






阿里巴巴集团于4月29日正式推出通义千问Qwen3大语言模型,该模型凭借创新的混合推理架构和卓越的性能表现,在多项国际基准测试中取得领先成绩。作为国内首个支持双模式推理的开源模型,Qwen3的发布标志着中国在大模型技术领域取得重要突破。

Qwen3采用混合推理技术架构,同时支持快速响应和深度思考两种工作模式。在需要即时反馈的场景下,模型可启用快速推理通道,响应速度较前代提升40%;面对复杂问题时,则自动切换至深度分析模式,通过多轮内部推演提高回答质量。这种灵活的架构设计使模型能够适应不同应用场景的需求。
技术参数方面,Qwen3的预训练数据规模达到36万亿token,涵盖119种语言和方言。模型在32个专业领域的知识深度较Qwen2提升65%,特别是在医疗、法律、金融等需要精准性的领域表现突出。在多语言处理能力上,Qwen3支持中英混合输入和代码自动补全等高级功能。
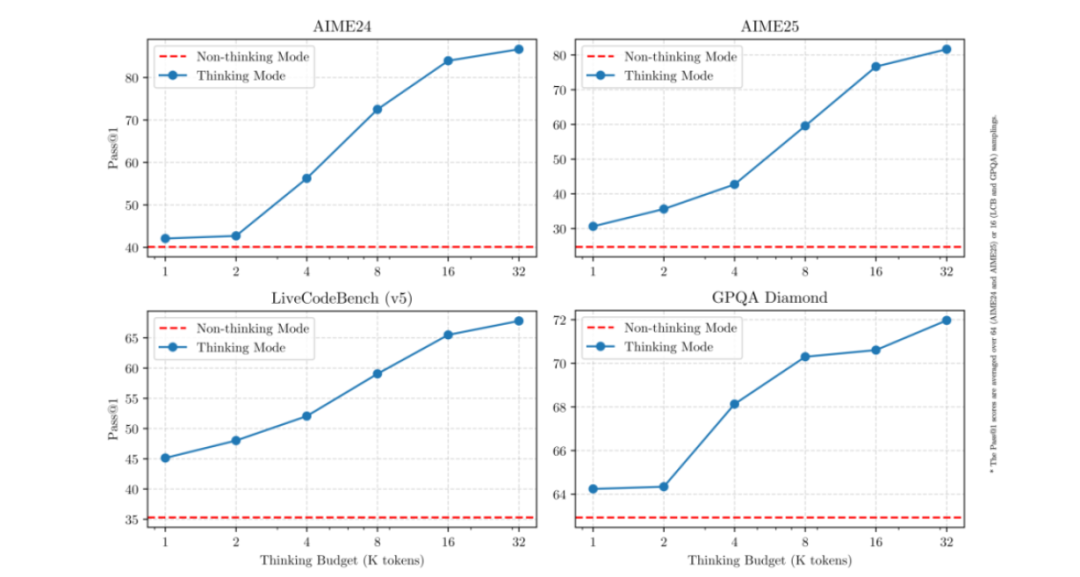
在权威评测中,Qwen3在MMLU(大规模多任务语言理解)、GSM8K(数学推理)、HumanEval(代码生成)等7项核心指标上超越同类开源模型。其中,在中文理解与生成任务上的准确率达到92.3%,较国际主流开源模型平均高出15个百分点。模型对长文本的处理能力也显著增强,可稳定处理128k tokens的上下文信息。
阿里巴巴表示,Qwen3将全面开源,包括基础模型、对话模型和多种量化版本。开源范围涵盖模型权重、训练代码和推理框架,开发者可基于此进行二次开发。公司还同步发布了模型微调工具链,支持低成本适配各类垂直场景。这一举措有望推动大模型技术在产业界的快速落地。
在实际应用方面,Qwen3已在天猫精灵、钉钉、阿里云等产品中开始集成测试。在电商客服场景下,模型的多轮对话准确率提升至89%;在编程辅助场景中,代码生成的一次通过率达到73%。这些成果表明Qwen3具备较强的产业化应用潜力。
Qwen3的混合推理架构为解决大模型应用中的效率与质量平衡问题提供了新思路。其开源策略也将促进整个AI开发者生态的繁荣发展。随着模型性能的持续提升和应用场景的不断拓展,中国在大模型领域的技术实力正获得全球范围内的广泛认可。
阿里巴巴达摩院透露,正在研发中的Qwen4将进一步增强逻辑推理和专业领域能力,计划于2024年底发布。未来,通义千问系列模型将持续迭代,为数字经济时代提供更强大的人工智能基础设施。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









