







字符串匹配是编程常用的技巧之一,特写此博文,一则深入学习之,二则作为一种积累,三则秉承“NO matter whether it is right,show my code and confirm the result”原则。
前段时间 ,也在csdn上看到了一篇 ,但感觉那是高手级别的手法,看起来着实让人不知所以然。
由于本人水平属于菜鸟级别的,极尽简单的语言,力求理解。纰漏之处,请指正!!
最简单的匹配莫过于蛮力法了,直接挨个遍历,算法复杂度O(m*n),老规矩 先上代码:
#include"iostream"
using namespace std;
int SearchStr(char * mStr,char * patternStr);//declare function
int main()
{
cout<<SearchStr("qwer","we");
}
int SearchStr(char * mStr,char * patternStr)//返回模式串的位置,否则返回-1
{
int i=0;
int j=0;
int mStrLen=0;
int patternStrLen=0;
while(mStr[i]!='\0')//获取目串的长度
{++i;}
mStrLen=i;
i=0;
while(patternStr[i]!='\0')//获取模式串的长度
{++i;}
patternStrLen=i;
for(i=0;i<=mStrLen-patternStrLen;++i)
{
while(j<patternStrLen && (patternStr[j]==mStr[j+i]))
{
j++;
}
if(j==patternStrLen)
return i+1;
}
return -1;
}
测试结果:
原理很简单:在母串中依次与模式串中的字符比较,直至模式串结束,若在结束前发现存在字符不匹配的情况,则停止匹配,母串右移一位,模式串回到第一个字符,然后重 新开始匹配。
如果在文本中查找这样的字符串,当文本很大时,对性能的影响还是很大,这个很大是相对于我们已有的其他匹配算法的性能而言的,任何技术都是在比较中才能找出其优劣。下面谈谈KMP算法的原理,至于其来源,网上一大堆,大家随手一搜就能找到,不再废话。
KMP看似复杂,其实也不难,网上有很多关于它的文章,但是大多晦涩难懂,特别是 清华 严蔚敏的书 一堆数学公式,直叫蛋疼。
KMP算法的本质就是匹配的次数比蛮力法更少了,其跳过了很多匹配,依据就是利用以前的匹配残留的信息。比如:
要在 a b e d d a b e a b 中查找 a b e a b,如果根据蛮力法,则依次比较


但是很明显:在母串中:a(母)!=b(母) b(母)!=e(母);同理:a(模)!=b(模) b(模)!=e(模);而a(母)=a(模),b(母)==b(模) ,e(母)==e(模)(我们已经匹配的3个字符,当然相等),简答的数学代换:a(模)!=b(母),其余俩个类似。既然如此,就没有匹配的必要了。模式串直接移到母串的第3个位置。如下图:
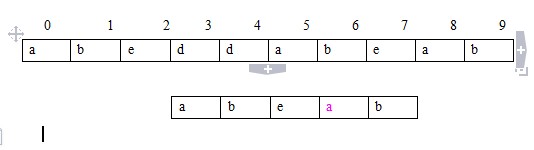
如次一来,是不是比较的次数就少了。KMP的大致原理就是这样。根据此原理,最坏的情况下时间复杂度为O(m+n),而蛮力法为O(m*n),也许当m,n很小是差别不大,但是如果m,n很大 差距就出来了。
根据此算法,KMP的关键就是得知道每次移动的次数,这个本人菜鸟级的,吃得不是很透,但是万幸找到了一个更细点的博客。直接转接:http://billhoo.blog.51cto.com/2337751/411486 http://www.ruanyifeng.com/blog/it/algorithm/















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









