









TFVT-HRI论文简报
论文信息
题目:
Proactive Interaction Framework for Intelligent Social Receptionist Robots(智能社交接待机器人的主动交互框架)
作者:
Yang Xue, Fan Wang, Jiangyong Li and Yueqiang Dong : Baidu Natural LanguageProcessing Department
Hao Tian : Baidu Research
Min Zhao and Haiqing Pan : Baidu AI Interaction Design Lab
发表期刊(会议):
ICRA 2021
发表时间:
2021
开源仓库:
https://github.com/PaddlePaddle/PaddleRobotics/tree/ICRA21/HRI/TFVT_HRI
论文简报
主动式人机交互可以提高可接受性和客户满意度。但是现有的方法要么基于多阶段决策过程,要么基于端到端决策模型。另一方面,现有的端到端模型仅限于很泛的问候语,例如:“你好”,“有什么需要帮助的吗?”,“打扰一下”。尽管这些话在某种程度上可以打破僵局,但是他们提供的信息很少,也没有显示出对场景的理解。为了应对这一挑战,论文提出了一个新的端到端决策模型——TransFormer with Visual Tokens for Human-Robot Interaction(TFVT-HRI)。训练集和测试集的数据是从一个在职接待机器人收集到的,然后由专家对其进行注释,以获得适当的主动行为。实验结果表明,与以往的被动接收策略相比,该决策模型取得了较好的性能,具有更高的人性化和智能化。
1. Why
由于大多数现有的接待机器人只能被动地接听用户的消息,因此在许多情况下,新访客可能没有动力与机器人交互。这可归因于缺乏对机器人的知识或者对他的能力期望值较低。然而主动接待机器人可以尝试自己发起交互,但是不恰当的主动交互会引起反感的风险。为了使主动交互更人性化,更容易被人接受,需要正确理解用户的意图。以往的工作首先需要对场景进行分类,比如“有人路过”,“有人在挥手”。为了识别这些场景,通常需要复杂的传感器设置。此外,还有一些“微信号”过于复杂,难以归类。
虽然之前的工作也使用端到端框架来生成主动问候语,但是他们的工作都受到以下限制:
-
机器人的行为仅限于极少数类型,通常不到10种,其中大多数很泛的问候语
-
对于主动的HRI,最好是随着时间的推移进行推理,而不是依赖于一个单一的框架。例如,来访者可能会犹豫很久,四处张望,这是寻求帮助的一个重要标志。
-
机器人的决策是基于一个特定的人或者一组特定的人,而不是基于场景,大多数端到端的决策都是基于场景的
为了应对上述挑战,提出了一个新的端到端框架,它具有如下特点:
- 使用 visual token extractor 提取图像特征
- 使用视频连续帧,以及每个visual token的时间和空间信息
- 使用transformer模型来处理token,以增强不同对象和不同时间之间的信息交互
为了训练决策模型,在一个在职接待机器人上收集了丰富的数据集,然后,邀请专家对视频进行审查,并标注适当的主动行为。并且收集了1000+由语言、表情、身体动作组成的多模态动作。
为了验证所提出的方法,首先将TFVI-HRI与最新的动作识别方法R(2+1)D model进行了比较,然后在Xiaodu Robot进行了一个用户实验。实验表明,TFVI-HRI能够产生类似人类的行为,表现出对场景的深刻理解,并在整体舒适性、自然醒、友好性和智能化程度上高于基于唤醒词HRI系统。
2. What
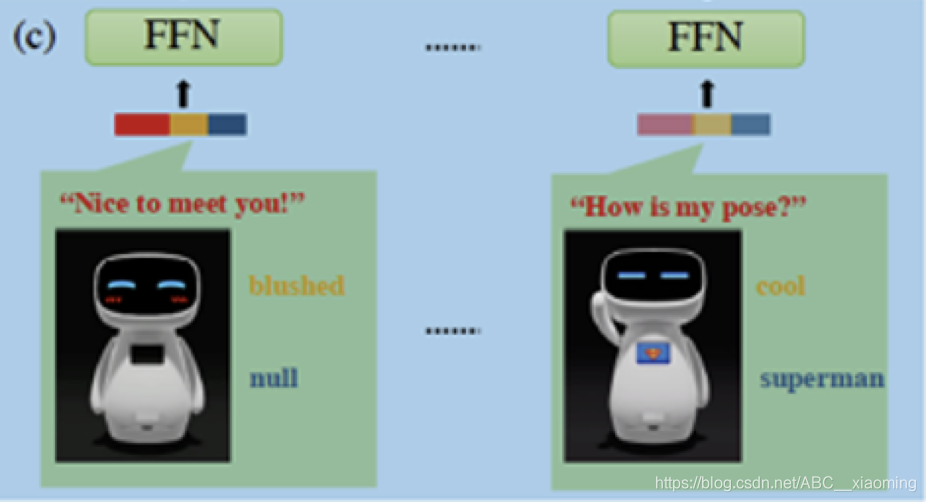
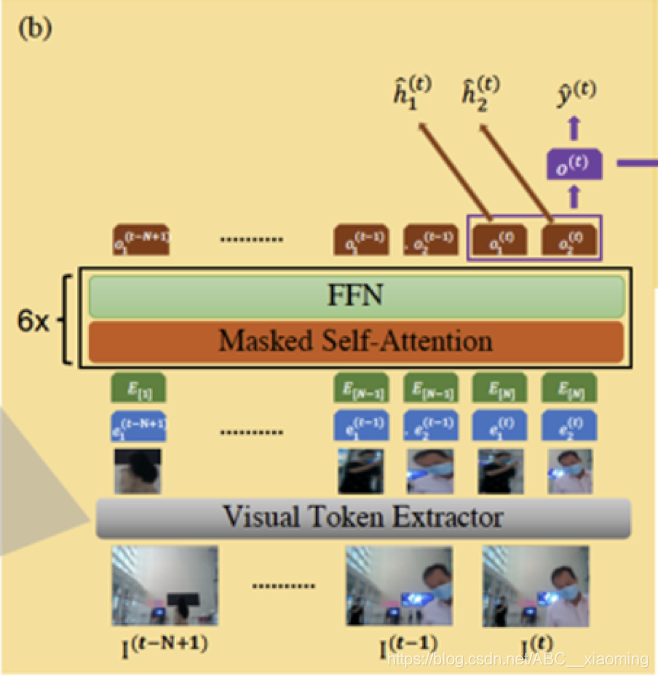
该框架以连续的RGB帧作为输入,决定是否发起交互、交互的对象以及交互的动作。其总体结构如下图所示,由3个模块组成:视觉Token提取器、基于transformer的决策模型、多模态动作编码器。
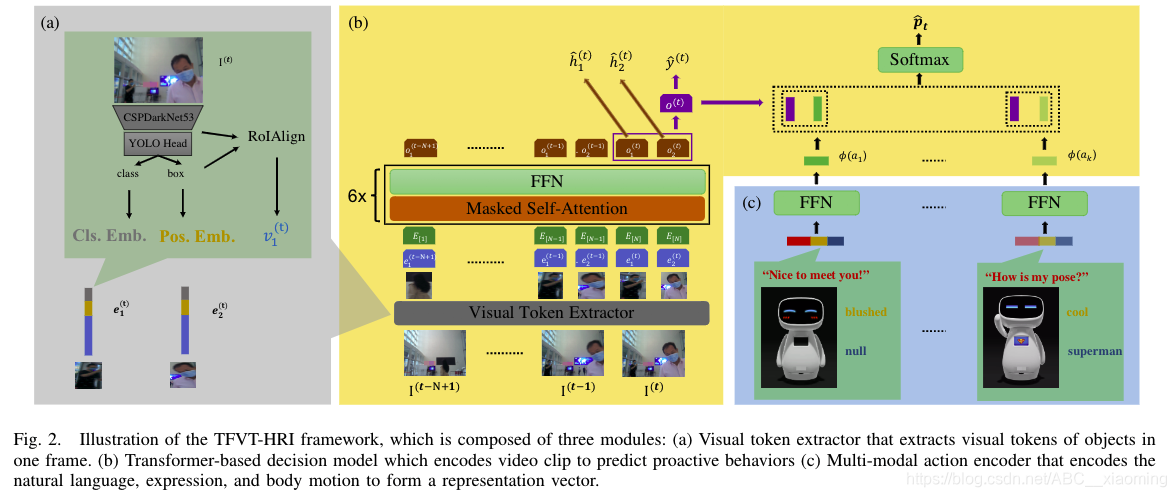
2.1 Visual Token Extractor
在这个模块,首先通过 YOLOV4 提取图像特征。在这个案例中,主要提取场景中可能与人类身份和行为识别有关的6个类别,包括“人”、“背包”、“手提包”、“手提箱”、“领带”和“手机”,而其他类别被忽略
为了降低计算成本,使用YOLOV4的主干输出CSPDarkNet53作为特征提取器。由于边界框的大小不同,采用RoIAlign池化来规范特征图的大小。
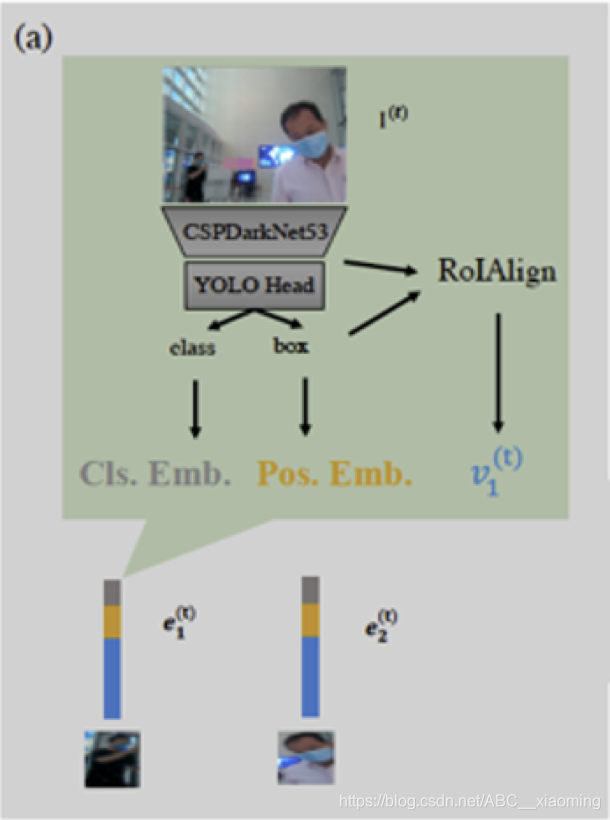
Visual Token还增加了2维的位置信息向量和分类ID。最后把图像特征以及上述嵌入向量合并,得到最终的Visual Token
用公式表示:
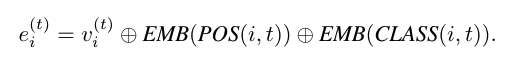
2.2 Multi-modal Action Encoder
动作被表示为话语、表情、身体运动的组合
话语使用一个开源的自然语言预训练模型ERNIE处理成一个向量
表情和身体运动被限制为几个预定义的模式
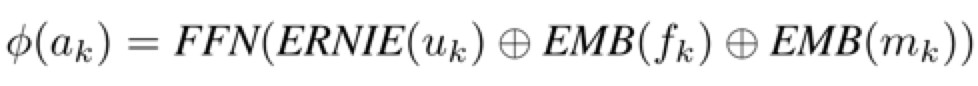
2.3 Transformer-based Decision Model
为了使决策模型能够随着时间的推移进行推理,提出了一个基于transformer的决策模型,它能够通过一段时间内的检测来捕捉每个行人的轨迹,还可以捕捉到目标与其他人之间的互动。该决策模型使用了6个transformer模块。
对于接收到了每一帧,使用Visual Token Extractor 获得一个 Token列表,从中我们选取Top-M(在实验中M=20) Visual Token,选择的优先策略是:
- 有“人”的类别优先选择
- 边界框越大,越优先选择
- 如果不够M个Token,则会padding到M个
在每一个时间步中,使用最新N帧作为输入。对于每个Token,进一步添加相对帧。编码过程可以表示为:
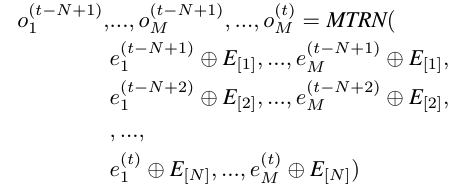
决策模型的预测有3方面:
- 决策是否发起交互
- 预测要交互的目标
- 选择要执行的动作
然后,编码完成后进行最大池化用来表示场景,用公式表示为
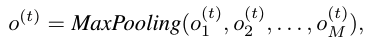
接着,定义模型的输出
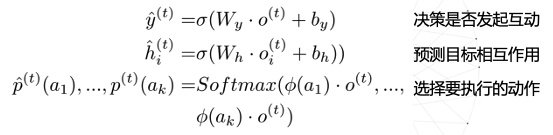
2.4 损失函数
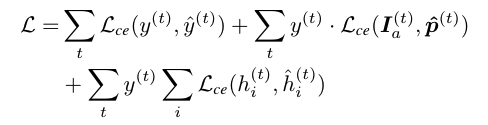
损失函数使用的是交叉熵损失
3. How
3.1 离线评估
使用了一个类似的视频动作识别模型R(2+1)D模型作为baseline,R(2+1)D模型是在社交媒体的大型视频数据集上预先训练的。我们使用R(2+1)D模型在数据集上进行预测多模态动作ID,为了公平,在动作集中加入了空动作,也就是说,选择空动作就意味着不触发启动。同时,加入空动作后,我们就拥有了3种不同的推理模式:

为了找出Visual Token中不同元素的影响,设计了消融实验。通过去除RoIAlign池化特征、位置向量和分类向量
结果表明,TFVT-HRI优于R(2+1)D模型,消融实验表明,最重要的是来自RoIAlign池化特征信息。
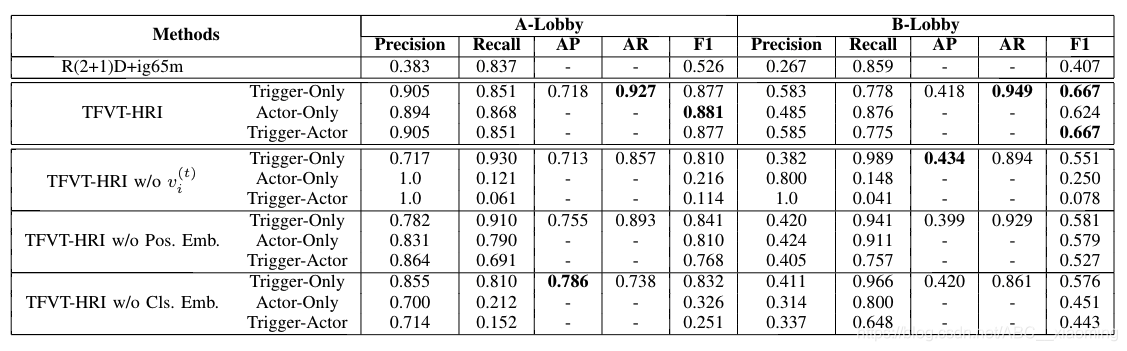
其中,A-Lobby是比较明亮的环境,B-Lobby是比较昏暗的环境
3.2 用户体验研究
招募了30名从未与Xiaodu Robot互动过的被试进行体验,参与者被随机分成两组,实验组和控制组。
在实验组中,机器人按照所提出的框架进行部署,并主动发起交互;在控制组中,机器人被动等待唤醒词。
因变量包括客观因素(成功率)和主观因素(情绪、态度)。对于情绪,使用了自我评估人体模型(SAM)技术,因为他与心理反应有很高的相关性,并将重点放在了valence和arousal上。对于态度,参与者被要求使用7-Point Likert问卷来评估总体舒适度、自然度、友好度和智力水平。
结果表明,对于因变量成功率,100%的参与者在使用该框架时成功互动,而在基于唤醒词的HRI系统中,成功率为80%。
对于情绪,独立样本T检验表明,valence和arousal无显著性差异,两组都有积极的情绪
对于态度,使用独立样本T检验来衡量总体舒适度、自然度、友好度得分,并使用T‘检验来衡量智力得分。与控制组相比,实验组在总体舒适度、自然度、友好度和智力方面的得分显著高于控制组。

4. Summary
该框架具有对象级建模、跨时间和语义空间的推理以及较大的多模态动作空间。进行了离线数据验证和在线用户研究。结果表明,该模型比R(2+1)D等端到端模型具有更好的HRI性能,且计算量比R(2+1)D小。
用户研究表明,所提出的框架在整体舒适性、自然性、友好性和智能性方面比现有的基于唤醒词的Xiaodu Robot HRI系统要高得多。
这项工作的一个可能的扩展是利用用户反馈信号进行在线强化学习,同时,我们还可以进一步将动作空间扩展到连续空间,使机器人能够与更广泛的行为体进行反应,为此有必要探索多模态生成模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









