






近日,Gartner 发布了如何利用Microsoft Fabric 构建你企业的大数据治理架构。
一、背景
在当今复杂且不断发展的数据格局中,组织正努力构建一个统一且集成的数据生态系统。数据架构师需要评估、设计和实施一个统一、可扩展且协作的数据管理架构,而 Microsoft Fabric 作为一种预集成的 SaaS 平台,为这一目标提供了新的可能。
二、关键挑战
-
技术选型与整合 :Microsoft Fabric 从独立的 PaaS 服务发展为统一的 SaaS 平台,整合了数据管理和分析工具。然而,它与 Azure Synapse Analytics 和 Azure Databricks 等服务存在功能重叠,组织需要确定这些服务是互补的,还是应该完全迁移到 Microsoft Fabric。此外,随着技术的不断更新,组织需要评估是否应将 Microsoft Fabric 作为独立平台部署,还是仅利用其特定组件,或者探索其他替代方案。
-
数据治理与合规性 :Microsoft Purview 提供广泛的数据治理能力,而 OneLake 目录则专注于 Fabric 环境内的数据发现和血缘关系。多种治理方法可能导致管理员的困惑,因此需要清晰的指南来简化管理。同时,组织必须确保数据管理架构能够满足数据质量、监管合规等要求,以支持业务目标。
-
架构设计与实施 :组织需要根据自身业务需求、用例和现有数据架构来设计数据管理架构。这涉及到考虑集成复杂性、可扩展性、易用性、成本和敏捷性等因素。此外,如何在 Microsoft Fabric 中实现数据的存储、处理、访问、交付等功能,以及如何与其他 Microsoft 服务(如 Azure、Power BI 和 Microsoft 365)进行无缝集成,也是需要解决的挑战。
-
数据存储与管理 :OneLake 作为 Microsoft Fabric 的统一存储层,支持多种数据类型,但在数据存储、访问和管理方面仍存在一些限制,如数据镜像和快捷方式的可用性有限,以及与某些数据库和数据源的集成尚不完善。
-
数据处理与分析 :Microsoft Fabric 提供了多种数据处理工具,如 Data Factory、Fabric Data Engineering、Fabric Data Science 和 Real-Time Intelligence 等。然而,这些工具在功能和性能方面仍存在一些局限性,如 Dataflow Gen2 的某些限制、Fabric Data Warehouse 对特定数据格式的支持有限等,可能影响组织对数据的处理和分析能力。
-
数据访问与交付 :确保数据能够安全、高效地被访问和交付给不同的用户和应用程序是一个关键挑战。Power BI 作为 Microsoft Fabric 的主要数据交付工具,虽然功能强大,但也存在一些限制,如语义模型的编辑和数据类型映射问题等。
-
DataOps 实践 :DataOps 是一种敏捷且协作的数据管理实践,旨在提高数据流的沟通、集成、自动化、可观测性和操作性。在 Microsoft Fabric 中,Data Factory 是主要的 DataOps 工具,但它在版本控制、CI/CD 等方面的能力有限,需要与 Git 等外部工具集成。
-
数据治理与元数据管理 :有效的数据治理和元数据管理对于确保数据的准确性、一致性和安全性至关重要。Microsoft Purview 和 OneLake 目录提供了数据治理和元数据管理功能,但在实际应用中可能存在一些局限性,如 DLP 策略的适用范围有限、用户对敏感信息标签的主动应用等。
三、方案建议
-
全面评估业务需求和技术能力 :组织应深入分析自身的业务需求、现有数据架构和未来用例,以确定 Microsoft Fabric 是否能够满足其数据管理要求。同时,评估组织内部的技术能力和资源,以确保能够有效地实施和管理 Microsoft Fabric 解决方案。
-
采用混合架构策略 :根据组织的具体情况,可以考虑采用统一模式或混合模式来实施 Microsoft Fabric。在统一模式下,将所有数据层(青铜、银和金)都包含在 Microsoft Fabric 生态系统中,适合主要用例为仪表盘、报告和分析,且已有投资于 Azure 服务的组织。而在混合模式下,青铜和银层位于外部平台或数据库中,金层存储在 Microsoft Fabric 的 OneLake 中,适用于希望利用现有专有数据湖仓产品的组织。
-
加强数据治理和合规性管理 :制定清晰的数据治理策略,明确数据政策、所有权和管理流程。利用 Microsoft Purview 和 OneLake 目录等工具,加强数据发现、分类、保护和合规性管理。同时,提供充分的培训和指导,确保用户能够正确地应用敏感信息标签和遵循数据治理政策。
-
优化数据存储和处理流程 :合理规划数据在 OneLake 中的存储和管理,利用其统一存储层的优势,减少数据重复和移动。根据数据的特点和分析需求,选择合适的存储格式和处理引擎,如 Delta Lake 格式和 Apache Spark 计算引擎,以提高数据处理的效率和性能。
-
提升数据处理和分析能力 :深入了解 Microsoft Fabric 提供的各类数据处理工具的功能和限制,并根据实际需求进行合理选择和组合使用。例如,在数据集成方面,利用 Data Factory 的数据流和数据管道功能;在数据科学和机器学习方面,借助 Fabric Data Science 的笔记本和 MLflow 体验等。同时,关注工具的更新和发展,及时利用新功能来提升数据处理和分析能力。
-
强化数据访问和交付机制 :根据用户和应用程序的需求,提供多样化的数据访问和交付方式。通过 Power BI 等工具,创建直观、交互式的仪表盘和报告,使业务用户能够轻松地获取和理解数据洞察。同时,优化数据查询和交付的性能,确保数据的及时性和准确性。
-
推进 DataOps 实践 :在组织内推广 DataOps 文化,加强数据管理团队与数据消费团队之间的沟通和协作。利用 Data Factory 的数据编排和可观测性功能,以及与 Git 的集成,实现数据管道的自动化、版本控制和 CI/CD 实践,提高数据系统的可靠性、可扩展性和效率。
-
持续监测和改进 :建立有效的监测和评估机制,持续跟踪 Microsoft Fabric 解决方案的性能、成本和业务价值。根据监测结果,及时调整和优化数据管理架构和策略,以确保其能够适应组织不断变化的业务需求和技术环境。
四、方案架构
架构的目标与范围
-
设计数据管理架构的指导 :该研究详细阐述了如何利用 Microsoft Fabric SaaS 解决方案来设计数据管理架构,包括对各种组件和功能的概述、比较,以及它们与特定用例的对应关系,并提供了实施的最佳实践。
目标组织与应用场景
-
适用的组织类型 :适用于那些正在使用或考虑使用 Microsoft Fabric 来开发数据管理架构的组织。这些组织可能具有多样的业务需求和数据管理目标,如需要整合多个数据源、处理不同类型的数据、支持复杂的数据分析等。
-
典型应用场景 :例如,组织希望通过评估当前业务需求、未来用例和现有数据架构,来确定是否采用 Microsoft Fabric 的统一或组合数据分析方法,以实现最佳价值;或者需要在 Microsoft Fabric 的 Lakehouse 中实施勋章架构,以提高数据管理的效率和可访问性。
组件与功能的对应关系
-
数据管理的关键组件 :研究中提到了 Gartner 的数据管理参考架构所涵盖的多个关键组件能力,如数据摄取、数据存储、数据处理引擎、数据访问、数据交付、DataOps、数据治理和元数据管理等,并解释了这些组件在数据管理架构中的作用。
-
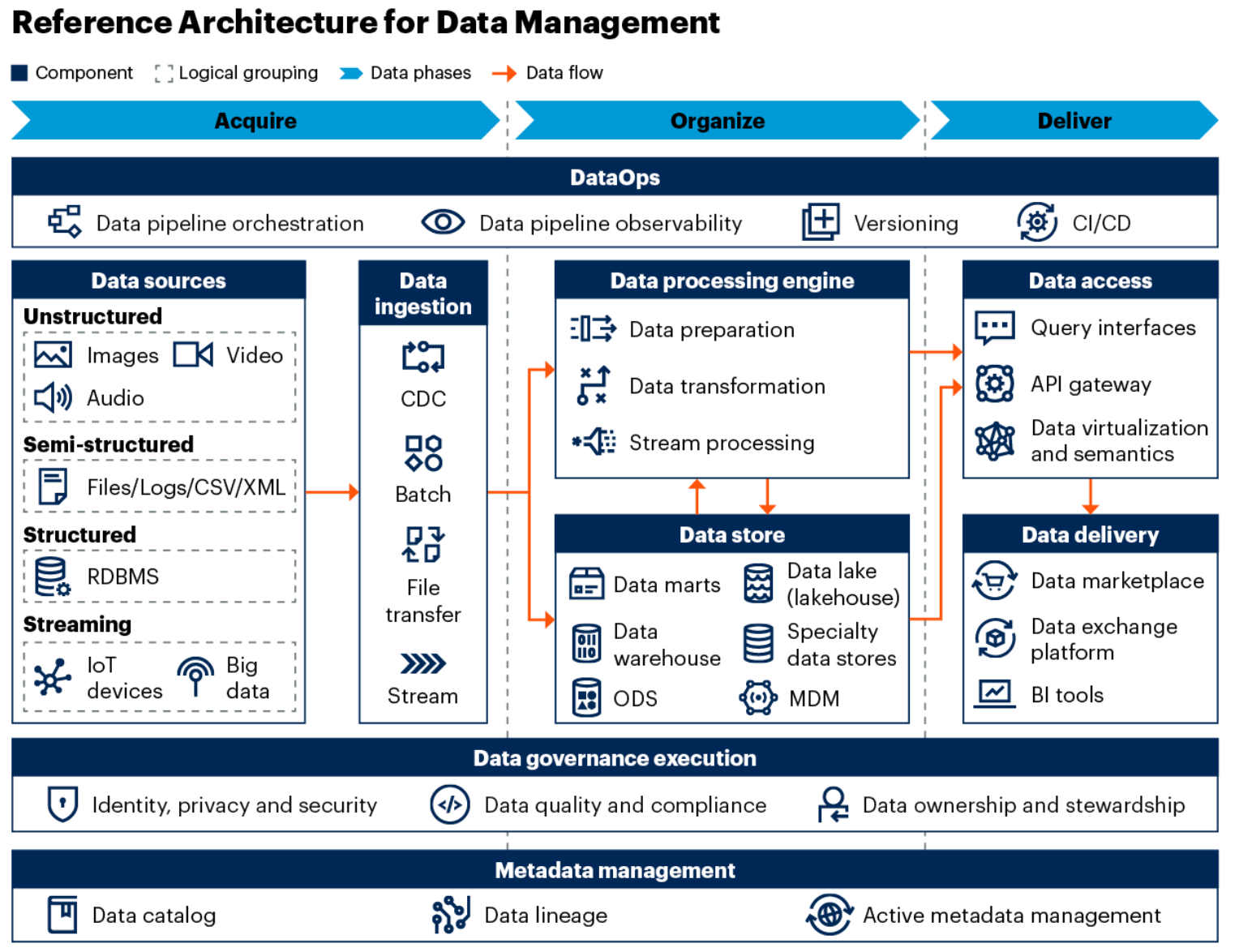
-
Microsoft Fabric 的对应功能 :阐述了 Microsoft Fabric 中与这些关键组件相对应的具体功能和服务,如用于数据摄取的 Data Factory、用于数据存储的 OneLake、Fabric Data Warehouse 和 Fabric Lakehouse 等,以及它们如何支持组织的数据管理需求。
-
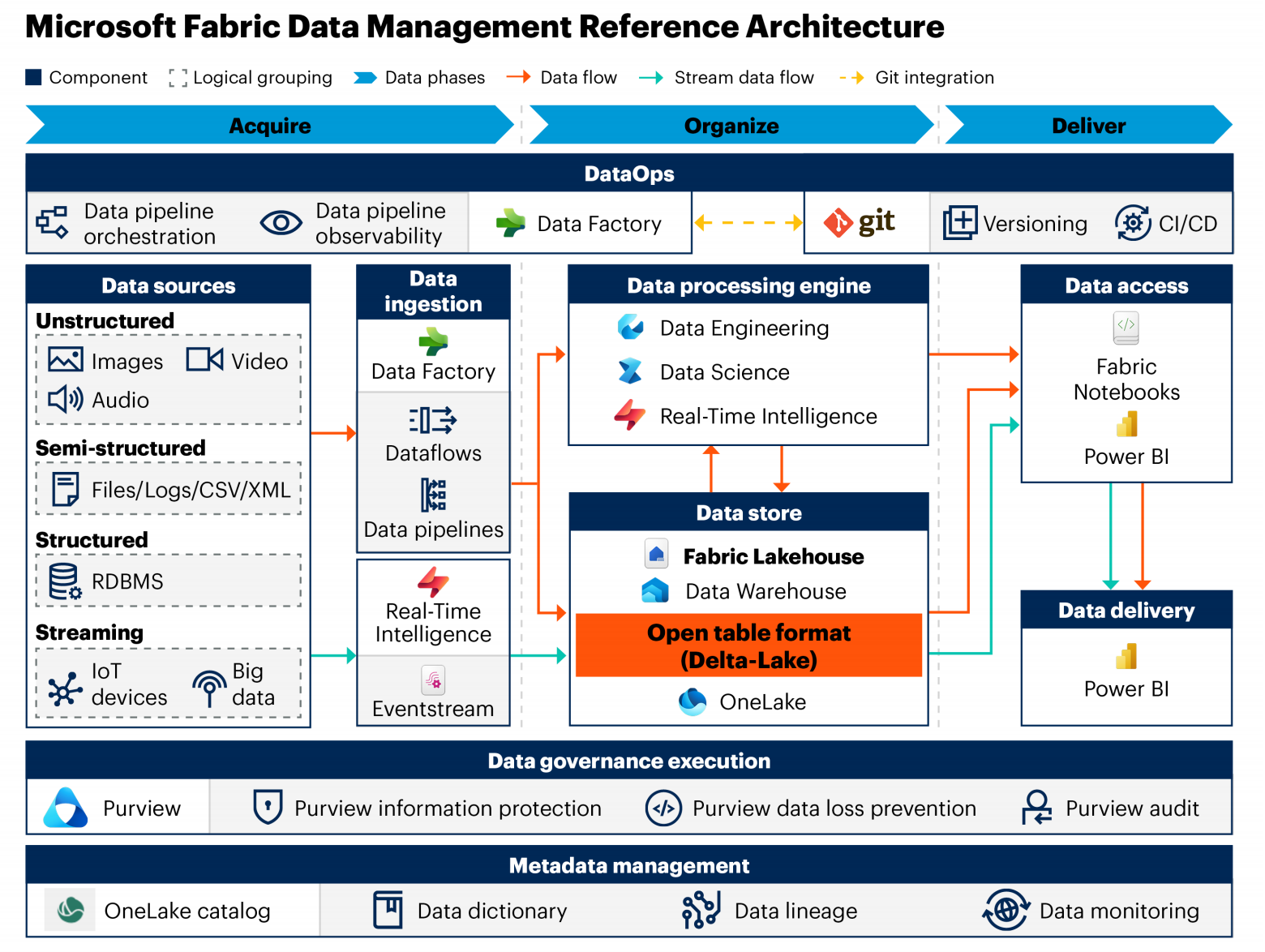
-
统一模式架构方案
-
数据存储层(OneLake) :将所有数据存储在 OneLake 中,利用其统一存储层的优势,支持多种数据类型,如结构化、半结构化和非结构化数据。OneLake 基于 Azure Data Lake Storage Gen2 架构,采用 Delta Lake 格式存储数据,确保数据的可靠性和高性能访问。
-
数据处理层 :利用 Fabric Lakehouse 的 Apache Spark 和 SQL 计算引擎,对数据进行处理和转换。数据可以从 OneLake 中直接读取和写入,无需数据移动或复制。通过笔记本、数据管道和 Dataflow Gen2 等工具,实现数据的清洗、转换、 enrichment 和分析等功能。
-
数据访问和交付层 :使用 Power BI 作为主要的数据交付工具,创建交互式仪表盘、可视化和报告。Power BI 可以通过 DirectQuery 模式、Import 模式和 Direct Lake 模式等方式访问和交付数据,满足不同用户和应用程序的需求。
-
数据治理和元数据管理层 :结合 Microsoft Purview 和 OneLake 目录,实现数据的治理和元数据管理。Purview 提供全局数据治理能力,涵盖整个企业数据资产,而 OneLake 目录则专注于 Fabric 生态系统内的数据管理。通过定义数据策略、应用敏感信息标签、跟踪数据血缘等方式,确保数据的安全性、合规性和可用性。
-
-
混合模式架构方案
-
数据存储层 :青铜和银层数据存储在外部平台或数据库中,如传统数据湖或数据仓库。金层数据则存储在 Microsoft Fabric 的 OneLake 中。通过数据镜像和快捷方式等功能,将外部数据引入到 OneLake 中,实现数据的统一管理和访问。
-
数据处理层 :利用 Fabric Data Factory 或其他集成工具,将外部数据源中的数据迁移到 OneLake 中的金层。在 OneLake 中,使用 Fabric Lakehouse 的计算引擎和工具对数据进行处理和分析,与其他 Microsoft 服务(如 Azure 机器学习、Power BI 等)进行集成,实现更高级的数据分析和机器学习功能。
-
数据访问和交付层 :与统一模式类似,使用 Power BI 作为数据交付的核心工具,结合其他数据访问和可视化工具,为用户提供了一个全面的数据访问和交付解决方案。根据数据的位置和特点,灵活选择数据访问模式和可视化方式,确保用户能够及时获取所需的数据洞察。
-
数据治理和元数据管理层 :在混合模式下,数据治理和元数据管理需要覆盖外部数据源和 Microsoft Fabric 生态系统内的数据。通过制定统一的数据治理策略和标准,确保数据在不同系统和平台之间的一致性和合规性。同时,利用 OneLake 目录和 Purview 等工具,实现对数据的全面治理和元数据管理。
-
五、小结
该报告针对Microsoft Fabric如何 企业提供了一个全面的云端解决方案,涵盖了端到端的数据管理能力。组织应根据自身业务需求、技术栈和未来战略规划,评估 Microsoft Fabric 是否适合其数据管理架构。通过采用合适的架构模式(统一模式或混合模式),并结合有效的数据治理、处理、访问和交付策略,组织可以充分利用 Microsoft Fabric 的优势,实现数据驱动的业务决策和创新。同时,应密切关注 Microsoft Fabric 的技术发展和更新,及时调整和优化数据管理策略,以适应不断变化的技术和业务环境。
相信这对于其他云上数据平台也有一定参考意义,请大家斧正


















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











