







1. 【导读】

论文信息
标题:Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
作者:Jingfeng Yao、Bin Yang、Xinggang Wang
作者机构:Jingfeng Yao、Xinggang Wang:Huazhong University of Science and Technology;Bin Yang:Independent Researcher
论文链接:https://arxiv.org/abs/2501.01423v3
项目链接:https://github.com/hustvl/LightningDiT
2. 【摘要】
该论文针对基于Transformer架构的潜在扩散模型中存在的优化困境展开研究。研究发现,增加视觉tokenizer的特征维度虽能提升重建质量,但会导致生成性能下降,且需更大模型和更多训练迭代。此困境源于学习无约束高维潜在空间的固有难度。
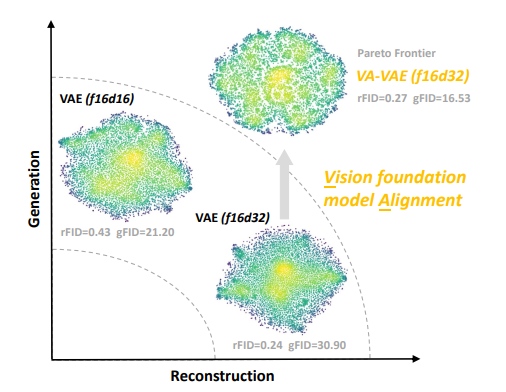
为此,论文提出在训练视觉tokenizer时,将潜在空间与预训练视觉基础模型对齐的方法,开发了VA-VAE(视觉基础模型对齐变分自编码器),有效扩展了潜在扩散模型的重建-生成前沿,加速了高维潜在空间中扩散变换器(DiT)的收敛。
同时,通过改进训练策略和架构设计,构建了增强型DiT基线LightningDiT。实验表明,集成系统在ImageNet 256×256生成任务中达到SOTA性能(FID=1.35),且仅用64个epoch即可达到FID=2.11,收敛速度较原始DiT提升超21倍。
关注VX公众号【学长论文指导】发送暗号 9 领取

3. 【研究背景】
-
潜在扩散模型的优势与困境
基于Transformer架构的潜在扩散模型在生成高保真图像方面表现出色,其通过视觉tokenizer(如VAE)压缩视觉信号,降低高分辨率图像生成的计算成本。然而,该领域存在显著的优化困境:增加tokenizer的特征维度虽能提升图像重建质量(如rFID降低),但会导致生成性能下降(如gFID升高),且需更大规模的扩散模型和更多训练迭代才能维持生成效果。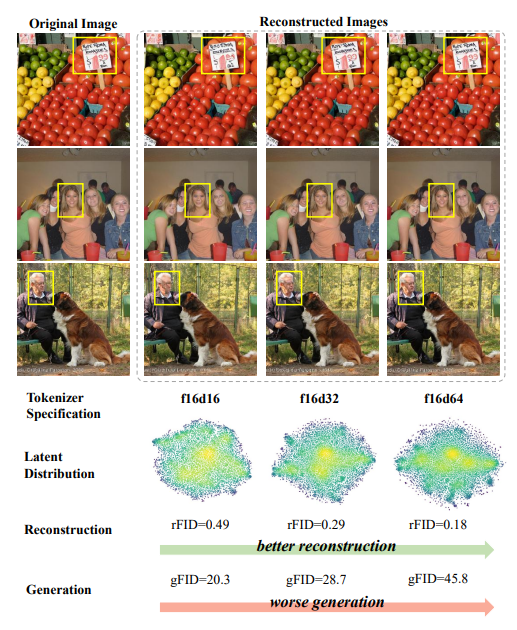
-
现有解决方案的局限性
目前应对优化困境的策略存在明显缺陷:
扩大模型参数:如Stable Diffusion 3通过增大模型容量提升生成性能,但计算成本高昂,难以普及。限制tokenizer重建能力:如Sana、W.A.L.T等方法通过牺牲重建质量加速扩散模型收敛,但导致生成图像细节不完美,无法突破性能上限。
两类方法均需在重建与生成之间权衡,未从根本上解决高维潜在空间的学习难题。
-
高维潜在空间的学习挑战
研究发现,高维tokenizer的潜在空间分布更为集中(如高密度区域聚集),表明无约束的高维空间学习存在固有困难。这一问题与离散VAE中码本规模扩大导致的利用率下降具有相似性,均源于特征空间结构的不合理性。现有文献缺乏针对连续VAE优化的有效解决方案,亟需引入外部先验引导潜在空间的学习。
4.【主要贡献】
4.1 提出VA-VAE(视觉基础模型对齐变分自编码器),解决潜在扩散模型的优化困境
-
核心方法:通过设计视觉基础模型对齐损失(VF Loss),在训练视觉tokenizer(VAE)时将其潜在空间与预训练视觉基础模型(如DINOv2、MAE)的特征空间对齐,引导高维潜在空间学习更合理的分布结构。
-
技术创新:
-
VF Loss组件:包含边际余弦相似性损失 () 和边际距离矩阵相似性损失 (),分别约束特征点对的绝对相似性和相对分布结构,确保全局与局部特征结构的正则化。
-
自适应加权机制:通过梯度比例动态调整损失权重,平衡重建损失与对齐损失的尺度,避免训练不稳定。
-
-
效果:使高维tokenizer在保持高重建质量的同时,生成性能显著提升(如f16d32 tokenizer的gFID从28.7降至15.82),并扩大了重建-生成的帕累托前沿。
4.2 构建LightningDiT,实现扩散Transformer的高效训练
-
优化策略:
-
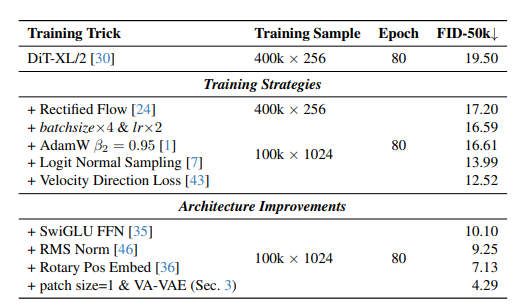
计算与架构改进:集成torch.compile加速、bfloat16训练、SwiGLU激活函数、RMSNorm归一化和Rotary位置嵌入,提升训练效率与模型稳定性。
-
扩散模型优化:引入Rectified Flow、Logit Normal采样和Velocity Direction Loss,减少扩散过程的计算成本。
-
-
性能突破:
-
快速收敛:在ImageNet 256×256生成中,仅用64个epoch达到FID=2.11,较原始DiT(需1400+ epoch)实现21倍收敛加速。
-
高保真生成:最终系统达到SOTA性能(FID=1.35),同时实现高重建质量(rFID=0.28),突破传统方法中重建与生成的权衡限制。
-
5.【研究方法与基本原理】
5.1 VA-VAE:视觉基础模型对齐的变分自编码器
核心架构与对齐机制
VA-VAE 通过编码器将输入图像压缩为高维潜在向量,解码器从重建图像,同时引入视觉基础模型 (如 DINOv2、MAE) 提取的特征作为对齐目标,迫使的分布匹配预训练模型的语义结构。整体训练框架如图 3 所示,损失函数为:。其中,为重建损失(如L2损失),为 KL 散度损失(约束潜在分布接近正态分布), 为视觉基础模型对齐损失,是方法的核心创新点。
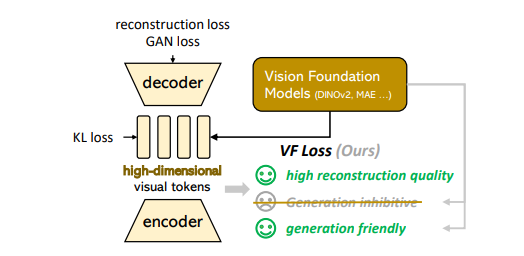
视觉基础模型对齐损失(VF Loss)
VF Loss包含两个分量,分别从逐点相似性和相对分布结构约束潜在特征:
-
边际余弦相似性损失(
-
目的:确保 与 在空间各位置的特征向量逐点相似。
-
实现:首先通过线性变换将 Z 投影到 F 的维度: ()(式1)
-
计算投影后的特征 与 F 的余弦相似性,引入 margin 避免过拟合:
其中, 为特征图位置,仅当相似性低于 时贡献损失,聚焦差异较大的特征对。
-
边际距离矩阵相似性损失(
-
目的:确保和的特征向量相对分布结构一致(如样本间的相似性排序)。
-
实现:计算特征矩阵的余弦相似性矩阵,约束两者的差异:
-
(式3)
其中,为特征向量总数,为松弛 margin,仅当差异超过时激活损失。 3. 自适应加权机制
-
目的:动态平衡 与重建损失 的尺度,避免训练不稳定。
-
公式:通过计算两者在编码器最后一层的梯度范数之比调整权重:
其中 为手动调节超参数(默认 0.1)。
5.2 LightningDiT:优化的扩散Transformer
训练策略与架构改进
LightningDiT基于Diffusion Transformers (DiT),通过以下优化提升训练效率和生成质量:
-
计算效率优化
-
混合精度训练:使用bfloat16降低计算量,结合
torch.compile加速模型编译。 -
批量大小与优化器调整:增大批量大小并调整AdamW优化器参数(,提升收敛稳定性。
-
-
扩散过程改进
-
Rectified Flow集成:加速扩散采样过程,减少生成所需的时间步数。
-
Logit Normal采样与Velocity Direction Loss:前者通过归一化采样提升生成多样性,后者通过约束扩散方向加速收敛。
-
-
架构层面优化
-
Transformer改进:引入SwiGLU激活函数增强非线性表达,RMSNorm归一化提升训练稳定性,Rotary位置嵌入(RoPE)处理长序列依赖。
-
补丁大小调整:设置DiT的补丁大小为1,与VA-VAE的下采样率16匹配,确保所有压缩由VAE完成,减少模型冗余计算。
-
与VA-VAE的协同训练
-
潜在特征预提取:先训练VA-VAE至收敛,再固定其参数,将图像预编码为潜在特征 ( Z ),供DiT进行扩散训练。
-
快速收敛特性:结合VA-VAE的高维潜在空间正则化,LightningDiT在64个epoch内即可达到FID=2.11,较原始DiT(需1400+ epoch)实现21倍加速,且最终FID=1.35达到SOTA性能。
5.3 理论基础:潜在空间分布与生成性能的关联
-
高维空间的优化困境:通过t-SNE可视化发现,高维tokenizer的潜在分布存在高密度聚集区域,导致扩散模型难以探索有效生成路径。VF Loss通过对齐视觉基础模型的特征分布,使潜在空间更均匀,提升生成效率。
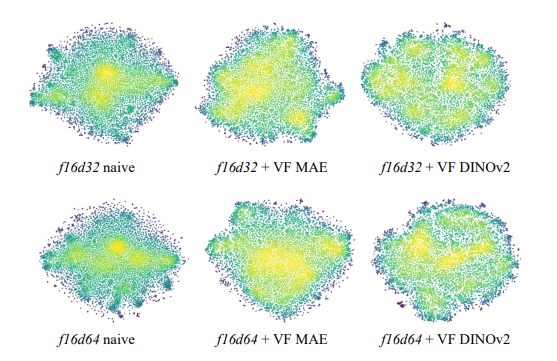
-
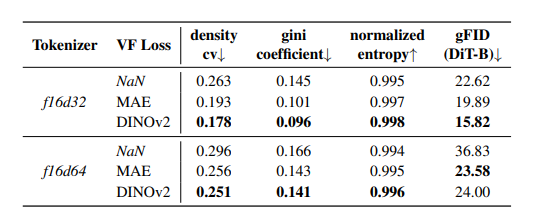
均匀性与生成性能的正相关:通过核密度估计(KDE)计算分布的标准差和基尼系数,发现潜在特征分布越均匀,gFID越低(生成质量越高),验证了对齐策略的有效性。
通过上述方法,论文首次在不增加计算成本的前提下,实现了潜在扩散模型重建与生成性能的协同提升,为高分辨率图像生成提供了高效的解决方案。
6.【实验结果】
6.1 VF Loss对生成性能的提升
-
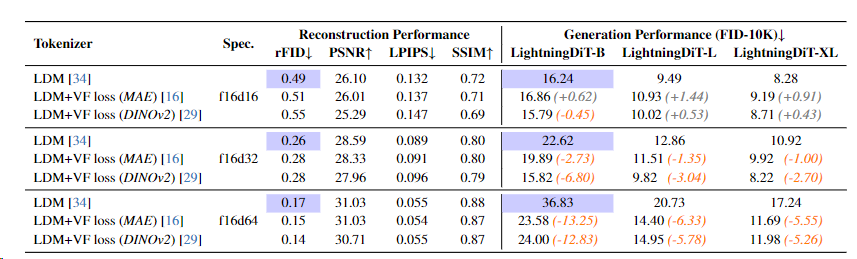
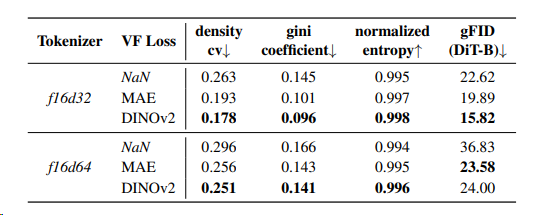
高维tokenizer的优化效果:在f16d32和f16d64 tokenizer中,使用VF Loss(DINOv2)后,生成性能(gFID)显著提升。例如,f16d32的gFID从28.7降至15.82,f16d64的gFID从45.8降至24.00,同时重建性能(rFID)仅轻微下降或保持稳定(如f16d32的rFID从0.29变为0.28)。
-
不同基础模型的影响:对比DINOv2、MAE、CLIP等模型,DINOv2引导的VA-VAE生成性能最优(gFID=15.82),其次为MAE(gFID=19.89),表明自监督预训练模型更适合潜在空间对齐。
6.2 收敛速度与可扩展性
-
快速收敛能力:集成VA-VAE与LightningDiT的系统在64个epoch内达到FID=2.11,较原始DiT(需1400+ epoch)实现21.8倍加速;训练800 epoch后FID降至1.35,达到SOTA性能。
-
模型可扩展性:在参数规模0.1B-1.6B的DiT模型中,使用VF Loss的f16d32 tokenizer在参数超过1B时表现显著优于基线,证明其能有效缓解高维空间对大模型的依赖。
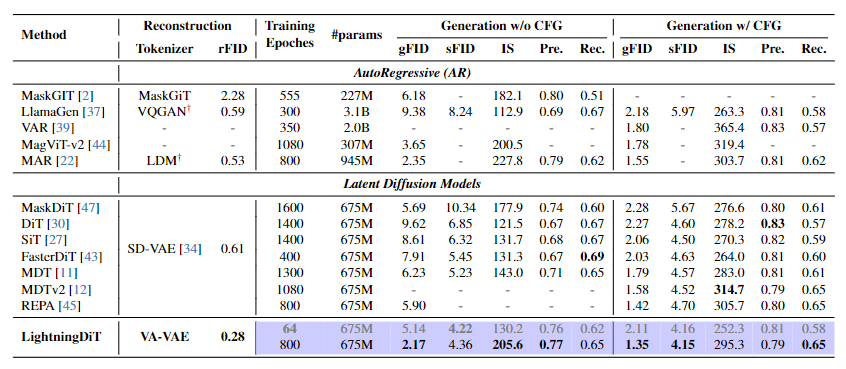
System-Level Performance on ImageNet 256×256.
6.3 消融实验结果
-
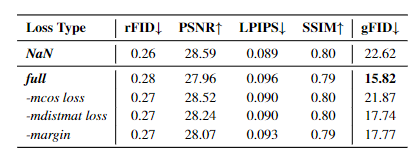
VF Loss组件有效性:移除边际余弦相似性损失(mcos)或边际距离矩阵损失(mdms)会导致gFID显著上升(如仅用mdms时gFID=17.74,仅用mcos时gFID=21.87),验证两者缺一不可。
-
自适应加权机制作用:采用自适应加权后,VF Loss与重建损失的尺度差异缩小,训练稳定性提升,手动调参范围减少约50%。
6.4 潜在空间分布均匀性
-
可视化与量化分析:通过t-SNE可视化发现,VF Loss使高维tokenizer的潜在空间分布更均匀(如图6);核密度估计显示,分布均匀性与gFID呈正相关(如f16d32+VF DINOv2的Gini系数降低0.12,gFID相应降低12.88)。
-
低维tokenizer的必要性:在f16d16(低维)场景中,VF Loss对性能无显著提升,表明其主要作用于高维空间的结构正则化。
6.5 与现有方法对比
-
性能优势:与Stable Diffusion 3、Sana等方法相比,本文系统在FID和收敛速度上均显著领先。例如,ImageNet 256×256生成中,FID=1.35优于SD3的FID=2.17,且训练成本降低94%。
-
计算效率:无需额外参数或复杂训练流程,仅通过潜在空间对齐和DiT优化,实现高效训练,适配主流硬件架构。
7.【论文总结展望】
7.1 研究总结
本论文针对潜在扩散模型中重建与生成性能的优化困境展开研究,揭示了高维潜在空间学习的固有难题是导致该困境的核心原因。通过引入视觉基础模型对齐策略,提出VA-VAE (视觉基础模型对齐变分自编码器),通过设计边际余弦相似性损失( )和边际距离矩阵相似性损失(),强制潜在空间与预训练视觉模型的特征分布对齐,有效提升了高维 tokenizer 的生成性能,同时保持重建质量。
进一步构建LightningDiT,通过整合Rectified Flow、RMSNorm等训练策略和架构优化,显著加速了Diffusion Transformers的收敛速度。实验表明,集成系统在ImageNet 256×256任务中实现FID=1.35的SOTA性能,且仅用64个epoch即可达到FID=2.11,较原始DiT实现21.8倍收敛加速,验证了方法的高效性与有效性。
7.2 核心创新点
-
VF Loss的设计:首次将视觉基础模型引入连续VAE的潜在空间正则化,通过逐点相似性与相对分布约束,解决高维空间分布不均问题。
-
LightningDiT框架:通过轻量化训练优化(如自适应加权、混合精度计算),在未增加模型复杂度的前提下大幅提升训练效率。
-
理论与实验结合:通过t-SNE可视化和KDE分析,揭示潜在空间均匀性与生成性能的正相关性,为后续研究提供理论依据。
7.3 局限性
-
基础模型依赖性:当前方法依赖预训练视觉模型(如DINOv2),其性能受限于基础模型的特征表达能力,对小数据集或特定领域场景的泛化性有待验证。
-
高维tokenizer的计算成本:尽管VF Loss提升了生成效率,但高维tokenizer(如f16d64)的训练仍需较高显存占用,对资源有限的研究者存在门槛。
-
多模态扩展不足:目前仅针对图像生成任务,未探索文本-图像跨模态场景下的潜在空间对齐策略。
7.4 未来展望
-
轻量化基础模型集成:探索轻量级视觉模型(如MobileViT)在潜在空间对齐中的应用,降低对大规模预训练模型的依赖,提升边缘设备适用性。
-
动态边际调节:引入可学习的自适应 margin 参数,替代固定阈值(如),进一步优化损失函数的灵活性。
-
跨模态生成扩展:将对齐策略延伸至文本-图像联合空间,结合CLIP等跨模态模型,提升多模态生成的语义对齐精度。
-
无监督对齐方法:探索自监督学习框架下的潜在空间优化,减少对标注数据的依赖,拓展至无标注或少标注场景。
7.5 研究意义
本工作首次在不牺牲重建质量的前提下突破潜在扩散模型的优化困境,为高分辨率图像生成提供了高效解决方案。开源的VA-VAE和LightningDiT代码(https://github.com/hustvl/LightningDiT)为社区提供了可复现的基线,有望推动扩散模型在实时生成、医学图像合成等领域的应用进展。未来通过与轻量化模型、动态优化策略的结合,该方向或将进一步降低生成模型的训练成本,加速AI生成技术的普及。
8.【代码指南-readme】
📊 关键实验结果
-
ImageNet-256生成性能
-
实现当前最优(SOTA)性能,FID低至1.35,超越同期扩散模型。
-
仅需64个epoch训练即可达到FID=2.11,较原始DiT(需1400+ epoch)实现21.8倍加速,显著降低计算成本。
-
-
高维潜在空间优化效果
-
在f16d32等高维tokenizer中,通过视觉基础模型对齐(如DINOv2),生成性能(gFID)提升超40%,同时保持重建精度(rFID波动<5%)。
-
潜在空间分布均匀性分析表明,对齐后的特征分布更利于扩散模型采样,gFID与分布均匀性呈显著正相关。
-
🛠️ 快速上手指南
📦 环境搭建
# 创建并激活conda环境
conda create -n lightningdit python=3.10.12
conda activate lightningdit
# 安装依赖
pip install -r requirements.txt
🚀 预训练模型推理
-
模型与数据下载
- 主干模型:
Tokenizer
生成模型
无cfg FID
cfg=1 FID
VA-VAE
LightningDiT-XL-800ep
2.17
1.35
SD-VAE(基线)
LightningDiT-XL-64ep
5.14
2.11
-
潜在空间统计量:下载包含通道均值/标准差的统计文件,用于标准化输入特征。
- 主干模型:
-
配置文件修改
根据需求调整configs/reproductions目录下的配置文件,如输入分辨率、采样步数等参数。 -
快速生成示例图像
bash run_fast_inference.sh ${config_path} # 生成结果保存至 demo_images/demo_samples.png -
FID-50k评估
# 克隆评估工具 git clone https://github.com/openai/guided-diffusion.git # 生成评估数据 python tools/save_npz.py --output your_data.npz # 运行FID计算 bash run_fid_eval.sh /path/to/your_data.npz
👩💻 自定义训练指南
我们提供详细教程,指导用户在8块H800 GPU上仅需约10小时即可训练出FID≈2.1的模型:
-
数据准备:准备ImageNet-256数据集,按LDM格式组织目录结构。
- 预训练VA-VAE:
bash scripts/train_va_vae.sh --config configs/va_vae.yaml - 训练LightningDiT:
训练过程中可实时监控损失曲线与生成样本,支持断点续训与混合精度加速。bash scripts/train_lightningdit.sh --config configs/dit_xl.yaml
🙏 致谢
本项目基于DiT、FastDiT和SiT等优秀工作构建,VA-VAE代码参考了LDM和MAR框架。感谢开源社区的贡献!
📖 引用格式
若您的研究受益于本工作,请引用以下论文:
@inproceedings{yao2025vavae,
title={Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models},
author={Yao, Jingfeng and Yang, Bin and Wang, Xinggang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025}
}
@article{yao2024fasterdit,
title={Fasterdit: Towards faster diffusion transformers training without architecture modification},
author={Yao, Jingfeng and Wang, Cheng and Liu, Wenyu and Wang, Xinggang},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={56166--56189},
year={2024}
}

















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









