







前言
该篇文章不像其他文章一般处处细节展开,而是希望从整体层面将整个transformer模型的每一个块彻底连接起来,让你完全明白transformer到底是在做什么。这篇文章更加适合那些了解局部细节却无法把每一个块串联起来的人群,当然对于初学者来说,可以根据这篇文章先从整体建立一个框架,再对小任务逐个击破,因此也十分值得一看。
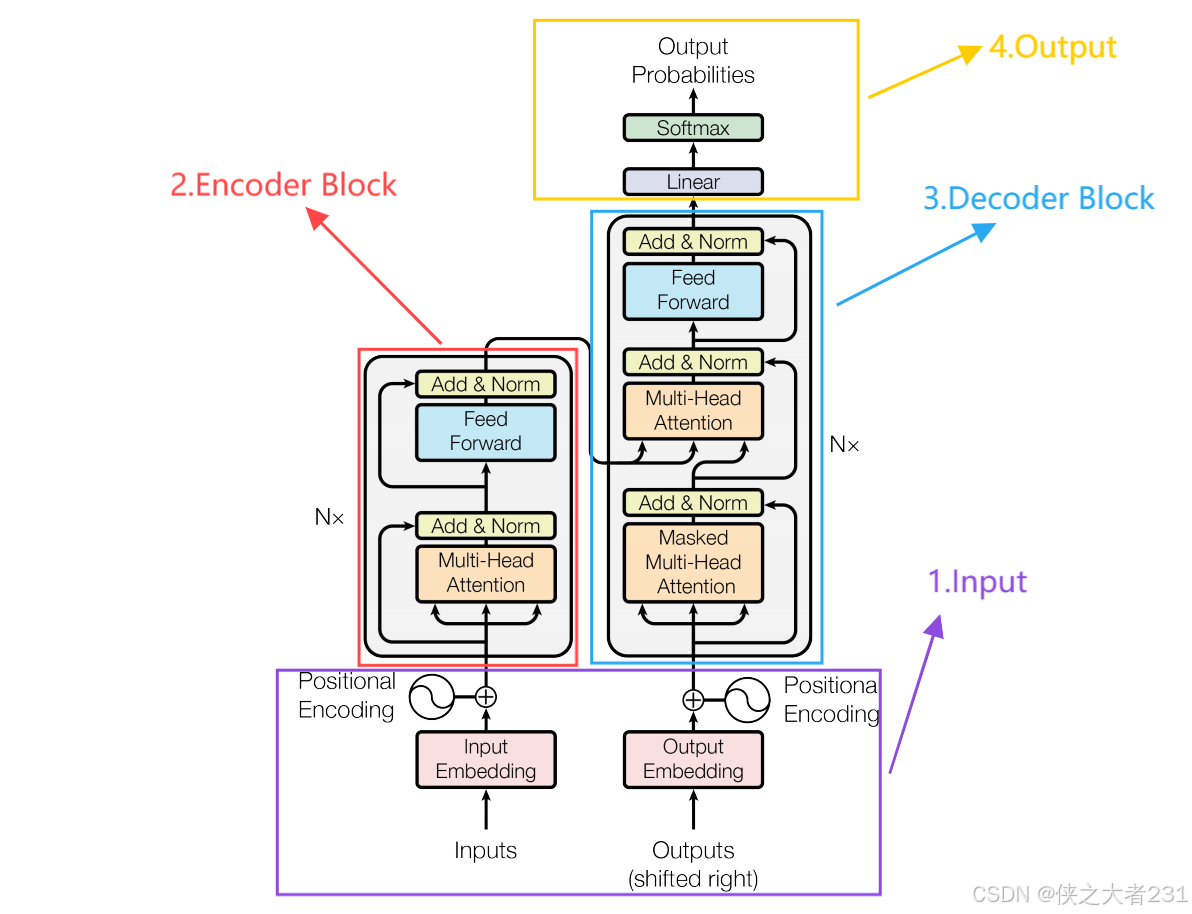
Transformer模型的完整流程图
本文涉及到的专业术语
1.Input Embedding:输入的词嵌入表示(这里也代表原始输入的词嵌入表示)
2.Positional Encoding:位置编码
3.Multi-Head Attention:多头注意力机制(又包括多头自注意力机制和多头注意力机制,这两者的区别在于自注意力机制的q=k=v,而普通注意力机制的q!=k=v)
4.Add:相加(这里代指Residual Connection 残差连接)
5.Norm:归一化(在Transformer中一般为层归一化)
6.Feed Forward:前向传播
7.Masked Multi-Head Attention:使用掩码的多头注意力
8.Linear:线性变换(一般用于改变维度)
9.Softmax:softmax函数
10.dropout:随机丢弃某层神经元的概率
11.Encoder Block:编码器块
12.Decoder Block:解码器块
13.q值:query 查询,是注意力机制运算三元中的一元
14.k值:key 键,是注意力机制运算三元中的一元
15.v值:value 值,是注意力机制运算三元中的一元
Transformer的整体工作流程
(这里我们假设Transformer模型已经构建完毕,为了便于描述这里以机器翻译任务为例,假设要进行中文到英文的转换)
1.数据预处理阶段
首先,用户借助词表将输入的sequence(序列)转变为vector(向量)的形式,再进一步转化为tensor(张量),这里可以用到padding(填充)或者truncation(截断)的方法使一个句子的单词数量保持一致,一般来说最终转变后的形状为(batch_size, sequence_len),代表有多少句子以及每个句子中有多少的单词。
2.词嵌入阶段
然后,用户将输入的tensor利用词嵌入技术获得tensor1,再利用Positional Encoding获得tensor2(注意这里的tensor2不随着模型的更新而更新),将tensor1和tensor2加起来获得input。
Inputs与Outputs的区别
以中文译英文为例,Encoder的Inputs就以中文进行构建tensor,Decoder的Outputs以英文进行构建tensor,这里的Outputs是作为第一个Decoder输入的一部分。
3.Encoder阶段
图中的Encoder Block是一个编码器块,但是真正的Transformer模型是由N个Encoder Block组成,在经典的Transformer中设置了6个Encoder Block。代表中文的tensor进入到第一个Encoder Block中,首先经历Multi-HeadAttension(多头自注意力机制),随后进行Residual Connection(残差连接)和Layer Norm(层归一化),然后经过Feed Forward Network(前馈神经网络),再进行Residual Connection和Layer Norm,到此为止第一个Encoder Block结束。紧接着将输出作为输入再次经过5个相同的Encoder Block,获得真正的编码器的输出。
4.Decoder阶段
对于Decoder来说,同样由6个Decoder Block组成,但与Encoder Block不同的是,每个Decoder Block的输入由两部分组成,第一部分是Encoder的输出作为6个Decoder的输入传入到每个Decoder Block中的第二个Multi-Head Attention当中作为k(key)和v(value)值,第二部分输入对于第一个Decoder Block来说,就是我们前面提到的英文获取的张量,而后面五个Decoder Block的第二部分输入则来自于前一个Decoder Block的输出。
而对于每一个Decoder Block 来说,第一部分输入先进行Masked Multi-Head Attention(使用掩码的多头注意力机制),【在这里使用掩码的作用有两个,一是起到在训练或预测阶段遮挡住当前以及当前之后的token的作用(因为多头注意力机制的每一个token是同时输入的,但是你在进行生成sequence的时候要根据前面已经输入的token进行预测,所以要将当前时刻的token以及之后时刻的token掩盖住,就是通过掩码来实现),二是起到掩盖住填充部分的不必要信息,从而减少不必要的特征的学习,从而提高计算效率。★在训练阶段和预测阶段的处理是不一样的,训练阶段是直接根据每一时刻传入的正确的token进行下一个token的预测,而预测阶段必须是根据之前所有时刻的预测值进行下一个token的预测】然后进行Residual Connection和Layer Norm。紧接着将输出作为q(query)值传入第二个Multi-Head Attention中,配合第二部分Encoder 的输出作为输入并且作为第二个Multi-Head Attention的k和v的值进行计算,计算结束之后再次进行Residual Connection和Layer Norm,然后经过一个Feed Forward Network,再经过Residual Connection和Layer Norm结束第一个Decoder Block。然后相同的事情再重复经过五次,就正式做完了Decoder的任务。
5.Output阶段
之后将Decoder的输出结果丢进一个Linear(线性变换)中,再随之进行softmax获得最终输出,这就是一整个Transformer的工作流程。
6.新手提示
对于想要学习Transformer模型的小白来说,看完我这篇文章后建议先搞懂每个模块的具体内容,后续相关模块的细节内容我也会持续更新,可以通过看其他人博客或者问ai或者线上视频教学的方式,如果你要看视频学习的话对于原理方面我建议你可以听一听Youtube上李宏毅老师对Transformer部分的大体介绍,然后你还可以关注B站up主 Ai大模型奋奋,他发布过一个总时长5小时52分钟的transformer模型基础原理加代码教学,以及一个总时长为3小时38分钟的transformer模型高级进阶教学,看完这些我相信你会受益良多的。
7.结语
这是我第一次正式开始写博客,我也只是一名刚入门的小白,如果哪里有错误的地方还请大方的对我指正,哪里有问题也可以积极与我沟通交流,我的qq是:3125295956。看完这些如果让你感觉受益良多,请不要吝啬你的点赞收藏+关注,之后我也会更新更多前沿ai领域的博客,谢谢!

















 3719
3719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









