






近年来,计算机视觉取得了长足进步,YOLO(You Only Look Once,只看一次)等模型在实时物体检测领域引领潮流。然而,大多数传统模型都存在一个显著的局限性:它们只能检测经过专门训练的物体。YOLO-E 的出现,是一项突破性的进步,有望彻底改变机器观察和理解周围世界的方式。
YOLO-E 有何特别之处?
YOLO-E 是一个脱颖而出的“看见一切”模型,它可以根据三种不同类型的提示检测和分割物体:
- 文字提示:用文字告诉模型要寻找什么
- 视觉提示:向模型展示要查找的内容的示例图像
- 无需提示的操作:让模型识别它所看到的一切,无需指导
虽然其他模型也尝试过类似的功能,但 YOLO-E 却以卓越的效率实现了这一目标——与 YOLO-World 等同类模型相比,训练速度提高了 3 倍,运行速度提高了 1.4 倍。这对于兼顾灵活性和速度的应用来说尤为重要。
传统物体检测的问题
要理解 YOLO-E 的重要性,请考虑以下常见场景:
你已经训练了一个安全系统来识别“人”和“车”。有一天,一位送货员骑着电动滑板车来了。你的传统系统失败了,因为它没有经过专门的训练来识别“滑板车”。
这是封闭词汇系统的根本局限性——它们只能检测在训练过程中明确学习到的内容。在一个充满无限可能对象的世界里,这种方法很快就会失效。
建筑学
YOLO-E 在成熟的 YOLO 架构基础上,添加了用于开放词汇检测的复杂组件。以下是完整架构的详细工作原理:
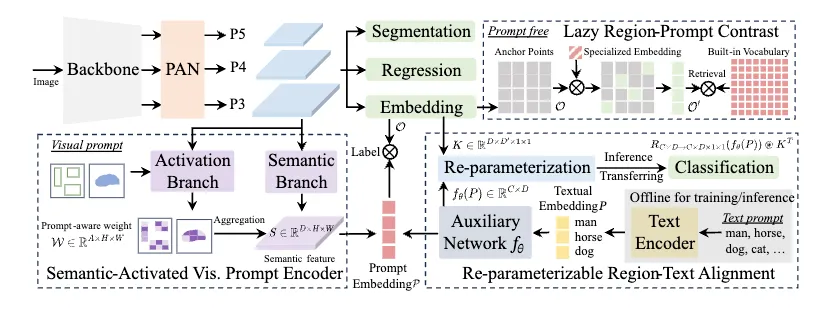
- 基础网络:YOLO-E 使用 YOLOv8 或 YOLO11 主干网络作为基础,通过一系列卷积层处理输入图像
- PAN(路径聚合网络):从主干网络中提取多尺度特征(P3、P4、P5),以捕获不同大小的物体
- 核心主管:
- 回归头:预测物体检测的边界框坐标
- 分割头:生成用于实例分割的原型掩码和系数
- 对象嵌入头:创建表示每个锚点处的视觉内容的特征嵌入。
处理管道
- 图像输入:系统以图像作为输入
- 特征提取:主干和 PAN 提取多个尺度的分层特征
- 锚点:模型将图像划分为锚点网格(类似传统的YOLO)
- 对象嵌入:对于每个锚点,模型生成对象嵌入(特征向量)
- 提示处理:根据输入类型,激活以下三条路径之一:
- 文字提示→RepRTA通路
- 视觉提示 → SAVPE 路径
- 无提示 → LRPC 通路
稍后再回来!
6. 嵌入匹配:系统通过点积运算比较对象嵌入和提示嵌入
7.输出生成:最后,模型产生:
- 检测到的物体的边界框
- 用于精确物体边界的分割蒙版
- 基于提示匹配的类别标签
这种统一的架构使 YOLO-E 能够在一个高效的框架内处理不同类型的输入。现在,让我们来看看实现这一目标的三种创新机制:
YOLO-E 如何解决开放词汇挑战
YOLO-E 通过三种无缝协作的创新机制解决了这个问题:
1. 可重新参数化的区域文本对齐(RepRTA)
作用:该组件允许模型理解文本描述并将其与图像中的视觉元素进行匹配。
想象一下,你身处异国他乡,当地人给你提供寻找地标的书面路线。RepRTA 就像一位智能翻译,它不仅能理解文字,还能帮助你直观地识别出你想要寻找的内容。
技术细节:
- 文本编码器:YOLO-E 首先使用 MobileCLIP-B(LT)文本编码器处理文本提示,以获得预训练的文本嵌入。
- 嵌入缓存:为了提高效率,训练数据集中的所有文本嵌入都会在训练开始前预先缓存。这样就无需在训练期间反复运行文本编码器。
- 辅助网络架构:辅助网络 (fθ) 由轻量级 SwiGLU FFN(前馈网络)模块组成,该模块包含一个线性层,后接 SwiGLU 激活层和另一个线性层。该网络处理文本嵌入,以改善其与视觉特征的对齐效果。
- 数学公式:
- 对于长度为 C 的文本提示 T,初始嵌入为 P = TextEncoder(T)
- 增强嵌入为 P' = fθ(P) ∈ R^(C×D),其中 D 是嵌入维度
- 在训练期间,锚点对象嵌入 O 通过点积与这些增强嵌入进行比较:标签 = O · P'^T
5.重新参数化过程:
- 令 K ∈ R^(D×D'×1×1) 为对象嵌入头中最后一个卷积层的核参数
- 训练完成后,辅助网络参数在数学上被折叠到 K 中,从而创建一个新的核 K' = RC×D→C×D×1×1(fθ(P)) ⊛ K^T
- 最终预测变为 Label = I ⊛ K',其中 I 是输入特征,⊛ 是卷积运算
这种重新参数化技巧使得 YOLO-E 能够在训练期间受益于改进的文本视觉对齐,同时在推理期间保持与标准 YOLO 模型相同的计算效率。
2. 语义激活视觉提示编码器(SAVPE)
作用:该组件使模型能够使用视觉示例作为搜索查询。
简单来说:这就像向朋友展示一张照片并询问“找到更多看起来像这样的东西”。
技术细节:
- 双分支架构:SAVPE 采用两个并行处理分支:
- 语义分支:生成与提示无关的语义特征
- 激活分支:为特征聚合生成提示感知权重
2.语义分支实现:
- 使用 PAN 中的多尺度特征 {P3, P4, P5}
- 在每个尺度上应用两个 3×3 卷积层
- 对特征进行上采样并连接它们
- 将它们投影以得出语义特征 S ∈ R^(D×H×W),其中 D 是嵌入维度
3.激活分支实现:
- 将视觉提示形式化为二进制掩码(1 表示感兴趣的区域,0 表示其他区域)
- 对掩码进行下采样,并通过 3×3 卷积处理,得到提示特征 FV ∈ R^(A×H×W)
- 通过卷积从{P3,P4,P5}中提取图像特征FI∈R^(A×H×W)
- 将 FV 和 FI 连接起来并处理它们以产生提示感知权重 W ∈ R^(A×H×W)
- 使用提示指示区域内的 softmax 对权重进行归一化
4.分组和聚合:
- 将语义特征 S 分为 A 组(默认 A=16)
- 每组都有 D/A 通道,共享 W 中相应通道的权重
- 这种方法能够在较低维度(A≪D)中处理视觉线索,从而降低计算成本
5.数学公式:
- 最终的提示嵌入是通过聚合创建的:P = Concat(G1,...,GA)
- 其中 Gi = Wi+1 · S^T_(D/A i: D/A (i+1))
- 然后,该嵌入与锚点的对象嵌入进行对比,以识别具有相似视觉特征的对象
关键创新在于语义特征与特定提示激活之间的高效交互,从而以最小的计算开销实现强大的视觉匹配。通过处理较低维度(A=16 vs. D=通常为 256 或 512)的视觉提示,SAVPE 在保持模型轻量级的同时实现了强大的性能。
3.惰性区域提示对比(LRPC)
作用:该组件使系统能够在没有任何提示的情况下工作,识别其可以识别的所有对象。
这就像有一位助手走进房间,无需别人告诉他要寻找什么,他就可以列出完整的清单。
技术细节:
- 问题重构:LRPC 不使用生成语言模型来生成对象描述(计算成本高昂),而是将无提示检测重新表述为检索问题:
- 首先确定所有对象区域
- 然后有效地将这些区域与预定义的词汇进行匹配
2. 专门的提示嵌入:
- 在训练过程中,YOLOE 会学习一种专门的提示嵌入 (Ps),该嵌入经过优化,可以将所有对象检测为一个类别
- 此嵌入仅使用相同的数据集训练 1 个 epoch,但所有对象均标记为单个类
- 目标是生产一个通用的“物体”检测器
3.内置词汇:
- LRPC 包含 4,585 个常见对象类别的综合内置词汇表
- 词汇表是从涵盖不同对象类型和属性的标签列表中收集的
- 每个词汇术语都有一个使用文本编码器预先计算的对应文本嵌入
4.高效的两阶段检测算法:
第 1 阶段(过滤):应用专门的提示嵌入来识别带有对象的锚点:
- O' = {o ∈ O | o · Ps^T > δ}
- 其中 O 是所有锚点的集合,Ps 是专门的提示嵌入,δ 是过滤阈值(默认值:0.001)
第 2 阶段(检索):仅针对词汇表处理已过滤的锚点 O'
- 这种“懒惰”的方法只对相关区域执行计算量很大的匹配
5.数学实现:
- 对于相关锚点 o ∈ O',计算相似度得分:Scores = o · V^T
- 其中 V 是所有词汇嵌入的矩阵
- 选择得分最高的词汇作为预测类别
关键创新在于无需处理所有词汇(4,585 个)对应的所有锚点(通常超过 8,400 个),这需要数十亿次运算。通过先进行过滤,LRPC 可将计算量减少高达 80%,实现 1.7 倍加速,且准确率不受影响。这使得无需提示的检测方法可用于实时应用,从而消除了竞争对手对大型语言模型的依赖。
YOLO-E 的实现步骤
训练过程
- 数据准备:
- 收集检测和接地数据集(如 Objects365、GoldG)
- 使用 SAM-2.1 生成伪实例掩码进行分割训练
- 过滤和精炼口罩以确保质量
2. 初始培训:
- 使用文本提示训练基础模型约 30 个 epoch
- 使用 AdamW 优化器,初始学习率为 0.002
- 应用数据增强,包括颜色抖动、随机变换和马赛克增强
3.视觉提示集成:
- 冻结基础模型参数
- 仅训练 SAVPE 组件约 2 个周期
- 使用地面实况边界框作为视觉提示
4. 无提示功能:
- 仅训练 1 个 epoch 的专门提示嵌入
- 将所有对象视为单个类别以启用一般检测
推理过程
- 文字提示方式:
- 输入:图片+文字描述
- 系统使用 RepRTA 将对象嵌入与文本嵌入进行匹配
- 输出:与文本描述匹配的对象
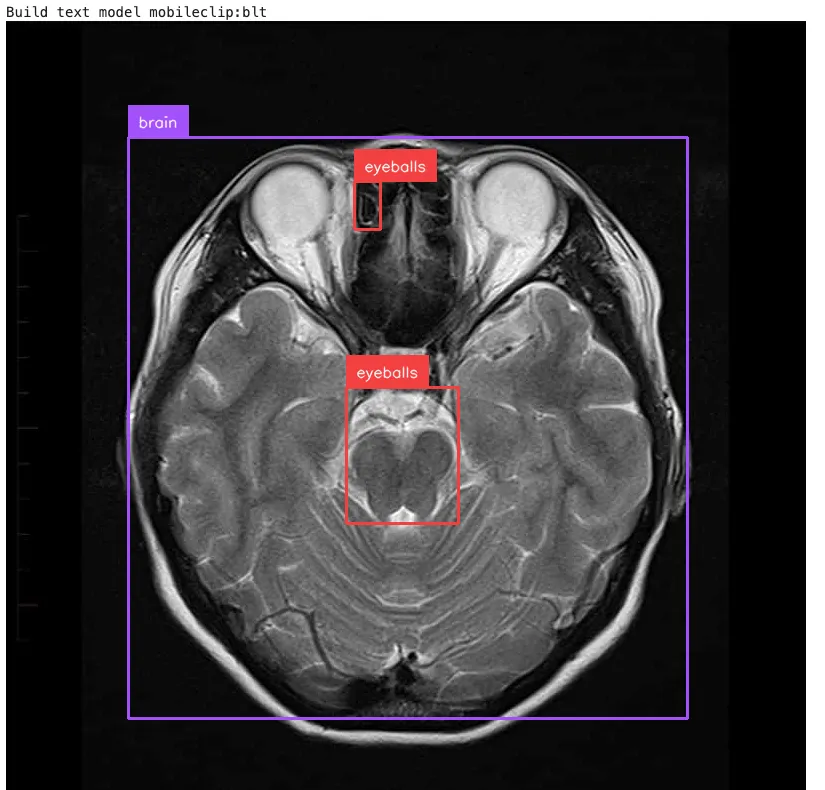

虽然该模型在一般设置下表现良好,但专门的应用需要额外的微调以确保精确的结果。
2.视觉提示模式:
- 输入:图像+参考视觉示例
- 系统使用 SAVPE 对视觉示例进行编码
- 输出:与提供的参考相似的对象
3.无提示模式:
- 输入:仅一张图片
- 系统使用 LRPC 检测所有可能的物体
- 从内置词汇表中检索类别名称
- 输出:所有检测到的对象及其类别名称
表现:
YOLO-E 不仅在理论上具有创新性,而且在实践中也实现了可衡量的改进:
- 在具有挑战性的 LVIS 数据集(包含 1,203 个不同的对象类别)上,YOLO-E-v8-S 在 NVIDIA T4 GPU 上以每秒 305.8 帧的速度运行时实现了 27.9% 的准确率
- 同一型号在 iPhone 12 上达到每秒 64.3 帧,非常适合移动应用
- 与 YOLO-World 相比,它以少 3 倍的训练成本实现了这一性能
这种准确性和效率的结合使得 YOLO-E 对于实时性能和灵活性都至关重要的应用特别有价值。
计算机视觉的未来
YOLO-E 代表着我们朝着更灵活、更高效的计算机视觉系统迈出了重要一步。它在一个高度优化的架构中融合了多种提示机制,弥合了专用模型与通用视觉系统之间的差距。
实时检测和分割任意物体的能力为需要快速适应不断变化的环境或用户需求的应用程序开辟了新的可能性。随着边缘设备功能越来越强大,用例也越来越复杂,像 YOLO-E 这样的模型对于构建响应迅速的智能视觉系统至关重要。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









