






引子:原创选修课报告,是在结课之后上传,主要作用是可以普及一下cpu入门的一些知识。
一CPU发展历史:
CPU 的发展历史是一部不断追求更高性能、更低功耗、更多功能的演进史,主要经历了以下几个阶段:

- 初期阶段(1971 年之前):
- 在 20 世纪 60 年代,计算机处理器还处于大型机和小型机的时代,处理器体积庞大、功耗高且价格昂贵。这些处理器主要由电子管和晶体管组成,运算速度相对较慢,主要应用于科研、军事等领域。

- 诞生与 4 位处理器时代(1971 年 - 1973 年)2:
- 1971 年,Intel 生产的 4004 微处理器将运算器和控制器集成在一个芯片上,标志着 CPU 的诞生。它是一个包含了 2300 个晶体管的 4 位 CPU,时钟频率仅为 108KHz,但这是一个划时代的突破,为后续 CPU 的发展奠定了基础。

- 上图为Intel公司在2021年时候纪念第一块4004的性能对比图
- 8 位处理器时代(1974 年 - 1977 年):
- 1974 年,Intel 推出了 8080 处理器,这是一款 8 位处理器,拥有 6000 个晶体管,运行速度为 2MHz,成为当时最受欢迎的 CPU 之一,广泛应用于个人电脑和工业自动化等领域4。
- 16 位处理器时代(1978 年 - 1984 年):
- 1978 年,Intel 推出了具有重要意义的 16 位微处理器 i8086,同时还生产出与之相配合的数学协处理器 i8087,这两种芯片使用相互兼容的指令集,即 x86 指令集。随后,Intel 又推出了外部总线为 8 位的 8088,方便了计算机制造商设计主板。1981 年,8088 芯片首次用于 IBM PC 机中,开创了全新的微机时代1。
- 1982 年,Intel 推出 80286 芯片,它在 CPU 的内部集成了 13.4 万个晶体管,时钟频率由最初的 6MHz 逐步提高到 20MHz,其内部和外部数据总线皆为 16 位,地址总线 24 位,可寻址 16MB 内存1。
- 32 位处理器时代(1985 年 - 1992 年):
- 1985 年,Intel 推出了 80386 芯片,这是 X86 系列中的第一种 32 位微处理器,制造工艺有了很大进步。80386 内部内含 27.5 万个晶体管,时钟频率从 12.5MHz 发展到 33MHz,地址总线也是 32 位,可寻址高达 4GB 内存124。

-
- 1989 年,Intel 推出 80486 芯片,首次突破了 100 万个晶体管的界限,集成了 120 万个晶体管。它将 80386和数学协处理器 80387 以及一个 8KB 的高速缓存集成在一个芯片内,并在 80x86 系列中首次采用了 RISC(精简指令集)技术,采用突发总线方式,大大提高了与内存的数据交换速度1。
- 奔腾时代(1993 年 - 2005 年)2:
- 1993 年,英特尔推出了 Pentium(奔腾)系列 CPU,该处理器首次采用超标量指令流水结构,引入了指令的乱序执行和分支预测技术,大大提高了处理器的性能。
- Pentium 系列的推出标志着个人电脑性能的飞跃,它不仅在速度上有了显著提升,还支持了多媒体和多任务处理,为用户带来了更加丰富和流畅的计算体验。随着技术的不断进步,奔腾系列也经历了多次升级,包括 Pentium Pro、Pentium II、Pentium III 和 Pentium 4 等,每个新版本都带来了性能的提升和新特性的增加。Pentium 4 甚至引入了超线程技术,允许单个物理处理器模拟出两个逻辑处理器,进一步提高了多任务处理能力。奔腾时代不仅见证了个人电脑的普及,也为现代计算机技术的发展奠定了坚实的基础。
- 多核与高性能时代(2005 年至今):
- 进入 21 世纪后,CPU 技术继续飞速发展。英特尔和 AMD 等厂商不断推出新一代 CPU,从单核到双核、四核、八核甚至更多核心,后续还加上了光锥等附加技术,使得CPU的性能不断提升。同时,CPU 的制造工艺也从微米级发展到纳米级(就比如小米公司最近刚刚完成的5nm级芯片工艺制造),进一步提升了 CPU 的集成度和能效比。
- 在这一时期,多核处理器的普及使得多任务处理和并行计算成为可能,极大地推动了高性能计算的发展。随着核心数量的增加,软件也开始优化以充分利用多核处理器的计算能力。此外,为了应对日益增长的功耗问题,CPU设计者们引入了多种节能技术,如动态频率调整和智能缓存管理,这些技术在不牺牲性能的前提下,有效降低了能耗。
- CPU的架构也经历了重大变革,例如引入了集成内存控制器和高速总线技术,这些改进显著提高了数据传输速度和系统响应时间。同时,随着云计算和大数据的兴起,CPU的设计开始更加注重网络和数据处理能力,以满足大规模数据处理的需求。
- 在竞争激烈的市场中,英特尔和AMD等厂商不断推动技术的边界,推出了具有创新特性的处理器,如超线程技术、Turbo Boost技术以及针对特定应用优化的加速指令集。这些技术的引入,不仅提升了CPU的性能,也使得个人电脑和服务器能够更好地适应各种计算密集型任务。
- 多核与高性能时代的CPU发展,不仅体现了技术的不断进步,也反映了计算需求的日益增长和多样化。随着技术的不断演进,未来的CPU将更加智能化、高效化,
-
- 为用户带来前所未有的计算体验。

附上一张2024年最新的CPU的性能天梯图
- 最新的成果:
- 英特尔酷睿 Ultra 系列:
- 英特尔在 2024 年推出了酷睿 Ultra 系列处理器,该系列采用了全新的架构和技术,为笔记本电脑带来了更高的性能和更低的功耗。例如酷睿 Ultra 5 200 和酷睿 Ultra 7 200 等型号,在多任务处理、图形处理等方面都有显著的提升,为用户提供了更流畅的使用体验。
- AMD Ryzen 7000 系列:
- AMD 的 Ryzen 7000 系列处理器是其最新的桌面级 CPU 产品,采用了先进的制程工艺和架构设计,拥有出色的性能表现。该系列处理器在单核性能和多核性能上都有很大的提升,能够满足游戏玩家、专业创作者等对高性能 CPU 的需求。
- 龙芯 3C60002:
- 龙芯中科技术股份有限公司自主研发的服务器 CPU 龙芯 3C6000 成功完成流片。与上一代产品龙芯 3C5000 相比,龙芯 3C6000 的通用处理性能成倍提升,其性能已达到英特尔公司推出的中高端产品至强(Xeon)Silver4314 处理器的水平,可满足通用计算、大型数据中心、云计算中心的计算需求。龙芯中科计划在 2024 年四季度发布该处理器。

- 龙芯中科技术股份有限公司自主研发的服务器 CPU 龙芯 3C6000 成功完成流片。与上一代产品龙芯 3C5000 相比,龙芯 3C6000 的通用处理性能成倍提升,其性能已达到英特尔公司推出的中高端产品至强(Xeon)Silver4314 处理器的水平,可满足通用计算、大型数据中心、云计算中心的计算需求。龙芯中科计划在 2024 年四季度发布该处理器。
- ARM Cortex-X925 和 Immortalis G9257:
- ARM 公司发布的面向旗舰智能手机的下一代 CPU 和 GPU 设计。Cortex-X925 CPU 相比上一代 X4 的 Geekbench 单核性能提升 36%,且其 AI 工作负载性能提高了 41%;同时还有新一代的 Cortex-A 微架构(“小” 核),在处理日常任务时更加高效。Immortalis G925 图形处理器被 ARM 宣称为迄今为止 “性能最强、效率最高的图形处理器”,在图形应用、AI 和 ML 任务处理等方面都有出色的性能和能效表现。预计搭载该系列的手机将于 2024 年底上市。
- FlowComputing 的 PPU 技术:
- 芬兰的初创公司 FlowComputing 研发出的并行处理单元(PPU)技术可能会让现有 CPU 的性能直接提升 100 倍。PPU 能够用于任何 CPU 架构中,包括桌面和移动处理器,并兼容目前的应用程序,能够自动识别代码中的并行部分并自动执行,有望为 CPU 性能的提升带来新的突破。不过该技术的具体细节将于 2024 年下半年公布。
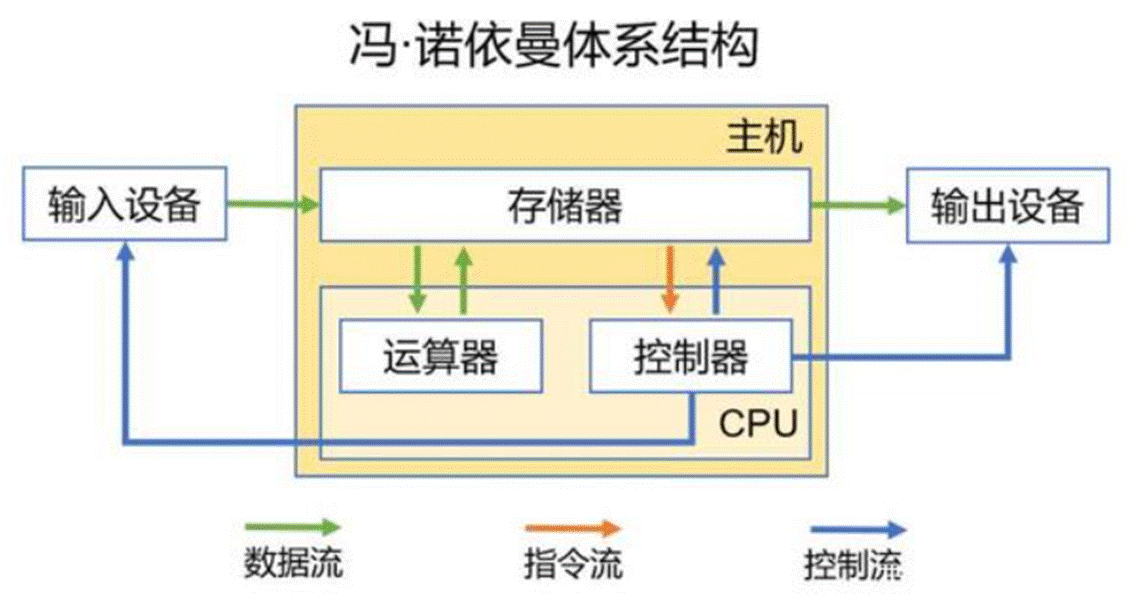
二、CPU原理介绍
CPU(中央处理器)是计算机硬件的核心部件,负责执行程序指令、处理数据和控制计算机的其他硬件部件。
- 算术逻辑单元(Arithmetic Logic Unit,ALU)
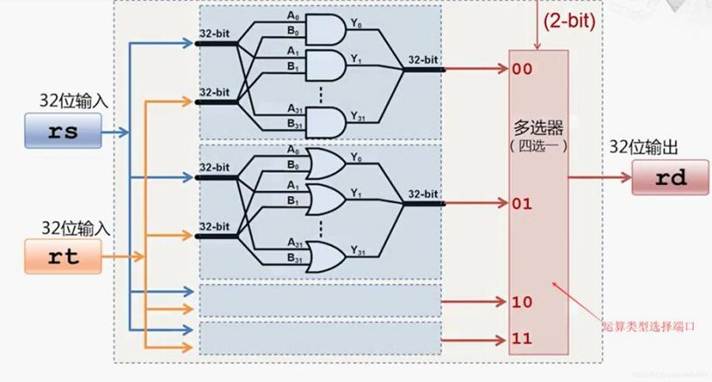
- 功能:
ALU 是 CPU 进行数据运算的关键部分,它能够执行诸如加、减、乘、除等基本算术运算,同时也可以处理逻辑运算,像与、或、非、异或等逻辑操作。例如,当我们在计算机上进行简单的数学计算,如 “3 + 5” 时,就是 ALU 来完成加法运算,得出结果为 8;再比如在判断一个条件语句是否满足时,像 “如果变量 A 大于 10 且小于 20”,ALU 会进行相应的逻辑比较运算,判断该条件的真假。 - 工作原理:
ALU 接收来自寄存器或其他数据存储单元的数据,按照指令所规定的运算类型进行操作。它内部有着各种逻辑门电路(如与门、或门、非门等通过组合构建复杂的运算电路),这些电路依据布尔逻辑规则来对输入的数据进行相应的变换和运算,运算完成后再将结果输出到指定的寄存器或者其他相关单元,以便后续的处理或存储。
2. 寄存器(Registers)
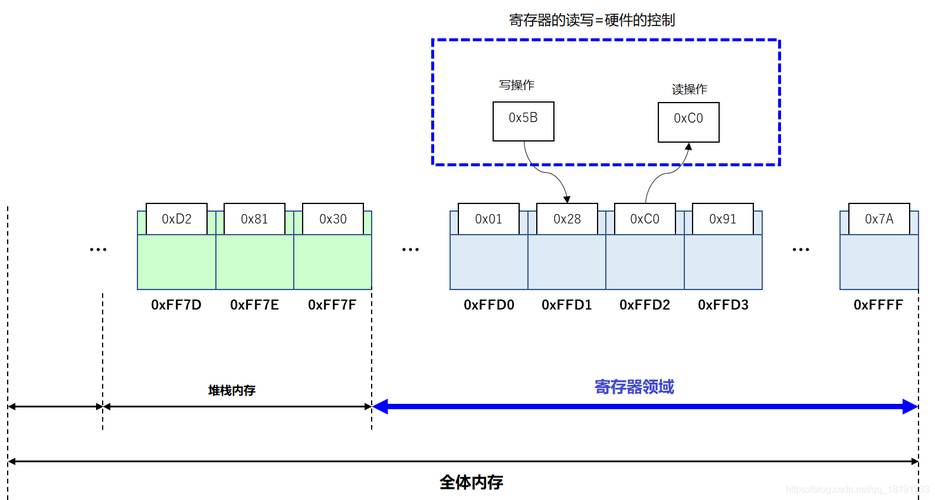
- 功能:
寄存器是 CPU 内部用来暂时存放数据和指令的高速存储单元,它们的访问速度极快,远远快于计算机的主存储器(如内存)。寄存器有着不同的用途,比如通用寄存器可以用来存放参与运算的数据、运算的中间结果等;程序计数器(Program Counter,PC)则用于存储下一条要执行的指令在内存中的地址,通过不断更新这个地址,使得 CPU 能按顺序从内存中获取指令依次执行;指令寄存器(Instruction Register,IR)用来存放当前正在执行的指令代码,便于 CPU 对指令进行译码等后续操作。 - 工作原理:
以通用寄存器为例,当 CPU 需要对某个数据进行运算时,会先将数据从内存加载到通用寄存器中,ALU 就可以直接从这些寄存器获取数据进行运算,运算结束后,结果又可以暂存回寄存器或者根据指令要求写回到内存等其他存储位置。程序计数器在每次指令执行完后,会自动更新为下一条指令对应的内存地址(一般是按照顺序增加,不过遇到跳转等指令时会改变其值,使其指向跳转后的指令地址),从而保证指令的有序执行。
- 控制单元(Control Unit)
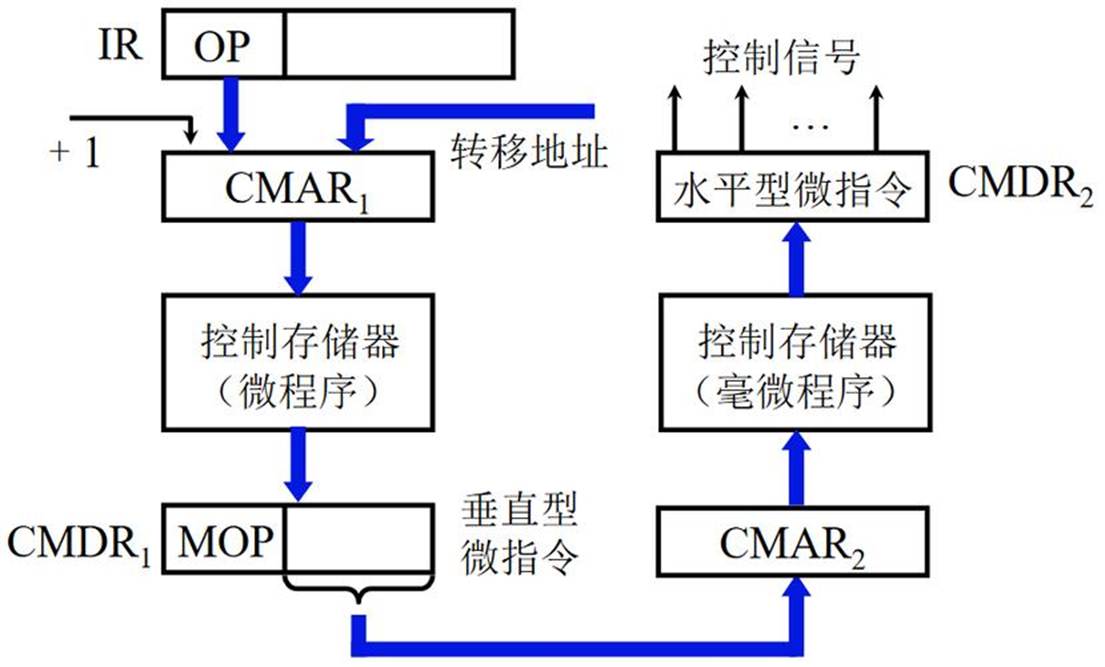
- 功能:
控制单元是整个 CPU 运行的指挥中心,它负责协调和控制 CPU 内部各个部件以及 CPU 与计算机其他硬件组件(如内存、硬盘、输入输出设备等)之间的协同工作。它决定了哪些指令在什么时候被执行,数据如何在各个部件之间流动等关键操作。例如,当我们启动一个程序,控制单元会指挥从硬盘把程序加载到内存,然后按照程序中的指令序列,依次安排从内存读取指令到 CPU,再指挥 ALU 进行相应运算,以及将结果存回合适的地方等一系列复杂的流程。 - 工作原理:
控制单元根据指令寄存器中的指令代码进行译码,分析出这是一条什么类型的指令(是算术运算、逻辑运算、数据传输还是控制转移等指令),然后依据指令的具体要求,产生相应的控制信号。这些控制信号就像是一个个 “命令”,发送到 CPU 内部的各个部件以及计算机系统的相关硬件接口上,使得各个部分按照规定的步骤和顺序完成相应的操作。比如,当要执行一条从内存读取数据到寄存器的指令时,控制单元会向内存的控制电路发送读信号,同时控制寄存器做好接收数据的准备,协调数据沿着正确的线路传输过来。
CPU 的指令集
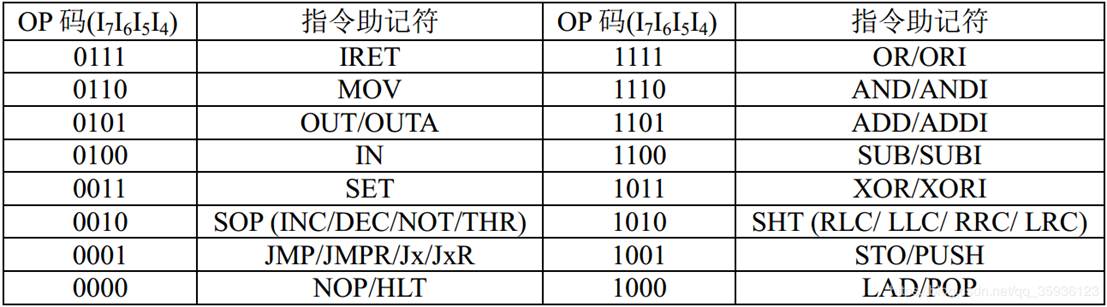
指令集与CPU架构
1. 指令集的概念
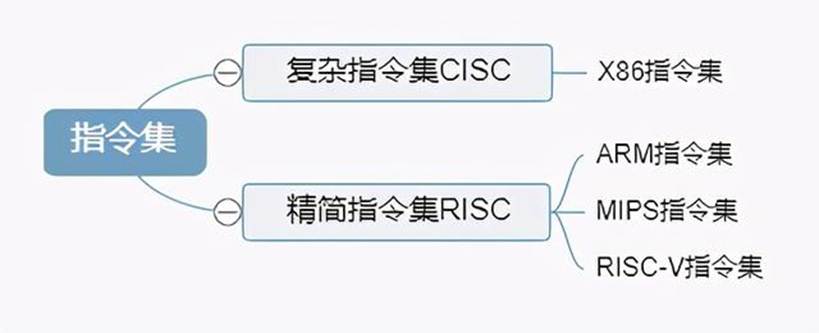
指令集是 CPU 能够识别和执行的所有指令的集合,它定义了 CPU 的基本功能和操作方式。不同的 CPU 架构往往有着不同的指令集,常见的指令集架构有复杂指令集(CISC,如英特尔的 x86 架构)和精简指令集(RISC,如 ARM 架构)。
2. 复杂指令集(CISC)
- 特点:
CISC 的指令数量较多,指令格式和长度往往各不相同,一条指令可以完成相对复杂的多个操作步骤。例如在早期的 x86 架构中,一条指令可能既包含了从内存读取数据、进行算术运算,又包含了将结果写回内存等多个功能。它的目的是为了方便程序员编写程序,使得程序代码相对简洁,因为可以用一条复杂指令完成很多工作。 - 优缺点:
优点在于编写高级语言程序时,编译器可以将高级语言语句比较直接地转换为对应的复杂指令,编程相对方便;但缺点是由于指令复杂,使得 CPU 内部的电路设计变得复杂,在执行指令时,为了处理不同长度和格式的指令,需要花费更多的时间进行译码等操作,影响了执行效率,并且复杂的电路也增加了芯片的功耗和设计难度。
3. 精简指令集(RISC)
- 特点:
RISC 指令集的指令数量相对较少,指令格式较为规整、长度固定,每条指令一般只完成一个简单且基本的操作,像单纯的加法运算、数据加载、数据存储等操作都是由单独的指令来完成。例如 ARM 架构下,很多指令都是简单明了的,执行特定的单一功能。 - 优缺点:
其优点在于由于指令简单、规整,CPU 的硬件设计可以更加简化,在执行指令时译码等操作速度更快,能够在一个时钟周期内执行一条指令,提高了 CPU 的运行效率,并且功耗相对较低,适合用于移动设备等对功耗要求较高的场景。然而,对于程序员或者编译器来说,可能需要用更多条的简单指令去组合完成复杂的任务,相比 CISC 在代码编写上可能会显得略微繁琐一些。
CPU 的工作流程
1. 取指阶段
程序在运行前会被加载到内存中,计算机启动后,CPU 的控制单元会指挥将程序计数器(PC)中的初始地址所指向的内存位置的指令取出来,这个地址一般是程序的第一条指令所在位置。通过内存的数据总线,将这条指令读取到 CPU 的指令寄存器(IR)中,然后程序计数器自动指向下一条指令的地址(通常是当前地址加一个固定的值,比如 4 字节,取决于指令的长度格式等情况),准备取下一条指令。
- 译码阶段
指令寄存器(IR)中的指令被送到控制单元后,控制单元会对其进行译码操作,分析这条指令到底是让 CPU 执行什么样的操作,是进行算术运算、逻辑判断、数据的读取还是写入,或者是控制转移到其他的指令地址等等。根据指令集的定义,识别出指令中操作码对应的具体功能以及操作数所在的位置等关键信息。
3. 执行阶段
根据译码得到的结果,如果是算术运算指令,控制单元就会指挥算术逻辑单元(ALU)从相应的寄存器或者内存位置获取操作数,然后进行规定的算术运算;如果是逻辑运算指令,同样由 ALU 按照逻辑规则进行操作;若是数据传输指令,就会协调数据在寄存器、内存等不同存储单元之间按照要求进行传输;而要是控制转移指令(比如跳转、循环等),则会改变程序计数器(PC)的值,使其指向跳转后的指令地址,从而改变程序的执行顺序。
4. 写回阶段
在执行阶段得到的运算结果或者从其他地方获取的数据,如果需要存储到寄存器或者内存等指定位置,在这个阶段就会按照指令要求完成写回操作。比如,一次加法运算的结果要存到某个通用寄存器中,就会将结果通过数据总线传输到对应的寄存器中保存起来,以备后续指令继续使用,或者将数据写回内存中相应的存储单元,完成数据的更新等操作。
整个过程会循环往复,一条指令执行完后接着执行下一条指令,就这样不断地从内存取指、译码、执行、写回,使得整个计算机程序得以有序运行,实现各种复杂的功能,如文字处理、图形渲染、网络通信等。
三、CPU性能参数
一、主频(Clock Speed)
1. 定义及基本原理
主频也称作时钟频率,它代表着 CPU 内核工作时的时钟脉冲频率,其单位通常为赫兹(Hz),在实际应用中,常见的单位是兆赫兹(MHz)和吉赫兹(GHz)。可以将 CPU 的工作想象成按照固定节奏进行的一系列操作,而这个节奏就是由主频来设定的。例如,一颗 CPU 的主频为 3.0GHz,那就意味着每秒钟其内部的时钟信号会产生 30 亿个周期,每个周期内 CPU 能够完成特定的操作,不过不同指令在不同架构下每个周期所完成的实际工作量会有所差异。
2. 对性能的影响
正向影响:在其他条件相同的情况下,主频越高,CPU 在单位时间内能够处理的指令数量理论上也就越多,从而使计算机系统的运行速度更快。比如在运行一些单线程的简单程序,像只进行简单数学运算的小程序时,较高的主频可以让运算过程迅速完成,减少用户等待的时间。
限制因素:然而,实际情况中主频对性能的提升并非是无限制的线性关系。一方面,随着主频的不断升高,CPU 的发热量会急剧增加,过高的热量可能导致 CPU 出现不稳定的状况,例如出现死机、自动重启等现象,甚至长期处于高温环境下还可能损坏 CPU 芯片,所以现代 CPU 在提升主频时往往需要兼顾散热问题,这就限制了主频能够提升的幅度。另一方面,CPU 的性能还受到指令集效率、缓存等其他众多因素的综合影响,单纯依靠提高主频并不一定能使 CPU 的整体性能按比例得到显著提升。例如,若指令集设计不够高效,即便主频很高,在执行复杂指令时,由于需要花费更多时间进行译码等操作,实际执行效率也未必理想;再比如缓存如果过小或者命中率较低,频繁从相对较慢的内存中读取数据,也会拖慢整体性能,即便主频高也难以充分发挥优势。
二、核心数(Number of Cores)
1. 概念阐述
核心数指的是 CPU 芯片内部集成的能够独立执行指令的处理单元数量。从早期的单核 CPU 发展至今,常见的 CPU 已经有双核、四核、六核甚至更多核心的产品。每个核心在功能上都类似于一个独立的 CPU,可以并行地处理不同的指令流,就好比多个大脑同时在为计算机系统工作一样。
2. 多核心在不同场景下对性能的影响
多任务处理场景:在如今多任务并行的使用环境下,比如用户一边在电脑上播放高清视频,一边使用办公软件编辑文档,同时还在后台进行文件下载等操作,更多的核心数能够带来显著的性能提升。不同的核心可以分别负责不同程序的指令执行,使得各个程序都能相对流畅地运行,避免出现因单个核心处理能力有限而导致程序卡顿的情况。例如,在一个四核 CPU 的计算机中,操作系统可以将播放视频的任务分配到一个核心上,文档编辑任务分配到另一个核心,文件下载任务再分配到另外两个核心,通过这样的并行处理,多个任务可以同时高效推进。
单线程程序场景:不过,对于一些单线程的程序,也就是只能按照顺序在一个核心上执行指令的程序而言,核心数再多,其性能提升也相对有限。像一些老旧的单线程游戏或者特定的单线程专业软件,它们无法充分利用多个核心的并行处理能力,此时 CPU 的性能主要还是取决于单个核心的性能表现,例如单个核心的主频、指令集执行效率等因素。但随着软件技术的发展,越来越多的软件开始进行多线程优化,以更好地适配多核 CPU,从而充分发挥多核的优势。
三、缓存(Cache)
1. 缓存的分类及特点
缓存是位于 CPU 内部的一种高速缓冲存储器,其速度相较于计算机的主存储器(如内存)要快得多。按照与 CPU 核心距离的远近以及容量大小等因素,缓存一般分为一级缓存(L1 Cache)、二级缓存(L2 Cache),不少 CPU 还有三级缓存(L3 Cache)等。
一级缓存(L1 Cache):它距离 CPU 核心最近,数据读取和写入的速度是最快的,但由于受到芯片面积等因素限制,其容量通常比较小,一般只有几十 KB 到几百 KB。例如,英特尔的某些早期 CPU 的一级缓存可能只有 32KB 左右,主要用于存放 CPU 最急需、最常使用的指令和数据,像 CPU 在执行一条指令时,下一条可能紧接着要执行的指令以及与之相关的操作数等往往会暂存在一级缓存中,以便 CPU 能快速获取并执行。
二级缓存(L2 Cache):二级缓存的速度稍逊于一级缓存,但容量相对更大一些,通常在几百 KB 到几 MB 之间。它起到了进一步缓冲数据的作用,当一级缓存中没有 CPU 所需的数据时,就会到二级缓存中查找。例如,在循环执行一段代码时,第一次执行时相关数据可能被加载到一级缓存,但如果一级缓存已满且后续还需要用到这些数据,那么这些数据就可能被转移到二级缓存中暂存,下次循环时 CPU 可以较快地从二级缓存中获取,避免了直接从相对缓慢的内存中读取。
三级缓存(L3 Cache):三级缓存离 CPU 核心相对更远一些,不过它的容量可以做得更大,常见的有几 MB 到几十 MB,在一些高端 CPU 中甚至可以达到上百 MB。它的作用是在一级、二级缓存都未命中的情况下,为 CPU 提供数据缓存服务,虽然其速度比前两级缓存慢一点,但相较于内存来说还是快很多,能有效减少 CPU 访问内存的次数,提高整体运行效率。
2. 缓存对性能的影响机制
缓存的大小、速度以及命中率(即 CPU 在缓存中能找到所需数据的概率)等因素对 CPU 的性能起着至关重要的作用。当 CPU 需要读取数据或指令时,会按照一级缓存、二级缓存、三级缓存这样的顺序依次查找,如果在缓存中能够找到相应内容,就可以直接快速获取并使用,极大地缩短了数据访问时间,从而提升整个 CPU 的运行效率。例如,在运行一个大型软件时,软件的核心代码和频繁使用的数据如果能被缓存起来,CPU 在多次调用这些内容时无需再去内存中慢慢搜索,直接从缓存中提取即可,这使得软件的运行速度明显加快。相反,如果缓存容量过小或者命中率过低,CPU 就不得不频繁地从内存中读取数据,而内存的读写速度相对缓存来说要慢得多,这就会导致 CPU 花费大量时间等待数据传输,进而拖慢整个系统的运行速度。
四、指令集架构(Instruction Set Architecture)
1. 主要指令集架构类型及特点
复杂指令集(CISC,Complex Instruction Set Computer):
指令特点:CISC 的指令数量众多,指令格式和长度变化多样,一条指令往往可以完成相对复杂的多个操作步骤。例如在英特尔的 x86 架构(典型的 CISC 架构)中,一条指令可能既包含了从内存读取数据、进行算术运算,又包含了将结果写回内存等多个功能。其设计初衷是为了方便程序员编写程序,程序员可以用相对简洁的代码来实现复杂功能,因为很多复杂操作可以通过一条指令来完成,减少了指令的编写数量。
性能影响:从性能角度来看,这种架构在执行指令时,由于指令复杂,使得 CPU 内部的电路设计变得复杂,需要花费更多的时间进行译码等操作来分析指令具体要执行的功能和操作数情况,这在一定程度上影响了执行效率。而且复杂的电路也导致芯片的功耗增加,同时设计难度也相应提高。不过在一些传统的桌面计算机应用场景中,尤其是运行一些对性能要求不是极高、但代码编写便利性很重要的软件时,CISC 架构凭借其对高级语言良好的编译适配性等优势,依然有着广泛的应用。
精简指令集(RISC,Reduced Instruction Set Computer):
指令特点:RISC 指令集的指令数量相对较少,指令格式较为规整、长度固定,每条指令一般只完成一个简单且基本的操作,像单纯的加法运算、数据加载、数据存储等操作都是由单独的指令来完成。例如 ARM 架构(广泛应用于移动设备等领域的 RISC 架构)下,指令清晰明了,便于硬件快速执行。
性能影响:其优点在于由于指令简单、规整,CPU 的硬件设计可以更加简化,在执行指令时译码等操作速度更快,能够在一个时钟周期内执行一条指令,提高了 CPU 的运行效率,并且功耗相对较低,非常适合用于移动设备等对功耗要求较高的场景。然而,对于程序员或者编译器来说,可能需要用更多条的简单指令去组合完成复杂的任务,相比 CISC 在代码编写上可能会显得略微繁琐一些。但随着编译技术的不断优化,这种情况也在逐步改善,如今 RISC 在诸如智能手机、平板电脑等众多移动设备以及一些对功耗和效率有特殊要求的嵌入式系统中占据着主导地位。
2. 指令集对软件兼容性及性能发挥的作用
不同的指令集架构决定了 CPU 能够识别和执行的指令集合,进而影响了软件的兼容性和性能发挥。软件在开发时需要针对特定的指令集进行编译,如果一款软件是基于某种指令集架构编译的,那么它只能在支持该指令集的 CPU 上运行。例如,为 x86 架构编译的 Windows 操作系统软件,就无法直接在采用 ARM 架构的 CPU 上正常运行,除非进行专门的移植和适配工作。而且即使软件能够在不同指令集架构的 CPU 上运行,由于指令集执行效率等方面的差异,其性能表现也会大不相同。比如同样是一款图形处理软件,在基于 CISC 架构的高性能桌面 CPU 上运行时,可能凭借其复杂指令能够较快地处理一些复杂的图形算法;而在基于 RISC 架构的移动设备 CPU 上运行时,可能就需要通过优化软件代码,利用多个简单指令的组合来完成同样的任务,速度上可能会稍慢一些,但在功耗控制方面会更具优势。
五、制造工艺(Manufacturing Process)
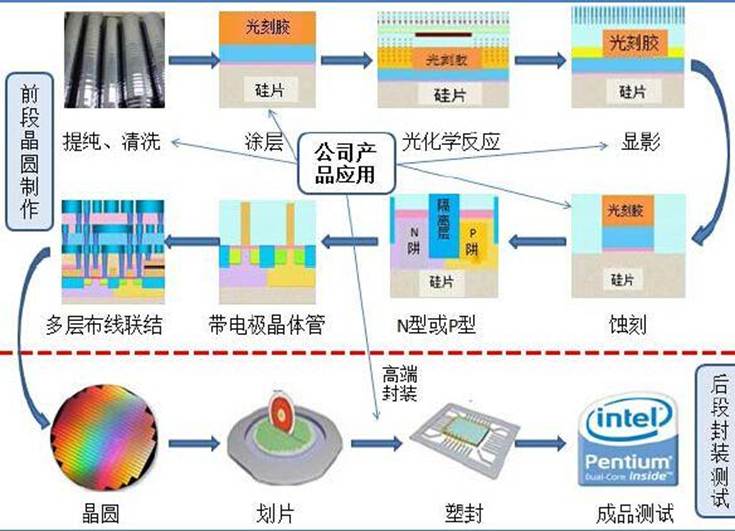
1. 制造工艺的衡量标准及含义
制造工艺通常用纳米(nm)来衡量,它指的是在芯片制造过程中,晶体管等电子元件在硅片上的最小尺寸。例如,当前先进的 CPU 制造工艺已经可以达到 7nm、5nm 甚至更小的尺度。可以简单理解为,更小的制造工艺意味着在同样大小的芯片面积上能够集成更多的晶体管,就如同在同样一块土地上可以盖更多更小的房子一样。同时,随着晶体管尺寸的缩小,其开关速度能够更快,也就是晶体管从导通状态转变为截止状态以及反之的速度会提升,并且功耗也能更低,因为在开关过程中消耗的电能会随着尺寸变小而减少。
2. 制造工艺对 CPU 性能及其他方面的影响
性能提升方面:随着制造工艺的不断进步,芯片能够容纳更多的功能单元,比如可以增加核心数、扩大缓存容量等,使 CPU 的整体性能得到很大提高。以核心数增加为例,更小的制造工艺可以让芯片在有限的面积内集成更多的核心,实现更强的并行处理能力,满足多任务、多线程复杂应用的需求。同时,由于晶体管性能提升,也为 CPU 的主频提升创造了空间,使得 CPU 在单位时间内能够处理更多的指令。例如,从 14nm 工艺升级到 7nm 工艺的 CPU,往往可以在保持功耗大致不变的情况下,实现核心数增加或者主频适度提高等性能优化。
功耗及散热方面:更低的功耗是制造工艺进步带来的另一个重要优势。在运行时,采用更先进制造工艺的 CPU 产生的热量更少,这有助于提高 CPU 的稳定性,减少因过热导致的性能下降、死机等问题,同时也延长了 CPU 的使用寿命。对于一些对功耗敏感的设备,如笔记本电脑、智能手机等,降低功耗就意味着可以延长设备的续航时间,提升用户的使用体验。而且热量产生少了,对计算机的散热系统要求也相应降低,使得电脑等设备可以设计得更加轻薄、便携,在散热设计方面也能节省成本和空间。
六、线程数(Thread Count)
1. 线程的概念及与核心数的关系
线程是 CPU 调度和执行的基本单位,一个线程可以理解为是 CPU 执行的一个独立的指令流。线程数与核心数密切相关,一般情况下,现代 CPU 存在两种线程模式:
物理核心对应单线程(传统模式):早期的 CPU 每个物理核心通常只对应一个线程,也就是单核单线程,这样 CPU 在同一时间只能处理一个指令流,执行效率相对有限,尤其是在多任务环境下容易出现卡顿现象。
超线程技术(Hyper-Threading Technology):后来出现了超线程技术,例如英特尔的一些 CPU 采用了这种技术,它允许一个物理核心同时处理两个线程,也就是在一个物理核心内部模拟出两个逻辑核心,这样在操作系统看来就好像有更多的核心存在一样。通过超线程技术,CPU 可以在同一个时钟周期内,根据指令的情况,交替执行两个线程中的指令,在一定程度上提高了 CPU 的利用率,特别是对于多任务处理以及一些多线程软件的运行有一定的性能提升作用。比如在处理多个网页浏览任务或者同时运行多个办公软件时,超线程技术可以让 CPU 更高效地分配资源,减少任务切换时的等待时间。
2. 线程数对不同应用场景性能的影响
多线程应用场景:在多线程应用中,更多的线程数往往意味着更好的性能表现。例如,在视频编辑软件中,视频的渲染、音频的处理、特效的添加等多个环节都可以作为不同的线程来并行处理,当 CPU 的线程数足够多时,就能同时处理这些不同的任务,大大缩短视频编辑的整体时间。再比如在 3D 游戏中,游戏中的场景绘制、物理模拟、角色动画等多个部分也可以通过多线程并行执行,提高游戏的帧率和流畅度,让玩家有更好的游戏体验。
单线程应用场景:不过对于单线程的应用,线程数的增加并不能直接带来性能提升,因为单线程应用只能利用一个线程来执行指令,主要还是取决于单个核心以及该核心对应的线程执行效率等因素。例如一些老旧的单线程数据库管理程序,其运行速度主要还是由其运行的单个核心的性能决定,即便 CPU 具备超线程等多线程技术,也无法使这类程序运行得更快。
七、字长(Word Length)
1. 字长的定义及意义
字长指的是 CPU 在一次操作中能够处理的二进制数据的位数,通常以位(bit)为单位。常见的字长有 8 位、16 位、32 位和 64 位等。字长反映了 CPU 的数据处理能力,字长越长,CPU 能够一次性处理的数据量就越大,运算精度也越高。例如,8 位的 CPU 在处理数据时,一次只能处理 8 个二进制位的数据,而 64 位的 CPU 一次则可以处理 64 个二进制位的数据,相当于可以处理更大范围、更高精度的数据。
2. 不同字长在不同时代及应用场景的作用
早期阶段及简单应用场景:在计算机发展的早期,像 8 位 CPU 时代,主要应用于一些简单的电子设备,如早期的游戏机、简单的计算器等,它们处理的数据量小、运算要求简单,8 位的字长足以满足基本的功能需求,例如在游戏机中显示简单的图形、处理简单的游戏逻辑等。
发展阶段及复杂应用场景:随着计算机技术的发展,出现了 16 位、32 位的 CPU,其应用范围逐渐扩大到早期的个人计算机等领域,可以运行简单的操作系统、文字处理软件等,能够处理相对复杂一些的数据和任务。例如,32 位的 CPU 有更大的寻址空间,可以更好地支持内存管理和运行一些稍复杂的应用程序。
四、CPU测试描述
基准测试:
原理:通过设计科学的测试方法、测试工具和测试系统,对 CPU 的某项性能指标进行定量的和可对比的测试。可测量、可重复、可对比是基准测试的三大原则。
常用软件及测试内容:
Cinebench:这是一款很流行的 CPU 基准测试软件。它基于著名的 3D 建模软件 Cinema 4D 的内核开发,可以分别测试 CPU 的单核性能和多核性能。例如,在 Cinebench R23 中,会给出 CPU 单核和多核的跑分成绩,分数越高代表 CPU 在该方面的性能越强。通过该软件,可以直观地对比不同 CPU 之间的性能差异,了解待测 CPU 在渲染、建模等场景下的表现能力。

俗称C4D是动画建模的必备软件,我就有,用来搭配AE和PR
Geekbench:它是一个跨平台的 CPU 性能测试工具,支持 Windows、macOS、Linux 等多种操作系统。Geekbench 不仅可以测试 CPU 的整数运算能力、浮点运算能力,还能测试内存性能等。测试完成后会生成一个综合的分数,方便用户快速了解 CPU 的整体性能水平,以及与其他 CPU 的对比情况。
压力测试:
原理:检查 CPU 在重负载下的性能表现以及系统在此情况下的温度等状况。压力测试可以帮助用户了解 CPU 在长时间高负荷运行下的稳定性和可靠性。
常用软件及测试内容:
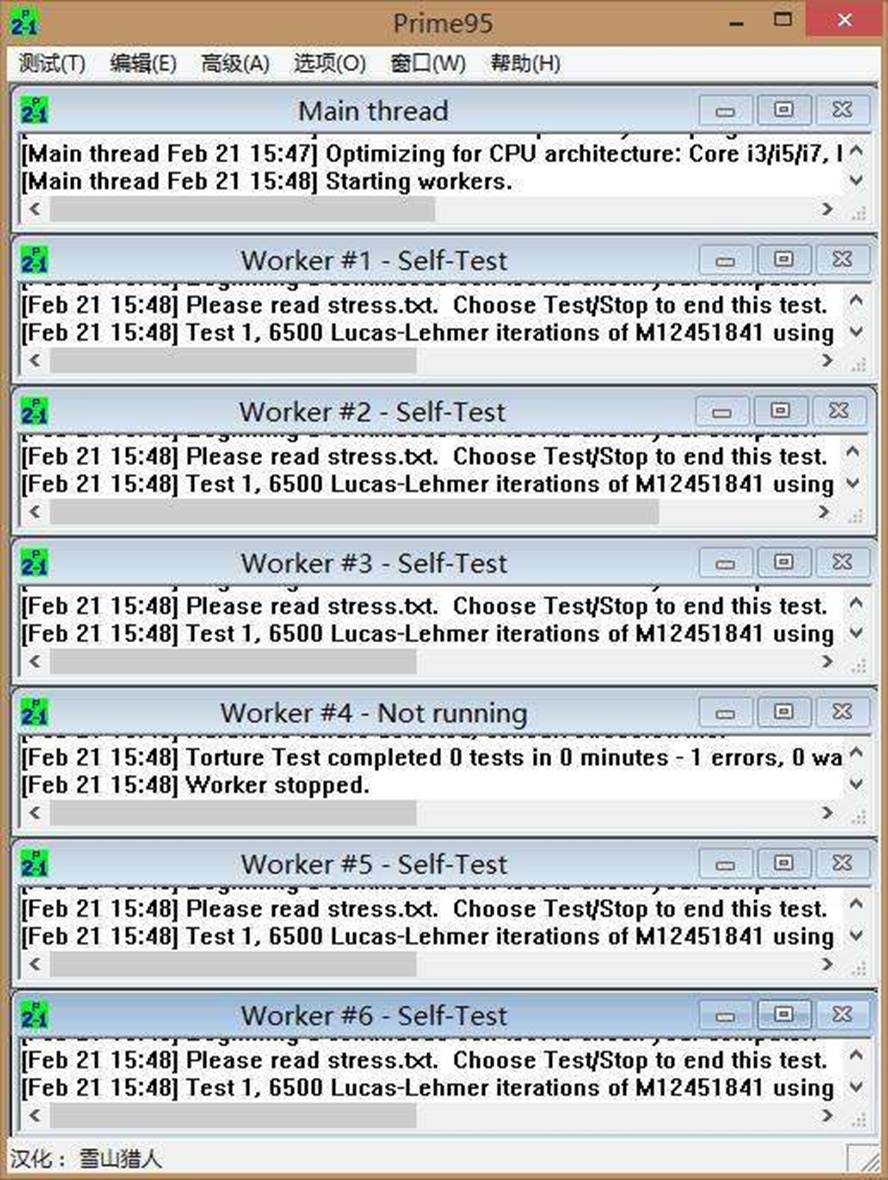
上图是Prime95的测试界面
Prime95:这是一款专门用于 CPU 压力测试的软件,在电脑发烧友和专业用户中广泛使用。它通过对 CPU 进行高强度的数学运算,如寻找大质数等,来使 CPU 处于高负载状态。在测试过程中,可以实时监测 CPU 的温度、电压、频率等参数。如果 CPU 在长时间的高负载下能够保持稳定运行,且温度在合理范围内,说明 CPU 的稳定性较好;反之,如果出现死机、重启等现象,则可能意味着 CPU 存在散热问题或稳定性不足。
AIDA64:这是一款功能强大的系统检测与测试工具,其中的 “系统稳定性测试” 模块可以对 CPU 进行压力测试。用户可以选择只对 CPU 进行测试,或者同时对 CPU、内存、硬盘等其他硬件进行综合测试。在测试过程中,AIDA64 会实时显示 CPU 的温度、功耗、频率等信息,方便用户监控 CPU 的状态。
日常应用场景模拟测试:
原理:模拟用户在日常使用电脑时的各种场景,如办公软件使用、网页浏览、视频播放等,来测试 CPU 在实际应用中的性能表现。
测试方法及工具:
PCMark:这是一款综合的性能测试工具,其中包含了对 CPU 在日常办公、多媒体创作、游戏等场景下的性能测试。例如,在办公场景测试中,会模拟用户打开 Word、Excel、PowerPoint 等办公软件,进行文档编辑、数据处理、幻灯片制作等操作,然后根据 CPU 在这些操作中的响应速度、处理能力等指标给出相应的分数。通过 PCMark 的测试,可以了解 CPU 在实际日常使用中的性能表现,以及是否能够满足用户的需求。
BrowserBench:对于网页浏览场景的测试,可以使用 BrowserBench 等工具。它会模拟用户打开多个网页、进行网页滚动、页面切换、在线视频播放等操作,测试 CPU 在处理网页浏览任务时的性能。CPU 的性能会直接影响网页的加载速度、视频的流畅度等方面,通过这种测试可以评估 CPU 在网页浏览场景下的表现。
BrowserBench的测试界面
游戏性能测试:
原理:游戏对 CPU 的性能要求较高,尤其是在大型 3D 游戏中,CPU 需要处理大量的游戏逻辑、物理计算等任务。因此,通过运行游戏来测试 CPU 的性能,可以了解 CPU 在游戏场景下的实际表现。
测试方法及工具:
赛博朋克2077游戏画面
实际游戏测试:选择一些对 CPU 性能要求较高的游戏,如《古墓丽影:暗影》《赛博朋克 2077》等,在游戏中设置不同的画质和分辨率,然后观察游戏的帧率变化。帧率越高,说明 CPU 在处理游戏任务时的性能越好。同时,可以使用游戏内置的性能监测工具,或者第三方的性能监测软件,如微星的 AfterBurner 等,来实时监测 CPU 的温度、频率、占用率等参数。
3DMark:虽然 3DMark 主要是用于测试显卡性能的工具,但它也包含了一些对 CPU 性能的测试项目。例如,在 3DMark 的 Time Spy 测试中,会同时对 CPU 和显卡进行测试,其中 CPU 的性能会影响到整个测试的分数。通过 3DMark 的测试,可以了解 CPU 在与显卡协同工作时的性能表现,以及在 3D 游戏场景下的处理能力。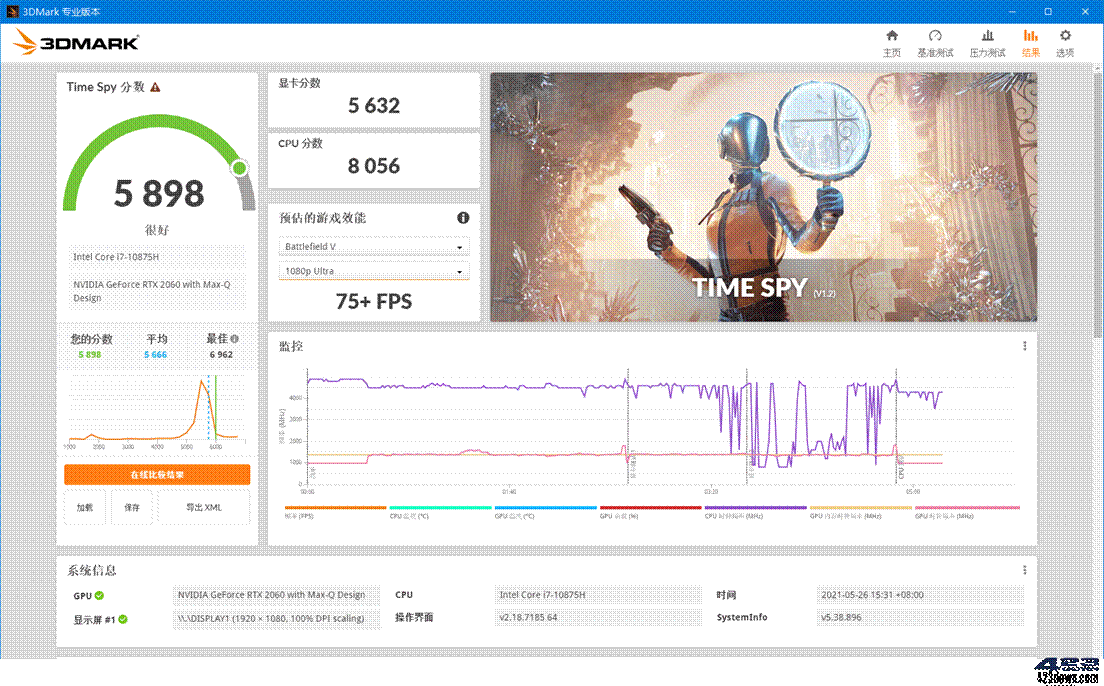
3DMark的测试画面
- CPU知识学习心得
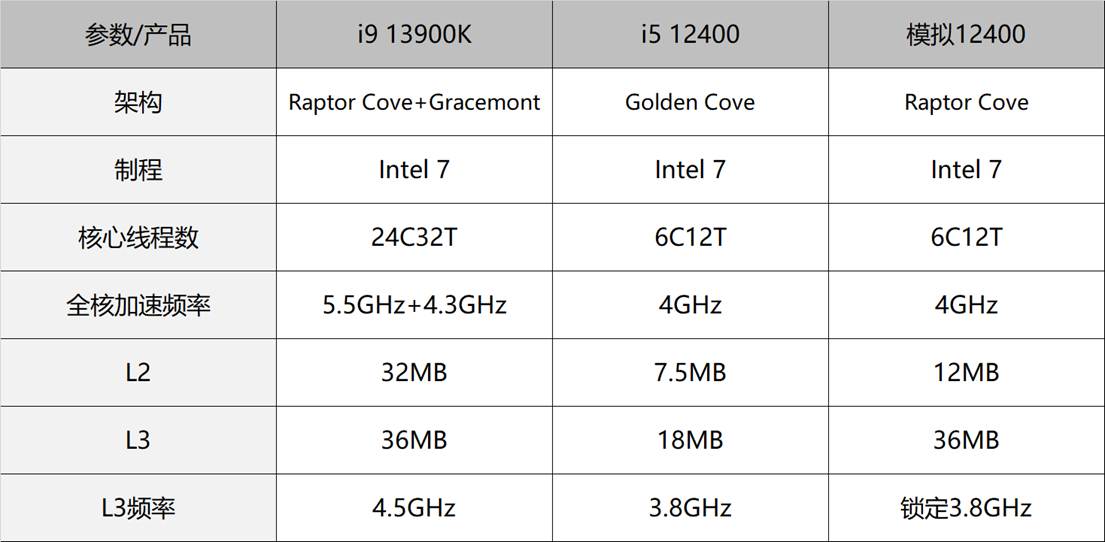
通过对CPU发展历程与技术参数的系统性梳理,从1971年Intel 4004的4位处理器到当代10纳米工艺的酷睿i9,深刻理解了计算机核心部件的演进逻辑与技术内涵。在剖析CPU关键性能指标时,主频(Base Clock)作为基础运行频率,决定了指令执行的基本节奏——例如i9-13900K的3.0GHz基频意味着每秒30亿次时钟周期;而睿频(Turbo Boost)技术则展现了动态超频的智慧,通过监测温度与功耗实时提升单核频率至5.8GHz,使突发任务处理速度提升40%。这些参数背后折射出半导体工艺的跨越:从早期8086的3μm制程、5MHz主频,到如今EUV光刻技术实现的7nm晶体管密度,单个芯片已能集成超260亿个晶体管。
在对比Intel与AMD的架构设计时,发现核心数(Cores)与线程数(Threads)的配置策略深刻影响多任务性能——Ryzen 9 7950X的16核32线程设计,通过Zen4架构的分CCD模块布局,在视频渲染任务中较8核处理器效率提升190%。而缓存体系(Cache)的层级设计更是性能优化的精髓:L1缓存3.5ns的极速访问(较DDR5内存快100倍),L3缓存的共享机制(32MB容量减少70%内存访问延迟),共同构建了数据处理的“高速通道”。这些认知颠覆了以往对“频率即性能”的片面理解,例如Apple M2芯片虽主频仅3.5GHz,却凭借统一内存架构与优化指令集,在能效比上超越x86处理器达2.3倍。
此番学习不仅解构了CPU的技术本质,更揭示了硬件与软件协同进化的规律。当在Linux环境下通过CPU-Z监测睿频动态时,亲眼见证处理器如何根据负载在P核与E核间智能切换;当拆解散热器观察硅脂涂抹对温度的影响时,深刻认识到5°C的温差波动足以导致最大睿频下降0.2GHz。这些实践印证了理论参数的物理意义,也为后续参与国产龙芯3A6000处理器的应用开发奠定了坚实基础——其LA664自主指令集虽主频仅2.5GHz,但通过12级流水线优化,SPECint分值已逼近国际主流产品。未来将持续追踪chiplet封装、3D堆叠存储等前沿技术,致力于在自主可控的硬件生态建设中贡献专业力量。


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









