






VGG网络、LeNet架构、AlexNet架构、VGG块、VGG16详解本文主要讲述VGG网络、LeNet架构、AlexNet架构、VGG块、VGG16等方面的知识。
VGG网络:
结构:VGG16和VGG19分别有16和19个卷积层,以及3个全连接层,通过重复的VGG块构建深度卷积神经网络。性能:更深层次的网络带来了更强的特征提取能力,提高了图像识别的准确性。发展趋势:加深网络:如VGG系列,通过增加卷积层数提高性能。加宽网络:如GoogleNet,通过增加网络宽度提升表达能力。

新功能:从分类到检测,引入新的组件和技术,如FCN、ResNet、Faster R-CNN等,推动图像识别技术的发展。在文档的发展趋势部分中,提到加深网络(如VGG系列)和加宽网络(如GoogleNet)是提升模型性能的方法。请问这两种方法在实际应用中各自的优缺点是什么?在什么情况下应该选择加深网络而不是加宽网络,反之亦然?☞
在文档的发展趋势部分中,提到加深网络(如VGG系列)和加宽网络(如GoogleNet)是提升模型性能的方法。以下是这两种方法在实际应用中的优缺点,以及在什么情况下应该选择加深网络而不是加宽网络,反之亦然:
加深网络(如VGG系列)优点:1. 更强的特征提取能力:随着网络层数的增加,模型能够学习到更加抽象和复杂的特征,从而提高分类或检测的准确性。2. 参数共享:通过卷积操作,模型可以在不同层次上共享参数,减少参数数量,避免过拟合。
缺点:1. 计算复杂度高:增加网络深度会导致计算量和内存消耗的增加,训练时间变长。2. 梯度消失问题:随着网络层数的增加,梯度在反向传播过程中可能会逐渐消失,导致训练困难。
适用场景:1. 需要高精度:当任务对精度要求较高时,可以通过加深网络来提高模型的表达能力。2. 数据量大:在拥有大量训练数据的情况下,加深网络可以更好地利用数据学习到丰富的特征。加宽网络(如GoogleNet)
优点:
并行计算:加宽网络可以通过增加每层的神经元数量或增加并行分支来提升计算效率,适合并行计算架构。2. 表达能力增强:增加网络宽度可以提升模型的表达能力,使得模型能够学习到更多的特征。
缺点:1. 参数量增加:增加网络宽度会导致模型参数数量的增加,容易导致过拟合。2. 计算资源需求高:虽然并行计算可以提高效率,但仍然需要更多的计算资源。
适用场景:1. 计算资源有限:在计算资源有限的情况下,加宽网络可以通过并行计算提高效率。2. 需要快速训练:加宽网络可以在不显著增加训练时间的情况下提升模型性能。选择加深网络还是加宽网络1. 精度优先:如果任务对精度要求较高,且有足够的计算资源和训练数据,可以选择加深网络。2. 效率优先:如果计算资源有限,或者需要快速训练模型,可以选择加宽网络。3. 数据量:数据量较大时,加深网络可以更好地利用数据学习到丰富的特征;数据量较小时,加宽网络可能更容易过拟合,此时加深网络可能更合适。4. 模型复杂度:加深网络会增加模型的深度复杂度,而加宽网络会增加模型的宽度复杂度。根据具体任务和资源情况,选择合适的复杂度提升方式。在实际应用中,可以根据任务需求、计算资源和数据量等因素综合考虑,选择合适的网络结构优化方法。☜
VGG架构:
VGG架构是一种经典的卷积神经网络(CNN)模型,由牛津大学视觉几何组(Visual Geometry Group)提出。
VGG架构以其简单、直观和高度可重复的结构而闻名。
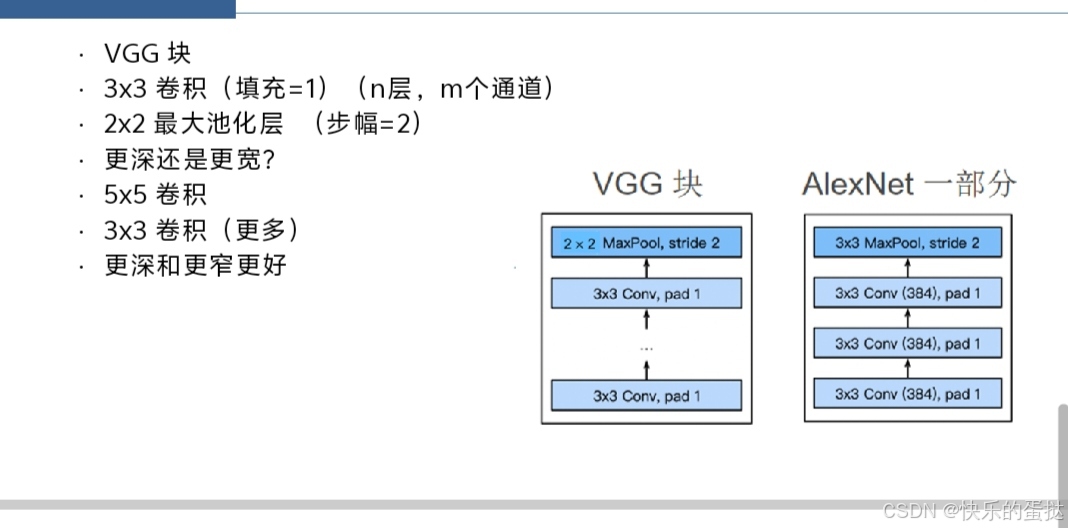
以下是VGG架构的主要特点:主要特点重复的卷积块:VGG架构由多个卷积块组成,每个卷积块包含多个连续的3x3卷积层,随后是一个2x2的最大池化层。例如,VGG16包含16个卷积层,分为13个卷积块,每个卷积块包含1到3个卷积层。小卷积核:VGG架构主要使用3x3的小卷积核。这种小卷积核可以多次堆叠,从而学习到更复杂的特征,同时减少参数数量。例如,两个3x3卷积层堆叠的效果与一个5x5卷积层相似,但参数数量更少。
固定步幅和填充:卷积层的步幅固定为1,填充固定为1(对于3x3卷积核),这有助于保持特征图的尺寸一致。池化层使用2x2的最大池化,步幅为2,用于下采样特征图。全连接层:在卷积层之后,VGG架构包含3个全连接层,用于分类任务。第一个全连接层通常有4096个神经元,接下来的全连接层也有4096个神经元,最后一个全连接层输出类别数。预训练和微调:VGG模型通常在大规模数据集(如ImageNet)上预训练,然后可以在其他数据集上进行微调,以适应特定的任务。VGG变种VGG架构有多个变种,包括VGG11、VGG13、VGG16和VGG19等,主要区别在于卷积层的数量和深度。例如:VGG11:包含11个卷积层。VGG13:包含13个卷积层。VGG16:包含16个卷积层。VGG19:包含19个卷积层。优点简单直观:VGG架构设计简单,易于理解和实现。
高度可重复:由于其模块化的结构,VGG架构可以很容易地扩展和修改。性能优异:在多个图像识别任务中表现出色,尤其是在预训练和微调的场景下。缺点计算量大:由于包含大量的卷积层和全连接层,VGG模型的计算量和参数数量都较大,训练和推理时间较长。内存消耗高:大量的参数和中间特征图会导致较高的内存消耗。应用场景VGG架构适用于需要高精度图像识别的场景,尤其是在有足够计算资源和训练数据的情况下。通过预训练和微调,VGG模型可以在各种图像识别任务中取得良好的效果。

VGG架构有哪些实际应用案例?
1. 图像分类: - ImageNet竞赛:VGG架构最初是为了参加ImageNet大规模视觉识别挑战赛(ILSVRC)而设计的。在2014年的竞赛中,VGG模型取得了优异的成绩,证明了其在图像分类任务中的有效性。 - 通用图像分类:VGG模型可以用于各种通用图像分类任务,如识别动物、植物、车辆等。
2. 目标检测: - R-CNN系列:VGG架构被用作区域卷积神经网络(R-CNN)、Fast R-CNN和Faster R-CNN等目标检测算法的特征提取器。这些算法在目标检测任务中表现出色,广泛应用于自动驾驶、安防监控等领域。
3. 语义分割: - FCN(全卷积网络):VGG架构可以作为FCN的基础网络,用于像素级的图像语义分割任务。例如,在医学图像分析中,FCN可以用于分割肿瘤区域。
4. 视频分析: - 双流网络:VGG架构可以用于双流网络(Two-Stream Networks),其中一个流处理空间信息,另一个流处理时间信息。这种网络结构在视频动作识别任务中取得了很好的效果。
5. 人脸识别: - 人脸验证和识别系统:VGG架构可以用于提取人脸特征,用于人脸验证和识别系统。例如,在安防监控系统中,VGG模型可以用于识别特定人员。
6. 医学图像分析: - 疾病诊断:VGG架构可以用于医学图像的分析和疾病诊断,如肺部CT图像中的结节检测、眼底图像中的病变识别等。7. 自然语言处理: - 图像描述生成:VGG架构可以用于提取图像特征,结合循环神经网络(RNN)等模型,生成图像的描述文本。这种应用在图像搜索和辅助视觉障碍者方面有很高的实用价值。这些应用案例展示了VGG架构在图像处理和计算机视觉领域的广泛应用和强大能力。通过预训练和微调,VGG模型可以在各种特定任务中取得良好的效果。VGG块:VGG块是VGG架构中的基本构建单元,由多个连续的3x3卷积层和一个2x2的最大池化层组成。
VGG块的设计目的是通过重复使用这种结构来构建深度卷积神经网络,从而有效地提取图像特征。
以下是VGG块的详细说明:VGG块的结构1. 卷积层: - 每个VGG块包含多个连续的3x3卷积层。这些卷积层使用小卷积核,可以多次堆叠,从而学习到更复杂的特征。 - 卷积层的步幅固定为1,填充固定为1(对于3x3卷积核),这有助于保持特征图的尺寸一致。2. 最大池化层: - 每个VGG块的末尾是一个2x2的最大池化层,步幅为2,用于下采样特征图。 - 池化层可以显著减少特征图的空间大小,降低参数数量和计算量,同时保留最重要的信息。VGG块的变种VGG架构有多个变种,包括VGG11、VGG13、VGG16和VGG19等,主要区别在于卷积层的数量和深度。每个变种中的VGG块数量和结构略有不同:
- VGG11:包含11个卷积层,分为5个VGG块。
- VGG13:包含13个卷积层,分为6个VGG块。
- VGG16:包含16个卷积层,分为13个VGG块。
- VGG19:包含19个卷积层,分为16个VGG块。
优点- 简单直观:VGG块设计简单,易于理解和实现。
- 高度可重复:由于其模块化的结构,VGG块可以很容易地扩展和修改。- 性能优异:在多个图像识别任务中表现出色,尤其是在预训练和微调的场景下。
缺点- 计算量大:由于包含大量的卷积层和全连接层,VGG模型的计算量和参数数量都较大,训练和推理时间较长。
- 内存消耗高:大量的参数和中间特征图会导致较高的内存消耗。应用场景VGG块适用于需要高精度图像识别的场景,尤其是在有足够计算资源和训练数据的情况下。通过预训练和微调,VGG块可以在各种图像识别任务中取得良好的效果。
在VGG16模型中,VGG块的具体配置如下:
VGG16中的VGG块配置
1. 卷积块1: - 2个3x3卷积层,每个卷积层有64个滤波器。
- 输出特征图尺寸:224x224x64 - 随后是一个2x2的最大池化层,步幅为2。
- 输出特征图尺寸:112x112x642.
卷积块2: - 2个3x3卷积层,每个卷积层有128个滤波器。 - 输出特征图尺寸:112x112x128 - 随后是一个2x2的最大池化层,步幅为2。
- 输出特征图尺寸:56x56x1283.
卷积块3:
- 3个3x3卷积层,每个卷积层有256个滤波器。 - 输出特征图尺寸:56x56x256 - 随后是一个2x2的最大池化层,步幅为2。
- 输出特征图尺寸:28x28x2564. 卷积块4: - 3个3x3卷积层,每个卷积层有512个滤波器。 - 输出特征图尺寸:28x28x512 - 随后是一个2x2的最大池化层,步幅为2。
- 输出特征图尺寸:14x14x5125. 卷积块5: - 3个3x3卷积层,每个卷积层有512个滤波器。 - 输出特征图尺寸:14x14x512
- 随后是一个2x2的最大池化层,步幅为2。
- 输出特征图尺寸:7x7x512全连接层在上述卷积块之后,VGG16模型包含3个全连接层:- 第一个全连接层有4096个神经元。
- 第二个全连接层也有4096个神经元。- 最后一个全连接层输出分类结果。总结VGG16模型通过重复使用这种VGG块结构,构建了一个深度卷积神经网络。每个VGG块包含多个连续的3x3卷积层和一个2x2的最大池化层。这种结构不仅简单直观,而且性能优异,在多个图像识别任务中表现出色。 AlexNet和VGG架构的主要区别是什么?AlexNet和VGG是两种经典的卷积神经网络(CNN)架构,它们在深度学习领域都有广泛的应用。
以下是AlexNet和VGG架构的主要区别:
1. 卷积核大小和层数- AlexNet: - 使用较大的卷积核,如11x11和5x5。 - 总共有8层(5个卷积层和3个全连接层)。- VGG: - 主要使用较小的卷积核,如3x3。 - VGG16和VGG19分别有16和19层,其中包含多个卷积层和全连接层。
2. 网络深度- AlexNet: - 相对较浅,只有5个卷积层。- VGG: - 较深,例如VGG16有16层,VGG19有19层。
3. 参数数量- AlexNet: - 参数数量相对较少,大约有6000万参数。- VGG: - 参数数量较多,例如VGG16大约有1.38亿参数。
4. 计算复杂度- AlexNet: - 由于使用了较大的卷积核,计算复杂度较高。- VGG: - 尽管层数较多,但由于使用较小的卷积核,计算复杂度相对较低。
5. 训练和推理时间- AlexNet: - 训练和推理时间相对较短。- VGG: - 由于网络较深,训练和推理时间较长。
6. 性能- AlexNet: - 在2012年的ImageNet竞赛中取得了显著的成绩,证明了其在图像分类任务中的有效性。- VGG: - 在后续的ImageNet竞赛中取得了更好的成绩,证明了更深层次的网络能够带来更强的特征提取能力。
7. 创新点- AlexNet: - 首次大规模使用ReLU激活函数,显著加快了训练速度。 - 引入了Dropout正则化,防止过拟合。 - 使用数据增强和多GPU训练,提高了模型的泛化能力和训练效率。- VGG: - 通过使用较小的卷积核和增加网络深度,提高了模型的表达能力。8. 应用场景- AlexNet: - 广泛应用于图像分类、目标检测、语义分割和视频分析等任务。- VGG: - 由于其较强的特征提取能力,也被广泛应用于图像分类、目标检测和语义分割等任务。

















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









