






目录
前言
视觉语言模型(VLM)功能强大,因为它们结合了百科全书式的网络知识和解决复杂问题的推理能力,但要在机器人领域发挥这种能力,就需要我们添加连续的动作输出。打个比方,如果我们把 VLM 中的视觉编码器看作视觉皮层,而 LLM 则看作前额叶皮层,那么视觉-语言-动作(VLA)模型也需要一个类似于运动皮层的东西。这个虚拟的运动皮层需要掌握基本 VLM 所不具备的能力,如执行精确的动作,同时还需要与 VLM 的核心推理和视觉能力保持复杂的高带宽接口。在大脑的进化过程中,运动皮层是第一位的,但在现代人工智能中,情况却是相反的:我们从语言开始,然后添加视觉,最后连接运动控制。这意味着,我们需要弄清楚如何将新添加的虚拟运动皮层 “连接 ”到 VLA 中,而不破坏其预先训练的推理能力和网络规模知识。我们该如何增强 VLM,从而获得具有连续动作输出的 VLA,并最大限度地继承网络尺度预训练所带来的所有能力?
RT-2 和 OpenVLA 等第一代 VLA 采用了一种简单的方法:它们训练 VLA 将动作输出为标记化的数字,将每个机械臂关节角度离散化为固定大小的分区,并为每个分区分配一个标记,就像在问题解答中答案由数字组成一样。虽然这种方法适用于拾取物体等基本操作,但并不适合高频、精确或流畅的动作,正如我们在 π0 和 π0-FAST 实验中观察到的那样。这种表征方式不适合训练模型,对于精确任务来说过于粗糙,而且运行速度非常慢。回到运动皮层的比喻,这有点像通过口头说出哪些肌肉应该收缩来控制手臂。对于更复杂的技能,比如叠衣服或铺床,我们的 VLA 就需要一个与运动皮层类似的适当模型。
从π0开始,第二代VLA通过在VLA训练过程中增加新的神经模块来产生连续输出,通常使用连续生成建模技术,如扩散或流匹配,来解决这一问题。这些新模块以动作专家或动作头的形式出现,它们可以关注 VLM 骨干中的表征,但也可以将自己专门用于连续运动控制。这些第二代 VLA 可以执行复杂得多的任务,但在 VLA 微调期间向模型添加新的运动控制权重会导致复杂的学习动态,从而损坏 VLM 的内部表征。从本质上讲,以如此粗略的方式将 “运动皮层 ”嫁接到 VLM 上可能会造成一种 “遗忘”,从而大大降低训练速度,损害模型最终解释语言的能力。
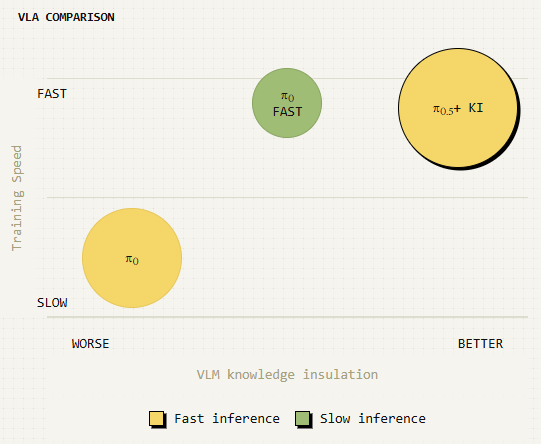
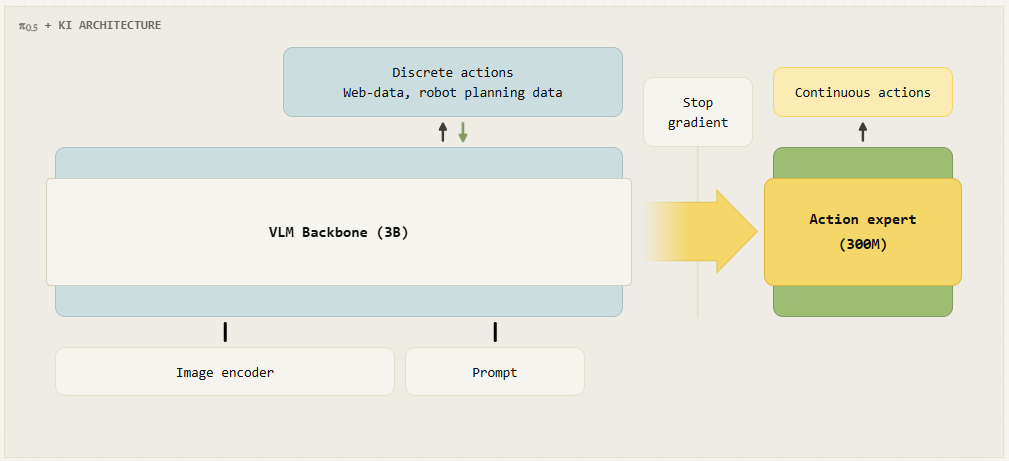
在一项广泛的新研究中,我们分析了这一现象,并开发出一种解决方案,使我们能够在不损失预先训练的网络尺度知识的情况下,将动作专家嫁接到 VLM 上,从而实现快速训练、良好的语义泛化和精确的运动控制。我们将这种方法称为 “知识绝缘 VLA”,它将我们在最近的 π0.5 模型中使用的方法正式化,并通过一种更精细的单阶段训练配方对其进行了扩展,从而将 VLM 骨干与动作专家绝缘。我们将由此产生的模型称为 π0.5 + 知识绝缘 (KI)。知识绝缘背后的关键理念是利用 FAST 标记的离散化动作对 VLM 骨干进行微调,以快速学习高质量的表征,同时调整动作专家以产生连续动作,而不会将其梯度传播回 VLM 骨干。训练完成后,动作专家可以通过流匹配产生流畅的连续动作,离散化动作则被丢弃。
一、连续动作 VLA 面临的挑战
目前的第二代 VLA 架构使用附加模块来处理连续输出,通常是扩散或流动匹配,但有时也处理其他连续分布类别。这通常是通过增加一个回归头、一个从更大的 LLM/VLM 获取输出的独立模型来实现的,或者是通过增加一个可通过扩散或流量匹配解码连续动作的动作专家,而不是通过自回归生成来实现的,正如在 π0 中引入并在许多最新的 VLA 模型中扩展的那样。所有这些设计都有一个共同特点:它们在 VLM 骨干上嫁接了一个虚拟的 “运动皮层”,并用连续动作生成损失对其进行训练。
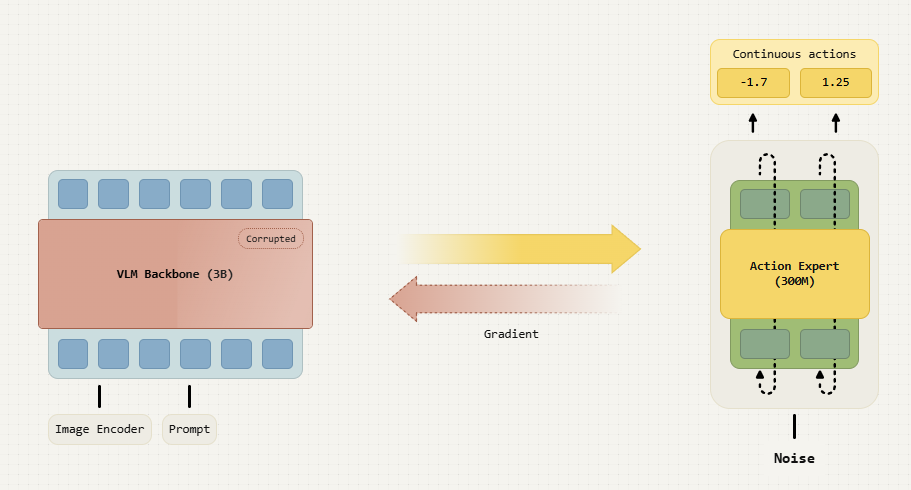
在这种动作专家设计中,当将 VLM 适应于 VLA 时,VLM 骨干表征就会暴露在来自动作专家的梯度中。我们的实验表明,来自动作专家的梯度会导致不利的学习动态,这不仅会导致学习速度大大降低,还会使 VLM 主干网失去在网络规模预训练中获得的部分知识。
这些不利学习动态的后果之一,就是降低了模型遵循语言指令的能力。在下面这个例子中,机器人接到的指令是将勺子放进餐具盒。然而,如果模型在 VLM 骨干上天真地添加了一个动作专家,机器人就会抓起垃圾。

关于出现这种情况的一个假设如下。预先训练好的 VLM 本质上非常关注语言输入。现在,来自动作专家的梯度严重干扰了模型处理语言的能力,导致模型首先捕捉到其他相关性。
根据我们的经验,π0-FAST 等自回归 VLA 不存在这个问题,但正如我们在下面视频中展示的那样,由于需要进行昂贵的自回归推理,因此完成任务的速度要慢得多。在下面的示例中,运行自回归 VLA 的机器人刚刚开始执行任务,右侧运行我们方法的机器人就已经完成了指令。

二、知识绝缘
为了克服这些问题,我们开发了一种新技术,在将骨干网的知识与动作专家 “隔离 ”的同时,使其适应电机控制。第一步是停止从动作专家到 VLM 骨干的梯度流,这样就能将 VLM 骨干与新加入的动作专家完全隔离。然而,如下图所示,仅靠这种方法是不够的。由于 VLM 主干网不再接收来自机器人数据的任何梯度,其表示不再适应机器人控制的需要,这使得动作专家更难生成正确的动作。回到我们的比喻,如果视觉皮层和前额叶皮层从未与物理世界互动过,那么它们很可能无法与运动皮层进行有效的交流。
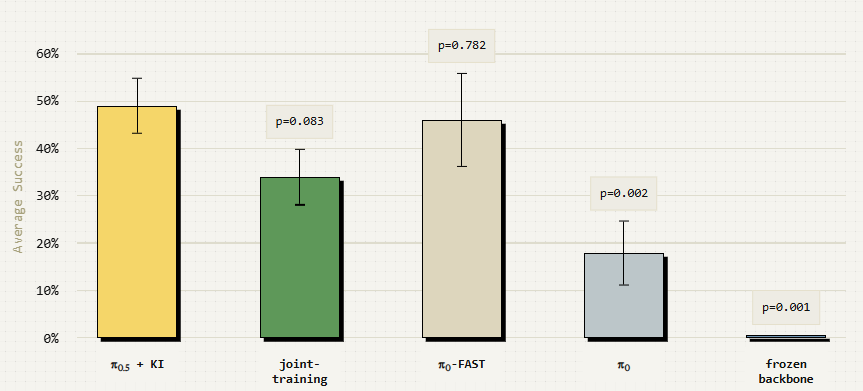
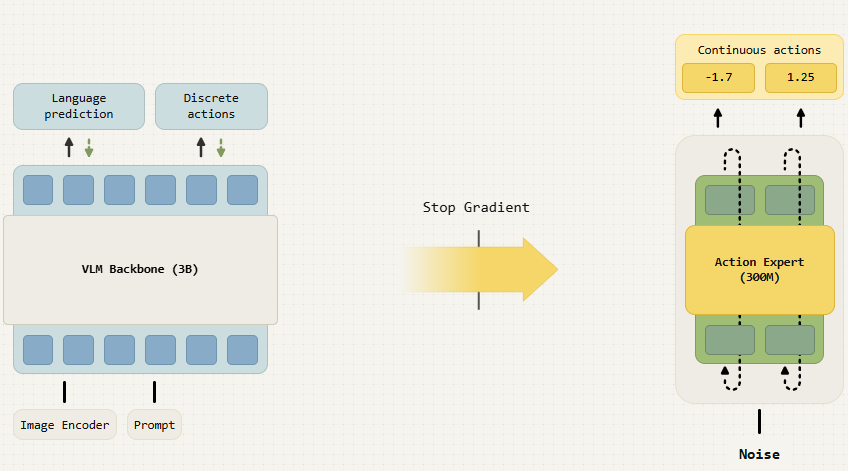
为了解决这个问题,我们使用 π0-FAST 动作标记来训练 VLM 骨干。这样,我们就为 VLM 主干网提供了运动控制的表征,而动作专家则可以使用这些表征,而无需反向传播其训练信号来破坏主网。π0-FAST 动作标记使模型获取运动表征的速度大大加快,而且交叉熵损失对 VLM 主干网预训练知识的干扰也大大减少。
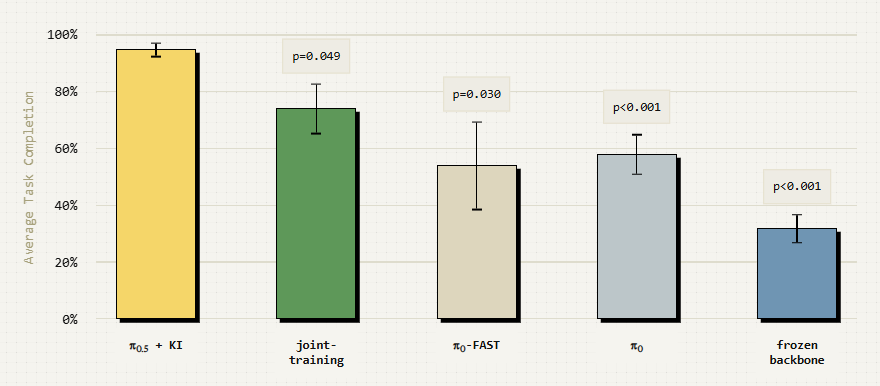
由于我们现在同时对离散标记和连续动作进行模型训练,因此我们还可以添加其他辅助的下一个标记预测任务。我们在全部 π0.5 混合数据上训练模型,其中包括来自网络的一般视觉语言数据和高级机器人指令。这进一步加强了 VLM 骨干中的语义知识,如下图所示,使模型能够更有效地泛化。
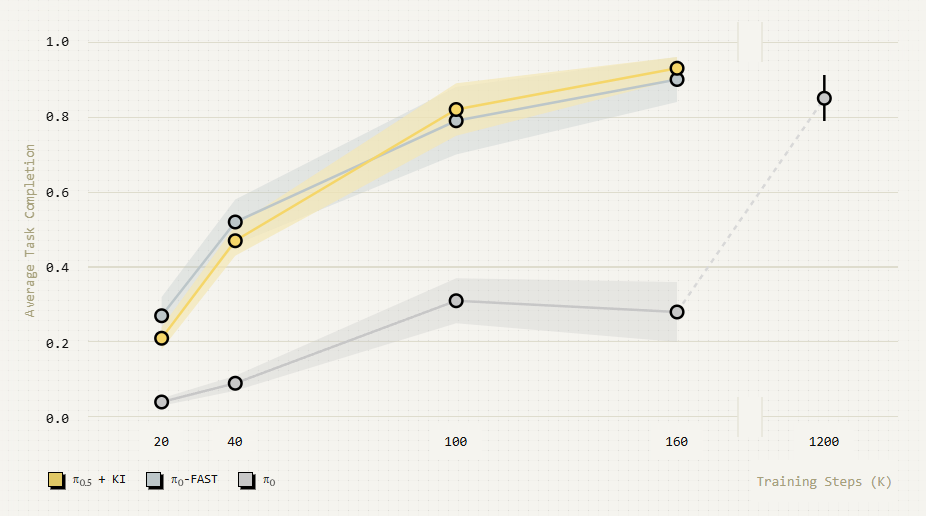
三、快速训练、快速运行、更好地泛化
通过π0-FAST动作标记进行表征学习,通过一般网络数据进行泛化,以及通过动作专家进行连续动作,同时对我们的模型进行训练,使我们实现了所有方面的最佳效果:模型的训练速度明显快于π0(实际上与π0-FAST一样快),同时推理速度与π0一样快,并显示出非常好的语义泛化能力。
下面是我们在完全未知环境中完成模型求解任务的一些示例。

所有实验都是在训练数据以外的环境中进行的。
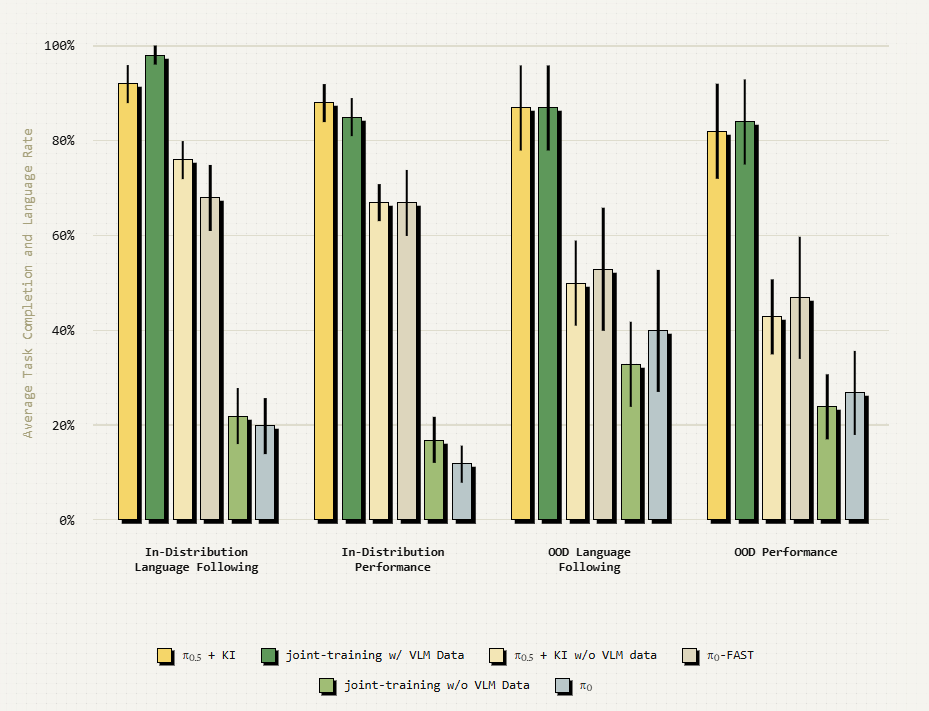
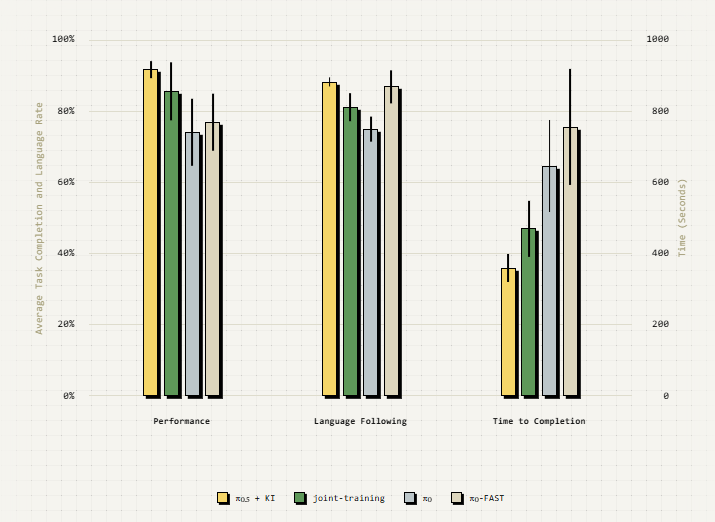
我们的论文包括详细的消融情况以及与其他方法的比较。在下图中,我们展示了这些消融的一瞥。更多详情,请查阅论文!
四、何去何从?
VLAs 已经从将机器人控制作为一个问题解答框架的 VLMs 的简单扩展,发展成为一类集视觉感知、语义理解、问题解决和运动控制于一体的复杂新模型。机器人系统使用的传感器和执行器种类繁多,这意味着 VLA 是最多模态的模型,而训练这些模型的科学实际上就是多模态机器学习的科学。第二代 VLA(如 π0 和 π0.5)带来了无与伦比的新功能,同时也带来了新的挑战。更好地了解这些模型的学习动态,不仅能让我们提高它们的性能,还能让我们朝着下一代 VLAs 的方向迈进。下一代 VLAs 将更深入地整合网络规模的知识和机器人运动控制、更复杂的顺序推理、规划以及以深思熟虑和目标导向的方式执行复杂任务的能力。我们仍处于 VLA 开发的早期阶段,我们正看到基于 VLA 的机器人控制从简单的一次性实验成熟为一门复杂的研究学科,并对实际应用产生深远影响。如果您有兴趣与我们合作,请联系我们。我们特别希望与那些希望在自主性方面开展合作的公司合作,利用部署在真实世界应用中的机器人扩大数据收集规模。
我们也在招聘!如果您有兴趣加入我们,请与我们联系。
对我们的工作、合作或其他问题感兴趣的研究人员,请致信 research@physicalintelligence.company。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









