







简介
正则表达式是一种描述字符的一种方式,通过该方式,匹配字符串。
正则表达式是自由的,一个字符的含义往往代表着一类字符,通过多个正则正则符号的组合描述,可以使组成的正则表达式能够描述一类字符串。
在开发中,很多时候使用正则表达式描述一类字符串。
注:正则在编程中是通用的
在python中,使用re模块的match方法进行字符串与正则的匹配。语法如下:
re.match(pattern, string, flags=0)
- pattern:正则表达式
- string:需要进行匹配的字符串
- flags:正则表达式的匹配方式
匹配成功返回匹配的对象,否则返回None。
正则基本使用
最简单的硬匹配
使用re模块前必须引入re,随后使用match方法进行正则匹配:
import re
res = re.match("这是正则区域","这是正则区域")
print(res.group())
以上代码正则区域进行了比较硬核的匹配,直接用 这是正则区域 作为正则匹配,字符串内容也是 这是正则区域。匹配完后把匹配结果赋给res 变量,随后使用print输出(group方法会可以提取数据)。结果如下:

成功输出了匹配的内容。
接下来我把 这是正则区域 的字符串内容改为 这是字符串区域:
res = re.match("这是正则区域","这是字符串区域")
结果如下:

由于匹配的值为None,所以输出错误。我们可以更改为如下方法:
import re
res = re.match("这是正则区域","这是字符串区域")
if res:
print(res.group())
这个时候就不会报错了,没有匹配就不会输出。
硬核的匹配方式学完了,接下来学一点别的方式。
\d
先介绍一个符号 \d,\d 可以匹配0-9的数字,在代码中可以写成如下形式:
import re
res = re.match("\d","2")
if res:
print(res.group())
结果如下:

如果后面的字符串为2则会匹配2,如果把2更换成字母则将不会输出任何值:
res = re.match("\d","a")
结果如下:

我们的代码还可以更加复杂一点,当然只是一点点不是亿点点:
res = re.match("今天星期\d","今天星期3")
这个时候不管是星期几,只要是数字都将会输出显示:

[]
接下来认识一下[],[]可以匹配方括号中列举的字符。例如在[]中列举1234,代码写为 [1234],代码如下:
import re
res = re.match("今天星期[0123456789]","今天星期3")
if res:
print(res.group())
以上代码是否还会匹配成功输出结果呢?当然是可以的,因为方括号中列举了0-9这几个数,并不是一些读者认为的0123456789是一个整体,这一串数字是以字符单个存在说明,并非整体,所以肯定会匹配成功并且显示:

以上代码列举了0-9这几个数字,写太长太过麻烦,可以写成以下形式,方便快捷且清晰:
res = re.match("今天星期[0-9]","今天星期3")
如果想列举字母a-z也没必要写太长,例如:
res = re.match("今天星期[a-z]","今天星期t")
结果如下:

如果你想大写也匹配呢?这个很简单,看如下示例:
res = re.match("今天星期[a-zA-Z]","今天星期T")
因为方括号里面的字符都是单个存在的,a-z描述的是a到z的字母,A-Z描述的是大写A到Z的字母,是一个整体,所以直接写成如上方式肯定是没问题的。
结果如下:

\w 与 \W
\w可以匹配 A-Z、a-z、0-9和下划线_。
\W可以匹配 非字母、非数字、非下划线以及非汉字,也就是和 \w反过来。
首先看\w:
import re
res = re.match("\w","a")
if res:
print(res.group())
由于\w是匹配 A-Z、a-z、0-9和下划线_所以匹配没问题,结果如下:

其它匹配将不再列出,都是一个意思。
尝试\W:
res = re.match("\W","+")
结果ok:

*、+、{}与?
进行到这如果还不增加一点难度想必就无趣了,现在开始使用一些字符对已学的单个字符匹配进行描述,使正则表达式能够匹配多个字符。
现在有一个字符串 房价租金1999 如何进行正则匹配?查看代码:
import re
res = re.match(r"房价租金[0-9]*","房价租金1999")
if res:
print(res.group())
仔细看,正则表达式 房价租金[0-9]*,前面的 房价租金 硬匹配了房价租金这几个字符串,之后我使用了一个中括号,里面的内容为匹配 0-9 其中任意一个数字,在一般情况下 [0-9] 匹配只能匹配一个,我在方括号后面增加了一个 *号。
*号的作用是描述它前面的一个正则表达式 [0-9] 匹配0次或者无限次,这里出现了1次,则匹配成功。结果如下:

当然0次也可以的,我们把代码更改为如下:
res = re.match("房价租金1*","房价租金")
以上代码使用*号去匹配1这个字符,如果不存在,正则表达式依旧会返回匹配对象,因为前面已经匹配成功了。*号0次没有也ok,所以依旧会输出:
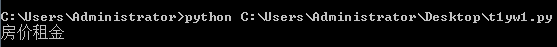
如果把以上代码中的 * 号改为 + 号会出现什么情况?我们试一下:
res = re.match("房价租金1+","房价租金")
这时候将不会输出。+号表示前面的字符出现1次,为0可不行,那么我们匹配一下 房价租金1111 这个字符串看看效果:
res = re.match("房价租金1+","房价租金111111111")
结果如下:

那如果我想匹配固定次数如何?
这个时候就可以使用{}进行限定次数的匹配:
res = re.match("房价租金1{0}","房价租金111111111")
结果为:
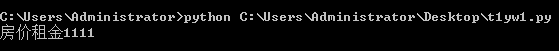
当然代码也可以写成:
res = re.match("房价租金1{0,4}","房价租金111111111")
{0,4}中0为匹配的起始位置,4为结束位置,如果4这个结束位置不填,那么将会从0起始位置(其实位置可以写任意位置,如1,2,3…)匹配到无限次。
^与$
^表示从字符串头进行匹配,$表示配字符串结束。
现在开始来一个综合的挑战,匹配一个邮箱地址吧,这个在正常的需求中也是很常见的:
import re
res = re.match("^\d+@\w+\.\w+",r"1234567@qq.com")
if res:
print(res.group())
查看正则我们写为:^\d+@\w+.\w+
我们分解一下正则表达式的组成:
^\d+:在最开头使用了一个^描述之后的一个正则描述为字符串开头。\d为数字,+号为匹配至少一个。连起来就是在字符串开头匹配一串数字。@\w+:一串数字结束后,硬匹配一个@符号,邮箱都这样。之后\w表示匹配
A-Z、a-z、0-9和下划线_(下划线我不懂,不过好像我见过有吧),由于邮箱有qq邮箱,163邮箱,谷歌等不同的邮箱,所以我就用\w了。由于匹配的不止一个,所以我用了+号进行之前的正则描述。、.\w+:最后进行了一个点 . 的硬匹配,在 . 前面加了一个\是因为需要转义,之后再匹配一个 \w,然后完事。 结果如下:
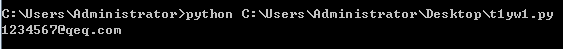
读者可以修改一下邮箱即可查看效果。
注意:以上邮箱的匹配形式并不是严谨的正则编写方式,请勿在实际项目中使用,在这里只是为了方便演示,请见谅。
以上的基础正则基本上在应用开发中已经够用了,接下来再扩展一下正则表达式的符号。
|与()
| 为一个或运算,|符号左右两边的正则都可以进行匹配,只要有一个匹配成功,那么整个正则匹配即为成功:
import re
re_1="^\d+@qq\.\w+"
re_2="^\d+@163\.\w+"
res = re.match(re_1+'|'+re_2,r"1234567@163.com")
if res:
print(res.group())
在以上代码中在上一个案例中修改,其中正则不再赘述,毕竟都相差不大。以上代码中定义了两个变量 re_1 与 re_2,re_1 为匹配qq邮箱,re_2 为匹配163的邮箱,在进行匹配时,在正则中代码编写为 re_1+'|'+re_2,使用 | 符号使左右两边连接,随后进行判断。这个符号也就是或运算。结果如下:

()圆括号的作用是进行分组:
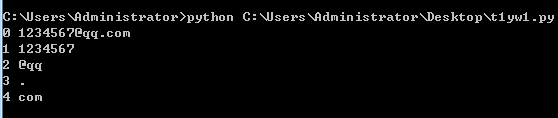
import re
re_1="(^\d+)(@qq)(\.)(\w+)"
res = re.match(re_1,r"1234567@qq.com")
if res:
print("0",res.group(0))
print("1",res.group(1))
print("2",res.group(2))
print("3",res.group(3))
print("4",res.group(4))
以上代码是上一个示例中修改,re_1 的变化不大,使用圆括号为每一个块的正则分了组。之后使用group的时候传入参数 0、1、2、3、4 。0表示正则匹配出来的所有结果,1表示 (^\d+) 匹配的结果,2表示 (@qq) 匹配的结果,之后的序号以此类推。结果如下:
爬虫系列持续更新,欢迎关注、点赞、收藏。
下一篇将使用正则抓取房价。















 4886
4886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











