是基于open mmlab,MMN,优化加速使用了flash attention,flash attention直接内置开启。
微调好后就是评测,open compass评测体系广泛应用于头部大模型企业及科研机构。
评测完就是部署。


所以要对大模型进行智能体框架的构建,让他与外部工具进行交互,提高输出的可靠性。
智能体主要是LeGent框架

零样本泛化:多模态AI工具使用
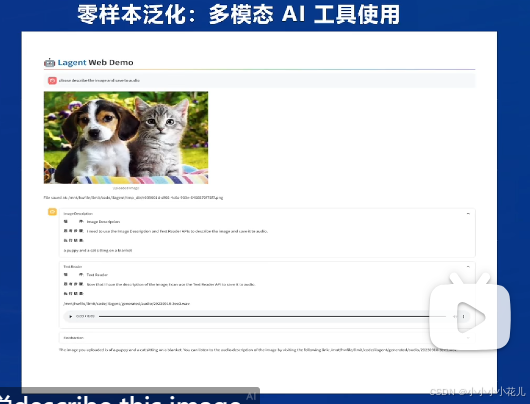
比如要让模型描述这张图片,第一步是调用image description这个插件(一个多模态模型),对图片生成一个描述;以二步使用text reader(文字转语音工具)生成一条语音,实现用语音回复的效果。
HuixiangDou 企业级知识库构建工具

实习生 LM
欢迎来到 InternLM 组织。InternLM 主要由上海人工智能实验室开发。我们不断开源高质量的 LLM 以及用于开发和应用的全栈工具链。
模型
- InternLM:一系列多语言基础模型和聊天模型。
- InternLM-Math:最先进的双语数学推理 LLM。
- InternLM-XComposer:基于 InternLM 的视觉语言大型模型 (VLLM),用于高级文本图像理解和合成。
工具链
- InternEvo:用于大规模模型预训练和微调的轻量级框架。
- XTuner:一个用于高效微调 LLM 的工具包,支持各种模型和微调算法。
- LMDeploy:用于压缩、部署和提供 LLM 的工具包。
- Lagent:一个轻量级框架,允许用户高效构建基于 LLM 的代理。
- AgentLego:一个多功能工具 API 库,用于扩展和增强基于 LLM 的代理,与 Lagent、Langchain 等兼容。
- OpenCompass:一个用于大型模型评估的平台,提供公平、开放和可重现的基准测试。
- OpenAOE:一个优雅且开箱即用的聊天 UI,用于比较多个模型。
应用
- 慧香豆:基于 LLM 的领域专属助手,可以处理群聊中复杂的技术问题。
- MindSearch:一个基于 LLM 的网络搜索引擎多代理框架。

















 2056
2056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









