







cuSPARSE是一个线性代数库,内含很多通用地稀疏线性代数函数,这些函数支持一系列稠密和稀疏的数据格式。下表列举了cuSPARSE支持的线性代数运算。想要对下列函数有更详细的了解,请参阅在线的cuSPARSE用户指南。cuSPARSE将函数进行了分类,第一类函数只能在稠密向量和稀疏向量中进行操作,第二类函数可以在稀疏矩阵和稠密向量中进行操作,第三类函数可以在稀疏矩阵和稠密矩阵中进行操作。

cuSPARSE 数 据 存 储 格 式
稠密矩阵中基本都是非零元素,矩阵中的每个值都是存储在一个多维数组中的。相反,稀疏矩阵和稀疏向量中基本都是零元素,因此在存储时可以只保存非零元素的值及其坐标。稀疏矩阵的存储方式有很多,目前cuSPARSE支持的有8种。接下来主要介绍稠密存储方式、坐标存储方式以及压缩稀疏行方式这三种存储方式。
稠密存储方式
稠密矩阵格式是一种常见的存储方式,这种方式把矩阵中的每个元素都存储起来,不管它是否为零。由于这些矩阵是存储在内存中的,而内存本身是一维的,因此稠密矩阵中的每个元素必须变平且映射到连续的一维内存地址中。下图所示为二维矩阵M到一维存储格式T的映射。

坐标存储方式
坐标稀疏矩阵格式(COO)存储了系数矩阵中每个非零元素的行坐标、列坐标及其元素值。因此当通过给定的行列坐标对存储在COO格式中的稀疏矩阵进行检索的时候,如果没有匹配值,那么这个位置的值为零。
坐标矩阵存储格式与稠密矩阵存储格式所占用的空间大小取决于矩阵的稀疏程度、元素的大小以及存储坐标类型的大小。例如,一个存储32位浮点型数据的稀疏矩阵,其坐标索引使用32位整型表示,只有当矩阵中的非零元素不到1/3时,才会节约存储空间。这是因为在这样的存储格式下,存储一个非零元素占用的空间是稠密格式下的3倍。下图为二维矩阵M到表示其坐标索引T的映射。

压缩稀疏行方式(CSR)
压缩稀疏行方式(CSR)与COO类似。唯一不同的是对于非零元素行索引的存储。在COO中,每个非零元素对应一个表示其值行索引的一个整数,而不是为每个值显示地存储行索引。而CSR则为同一行地所有元素存储一个偏移量。假设,稀疏矩阵M的非零元素存储在数组V中,而这些元素的列索引则存储在数组C中,如下图所示。

因为同一行的所有元素在V中都是被相邻的存储,因此要想找到某一行的值只需要数组V中的一个偏移量和长度值。例如,如果你只想直到M中第三行的非零元素有哪些,我们可以使用偏移量和长度2在V中进行检索,如下图所示,这就是CSR中行索引的存储方式。

在列数组C中利用相同的偏移量和长度值可以确定所存储元素的列索引,因此该方法完全可以确定某个元素在源实矩阵M中的位置。当存储一个较大的矩阵且每行元素较多时,每行都是用一个偏移量和长度值进行存储比存储每个值的行索引要有效。
那么,每行数据的偏移量和长度该如何存储呢?最简单的方法是创建长度为nRows的数组RO和RL,RO用来存储每一行的偏移量,RL用来存储每一行的长度。但如果一个矩阵有很多行,就需要有两个较大的数组。因此,我们可以使用一个长度为nRows+1的简单数组R,数组V和C中第i行的偏移量就存储在数组R的i索引中。第i行的长度可以通过比较i和i+1行的偏移量来判定。而数组R[i+1]中实质上存储的是所有行中所有非零值的总数。R[nRows]是矩阵M中非零值的总数,综上所得数组R如下图所示:

由上图可知,在数组V和C中可以获得矩阵M中第0行的值和列索引,其长度为1-0=1,对于矩阵M的第1行和第2行元素可以应用同样的方法得到其值和列索引。M中非零值的总数也可以由R的最后一个元素获得。因此,CSR比COO更节省存储空间。CSR的完整示意图如下图所示:

可以把CSR格式的稀疏矩阵传到GPU中,然后直接在cuSPARSE函数中使用。首先,假设我们已经通过下列代码在主机上定义了一个CSR格式的稀疏矩阵:
float *h_csrVals; //用来存储稀疏矩阵的非零值个数
float *h_csrCols; //用来存储每个值的列索引
float *h_csrRows; //用来存储每个值得行索引
接下来为每个数组分配设备内存,然后传给GPU:
float *d_csrVals;
int *d_csrCols;
int *d_csrRows;
cudaMalloc((void **)&d_csrVals,n_Vals * sizeof(float));
cudaMalloc((void **)&d_csrCols,n_Vals * sizeof(int));
cudaMalloc((void **)&d_csrRows,(n_rows + 1) * sizeof(int));
cudaMemcpy(d_csrVals,h_csrVals,n_Vals + sizeof(float),cudaMemcpyHostToDevice);
cudaMemcpy(d_csrCols,h_csrCols,n_Vals + sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(d_csrRows,h_csrRows,n_Rows + 1 + sizeof(int),cudaMemcpyHostToDevice);
存储格式小结
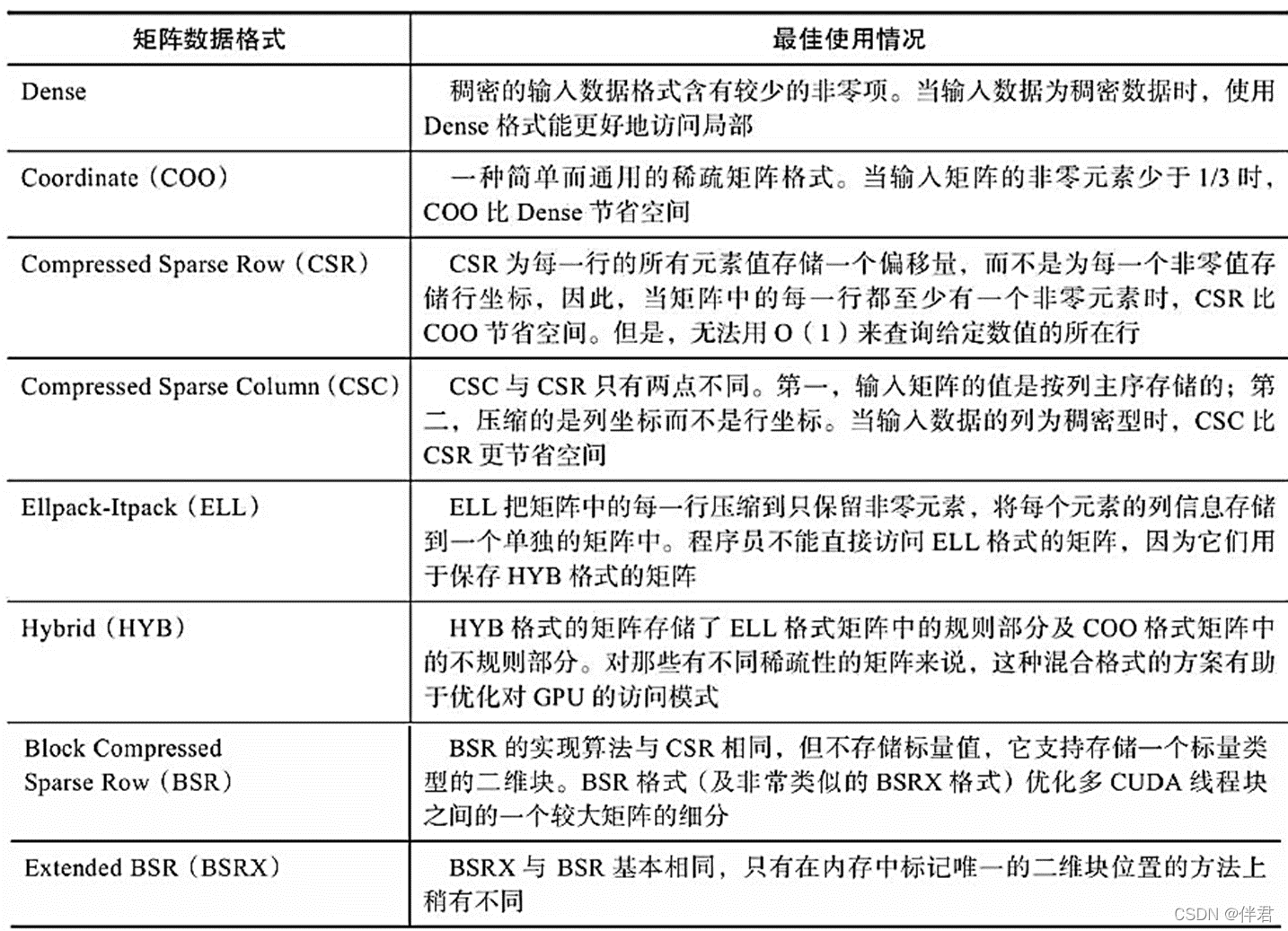
在cuSPARSE中支持上述所有存储格式,并且每种存储格式因所处理数据集的特点而表现出不同的优缺点。cuSPARSE用户指南的第三部分中有cuSPARSE数据格式的完整说明。下表列出了cuSPARSE当前支持的数据格式及各自的最佳使用情况:
用 cuSPARSE 进 行 格 式 转 换
在函数库的工作流有两个阶段,先将应用程序的原始数据格式转换成函数库支持的数据格式,然后再进行这个过程的逆过程。当用cuSPARSE支持的格式转换应用程序的原始数据格式的开销很高时,这两个步骤与之相关。例如,许多传统的应用程序可能只使用稠密矩阵存储格式,然而,在cuSPARSE中执行矩阵与向量或矩阵与矩阵之间的操作时就要求用CSR,BSR,BSRX或HYB等存储格式。
cuSPARSE数据格式转换所带来的开销,包括计算开销和存储空间的开销。因此,为了发挥cuSPARE在稀疏矩阵存储上的优势,我们应该避免进行这种数据格式转换。
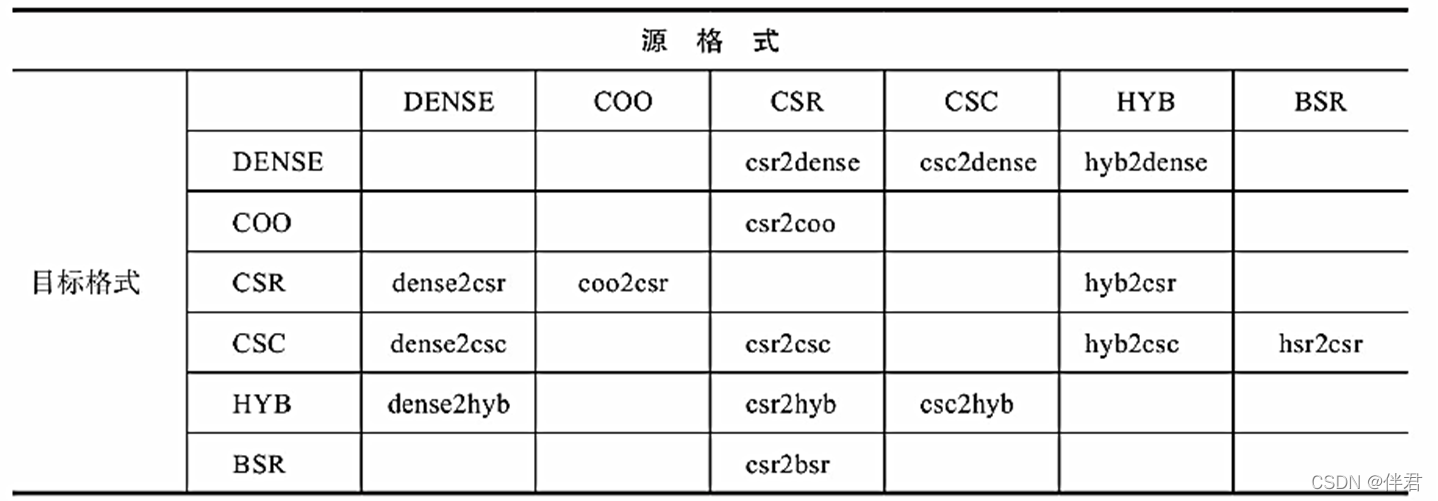
.cuSPARSE里有很多用于格式转换的函数,下表列出了几个。最上面一行时输入数据(源数据)格式,最左边那一列是输出数据(目标数据)格式。空的单元格表明不支持两种数据格式的转换,我们可以通过多次转换来实现未显示支持的转换。
cuSPARSE 功 能 示 范
使用cuSPARSE和CSR稀疏矩阵格式的工作流与前面所述的通用工作流非常类似:
1.使用cusparseCreate创建一个cuSPARSE库句柄;
2.使用cudaMalloc可以分配设备内存,它用于存储稠密和CSR格式的输入矩阵和向量;
3.用cusparseCreateMatDesr和cusparseSetMat *来配置矩阵的某一属性,然后用cudaMemcpy将所有输入数据传到预先分配好的设备内存中。格式转换子程式cusparseSdense2csr用于生成CSR格式的稠密输入数据,并由cusparseSnnz统计稠密矩阵中各列和各行非零元素的数目;
4.在CSR稀疏矩阵和输入向量上调用cusparseScsrmv来执行矩阵向量乘法;
5.cudaMemcpy用于从设备内存的向量y上取回最终的计算结果,由于计算结果是以稠密向量格式存储和处理的,因此不需要格式转换;
6.使用cudaFree,cusparseDestroyMatDescr和cusparseDestroy释放CUDA和cuSPARSE资源。
// Create the cuSPARSE handle
CHECK_CUSPARSE(cusparseCreate(&handle));
// Allocate device memory for vectors and the dense form of the matrix A
...
// Construct a descriptor of the matrix A
cusparseCreateMatDescr(&descr));
cusparseSetMatType(descr, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseSetMatIndexBase(descr, CUSPARSE_INDEX_BASE_ZERO);
// Transfer the input vectors and dense matrix A to the device
...
// Compute the number of non-zero elements in A
cusparseSnnz(handle, CUSPARSE_DIRECTION_ROW, M, N, descr, dA,
M, dNnzPerRow, &totalNnz);
// Allocate device memory to store the sparse CSR representation of A
...
// Convert A from a dense formatting to a CSR formatting, using the GPU
cusparseSdense2csr(handle, M, N, descr, dA, M, dNnzPerRow,
dCsrValA, dCsrRowPtrA, dCsrColIndA);
// Perform matrix-vector multiplication with the CSR-formatted matrix A
cusparseScsrmv(handle, CUSPARSE_OPERATION_NON_TRANSPOSE,
M, N, totalNnz, &alpha, descr, dCsrValA,
dCsrRowPtrA, dCsrColIndA, dX, &beta, dY);
// Copy the result vector back to the host
cudaMemcpy(Y, dY, sizeof(float) * M, cudaMemcpyDeviceToHost);
cuSPARSE 发 展 中 的 重 要 主 题
尽管可以说cuSPARSE是CUDA库中以最快和最简单的方式执行高性能线性代数的函数库,但如果我们要探索cuSPARSE更多的高级功能,那么我们需要谨记cuSPARSE使用的一些关键点。
我们可能会遇到的第一个挑战就是需要保证正确的矩阵和向量数据格式。cuSPARSE本身是不能检测到错误或不恰当的数据输入格式的(例如,将一个CSR格式的矩阵传递给一个只接受COO格式输入的函数)。如果出错,最好的诊断信息可能来自于cuSPARSE内的段错误,或应用程序上的验证错误。
对于cuSPARSE的数据格式转换函数来说,在矩阵和向量数据规模较小时,手动验证其数据格式是可行的。通过格式的逆过程得到原数据格式的数据,可以是自动验证数据集成为可能,并比较两次转换后的数据是否相同。为了对计算函数验证输入数据格式,建议与具有相同功能的主机端实现进行对比。
另一个挑战是cuSPARSE默认的异步行为。对于许多CUDA函数来说这并没有什么特别的,但对于传统的有返回值的主机端阻塞式数学库来说,计算结果会出乎预料。如果我们使用cudaMemcpy将cuSPARSE的结果从设备传到主机,那么应用程序将会自动阻塞,等待来自设备的结果。然而,如果配置要求cuSPARSE使用CUDA流和cudaMemcpyAsync,那么在访问cuSPARSE调用结果之前必须确保任务同步性的正确。
最后一点比较新奇的是标量参数的转换,他总是以引用的方式传递的。如下所示:
float beta = 4.0f;
...
// Perform matrix-vector multiplication with the CSR-formatted matrix A
cusparseScsrmv(handle, CUSPARSE_OPERATION_NON_TRANSPOSE,
M, N, totalNnz, &alpha, descr, dCsrValA,
dCsrRowPtrA, dCsrColIndA, dX, &beta, dY);
如果我们不小心传递了beta而不是&beta,那么我们的应用程序会在主机端产生来自于cuSPARSE库的报错(SEGFAULT),不注意的话会很难调试。
此外,标量输出参数可以作为主机或设备指针进行传递。对于返回的标量结果,用cusparseSetPointerMode函数来决定是否使用指针来获取计算结果。














 7334
7334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









