






【Stable Diffusion】
AI生成新玩法:图像风格迁移
Stable Diffusion带来全新AI图像生成体验,通过风格迁移技术,轻松将任意图片转化为独特艺术风格。从梵高的星空到毕加索的立体主义,甚至将花瓶图案迁移到人物形象设计上,都能轻松实现。本文将带你深入了解Stable Diffusion的图像风格迁移功能,从基础原理到操作步骤,全方位展示如何利用这一技术玩转艺术创作,为你的创意注入无限可能!
1背景导入

你是否曾梦想过让自己融入梵高的星空之中
或是将一幅风景画赋予毕加索的立体主义之魂
还是把人物送进宫崎骏的动画世界?
下面让我们来看看如何通过
*Stable Diffusion*
实现在图像中玩转艺术风格吧!
图像风格迁移
将一幅图片的内容与其他风格图的风格相融合,生成同时具有原特征和新风格的图像。
除了特殊艺术风格的融合,我们还能通过风格迁移实现建筑设计,甚至将花瓶的图案风格迁移到人物形象的设计上:



(图片来源于网络)
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

这份完整版的AI新手入门资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

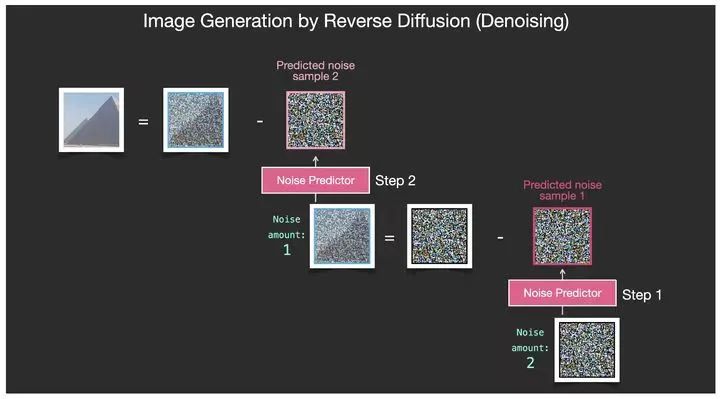
Stable Diffusion
·用于处理图像生成与图像编辑任务
·基于无监督学习和概率建模的思想
·通过迭代地将噪声图像逐渐转化为目标图像
·在图像生成、图像修复、图像风格迁移等任务中具有广泛的应用潜力

Stable Diffusion Tutorials
基本原理是什么
基于大量的图像数据→得到图像中的统计规律和特征→调整模型的参数和输入条件→生成不同风格、内容和分辨率的图像。
该如何操作呢
操作步骤
·噪声注入:在目标图像上生成一个与之大小相同的随机噪声图像,包含一些随机的像素值。
·扩散:通过多个扩散步骤将噪声图像进行反复迭代,逐渐使其接近目标图像→扩散通过概率模型来调整噪声图像的像素值,使其更接近目标图像的像素分布。
·提升:随着扩散次数的增加,噪声图像中的噪声逐渐减少,图像的细节和结构逐渐显现出来,达到提高生成图像的质量的目的。
我更想知道其优势在于…?
·在生成过程中控制生成图像的质量和风格,调整扩散步骤的次数和概率模型的参数来实现不同程度的图像细化和编辑效果。
·采用预训练好的Clip text encoder。
·更多的训练数据及高分辨率训练子集。
2运用展示

当我们在网上看见这么一张照片时
我们该如何去实现风格迁移呢?
首先打开Stable Diffusion,选择文生图选项。
输入提示词,我们这里选择masterpiece,the best quality来控制生成图片的质量,a gril ,a dragon为图片主要元素(当然,也可以选择其他图片来生成自己喜欢的风格)。

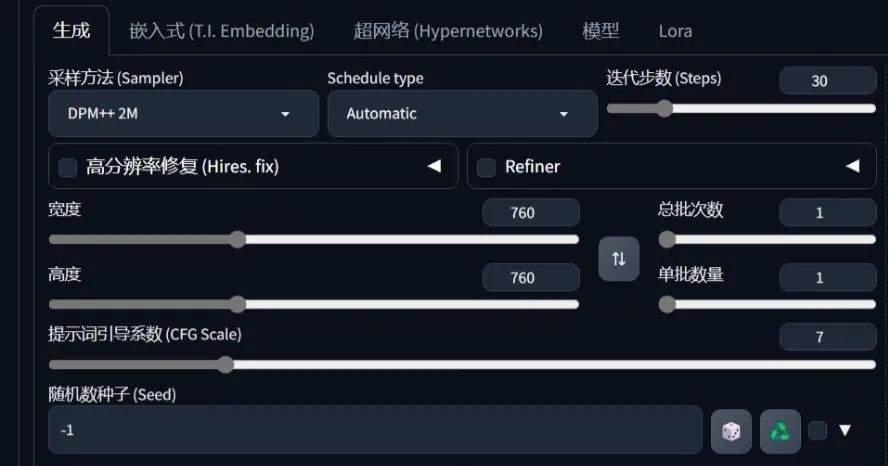
采样方法选择DPM++ 2M,将迭代次数从20改为30,其它参数可以保持不变。
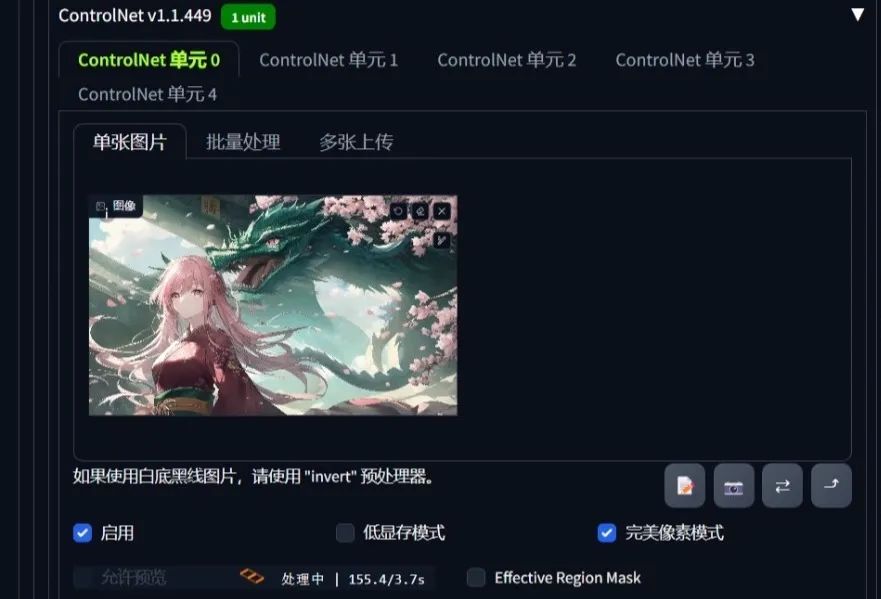
最后就到了我们今天的主角——ControlNet!它将帮助我们完成今天的风格迁移!首先打开ControlNet,点击启用,选择完美像素模式,并在单张图片处上传我们想要模仿的图片。
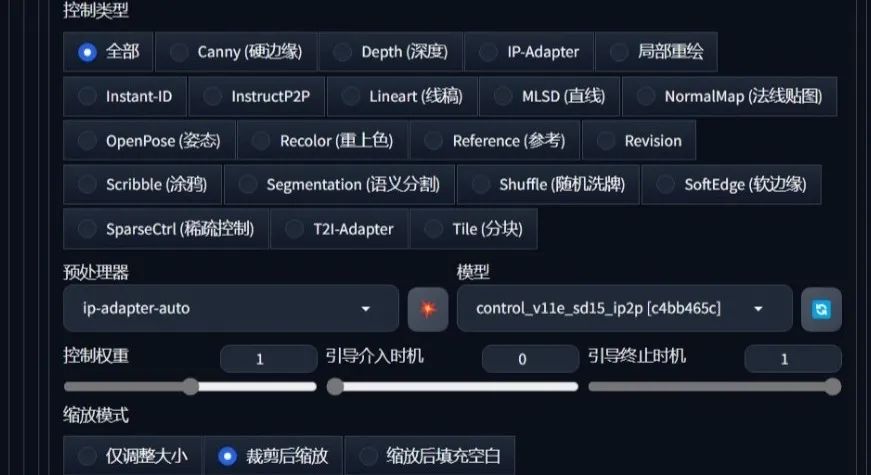
控制类型选择全部,将预处理器改为ip-adapter****-auto,模型选择control_v11e_sd15
_ip2p,其他保持不变。
最后点击生成,就可以静待我们进行风格迁移之后图片啦!
成果展示

可以看出生成的图片还是与原图有些差异,但是基本风格和元素已经非常接近了。
3
结语
以Stable Diffusion为例的图像风格迁移教程就到这里啦,希望能助力你的创意与想法变现,
相信你对艺术创作的大胆想象在数据库之外!
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

这份完整版的AIGC全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
PS. 由于图像生成所占用的内存较大,使用Stable Diffusion前请注意留出足够存储空间哦

















 3950
3950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









