







前言
该篇文章承接第一篇文章的内容,将从细节部分致力于将每个Encoder和Decoder部分的每个模块解释清楚,通过这篇文章相信你能彻底理解Transformer中许多重要模块的基本原理。
Transformer完整的流程图
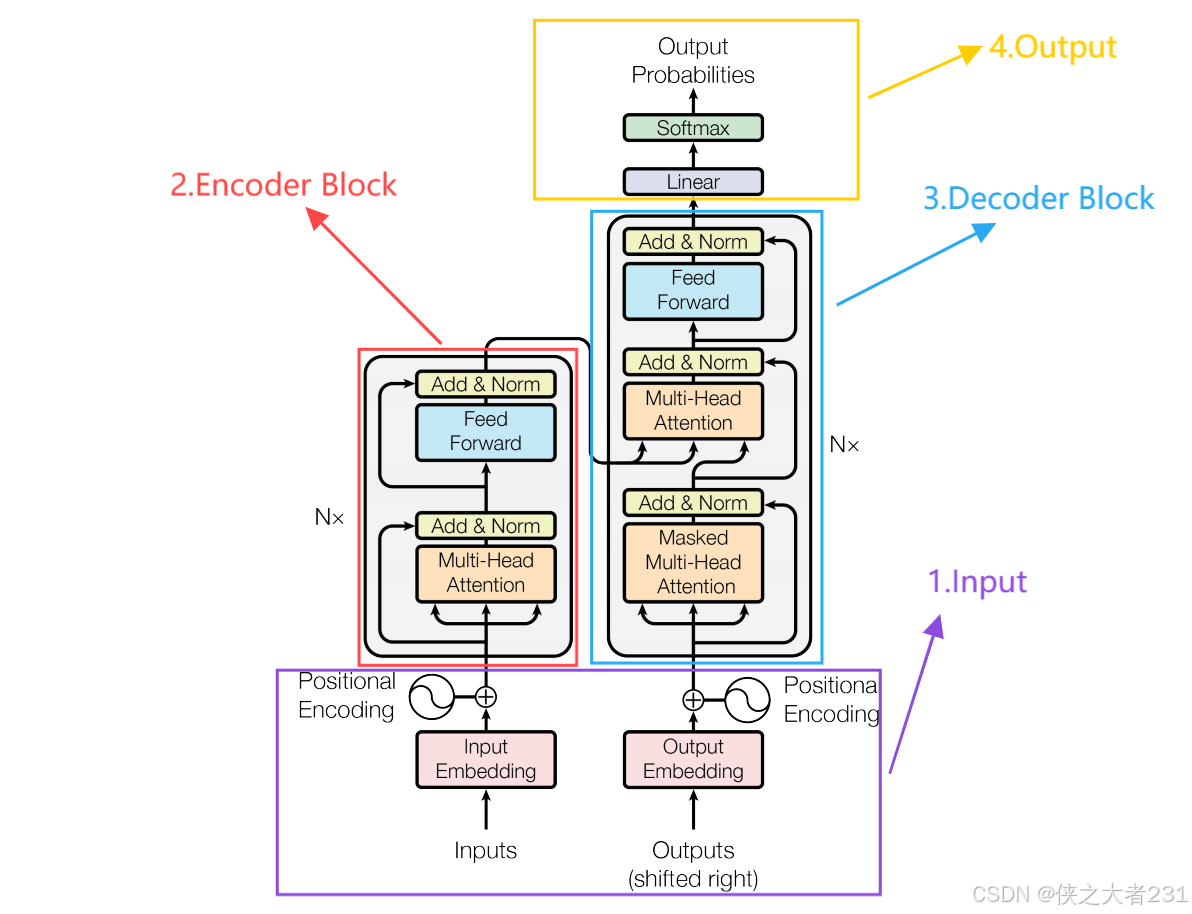
在这篇文章中,我们将致力于解决Encoder Block和Decoder Block的部分,我们将要解决以下问题:1.softmax的原理和计算2.自注意力机制的原理和计算3.多头自注意力机制的原理和计算4.残差连接的原理5.层归一化的原理
细节模块讲解
1. Softmax激活函数的原理和计算
由于在注意力机制的计算中使用到了Softmax激活函数,因此在这里先来简单介绍一下什么是softmax。
1.1 Softmax的计算公式如下
1.2 Softmax的作用
Softmax可以将一系列输出值转化为值域在[0, 1]之间的一系列值,并且这些值的加和为1。因此我们可以把softmax处理后得到的一系列值看作是概率,而softmax后的值越接近1,则代表概率越大,在分类任务中则代表越有可能属于这一类,因此我们经常能够在最后的输出层看到Softmax的身影。
1.3 Softmax在Encoder中的核心作用
在计算自注意力机制的过程中会用到Softmax激活函数,这里阐述一下其在注意力机制中所发挥的作用。
1.31 归一化注意力权重
-
概率分布特性:softmax将实数分数转换为概率分布([0,1]区间,总和为1),明确每个位置对其他位置的影响程度。
-
示例:若输入为句子,softmax能突出语义相关的词(如动词与主语),抑制无关词。
1.32 动态聚焦重要信息
-
指数放大效应:softmax的指数运算会放大高分值,抑制低分值,使模型更关注强相关的位置。
-
示例:在句子“The animal didn’t cross the street because it was too tired”中,softmax会让“it”更关注“animal”而非“street”。
1.33 支持长距离依赖
-
全局交互:无论位置远近,softmax允许模型直接计算任意两个位置的相关性,克服了RNN的序列依赖限制。
-
示例:捕捉段落中首尾呼应的关键词,无需逐步传递信息。
2. 自注意力机制的原理和计算
2.1 注意力机制的计算公式
其中Q代表query(查询),K代表key(键),V代表value(值),代表K的转置,
代表最后一维的维度(特征维度)。
2.2 注意力机制的计算原理
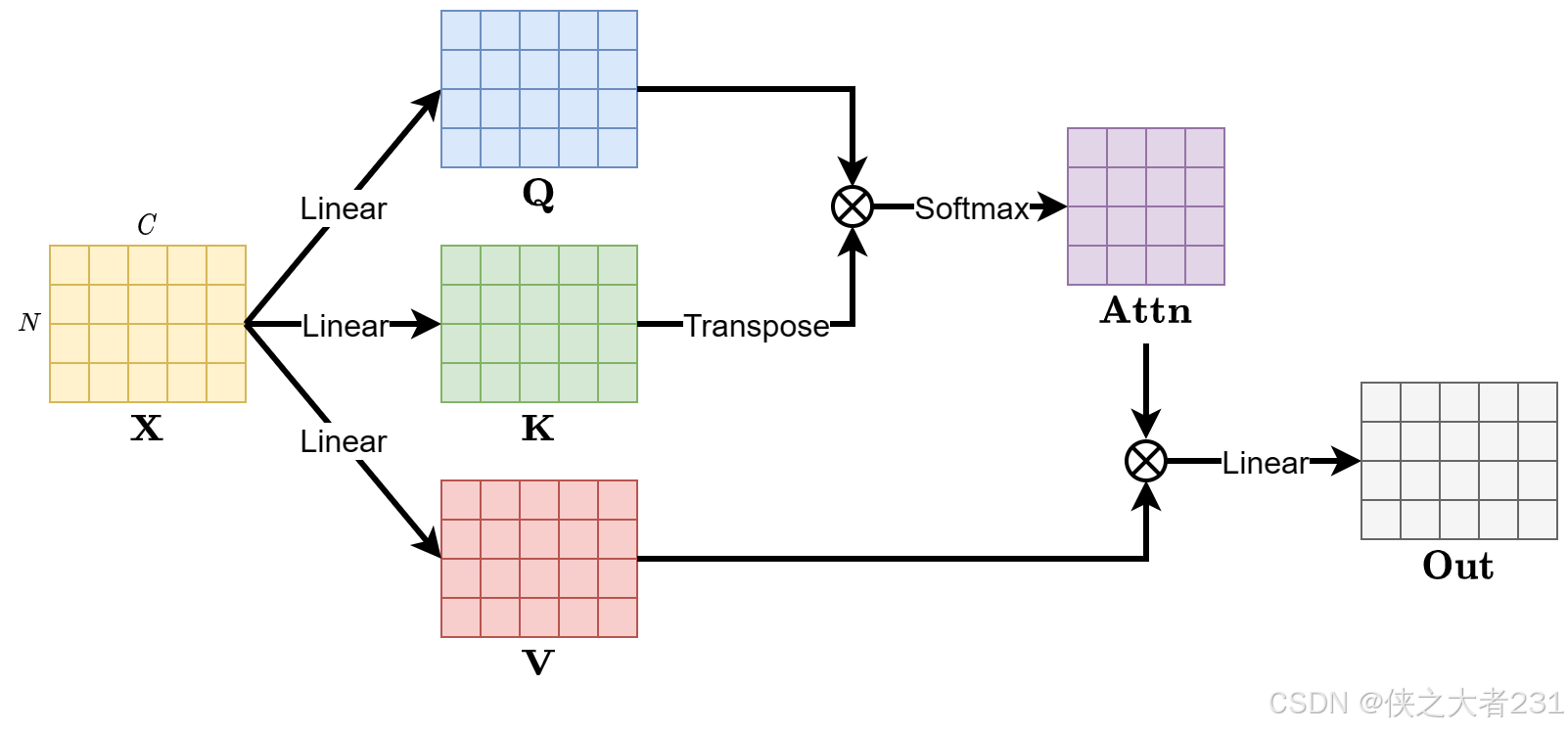
我们以这张图为例,X是一个4行5列的输入,然后X分别经过三个线性层变为Q,K,V,这里Q,K,V的形状并没有发生改变,我们可以判断这里的Linear应该是一个方阵,这三个Linear从上至下我们可以分别看作,
和
三个权重矩阵,通过这三个权重矩阵将输入X分别映射为Q,K,V,随后Q和
进行矩阵乘法运算再进行Softmax处理获得Attention Score,也就是Attn矩阵,Attn矩阵再与V进行矩阵乘法,随后通过一个Linear线性层获得最后的输出Out,这就是注意力机制的整个运算流程。自注意力机制呢则是在此基础上要求初始化的Q,K,V相同,即Q=K=V,而普通的注意力机制没有此要求,也就是满足K=V即可,Q无需与其相同。(在这里整个讲解过程我都是直接用的矩阵的形式来进行讲解,而实际的运算过程也是于此相同。我并没有拿出一个单独的样本进行讲解,这是因为那样之后即使听懂也很难以自行回归到矩阵计算。矩阵计算你可以理解为数学层面的“并行”计算,他虽不是真正的并行计算,却能起到和并行计算近似的作用)
2.3 关于注意力机制的计算公式中为什么要除以 的问题的回答
的问题的回答
相信不少朋友们对此是存在异或的,这里我从两个角度进行解答。
1. 直观感受角度:当越大时即最后一维的维度越大时,就会造成
的值越大,体现为方差变大,一旦如此再经过Softmax函数的作用会进一步放大更大的部分,从而可能会出现一个值为1,其他值几乎完全不起作用的情况,显然这不是我们想要的,因此除了一个
来解决这个问题。
2.严禁数学角度:我们可以把Q和K看作相互独立的服从标准正态分布的随机变量,那么根据概率统计的知识我们不难发现就服从均值为0,方差为
的正态分布,而我们希望在这个过程中的方差保持不变,因此我们需要对每个随机变量同时除以
来消除掉方差的影响。
3. 多头自注意力机制的原理和计算
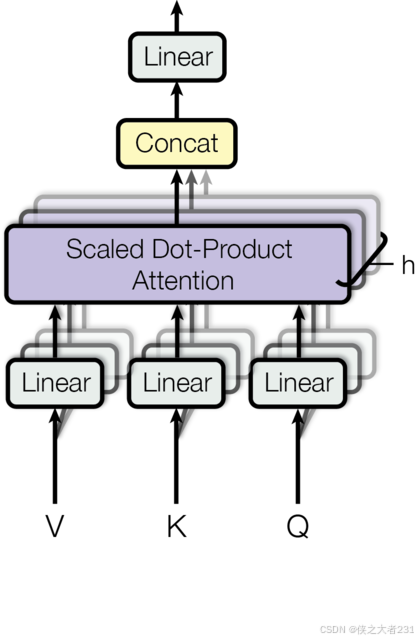
3.1 多头注意力机制图
3.2 多头自注意力机制的计算原理
Multi-Head Attention总体计算原理和Self Attention基本一样,唯一不同点在于Multi-Head Attention引入了head(头),通常head设置为8(12,16也可,具体情况具体分析),他的作用是将Self-Attention中提到的(词嵌入维度)均分,然后进行并行计算,每一个head都是相互独立的,其他计算于Self-Attention没有区别。
3.3 多头自注意力机制的优势
3.31 捕捉多样化依赖模式
-
单头局限性:单头自注意力只能学习一种全局的注意力模式(例如全局关注动词与主语的关联)。
-
多头优势:每个头可独立关注不同的语义或语法关系,例如:
-
一个头捕捉长距离依赖(如段落首尾呼应)。
-
另一个头捕捉局部结构(如短语内部的修饰关系)。
-
其他头可能关注词性或句法角色。
-
3.32 计算效率优化
-
并行计算:多个头的计算可并行化,充分利用GPU/TPU的硬件加速能力。
-
维度分解:通过将
(
) 分解为多个低维子空间(
),在保持总计算量相近的前提下,提升特征多样性。
3.33 增强模型鲁棒性
-
冗余性:多个头的并行计算引入冗余性,避免模型过度依赖单一注意力模式。
-
抗噪能力:即使某些头因噪声失效,其他头仍能提供有效信息。
4. 残差连接(Residual Connection)的原理
4.1 为什么需要残差连接
在深度神经网络中,随着层数的增加,网络的性能在一定程度上会提高。然而,深度网络的训练也面临着一些挑战,其中之一是梯度消失或梯度爆炸的问题。当反向传播过程中的梯度变得非常小或非常大时,网络的参数更新会受到影响,导致训练变得困难。
4.2 残差连接的思想
残差连接的核心思想是引入一个"shortcut"或"skip connection",允许输入信号直接绕过一些层,并与这些层的输出相加。这样,网络不再需要学习将输入映射到输出的完整函数,而是学习一个残差函数,即输入与期望输出之间的差异。假设一个层的输入为 x,输出为 F(x),那么该层的残差连接可以表示为:
4.3 残差连接的作用
4.31 解决梯度消失/爆炸问题
-
问题背景:在深层神经网络中,梯度在反向传播时可能因多次链式求导而急剧缩小(消失)或增大(爆炸),导致浅层参数难以更新。
-
残差的作用:
-
梯度直通:残差连接允许梯度直接通过跳跃路径回传,绕过了复杂的非线性变换层,减少了梯度逐层传递的衰减。
-
稳定训练:即使某些层的梯度趋近于零,跳跃连接仍能保留有效的梯度信号,确保深层网络的稳定训练。
-
示例:ResNet-152(152层)通过残差连接成功训练,而普通CNN在20层以上就可能因梯度消失无法收敛。
4.32 允许构建更深的网络
-
深层网络的表达能力:网络越深,理论上能学习更复杂的特征,但实际中普通深层网络因训练困难而性能下降(退化问题)。
-
残差的作用:
-
退化问题缓解:残差块让网络更容易学习“恒等映射”(即输出等于输入),即使新增层无效,也不会比浅层网络更差。
-
突破深度限制:ResNet通过残差连接构建了超过1000层的网络,显著提升了模型容量。
-
示例:ImageNet比赛中,ResNet-152的错误率(3.57%)远低于VGG-19(7.3%),证明了深度的优势。
4.33 促进特征复用与信息流动
-
低层次特征保留:浅层网络提取的细节特征(如边缘、纹理)在深层可能被丢失,残差连接通过跳跃路径保留这些信息。
-
残差学习的本质:网络只需学习输入与输出的差异(残差 F(x)=H(x)−x),而非直接拟合复杂映射 H(x),简化了学习目标。
示例:在图像分割任务中,跳跃连接(如U-Net)将浅层的细节特征与深层的语义特征融合,提升分割精度。
4.34 提升模型鲁棒性
-
冗余性增强:多个残差路径提供了信息传递的冗余通道,即使某些路径失效,其他路径仍能维持网络功能。
-
抗噪能力:输入信号通过残差连接直接传递,减少了噪声在多层变换中的累积效应。
4.4 残差连接在transformer中的作用
Transformer模型中的每个子层(自注意力层、前馈网络)均采用残差连接,其结构为:
Output=LayerNorm(x+Sublayer(x)) ★Sublayer(子层的意思)
-
作用:
-
缓解深层Transformer的训练不稳定问题。
-
允许注意力机制专注于学习输入序列的交互关系,而跳跃连接保留原始位置信息。
-
示例:GPT-3(1750亿参数)依赖残差连接实现超深层的稳定训练。
5. 层归一化(Layer Norm)的原理
5.1 Layer Normalization的定义
Layer Normalization 的目标是在神经网络的每一层中,对该层所有神经元的激活值进行归一化。具体来说,LayerNorm 将每一层的激活值转换为均值为 0、标准差为 1 的分布,然后对结果进行缩放和偏移。
计算公式为
其中为均值,
为标准差。假设H为该层神经元的个数,
是一个非常小的正数(用来防止除0错误),则有
经过归一化后,每个归一化后的激活值会进行缩放和偏移操作,以保持模型的表达能力。这个过程通过引入可学习的参数
和
来完成:
其中:
是缩放系数,用于控制归一化后的尺度(可学习)
是偏移系数,用于控制归一化后的位移(可学习)
5.2 Layer Norm 的核心作用
5.21 稳定特征分布,缓解内部协变量偏移(Internal Covariate Shift)
5.22 加速模型收敛
-
梯度优化平滑化:归一化后的特征分布更稳定,使得优化器(如Adam)更容易找到梯度下降方向。
-
降低对初始化和学习率的敏感度:归一化后的参数尺度一致,减少超参数调优难度。
5.23 缓解梯度消失/爆炸
-
梯度传播稳定性:归一化操作限制了激活值的范围,避免深层网络中梯度因数值过大或过小导致的不稳定。
5.24 适配变长序列数据(如Transformer)
-
与Batch Norm的区别:
-
Batch Norm在批量维度归一化,对序列长度敏感,不适合变长输入(如NLP任务)。
-
Layer Norm在特征维度归一化,独立处理每个样本,完美适配变长序列。
-
5.3 Layer Norm在Transformer中的具体应用
在Transformer的Encoder/Decoder中,Layer Norm通常与残差连接结合,形成以下两种结构:
5.31 Post-Norm(原始Transformer设计)
Output=LayerNorm(x+Sublayer(x))
-
特点:先执行残差连接,再进行归一化。
-
优势:确保输入到下一层的分布稳定。
-
缺点:深层训练可能不稳定(需配合较小的初始化和精细调参)。
5.32 Pre-Norm(现代改进版)
Output=x+Sublayer(LayerNorm(x))
-
特点:先归一化,再执行子层计算和残差连接。
-
优势:训练更稳定,适合极深层模型(如GPT-3)。
-
缺点:理论收敛性略弱于Post-Norm。
6.结语
到此为止,我的第二篇关于Transformer细节模块介绍的讲解也是彻底结束了,利用这篇博客结合上篇博客相信大家应该可以把Transformer架构基本搞清楚啦!还是欢迎各位朋友们积极为我指出错误,若想与我本人深入探讨还请加q:3125295956。
如果你觉得这篇博客对你很有帮助,请不要吝啬点赞👍收藏+关注,你们的三连是我继续前进的动力!

















 2531
2531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









