






一、关于YOLO
1、什么是YOLO
YOLO(You Only Look Once)是一种基于深度学习的目标检测算法,由Joseph Redmon等人于2016年提出。它的核心思想是将目标检测问题转化为一个回归问题,通过一个神经网络直接预测目标的类别和位置,例如下图所示。

YOLO算法将输入图像分成SxS个网格,每个网格负责预测该网格内是否存在目标以及目标的类别和位置信息。此外,YOLO算法还采用了多尺度特征融合的技术,使得算法能够在不同尺度下对目标进行检测。
关于不同尺度:例如在ResNet残差网络中,无论是18层的还是36层的,他们的输入图像的尺寸都是固定不变的,不能传入不同尺寸的图像,而YOLO算法可以传入任意大小的图片,对其进行检测。
相比于传统的目标检测算法,如R-CNN、Fast R-CNN和Faster R-CNN等,YOLO算法具有更快的检测速度和更高的准确率,这得益于其端到端训练方式和单阶段检测的特性,使其可以同时处理分类和定位任务,避免了传统方法中的多阶段处理过程。因此,YOLO算法广泛应用于实时目标检测和自动驾驶等领域。
关于端到端:
端到端的训练是模型直接从原始输入数据学习如何映射到最终的输出目标,而不需要在中间阶段进行人为的特征工程或分割成多个独立的处理模块。例如,以前的汽车自动驾驶,通过车上搭载的摄像头拍摄实时画面,将获取到的画面每一帧图像传入模型进行识别,然后对模型的输出结果进行判断,判断是哪种类别,是否需要减速转向,然后再执行相应的减速转弯等操作,二当前端到端的训练,摄像头的事实画面帧传入模型后,经过检测后直接执行减速转向灯的操作。
2、经典的检测方法
1)one-stage单阶段检测
YOLO系列、SSD

单阶段检测指在目标检测任务中,通过一个网络模型直接预测出物体的类别和位置。
优点:识别速度非常快,适合做实时检测任务
缺点:正确率相对two-stage较低,尤其在小物体和严重遮挡的情况下性能较差。
模型指标介绍:

mAP指标:用于评判目标检测效果,其值越大越好,在机器学习的分类任务
FLOPS:表示模型进行一次前向传播(即处理一张图像)所需要的浮点运算次数。它是一个衡量算法效率的关键指标,与模型的计算量和推断速度密切相关。
FPS:每秒可以处理的图像数量
2)two-stage多阶段检测
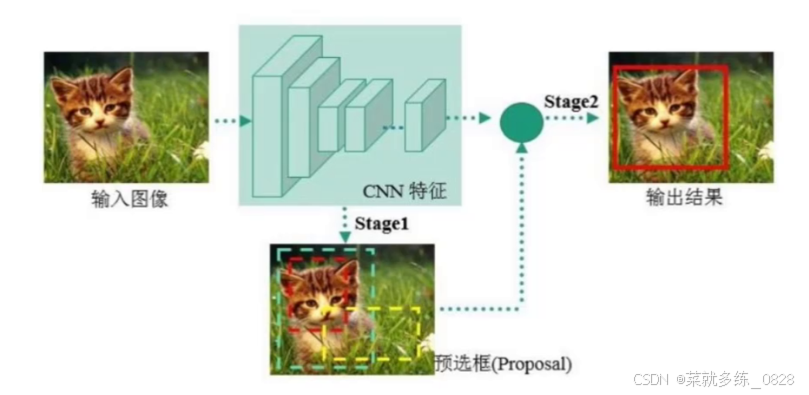
Faster-rcnn和mask-Rcnn系列
两阶段目标检测器是一种先生成候选框,然后对候选框进行分类和回归的检测方法。这种方法主要包括两个阶段:
第一阶段:生成候选框。这通常通过一个类似于Selective Search或EdgeBoxes等区域提名算法来实现,该算法从输入图像中生成多个候选框。每个候选框都会经过一个CNN模型进行特征提取,然后通过分类器进行过滤,保留与目标物体更相似的候选框。
第二阶段:在保留的候选框上进行精细的分类和回归。这个阶段通常使用另一个CNN模型或类似SVM的分类器来进行分类和回归。对于每个候选框,可能需要预测物体的类别、位置和大小等。 代表性的两阶段目标检测器包括R-CNN系列,以及其改进版本Fast R-CNN、Faster R-CNN和Mask R-CNN等。
优点:正确率比较高,识别效果理想
缺点:识别速度比较慢,通常达到5FPS
二、关于mAP指标
1、概念
mAP(mean Average Precision)是用来评估目标检测算法性能的常用指标之一。它结合了目标检测算法的准确率和召回率,并考虑了不同类别之间的差异。
准确率是指预测为该类别的样本中,被正确分类的比例。召回率是指该类别中被正确分类的样本数与该类别总样本数的比例。
2、IOU
IOU用于评估预测框与真实目标框之间的重叠程度,即计算预测框和真实目标框的交集面积除以它们的并集面积来进行计算。

3、关于召回率和准确率
1、召回率:预测的结果是真的有多少是预测正确的
2、准确率:真实的结果中有多少是预测正确的

4、计算mAP
根据不同的阈值(置信度),绘制出召回率和精确率的曲线,将曲线以下的面积作为MAP值。当MAP值越大,则表示指标越好 。

三、YOLO v1网络架构 、损失值、NMS极大值抑制
一、Yolo系列v1
1、核心思想
将一幅图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。YOLO v1将图像分为7*7个网格
2、示例

对于上图,YOLOv1将输入图片划分成7×7的网格,每个网格允许预测出2个边框(bounding box),这些边框的大小可以超出当前网格的范围,对于每个边框,YOLOv1都预测了5个参数,分别是中心坐标(x, y)、宽度w、高度h以及置信度confidence。置信度反映了模型对边框内包含物体的信心程度以及边框的准确度。
3、流程图解析

YOLOv1的网络结构主要由卷积层、池化层以及最后的全连接层组成。
网络的输入是448x448x3的彩色图片,输出是7x7x30的张量(tensor)。
7x7表示将输入图片划分成了7*7个网格(grid),每个网格负责检测其内的物体。
30表示每个网格内的30个预测信息,包括20个类别概率(以PASCAL VOC数据集为例,该数据集共20个类别)、2个预选框(bounding box)及其置信度(每个边界框包含中心点坐标x、y,宽度w、高度h以及一个置信度分数)。

坐标点x,y(相对于网格单元格边界的框的中心)用对应网格的归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。
二、YOLO系列v1损失函数
1、位置误差
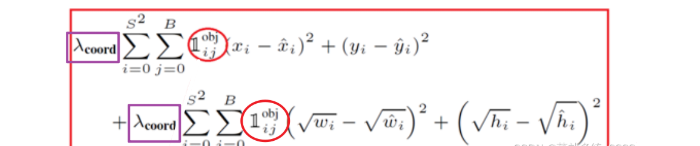
如上图所示,其为位置误差的计算公式,其中对应的值为一个系数,表示如果你觉得位置误差更重要,那么就设置大一点,置信度误差与分类误差也是同样的意思
第二个红框内的符号表示第i个网格的第j个预选框,如果负责预测物体,那么整体的值为1,反之为0
前面的求和符号s平方表示网格的格式,例如YOLO v1中的网格个数为7*7,然后B表示预选框的个数,此处数值为2,后面的x表示预选框的中心点的坐标x,y,以及预选框的宽w、高h。
2、置信度误差


的值所表示的意思和上述一致,但是第二个像阿拉伯数字1noobj的符号,其所表示的值和上述位置误差中的相反,此处表示第i个网格,第j个预选框,如果不负责预测物体,那么他的值为1,否则为0,
C的表示置信度的值,置信度C的值 = Pr类别概率 * IOU
类别概率表示边界框(预选框)内存在对象的概率,若存在对象则为1,不存在则为0,IOU为预测的位置框和真实值的框相交集的值除以并集的值的大小。
Ci表示模型预测出来的置信度的值,C^i的值表示实际计算得到的置信度的值
3、类别概率损失

这里第一个求和符号后面的小符号,表示第i个网格是否包含物体,如果包含,那么其值为1,否则为0
pi(C)-p^i(C)表示预测的类别的概率减去真实标签的概率,例如模型输出20类别的结果,即有20个数据,其中有预测到狗的概率,加入标签打的是狗,只需要将20个数据中预测狗额概率的值取出来,然后减去1,在对结果平方即可
三、NMS非极大值抑制
1、概念
在目标检测过程中,通常会生成大量的候选框,当前v1版本有2个复选框,这些候选框可能会有重叠或者包含关系。为了减少重叠的候选框,避免重复检测同一个目标,使用非极大值抑制可以筛选出最佳的目标框。

例如上图中,同一个人脸被多个预选框预测出来,导致了预选框的重叠,此时可以将置信度低的抑制了,只保留最大的那个。
2、步骤
1)对所有的候选框根据某个评分指标(例如置信度得分)进行排序,得到一个有序列表;
2)选择评分最高的候选框,并将其添加到最终的目标框列表中;
3)计算当前选择的候选框与其他未选择的候选框的重叠区域,并计算重叠区域与两个候选框面积的比值;
4)如果重叠区域与两个候选框面积的比值超过了设定的阈值,则将该候选框从列表中移除;
5)重复步骤2~4,直到所有的候选框都被处理完毕。
四、YOLO v1优缺点
1、优点
1)速度快
YOLO v1的设计初衷就是实现实时目标检测,相较于其它目标检测算法如R-CNN和SSD,YOLO v1在保持较高准确率的同时,能够达到更快的检测速度,每秒处理上百张图片。
2)端到端
YOLO v1是一个端到端的算法,它将目标检测任务作为一个单一的回归问题进行处理,通过在全局上直接预测目标的类别和位置,避免了复杂的后处理步骤。
3)多尺度预测
YOLO v1在训练和测试阶段都会对不同尺度的图像进行处理,通过将输入图像划分为网格单元,并生成边界框,确保对不同尺度的目标能够进行有效的检测。
4)网络结构简单
YOLO v1的网络结构相对简单,由24个卷积层和2个全连接层组成。这种端到端的网络结构使得YOLO v1易于实现和部署。
2、缺点
1)对小目标检测效果差
由于输入图像大小为448x448,而输出特征图大小为7x7,因此YOLO v1在下采样过程中会丢失大量小目标的特征信息。这导致YOLO v1对小目标的检测效果不理想,容易出现漏检或误检的情况。
2)每个网格只能生成两个框,且只能预测一个类别
这一限制使得YOLO v1在处理多类别、多目标的情况时存在一定的局限性,例如图像重叠时,无法预测
五、YOLO系列v2 网路构架解析
一、YOLO系列v2
1、YOLO v1与v2对比

2、BatchNorm批次归一化
V2版本舍弃Dropout(抛弃神经元比例),卷积后全部加入BatchNormalization,网络的每一层的输入都做了归一化,经过卷积后输出特征图,特征图输出到下一层卷积,收敛相对更容易,经过Batch Normalization处理后的网络会提升2%的mAP,从现在的角度来看,Batch Normalization已经成网络必备处理
3、YOLO v2 更大的分辨率
V1训练时用的是224*224,测试时使用448*448,可能导致模型水士不服
V2训练时额外又进行了10次448*448 的微调使用高分辨率分类器后,YOLOv2的mAP提升了约4%
4、YOLO v2网络结构
1)YOLO v2网络结构
不在和YOLO v1一样使用GoogLeNet网络,而是使用DarkNet网络,实际输入416*416大小的图片,其没有fc全连接层,经过5次降采样,得到大小为13*13,

2)传统的卷积神经网络系统
在前面学习的卷积神经网络中,如下图所示,当输入一张图片大小为224*224,经过卷积核处理后,得到的特征图再次进行卷积,到最后的全连接,可以发现,全连接前特征图大小为128*13*13,此时想要经过全连接得到2048个结果需要的权重参数w的个数为128*13*13*2048个,这个数目非常庞大,此时如果传入其他大小的图像,这个权重参数则无法对其进行更新,因为不同大小的输入图片对应输出的特征图大小都是不一样的,这就导致全连接时的权重参数个数都是不同的,所以针对不同尺度的图像,这个卷积神经网络的系统则无法进行处理。

此时再回头可以看到YOLO v2的网络结构,其没有全连接层,只有最后一步的Avgpool全局平均池化,此时对输出的不同大小的特征图都进行同样的处理,使其返回1000个结果,然后通过softmax计算每个类别的概率,那么,无论传入多大的图片,最终的结果都是一样的,以此来实现多尺度的输入。
YOLO v2结构局限性
输入图片的大小有所局限,因为该网络结构经过5次降采样,所以输入图片的大小必须是32的倍数
5、YOLO v2聚类提取先验框
YOLO v1的预选框有2个,而YOLO v2则有5个预选框,预选框越多找到的目标就越精确,但是算力越多,faster-rcnn系列一共有9种预选框,这9种分为3类,每个类别大小不同,类别内的比例不同(每个类,1:1、2:1、1:2)。
YOLO v2使用K-means聚类算法来提取先验框。K-means是一种无监督学习算法,用于将数据点分为K个不同的簇,以便找到数据的聚类结构。
YOLO v2中假如有100万张图片,需要对其进行训练,每个图片都有标记框,此时有起码100万个标记框,每个标记框都有其高宽的信息,那么将这个w宽和h高当做成一个坐标(w,h),即表示每个框的信息,然后使用k-means对其进行聚类,以此来区分
1)k-means聚类
k-means聚类(如下所示)中的距离:d(box,centroids) = 1-IOU(box,centroids),之前用的是欧氏距离,而yolo v2使用1-交并集比值的大小来将其当做距离。

YOLO v2聚类流程
在模型训练之前,提前把训练集的标签值提取出来,通过k-means聚类的方法,聚类出5个类别,然后计算平均值,将其结果当作是先验框。 最后在进行模型训练。
YOLO v2聚类框个数由来

6、YOLO v2 Anchor Box聚类先验框
通过引入聚类先验框,使得预测的box数量更多(13*13*n),跟faster-rcnn系列不同的是,先验框并不是直接按照长宽固定比给定


















 4547
4547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









