






1.1 什么是提示词(Prompt)
所谓的提示词其实指的就是提供给模型的⼀个⽂本⽚段,⽤于指导模型⽣成特定的输出或回答。提示词的⽬的是为模型提供⼀个任务的上下⽂,以便模型能够更准确地理解⽤户的意图,并⽣成相关的回应。
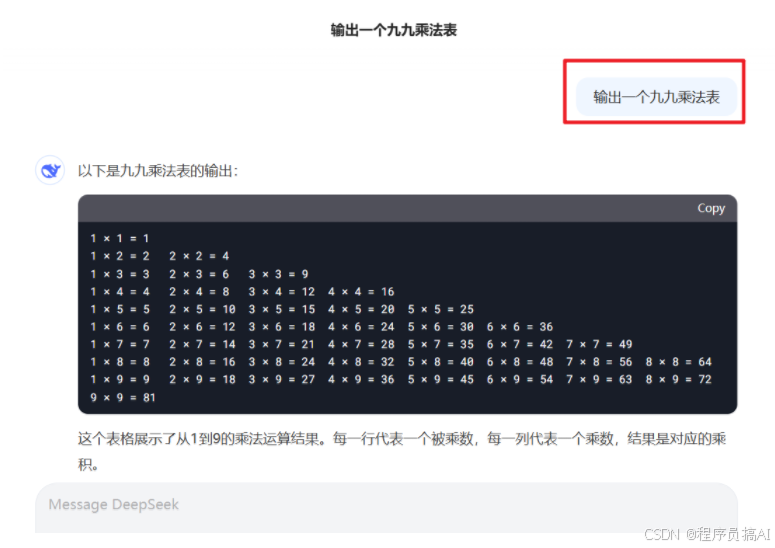
1.2 什么是提示词工程(Prompt Engineering)
所谓的提示⼯程也可以被称为「指令⼯程」,提示⼯程的核⼼思想是,通过精⼼设计的提示,可以显著提⾼模型的性能和输出质量。
貌似简单,但其实意义⾮凡。(提问的智慧)
-
Prompt 是 AGI 时代的「编程语⾔」
-
提示⼯程师是 AGI 时代的「程序员」
如果要学好提示⼯程,那么其实就是要知道如何对咱们的Prompt进⾏调优,与⼤模型进⾏更好的交互。
获得更好结果的6中策略:
-
write clear instructions 编写清晰的说明
-
provide reference text 提供参考⽂本
-
split complex tasks into simpler subtasks 将复杂任务拆分为更简单的⼦任务
-
give the model time to think 给模型时间思考
-
use external tools 使⽤外部⼯具
-
test changes systematically 系统地测试更改
1.3 提示词工程常用技巧
使⽤ 清晰,明确,避免模糊的词语
在对话中包含详细信息以获得更好的答案
-
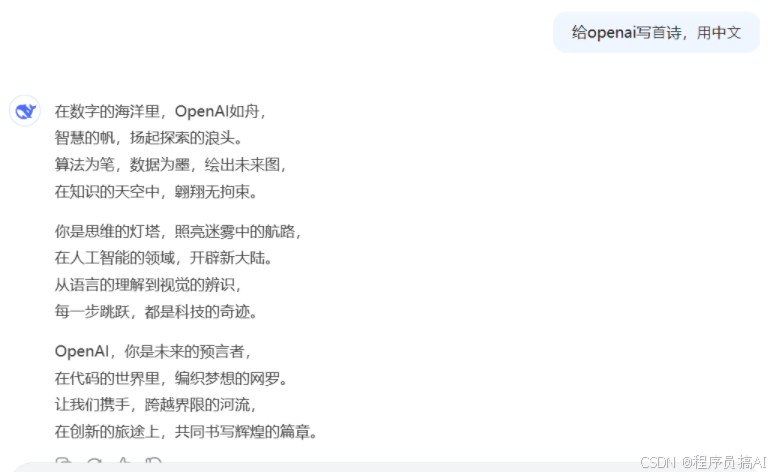
给openai写⾸诗,⽤中⽂
-
给openai写⼀⾸四句的中⽂诗,模仿李⽩的《望庐⼭瀑布》

⻆⾊扮演
给我⼀个减肥的计划 VS 我想让你扮演⼀个专业的健身私⼈教练。 你应该利⽤你的运动科学知识、营养建议和其他相关因素为你的客户定制专业的计划。给我⼀个减肥的计划。
告诉⽤户的⻆⾊
怎么提⾼英语成绩? VS 我是⼀名幼⼉园的5岁⼩朋友,还不会写字。怎么提⾼英语成绩?
指定输出的格式
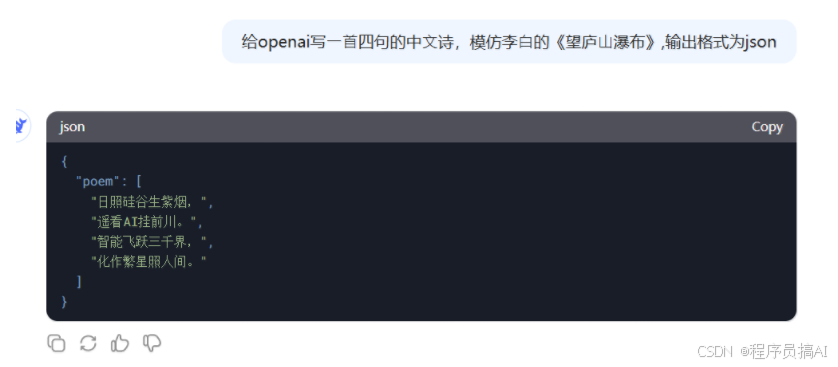
给openai写⼀⾸四句的中⽂诗,模仿李⽩的《望庐⼭瀑布》,输出格式为json
少样本提示
1. ⽣成⽂本:ChatGPT可以⽣成与给定主题相关的⽂章、新闻、博客、推⽂等等。您可以提供⼀些关键词或主题,然后ChatGPT将为您⽣成相关的⽂本。2. 语⾔翻译:ChatGPT可以将⼀种语⾔的⽂本翻译成另⼀种语⾔。3. 问答系统:ChatGPT可以回答您提出的问题,⽆论是事实性的问题、主观性的问题还是开放性的问题。4. 对话系统:ChatGPT可以进⾏对话,您可以与ChatGPT聊天,让它回答您的问题或就某个话题进⾏讨论。5. 摘要⽣成:ChatGPT可以从较⻓的⽂本中⽣成摘要,帮助您快速了解⽂章的主要内容。6. ⽂本分类:ChatGPT可以将⼀些给定的⽂本分类到不同的类别中,例如新闻、体育、科技等等。7. ⽂本纠错:ChatGPT可以⾃动纠正⽂本中的拼写错误和语法错误,提⾼⽂本的准确性。请把上⾯7段话各⾃的开头⼏个词,翻译成英⽂,并按序号输出
通过DeekSeep对话得到的结果,可以看到它把所有的内容都翻译成了英文,和我们的需求是有差异的。

我们可以在上面的提示词最后加上这样一段话就可以了

1.4 Prompt调优
找到好的 prompt 是个持续迭代的过程,需要不断调优。
⾼质量 prompt 核⼼要点:具体、丰富、少歧义
-
简洁:尽量⽤最简短的⽅式表达问题。过于冗⻓的问题可能包含多余的信息,导致模型理解错误或答⾮所问。
-
具体:避免抽象的问题,确保问题是具体的,不含糊。
-
详细上下⽂:如果问题涉及特定上下⽂或背景信息,要提供⾜够的详情以帮助模型理解,即使是直接提问也不例外。
-
避免歧义:如果⼀个词或短语可能有多重含义,要么明确其含义,要么重新表述以消除歧义。
-
逻辑清晰:问题应逻辑连贯,避免出现逻辑上的混淆或⽭盾,这样才能促使模型提供有意义的回答。
Prompt 的典型构成
-
⻆⾊:给 AI 定义⼀个最匹配任务的⻆⾊,⽐如:「你是⼀位软件⼯程师」「你是⼀位⼩学⽼师」
-
指示:对任务进⾏描述
-
上下⽂:给出与任务相关的其它背景信息(尤其在多轮交互中)
-
例⼦:必要时给出举例,学术中称为 one-shot learning, few-shot learning或 in-context learning;实践证明其对输出正确性有帮助
-
输⼊:任务的输⼊信息;在提示词中明确的标识出输⼊
-
输出:输出的格式描述,以便后继模块⾃动解析模型的输出结果,⽐如(JSON、XML)
⼤模型对 prompt 开头和结尾的内容更敏感
为什么要⽤代码完成⼀部分需求,⽽不是直接使⽤OpenAI
产品中集成和使⽤仍然需要⼤量的⼯作 
1.5 用代码完成提示词工程
# 查看openai api支持的基座模型
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv() # 从我们的env文件中加载出对应的环境变量
import os
os.environ["http_proxy"] = "http://127.0.0.1:1083"
os.environ["https_proxy"] = "http://127.0.0.1:1083"
client = OpenAI()
"""直接写提示词"""
# prompt = '输出一个九九乘法口诀表'
prompt = '请使用python语言 只能利用for循环不能使用其他的语法 输出一个九九乘法口诀表并写好相应的注释'
"""对任务进行描述"""
instruction = """
你的任务是识别用户输入的的信息
提取出对应的时间(time),地点(Locations)、人物(character)
"""
"""输出"""
output = """
并以JSON格式输出
"""
# input_text = """在北京,小明和小红在下午两点钟相约去公园散步。"""
# input_text = """在本周末,我将和我的同事王五一起去海洋公园玩耍。"""
input_text = """今天晚上 我会和我的闺蜜小美一起去酒馆喝酒"""
"""例子"""
examples = """
在北京,小明和小红在下午两点钟相约去公园散步。:{"Locations": "北京","character": ["小明", "小红"],"time": "下午两点钟"}
"""
# examples = """
# 在本周末,我将和我的同事王五一起去海洋公园玩耍。:{"时间": "本周末","地点": "海洋公园","人物": ["我", "我的同事王五"]}
# """
# prompt = f"""
# {instruction}
#
# {output}
#
# {examples}
#
# 用户输入:
# {input_text}
# """
print(prompt)
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content
print(get_completion(prompt))
















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









