






1. 数据集与评价指标
1.1算法评估相关概念
TP:被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
FP:被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
TN:被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
混淆矩阵:

P(精确率): 𝑇𝑃/(𝑇𝑃 + 𝐹𝑃),标识“挑剔”的程度。
R(召回率): 𝑇𝑃/(𝑇𝑃 + 𝐹𝑁),召回率越高,准确度越低,标识“通过”的程度。
精度(Accuracy): (𝑇𝑃 + 𝑇𝑁)/(𝑇𝑃 + 𝐹𝑃 + 𝑇𝑁 + 𝐹𝑁)
P-R曲线:
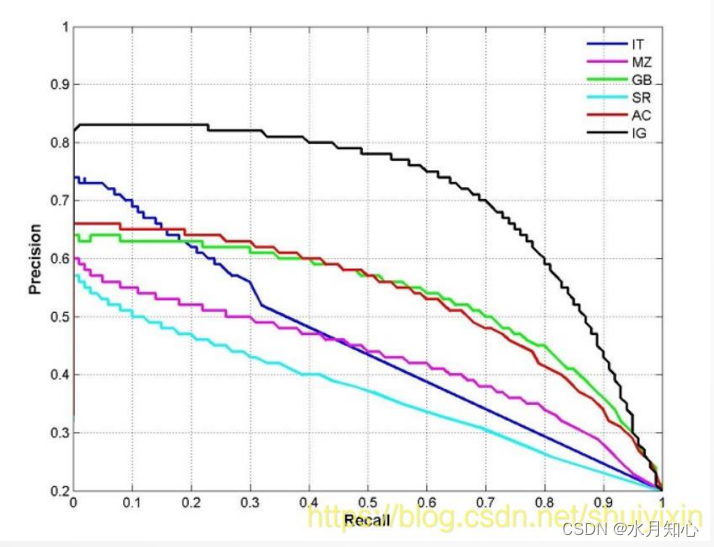
1.2算法评估示例
如图假设一个测试集,其中图片只由大雁和飞机两种图片组成。
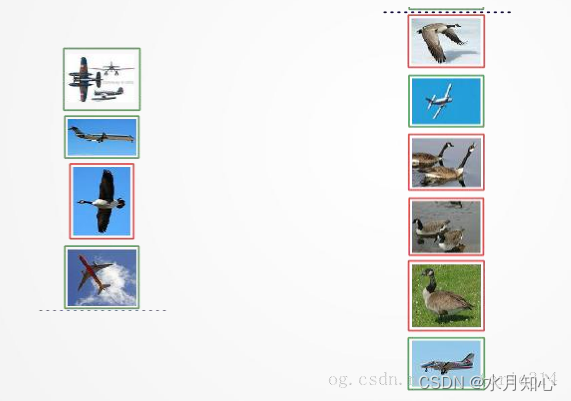
则分类结果为:
True positives : 飞机的图片被正确的识别成了飞机。
False positives: 大雁的图片被错误地识别成了飞机。
False negatives: 飞机的图片没有被识别出来,系统错误地认
为它们是大雁。
True negatives: 大雁的图片没有被识别出来,系统正确地认
为它们是大雁。
1.3置信度与准确率
调整阈值可改变准确率或召回值。可以通过改变阈值(也可以看作上下移动蓝色的虚线)来选择让系统识别能出多少个图片,当然阈值的变化会Precision与Recall值发生变化。比如,把蓝色虚线放到第一张图片下面,也就是说让系统只识别出最上面的那张飞机图片,那么Precision的值就是100%,而Recall的值则是20%。如果把蓝色虚线放到第二张图片下面,也就是说让系统只识别出最上面的前两张图片,那么Precision的值还是100%,而Recall的值则增长到是40%。
1.4 AP计算
mAP:均值平均准确率
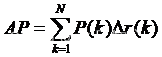
其中𝑁代表测试集中所有图片的个数,𝑃(𝑘)表示在能识别出𝑘个图片的时候Precision的值,而 Δ𝑟(𝑘)则表示识别图片个数从𝑘 − 1变化到𝑘时(通过调整阈值)Recall值的变化情况。
2. 目标检测与YOLO
2.1目标检测问题
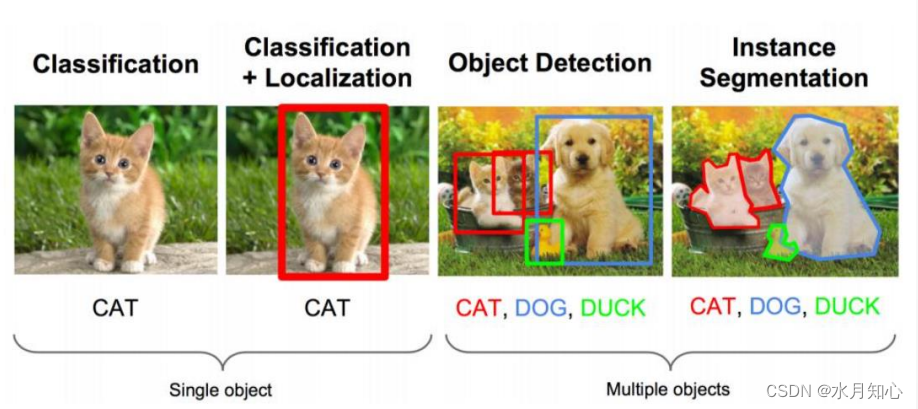
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。
物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图
片的任何地方,并且物体还可以是多个类别。
2.2目标检测基本思想
2.2.1基本的滑动窗口
(1)滑动窗口的原理
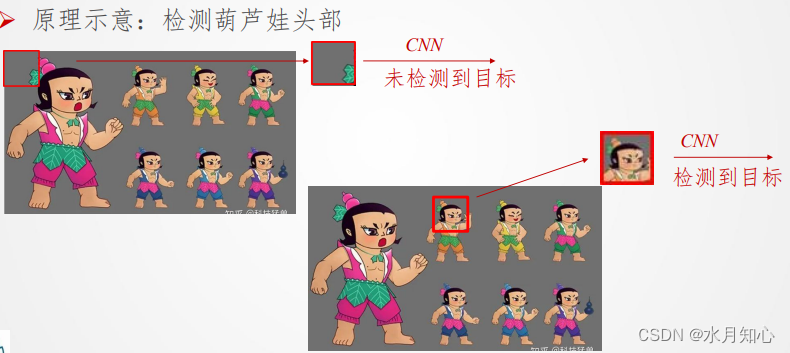
(2)滑动窗口的缺点:
➢滑动次数太多,计算太慢;假设图片为𝑤宽,ℎ高,识别一幅图片需要𝑇时间,则需要𝑤 ∗ ℎ ∗ 𝑇的总时间。
➢目标大小不同,每一个滑动位置需要用很多框。
(3)滑动窗口的改进:
➢ 一般图片中,大多数位置都不存在目标。
➢ 可以确定那些更有可能出现目标的位置,再有针对性的用CNN进行检测——两步法(Region Proposal)。
➢ 两步法依然很费时。
➢ 进一步减少出现目标的位置,而且将目标分类检测和定位问题合在一个网络里——一步法(YOLO)
2.2.2 YOLO网络结构
YOLO网络结构包含24个卷积层和2个全连接层;其中前20个卷积层用来做预训练,后面4个是随机初始化的卷积层,和2个全连接层。
(1)YOLO网络输入
YOLO v1在PASCAL VOC数据集上进行的训练,因此输入图片为448 × 448 × 3。实际中如为其它尺寸,需要resize或切割成要求尺寸。
(2)YOLO网络输出
➢输出是一个7×7×30的张量。对应7×7个cell
➢每个cell对应2个包围框(bounding box, bb),预测不同大小和宽高比,对应检测不同目标。每个bb有5个分量,分别是物体的中心位置(𝑥,𝑦)和它的高(ℎ)和宽(𝑤),以及这次预测的置信度。
(3)YOLO模型输出
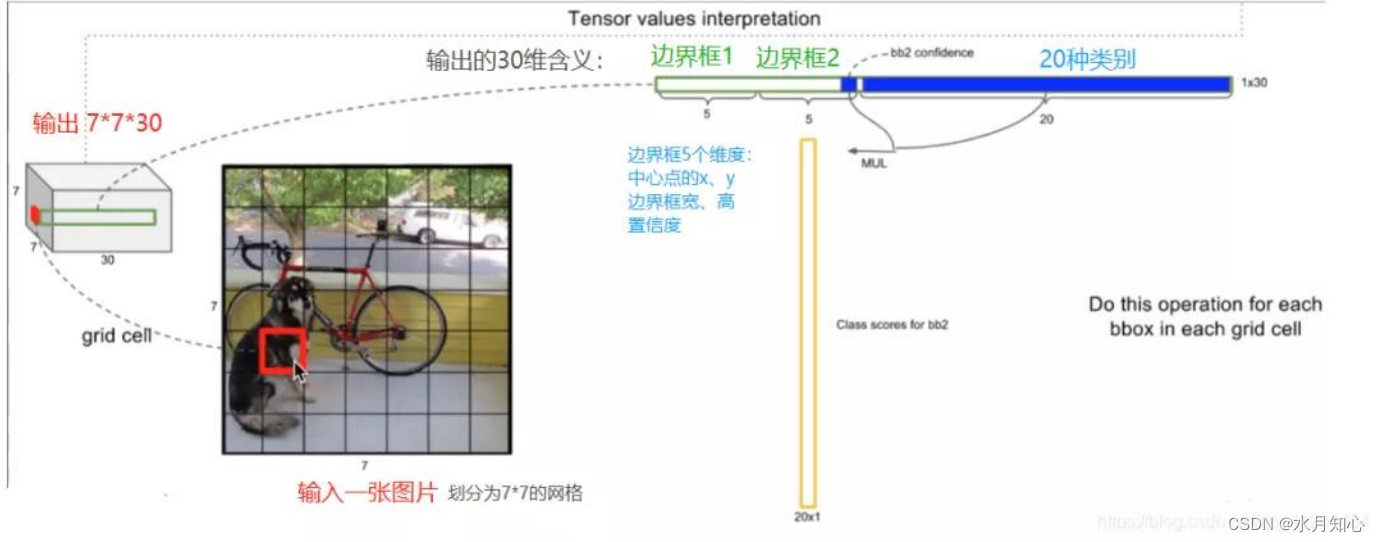
在上面的例子中,图片被分成了49个框,每个框预测2个bb,因此上面的图中有98个bb。
2.2.3包围框与置信度
我们有s*s个框,每个框的bb个数为𝐵,分类器可以识别出𝐶种不同的物体,那么所有整个ground truth的长度为𝑆×𝑆×(𝐵×5+𝐶)。
YOLO v1中,这个数量是30;
YOLO v2和以后版本使用了自聚类的anchor box为bb, v2版本为𝐵 = 5, v3中𝐵=9。
处理细节:
➢归一化:四个关于位置的值,分别是𝑥, 𝑦, ℎ和𝑤,均为整数,实际预测中收敛慢。因此,需要对数据进行归一化,在0-1之间。
➢置信度计算公式:
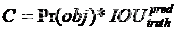
其中,Pr(obj)是一个 grid有物体的概率,IOU是预测的bb和真实的物体位置的交并比。
➢训练值:
三个目标中点对应格子为1,其它为0。
2.2.4损失函数
YOLO损失函数(共5项)

2.2.5训练与NMS
NMS算法要点:
1.首先丢弃概率小于预定IOU阈值(例如0.5)的所有边界框;对于剩余的边界框:选择具有最高概率的边界框并将其作为输出预测;
2.计算“作为输出预测的边界框”,与其他边界框的相关联IOU值;舍去IOU大于阈值的边界框;其实就是舍弃与“作为输出预测的边界框”很相近的框。
4.重复步骤2,直到所有边界框都被视为输出预测或被舍弃。
训练:
➢ YOLO先使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练和预测
➢ 训练中采用了drop out和数据增强来防止过拟合。
➢ YOLO的最后一层采用线性激活函数(因为要回归bb位置),其它
层都是采用Leaky ReLU激活函数:
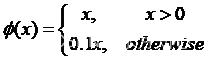
3.语义分割
语义分割(Fully Convolutional Network,FCN)是一种被广泛应用于语义分割任务的基本网络结构。相比传统的卷积神经网络(CNN)只能输出固定大小的特征图,FCN可以接受任意大小的输入,并且输出相应大小的分割结果。
FCN通常由编码器和解码器组成,编码器负责提取图像的高级特征,解码器则负责将这些特征映射回原始图像大小,并对每个像素进行分类。
FCN的基本思想是将传统的全连接层替换为全卷积层,这使得网络能够接受任意尺寸的输入图像,并生成相应尺寸的分割结果。同时,FCN 通过使用上采样或转置卷积(transposed convolution)等技术,将中间层的特征图进行上采样,以恢复到原始输入图像的尺寸,从而实现像素级别的语义分割。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









