






2025深度学习发论文&模型涨点之——PINN+KAN
当前PINN结合KAN的研究前沿聚焦于动态自适应机制的设计。
清华大学团队提出的AdaKAN-PINN框架,通过实时监测残差分布动态调整网络宽度与深度,在等离子体湍流模拟中实现了亚网格尺度特征的自主捕获。该系统采用分阶段训练策略:前期利用KAN的符号回归能力解析主导物理模式,后期通过PINN机制补全高阶非线性效应,最终在托卡马克装置参数预测任务中,将误差带从传统方法的±15%收窄至±4.3%。这种分层解耦策略为多物理场耦合问题提供了可扩展解决方案。
我整理了一些PINN+KAN【论文+代码】合集,以需要的同学公众号【AI科研灵感】发666自取。
论文精选
论文1:
Enhancing Physics-Informed Neural Networks with a Hybrid Parallel Kolmogorov-Arnold and MLP Architecture
通过混合并行Kolmogorov-Arnold和MLP架构增强物理信息神经网络
方法
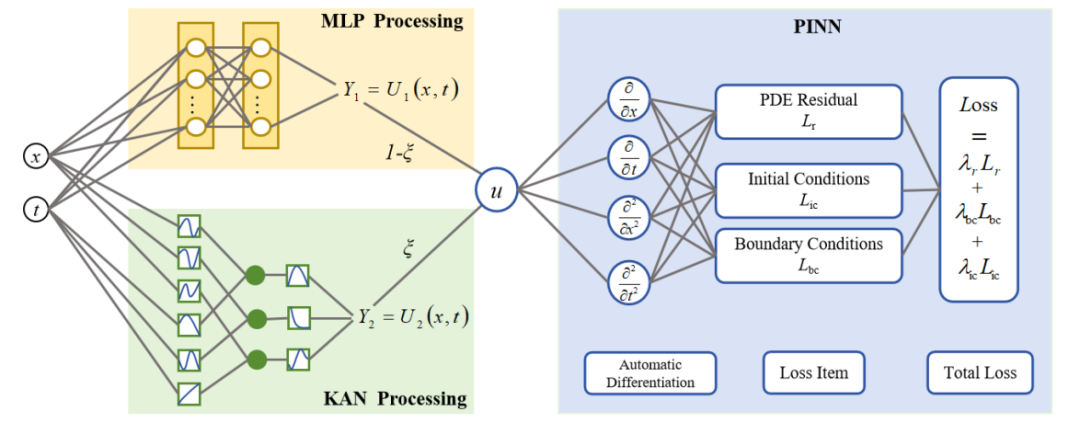
混合并行架构:提出了一种新型的混合并行Kolmogorov-Arnold网络(KAN)和多层感知器(MLP)的物理信息神经网络(HPKM-PINN)架构。
可调参数ξ:引入可调参数ξ,动态平衡KAN的可解释函数逼近和MLP的非线性特征学习,通过加权融合它们的输出来增强预测性能。
系统评估:通过系统数值评估,研究了ξ对模型在函数逼近和偏微分方程(PDE)求解任务中的性能影响。
基准实验:在多个经典PDEs(如泊松方程和对流方程)上进行基准实验,验证了HPKM-PINN的性能。
创新点
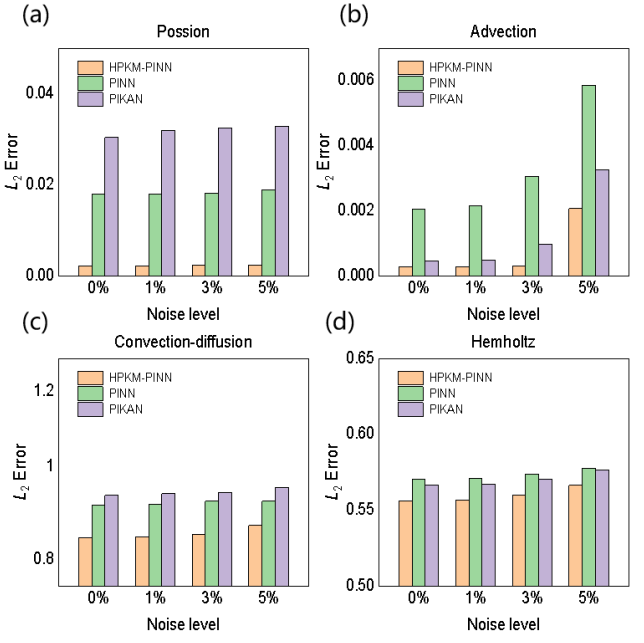
性能提升:在泊松方程实验中,HPKM-PINN的相对误差比单独的KAN或MLP模型降低了两个数量级,具体从KAN的2.31%和MLP的1.84%降低到0.29%。
收敛速度:HPKM-PINN在训练过程中表现出更快的收敛速度,例如在对流方程实验中,HPKM-PINN在10,000次迭代内达到的最小损失值比单独的KAN或MLP模型更快。
泛化能力:在多种物理系统中验证了HPKM-PINN的数值稳定性和鲁棒性,证明了其在解决复杂PDE驱动问题中的通用性和可扩展性。
论文2:
KAN-ODEs: Kolmogorov-Arnold Network Ordinary Differential Equations for Learning Dynamical Systems and Hidden Physics
KAN-ODEs:用于学习动力系统和隐藏物理的Kolmogorov-Arnold网络常微分方程
方法
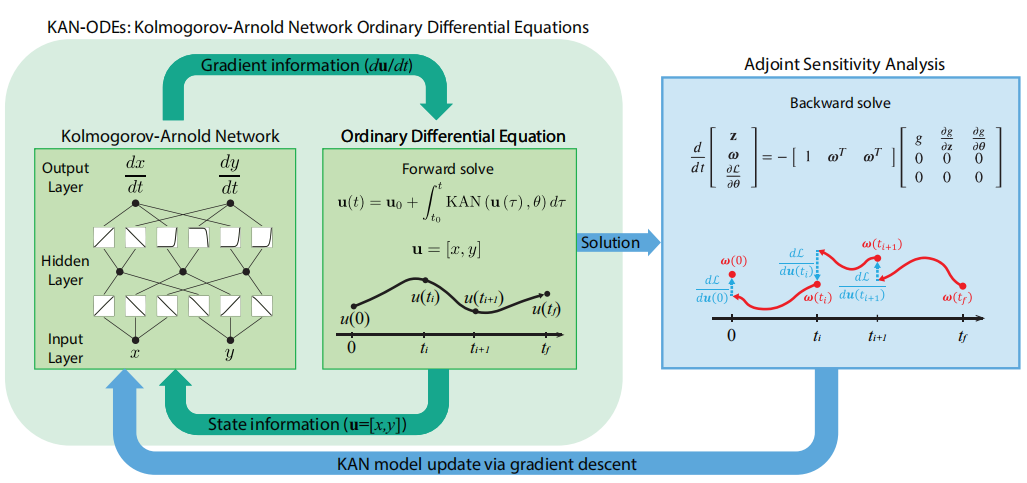
KAN-ODE框架:将Kolmogorov-Arnold网络(KAN)作为神经常微分方程(Neural ODE)框架的骨干网络,应用于时间依赖和时间网格敏感的动力系统和科学机器学习应用中。
KAN结构:基于Kolmogorov-Arnold表示定理,KAN使用可学习的激活函数,这些激活函数由网格化的基函数和相关的可训练缩放因子组成。
训练方法:采用伴随敏感性方法进行训练,通过自动微分技术计算梯度,更新KAN的参数。
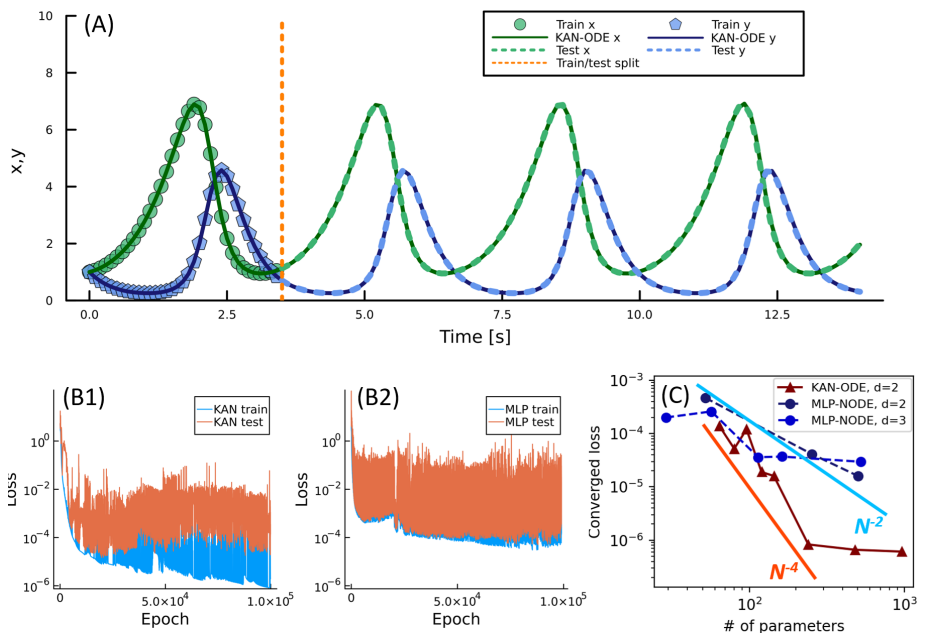
应用验证:在多个经典动力系统模型(如Lotka-Volterra捕食者-猎物模型)中验证了KAN-ODEs的性能。
创新点
性能提升:在Lotka-Volterra捕食者-猎物模型中,KAN-ODEs的训练损失比基于MLP的神经ODEs低两个数量级,具体从MLP的3×10^-5降低到8.3×10^-7。
收敛速度:KAN-ODEs在训练过程中表现出更快的收敛速度,例如在10^5次迭代内达到的最小训练损失比MLP快3-4倍。
论文3:
Learnable Activation Functions in Physics-Informed Neural Networks for Solving Partial Differential Equations
在物理信息神经网络中使用可学习激活函数求解偏微分方程
方法
可学习激活函数:研究了在物理信息神经网络(PINNs)中使用可学习激活函数求解偏微分方程(PDEs)的效果,特别是比较了传统多层感知器(MLP)与固定和可学习激活函数以及Kolmogorov-Arnold网络(KAN)的效果。
最大Hessian特征值分析:通过最大Hessian特征值分析了模型的敏感性和稳定性,提供了关于收敛动态和准确逼近复杂高频模式能力的见解。
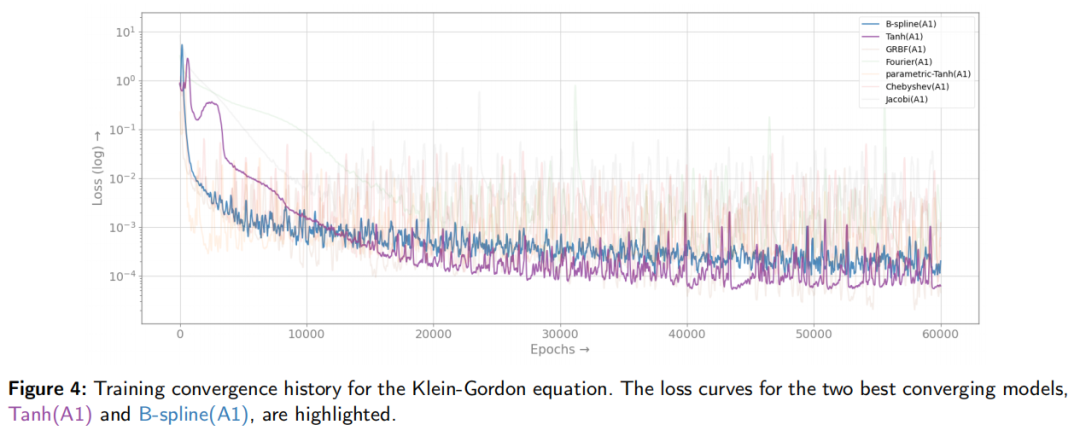
应用验证:在多种PDEs(如Helmholtz、波动、Klein-Gordon、对流-扩散和腔体问题)上验证了方法的有效性。
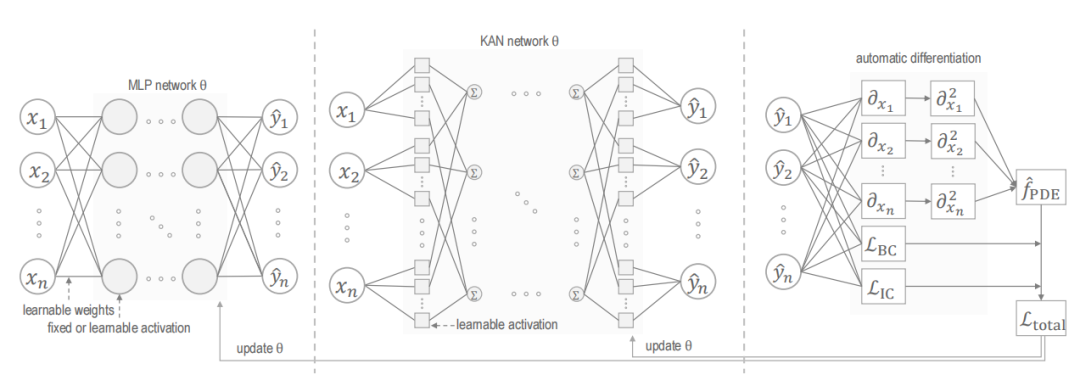
创新点
性能提升:在Helmholtz方程实验中,B-spline(A1)模型的测试误差最低,为1.93%,比其他模型低1-2个百分点。
收敛速度:B-spline(A1)和Fourier(A1)模型在训练过程中表现出更快的收敛速度,例如在10,000次迭代内达到的最小训练损失比其他模型低1-2个数量级。
泛化能力:KAN模型在从有限训练数据中学习符号源项和完整解剖面的能力上表现出色,特别是在高复杂度和数据匮乏的情况下。

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









