






神经网络可以被证明为通用函数逼近器 universal function approximatore
transfomer
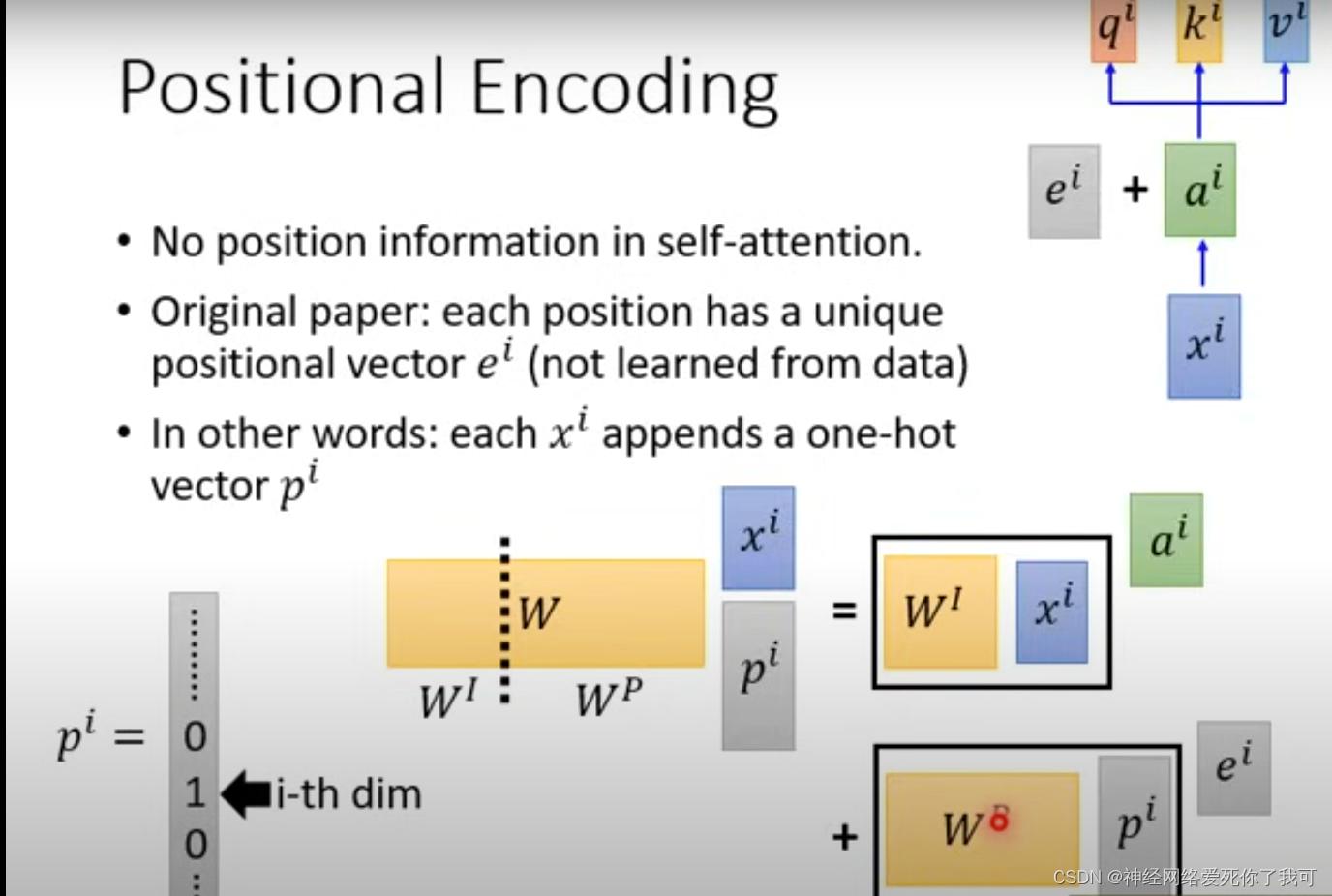
为什么position encoding 可以直接和 input encoding 相加 而不会造成信息的绞缠。
RAG(Retrieval Augmented Generation)检索增强技术
正则化惩罚
分为L1范数和L2范数
共同的目的是为了防止模型过拟合
L1范数:加入权重W的绝对值之和到损失函数里面
特点是:可以将不重要的特征权重值推到/惩罚到0 从而生成稀疏的权重特征矩阵 提取重要特征
L2范数:加入权重W的平方和到损失函数里
特点是:让all特征更平滑 均匀的考虑all特征 不会产生稀疏矩阵 模型保留一定的复杂性
损失函数:交叉熵函数
-Ylog(Yi) 优点 相对于简单的平方损失函数 梯度更大 收敛越快 加速学习
平方损失函数 梯度更大 收敛越快 加速学习














 3194
3194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









