






很多人在刚入门使用StableDiffusion(下文StableDiffusion我们简称SD)时候,会被各种各样的模型搞得一脸懵圈。什么是模型?什么Checkpoint模型,LoRa模型,VAE模型,究竟这些模型是干什么用的?
首先,我们要明白,模型是怎么来的,它是干什么用的? 我这里用一种比较通俗易懂的比喻,但是,不是很准确或者全面的解释,旨在大家都能听懂,给大家分享一下。模型,就是那些搞AI的程序员,给了一大堆数据给计算机,同时标记了这堆数据(后面都不用标记了)。例如,标记的数据是“猫”,然后电脑通过AI算法,能够将一大堆图片的里面像素数据跟“猫”这个字关联起来,形成复杂的数学公式(俗称算法)和数据。当计算机再遇到“猫”这个字的时候,通过数学公式和数据,也就是说这个模型,能够重新识别并把“猫”画出来。
好了,现在我们结合一下SD大名鼎鼎的模型库网站,C站,网址是: https://civitai.com/(假如你上不了国外的网站,只能用国内的网站,这里,推荐一个国内的,https://tusiart.com/)梳理一下SD会用到的主要的模型,总结一下它们的主要作用:
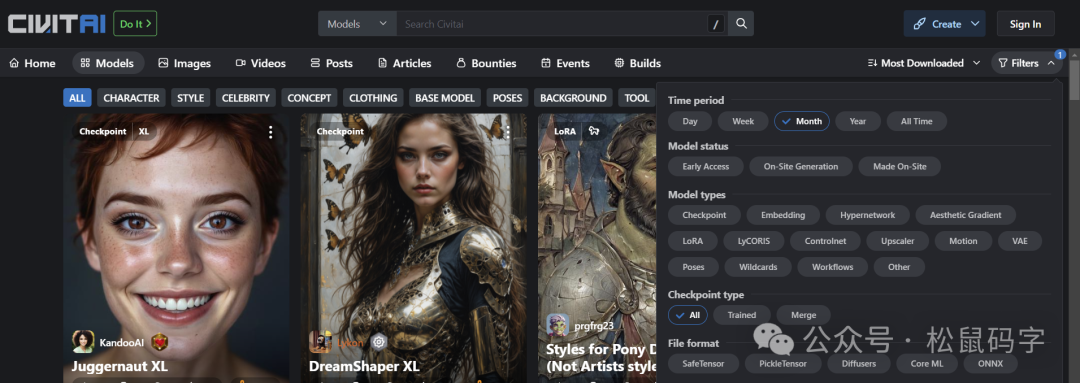
上面这张图,是我在著名的C站上的一张截图,从截图的右侧可以看到, StableDiffusion的模型主要分为几个种类,有CheckPoint,Embeding, Hypernetwork,Aesthetic Gradient,LoRa,LyCORIS,Controlnet,Upscale,Motion,VAE,Poses,Wildcards,Workflows,Other。
1.CheckPoint模型。
我们俗称底模,一般模型体积较大,单个模型的大小一般在GB量级。这是使用StableDiffusion模型进行绘画的基础。它是别人训练,或者融合好的大型模型,里面集合了这个模型的参数、权重等。因此,一旦你选择了某个大模型,那么你SD出图的风格、画风已经相对确定了。
下面在我电脑找个模型, 和大家一起开启探索梳理之旅:


这个是在C站比较火的画美女的模型,生成出来的效果是这样子的:

我这里用到提示词:
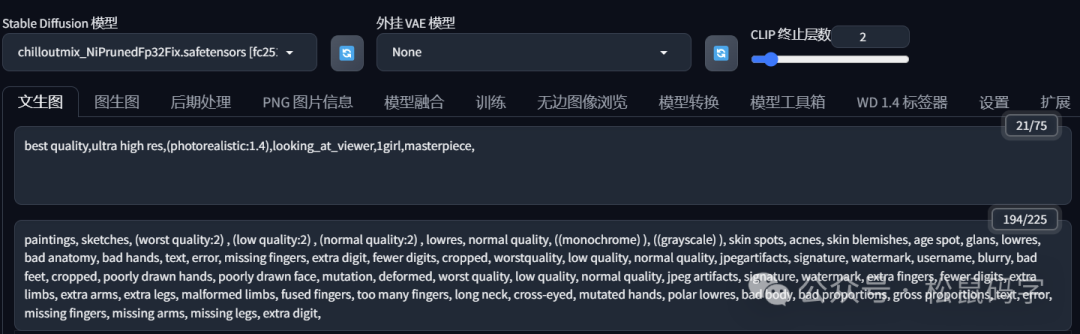
使用SD进行绘画,必须要用到Checkpoint和VAE模型,不过现在有部分Checkpoint模型已经融合了VAE模型,所以就不需要单独下载和配置和VAE模型。
2.VAE模型
什么是VAE模型?我们用一种通俗的解释来讲,VAE模型主要有2种功能:
一种是滤镜(就像是PS、抖音、美图秀秀等)用到的滤镜一样,让出图的画面看上去不会灰蒙蒙的,让整体的色彩饱和度更高。
另一种是微调,部分VAE会对出图的细节进行细微的调整(个人觉得变化并不明显仅会对细节处微调)。
下面,我在C站下载一个Anything模型和VAE模型,体验和总结一下:


在没有使用VAE模型情况下,使用Angthing模型输出的照片,画风是这样子的:

我使用到的提示词是下面:
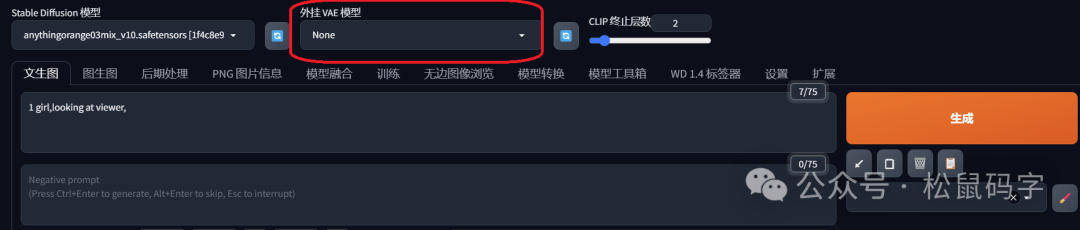
然后我们再外挂VAE模型之后,画风变成了这样:

提示词还是原来的那样,外挂刚才我再C站上下载的这个VAE模型,画风有很大变化:
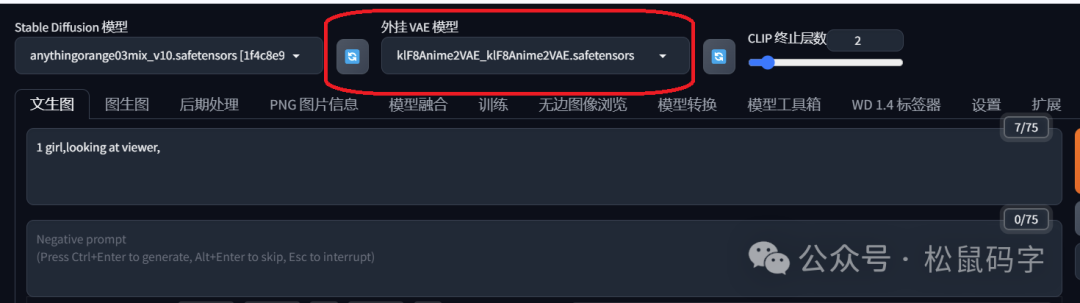
从图片对比,可以很明显地看出来,添加VAE模型后,图片颜色饱和度更高,色彩更艳丽。
3、LoRa模型
我们知道,CheckPoint模型是整个绘画的基础,决定后续绘画内容基调和整体绘画风格,但是训练和修改一个基底模型需要大量的数据,较长的训练时间。那么,有没有一种办法能够,不通过重新训练基底模型,局部修改模型输出中我想要的那部分。例如,我希望上面输出的美女的长相比较接近某个人。模型实现微调面部的输出就可以了。那这时候,LoRa模型就出场了,LoRA模型一般体积不是很大,几十兆到一两百兆,主要用于处理大模型微调的问题。
简单来说,例如就是通过收集和整理某个人的面部数据,然后根据这些脸部数据,专门训练一个LoRA模型,为我们提供了更便捷,更自由的微调局部数据的输出。LoRA模型能够使我们在底模的基础上,进一步指定整体风格、例如指定人脸等等。例如所穿的衣服!
例如下面的例子,使用上面的底模,原始的输出,是这样子的:
下面是原来的提示词:
现在,我增加一个某知名明星刘姐姐的LoRA模型之后,就变成这样的输出:

这是更新后的提示词,可以发现,我们只需要引入LoRA模型,并设置该模型的权重,就可以改变整体的人物的面部输出的画风:

4、ControlNet模型
在说ControlNet模型之前,需要理解它的需求背景,在没有ControlNet模型前,输出结果的不稳定性,如下面提示词中,我们要求画4个女孩,画风是这样的,可以看到每次画画输出,每个女孩的姿势都是不一样的,没有办法稳定控制,那就没有办法商用,不然它只能是个玩具了。

提示词是这样的

ControlNet模型的主要作用,就是一种通过添加额外的模型,来控制大模型的某些方面的结果,ControlNet提供了一种增强稳定输出方法,使得StableDiffusion的输出能够变得更可控和预测,让StableDiffusion落地应用起到了重要的作用。其中,比如可以做出指定动作的姿势,下面四个女生的背影图曾经火爆一时,就是因为ControlNet模型的出现,解决了稳定控制这个问题。
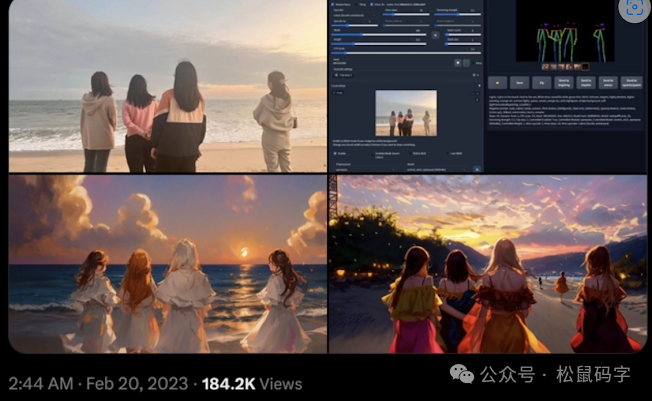
上面只是ControlNet的简单应用之一,还有更多生成线稿图、线稿图上色(下图)、卡通变真人的各种神奇功能,这里面涉及很多的内容,都可以写一篇长的文章。在这里暂时就不多讲了,留到下篇文章,分享和讨论更多。

整体来讲ControlNet模型给出来的模型有8种,包括草图、边缘图像、语义分割图像、人体关键点特征、霍夫变换检测直线、深度图、人体骨骼等。其中每一种都有很多种应用方式,使用得好就能发挥神奇的功效。
5、HypernetWork模型
中文翻译为超文本网络模型,HypernetWork模型可以通过学习已知的图像集合,用于影响影响大模型的绘画的风格,生成新一种新风格的图像。这种模型可以被看作是一个风格生成器,它可以接收一些风格模型为输入,并输出一张新风格的图像。。
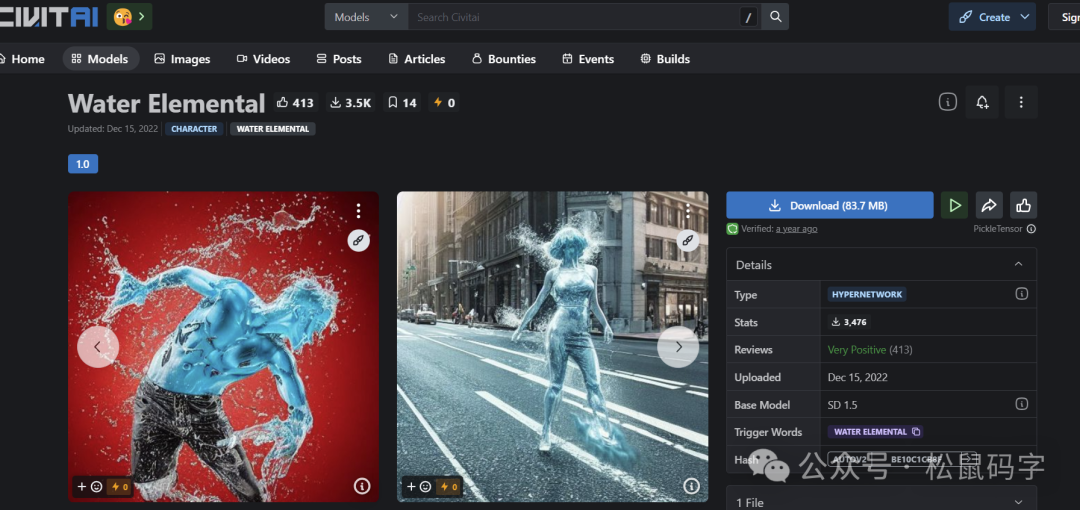
下面,C站下载一个叫Water element的模型给大家演示一下:
没有添加HypernetWork模型,输出画风是这样子的:

它的提示词是这样:
然后,我们在这个基础上,添加了HypernetWork模型后,输出的画风是这样子的:

可以看出HypernetWork,满屏水润的感觉,更新后的提示词是这样子的:
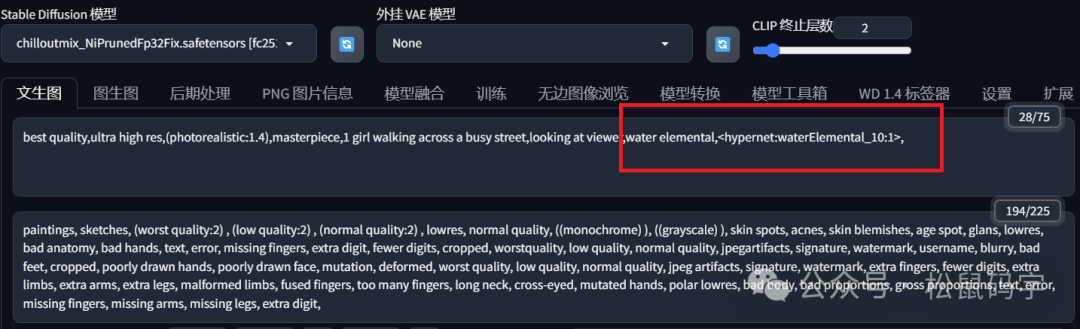
增加了一个water elemental的提示词,整个画面的风格,都变得非常的水润。
6、Embedding模型
也叫文本倒置(Textual Inversion)模型,大家也称呼为私炉。通俗一点的解释是,我们训练出的大模型,通常都很粗范,也就是说当遇到想要生成特殊风格的图像时,往往很难通过提示词来让大模型生成。因为大模型在当初训练时难以做到面面俱到,没有含有这个场景和要素,对于特殊的新概念的风格并没有单独训练过,所以当你用这个大模型想生成某种只有你或少数人才知道的特殊的新风格时,对应的特殊的新提示词在这个大模型上就无法起到作用。

如何解决这个问题?此时,你便需要在这个大模型基础上进行 Textual Inversion 训练。你可以按照自己的需要起名字以描述这种特殊风格或物体的词汇,比如上图中的“S*”,我们用这个新词汇来代指一种新的风格。
上图中第一行里展示了用四张无头打坐的小雕像图形训练出一个“S*“。“S*” 这个新词就代表了 Textual Inversion 训练的结果,也代表了生成出的 Embedding模型的名称。
下面,我在C站下载一个古埃及风格的Embedding模型给你大家演示一下:

在没有添加这个Embedding模型的时候,正常的画风是这样的:

添加了这个embedding模型之后,添加了这个模型的Style-Hamunaptra提示词之后,画风换成是这样的:

下面是这个这次绘画的提示词:
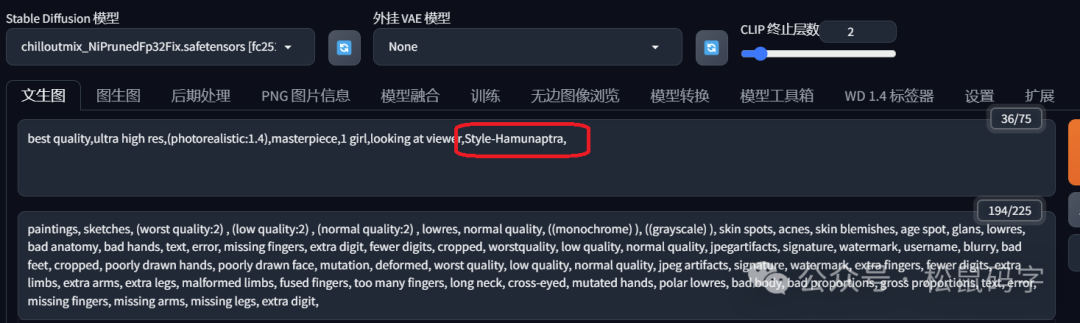
可以看到,整个画风有了很大的变化,只是添加了一个embedding模型和该模型的提示词。
7、Upscale模型
即我们常说的放大模型,这个模型主要用途是放大图片,增补细节,让生成更高质量的图片。要先理解这个模型的需求背景,显卡的显存资源是十分有限的,高端显卡是不便宜的,在绘画的时候,设置较大的图片尺寸,较高的精度,会让很多小显存的显卡吃不消,直接报错显存不足。如何解决这个问题?就是通过的这个放大模型进行解决,先画一张小的图片,当你获得一张或者是多张满意的图片之后,再一张或者多张,使用放大模型,进行图片批量放大。

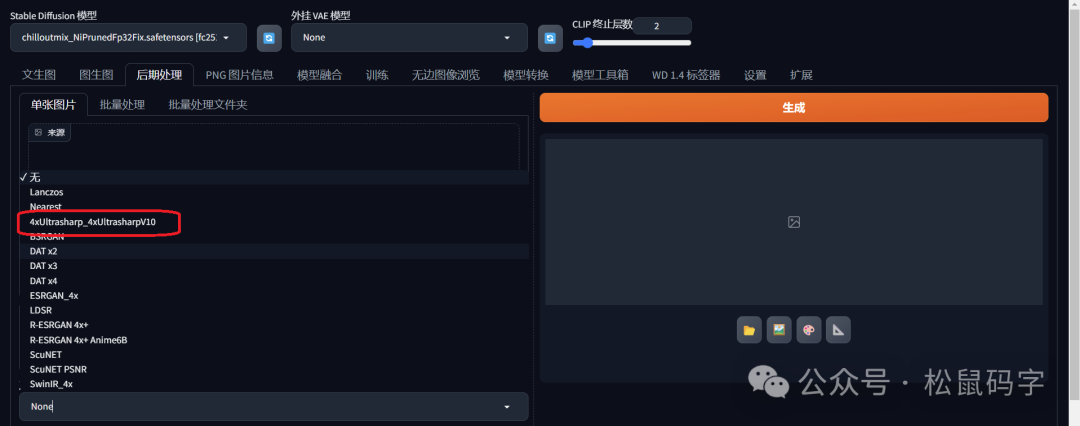
下面我在C站,下载4x-Ultrasharp模型给大家演示一下
我们下载安装之后,就在后期处理中,新增了这个放大算法:
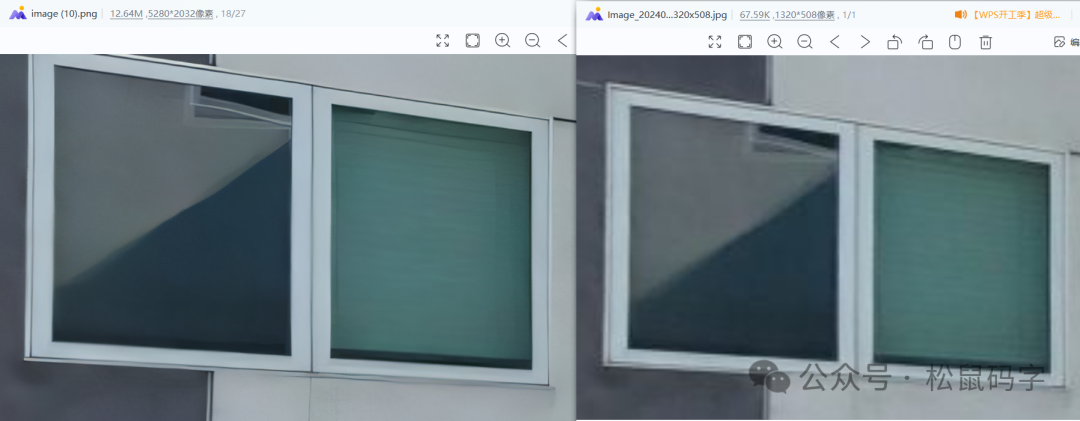
下面我们对比一下高清放大后的效果:
8、LyCORIS模型
我们可以理解它为LoRA模型算法的加强版本,LyCORIS比LoRA信息承载量更高,控制的信息更多,它比LoRA更强大一些,它修改了模型的更多部分。但是,不是说使用LyCORIS了的模型,就一定比使用LoRA的模型的效果好。模型效果好不好,很核心一点的是,在训练模型的时候所采用的训练数据的质量如何,使用,糟糕数据来训练LyCORIS模型,效果一定比不上使用优质数据训练LoRA的模型出来的模型的效果。只能说LyCORIS比LoRA的算法更优秀。
在C站暂时也没有找到使用同一批数据训练出来,LoRA和LyCORIS模型,也不好比较,大家只要知道,LyCORIS算法比LoRA更好,更高级就好。
9、Aesthetic Gradient模型
中文翻译为美学梯度模型,其实和上面Embedding模型要实现的目标差不多, 也就是说通过自己所训练的模型,实现照片的私有特殊的风格化。只是一种和Embedding比较新算法和实现方式。
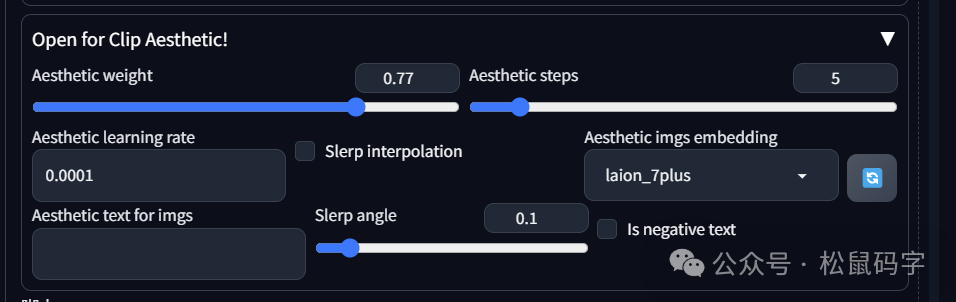
同样,我们使用一张C站上的模型来测试一下效果:

它的提示词是这样的:

应用了官方的模型之后的效果是这样的:

10、Poses模型
Pose,顾名思义就是姿势,在Stable Diffusion软件里面是没有专门的Pose模型选项,只是C站将一些用于控制姿势如ControlNet的模型,单独建立一个分类,方便用户查找这个功能类别,其本质都是一些用户控制输出的姿势ControlNet模型或者是其他类型模型集合。我们打开一个C站的模型看看就知道了。
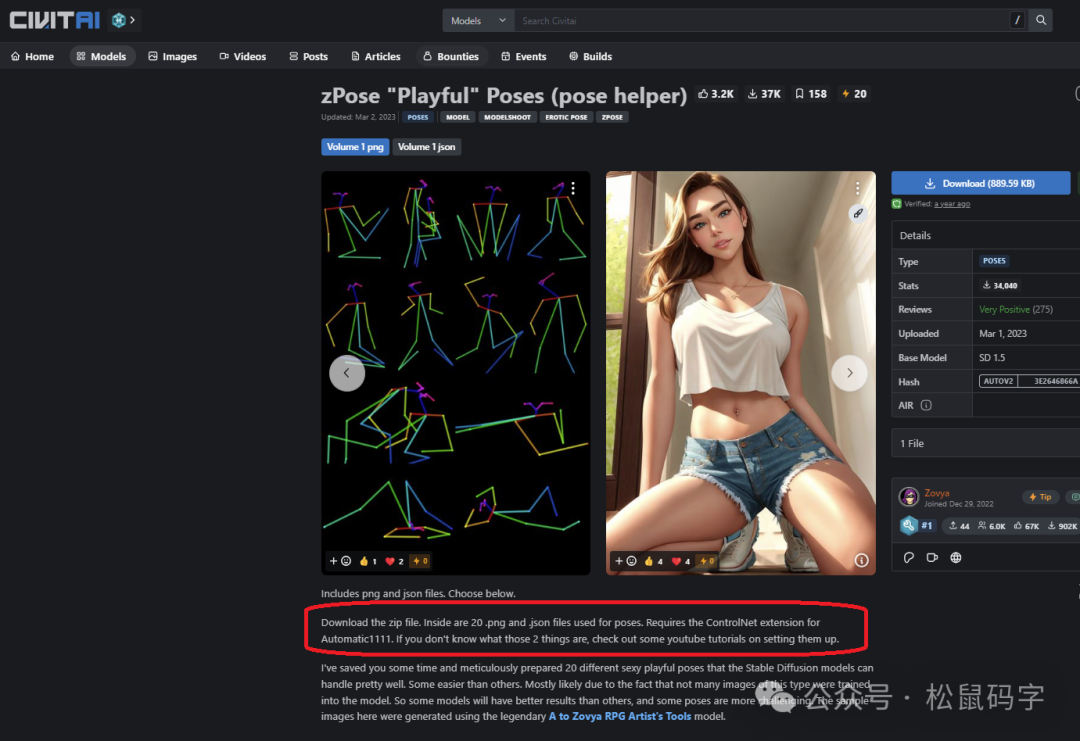
关于如何控制姿势和使用ControlNet模型,放到另外一篇文章来梳理吧,确实知识点满满。
11、Motion模型
顾名思义,运动模型。这个模型主要是,要配合使用的SD的一个插件AnimateDiff,它的作用,是帮你将一张图片生成一个动画。在写这篇文章的时候OpenAI已经发布了Sora,能够秒杀这个SD插件的效果。从我测试来看,像我手上这台机器的40系列N卡的机器,6G显存,都是只是生成1秒的512*512的视频,还是算了吧,直接放弃。
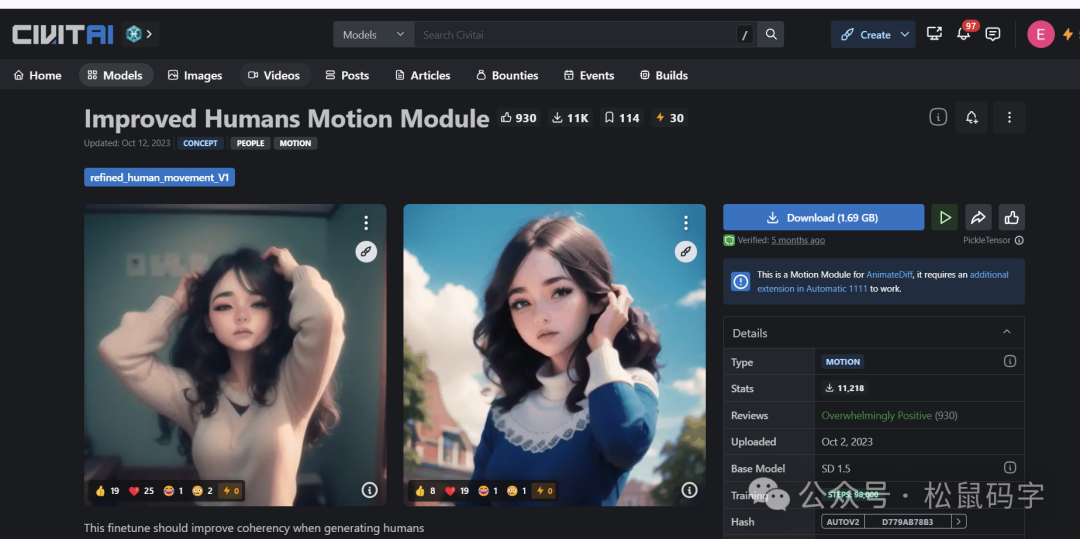
同样地,我们在C站下载模型来体验一下

生成了下面的动画:
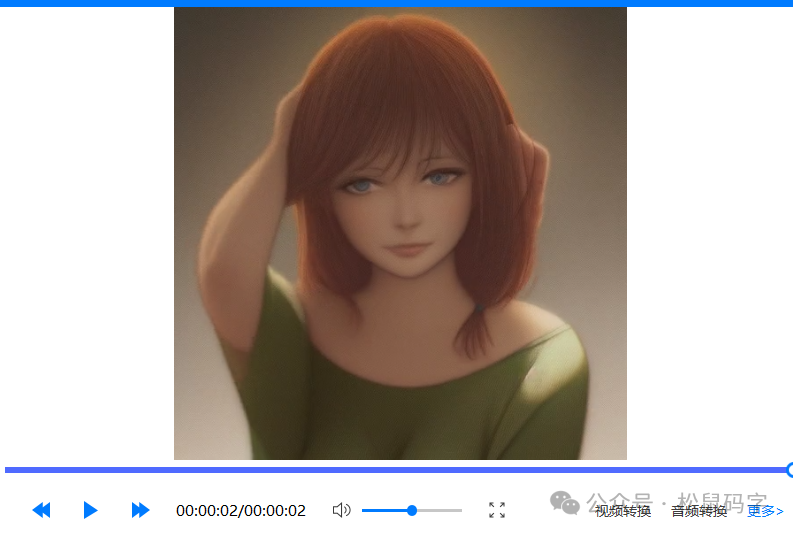
12、Wildcards模型
Wildcards的中文意思就是*通配符。这些模型要配合SD的一个插件stable-diffusion-webui-wildcards来使用。模型的文件就是一堆txt文件,这个插件的作用是允许你将一些提示词,写一个例如color.txt的txt文件,内容范例:
yellow
green
然后,你就可以在提示词中,使用类似 1 girl, wearing a _color_ shirt 这样的通配符批量生成图片。我觉得可以在另外一篇文章介绍一下这个模型,更多的是需要讲这个插件的使用操作流程。
13、Workflow模型,
里面主要是ComfyUI模型,ComfyUI 是一个基于节点工作流形式的stable diffusion AI 绘图工具WebUI, 通过将stable diffusion的流程拆分成节点,实现了更加精准的工作流定制和完善的可复现性。
经过上面的梳理。我们可以发现,SD用到的模型,可以简单归纳为几个方面下面:
Checkpoint模型:SD画图的底模,决定后续画风的内容和基本输出风格。
VAE模型:类似在底模上加一层滤镜,微调输出的风格,但是现在很多Checkpoint模型已经合并了VAE模型。
LoRA和LyCORIS模型:在底模的基础上,训练出某部分特征的模型,然后将这部分应用到底模,实现底模某部分的修改,如修改脸部外貌,修改衣服等元素。
ControlNet模型:主要解决了画图输出不稳定问题,通过使用ControlNet模型,稳定输出人物姿势,图像景深等。
Embedding/HypernetWork/Aesthetic Gradient模型,主要是在底模的基础修改画面的风格,只是实现的算法和方式有所不同。
Motion主要是AnimateDiff插件和对应的模型实现,Sora出来后,基本可以放弃了。
Workflow模型:主要是ComfyUI的工作流模板。
Wildcard模型:就是一堆txt文件,配合该SD插件,实现在提示词中使用通配符代表文件里面的每一行。
以上各大模型插件我已整理放在网盘中,有需要的小伙伴文末扫码获取~
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除















 2407
2407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









