






前言:昨天,美国迎来重磅消息,「星际之门」(Stargate Project)计划在未来四年内投资 5000 亿美元,为 OpenAI 在美国建设新的人工智能基础设施。现在将立即投入 1000 亿美元。但美国不是最近卷王第一棒,25年国内的 AI 圈早就卷起来了!

在白宫新闻发布会上,特朗普和 OpenAI CEO Sam Altman、软银 CEO 孙正义等人联合宣布了一个名为「星际之门」(Stargate Project)的人工智能项目。将开展 5000亿美元(6764亿新元)人工智能(AI)基础设施项目。

美国总统特朗普(左),右起为OpenAI首席执行官奥尔特曼、甲骨文创始人之一埃里森,以及软银创始人孙正义。
但美国只是开始卷,国内早已经卷起来了,光 1 月迭代的模型就超近 20 个。Deep seek 也杀出重围,AI 格局也变成 6+2。今天就来盘点一下 1 月发布的大模型情况。
1月22日:
-
字节跳动发布了豆包大模型 1.5Pro 版本,包含 Doubao-1.5-realtime-voice-pro(实时语音)和 Doubao-1.5-vision-pro(视觉理解)
-
商汤发布了 SenseNova-5o,属于融合大模型交互。
-
阶跃星辰发布了 Step-Video V2,属于视频生成模型。
1月21日:
-
腾讯发布了 Hunyuan3D-2.0,属于3D视觉模型。
1月20日:
-
阶跃星辰发布了 Step-2 mini 和 Step-2 文学大师版,均属于 LLM。
-
字节跳动发布了豆包实时语音大模型,属于实时语音模型。
-
深度求索发布了 DeepSeek-R1,属于推理模型。
-
月之暗面发布了 Kimi k1.5,属于推理模型。
1月16日:
-
智谱发布了 GLM-Realtime(实时语音)、GLM-4-Air(升级)(LLM)和 GLM-4V-Plus(升级)(VLM)。
-
阶跃星辰发布了 Step R-mini,属于推理模型。
-
面壁智能发布了 MiniCPM-o 2.6(实时语音),侧端模型。
1月15日:
-
科大讯飞发布了星火深度推理模型 X1,属于推理模型。
-
MinMax 发布了 MiniMax-Text-01(LLM)、MiniMax-VL-01(VLM)和 T2A-01-HD(语音合成)。
-
Vidu 发布了 Vidu 2.0,属于视频生成模型。
具体更新版本表单如下:
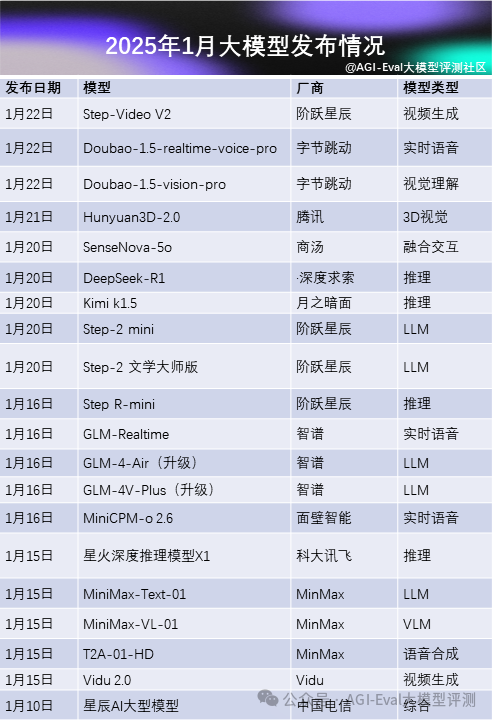
发版时间从最近到最远排列
可以看到推理系模型、多模态模型以及大语言模型都在不同版本迭代,特别是推理系模型。11 月我们评测过国内的推理系模型,那时候 o1 仍排在榜首,,点击查看分析。
但短短 2 个月各家都有了新的迭代,具体能力可以期待我们之后的评测榜单(https://agi-eval.cn/mvp/home)。
| 更新的推理系模型各家都有亮点,没来得及看完,就挑几个我觉得有意思的部分和大家分享一下。
首先是 DeepSeek,
亮点1:DeepSeek-R1-Zero,直接在基座模型上,通过纯 RL 训练。训练过程中观察到“顿悟时刻”(aha moment),即模型自主改进推理流程,使模型能够探索解决复杂问题的 CoT,更好的激发了模型的潜力,但存在可读性和一致性问题。
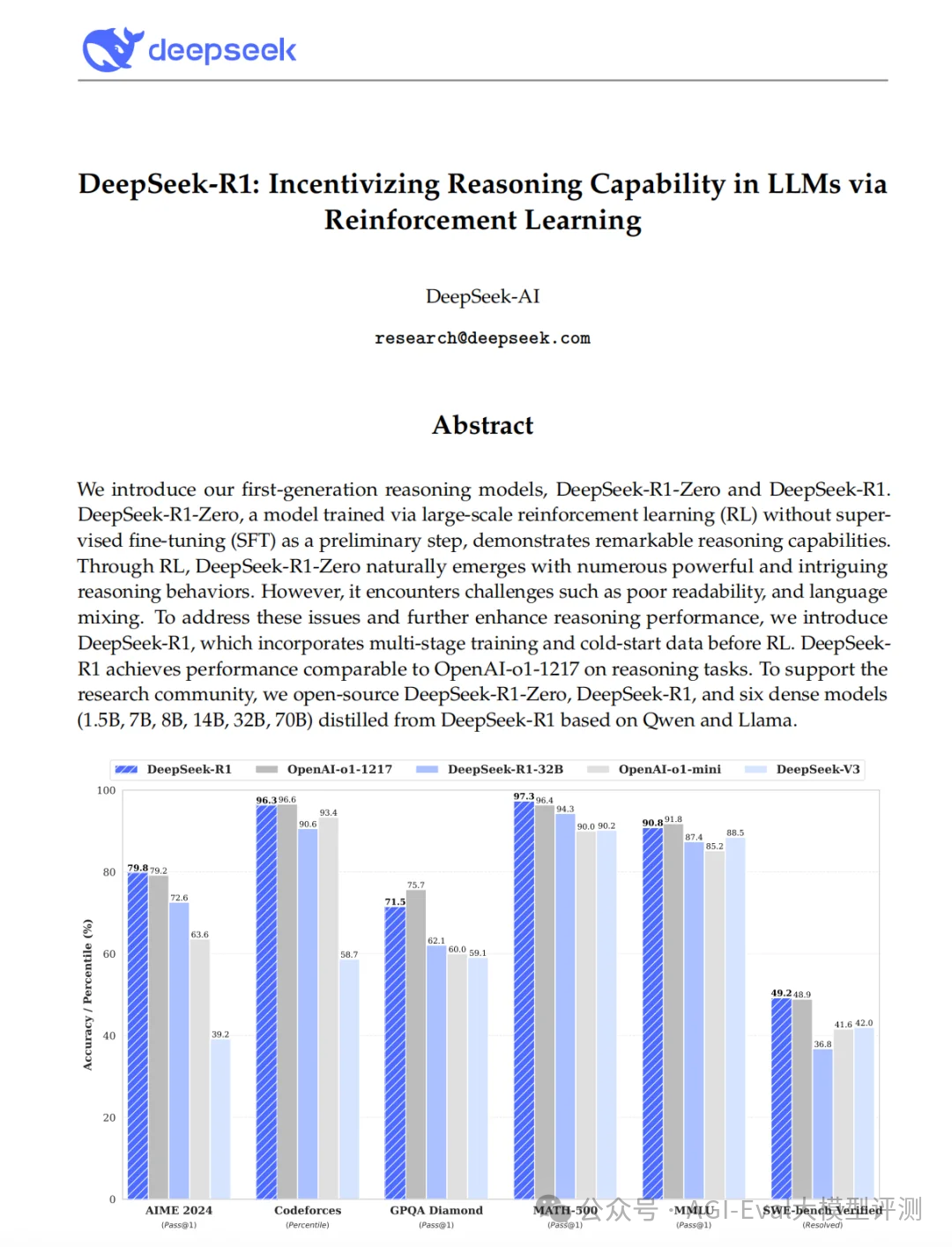
亮点2:DeepSeek-R1 采用多阶段训练流程,在强化学习前引入了监督微调(SFT)和冷启动数据,DeepSeek-R1 的冷启动数据,包括长 CoT 示例进行的少样本提示数据、直接提示模型生成带反思和验证的详细答案的数据以及经过人工处理后的DeepSeek-R1-Zero可读格式输出的数据等,在 DeepSeek-V3-Base 上进行微调,使模型在训练初期更加稳定。
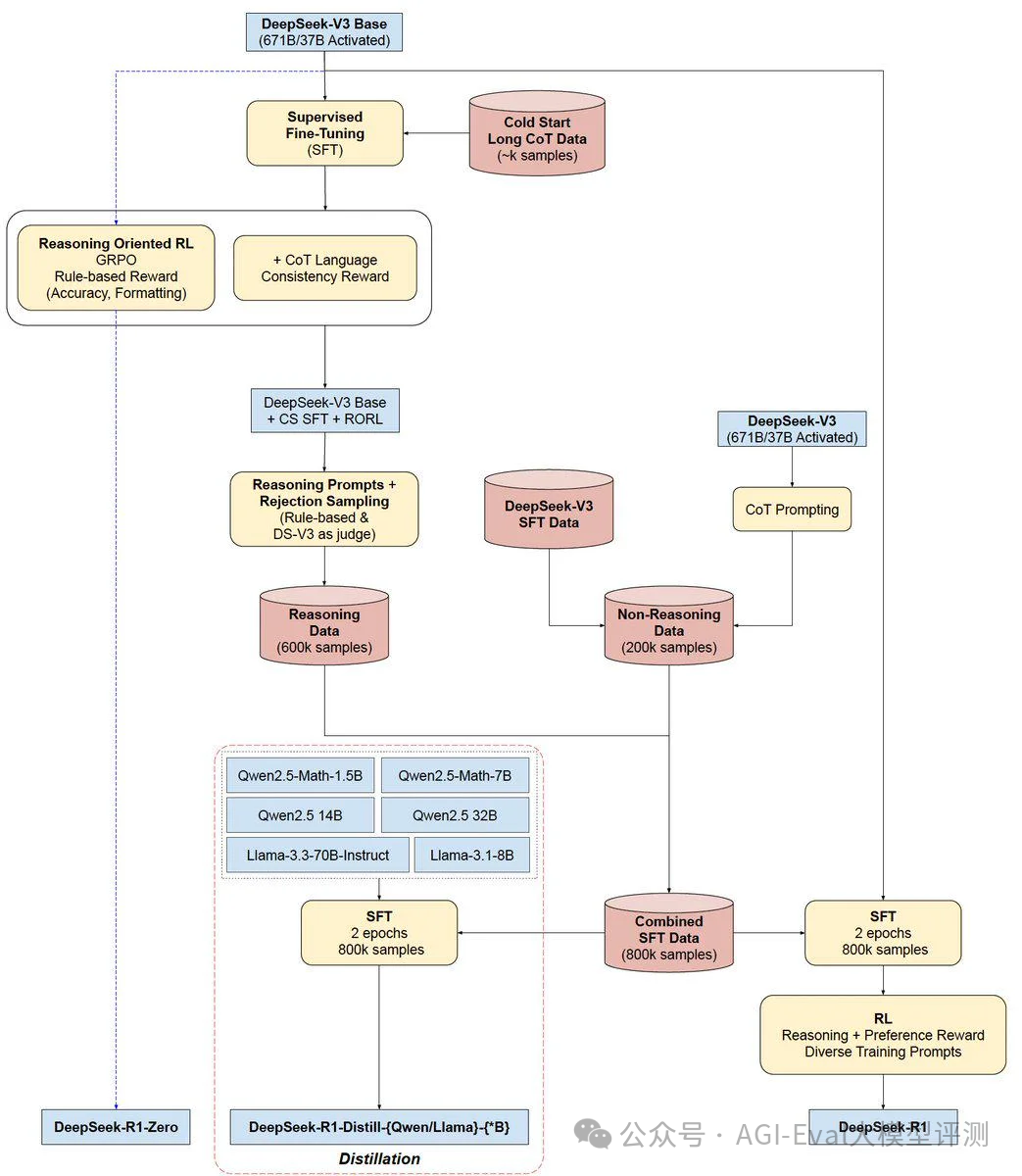
Deep seek训练流程图
亮点3:这个在 V3 版本发布时就提出了,采用群组相对策略优化(GRPO)算法进行强化学习,区别于 PPO,减少了较大的内存和计算负担。

亮点4:这次也开源了蒸馏的小模型,利用 DeepSeek-R1 生成推理数据,对基于 Llama,Qwen 等多尺寸模型进行SFT微调 (无RL),生成效果惊人!如 DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上达到 55.5%,超越 QwQ-32B-Preview。
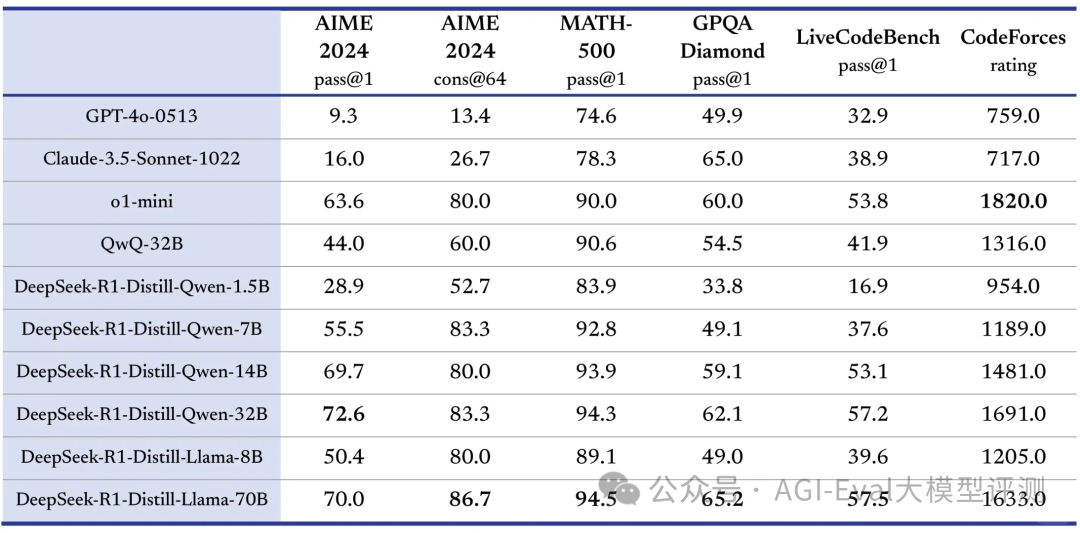
亮点5:性价比真的很不错,API 定价为每百万输入 Tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 Tokens 16元。回想 DeepSeek-V3 仅用 2048 块 H800 GPU 训练不到 2 个月,总计 266.4 万个 GPU 小时,花费约 557.6 万美元,就打造出了一个在 Arena 排名前十的模型。
聊多了拉回其他模型的报告上,比如 Kimi 提出 Long2short,这个很有趣,利用 Long-CoT 技术来改进 Short-CoT 模型,这个也是 Kimi 可以在短推理上取得超优效果的核心。
但具体如何实现,我从 Kimi 团队的研究员 Flood Sung,他的 Long Chain of Thoughts 上看到了一些灵感来源的路径:
首先在 2024 年 9 月 12 号,o1 发布后,效果爆炸,Flood Sung 他们意识到 Long CoT 的有效性。那如何搞 Long CoT 呢,首先要先搞明白 o1,先反推 o1 是怎么做的?RL-LLM 是怎么做的?
他觉得有两张 PPT 至关重要
第一 Noam Brown 这张 PPT,他告诉了我们 Test-Time Search 的重要性,更深层次就是需要让模型能够自行搜索。
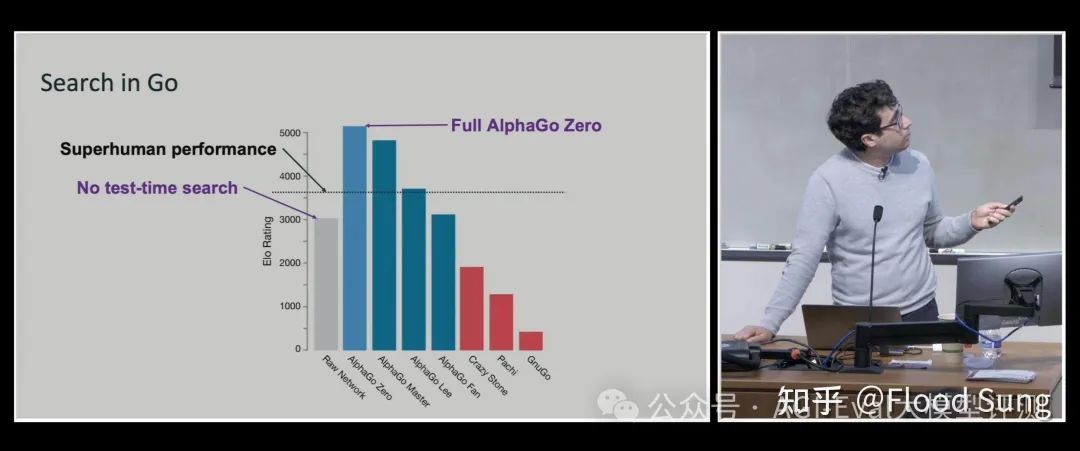
第二张就是 Hyung Won Chung 的 Don't Teach,Incentivize,MCTS 是一种 Structure,A* 是一种 Structure。当人为加了点 Inductive bias 进来强求 LLM 按我们要求的格式进行思考,那么这种思考就是结构化的。而基于对 o1 的观察,两件事联系在一起就得出一个结论 o1 没有限制模型如何思考!
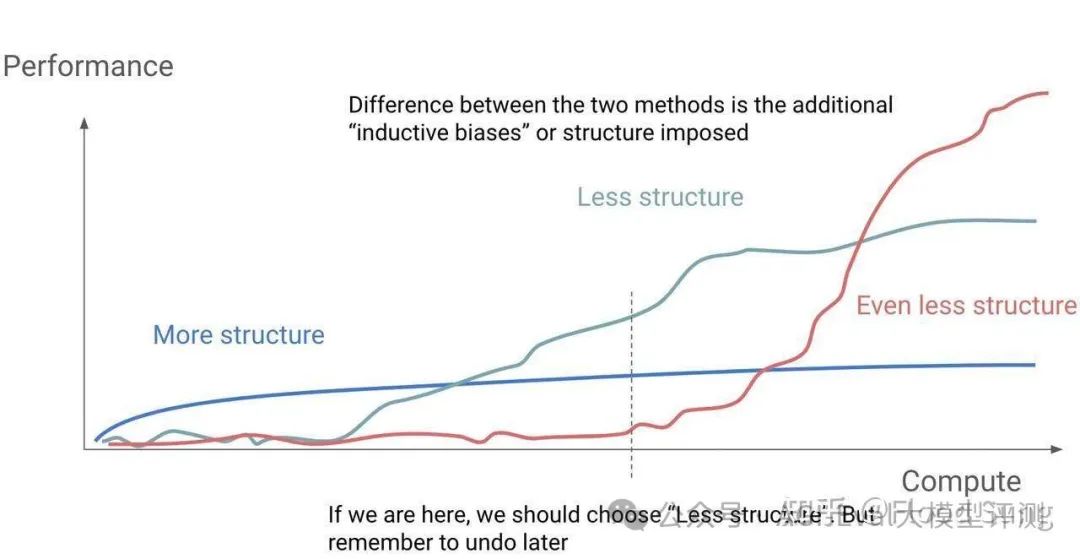
以上思考结合起来就是把问题变成了Contextual Bandit的问题,用Reinforce 的变种来做。下面是最基本的 Reinforce 的公式,简单的说就是做对加梯度,做错减梯度。
根据这一套思路之后就是具体实操,对应的也是 Long2Short 的强化学习,在标准的强化学习训练阶段之后,进行单独的 Long-cot 到 Short-cot 的强化学习训练阶段。采用长度惩罚,进一步惩罚超出期望长度,但保证模型仍然可能正确地输出答案。

这些技术都是在探索一些未来 AI 的一些新的提升,如 Flood Sung 说到的未来或许我们给 AI 一个可衡量的目标,然后让其自己去探索,然后通过 RL 提升模型,不过是把这个过程不断的复制到更复杂的场景。
比如给 AI 一本飞机手册,然后让其自己学会模拟驾驶;
比如让 AI 写出 10 万+的公众号文章;
比如让 AI 发布一个复制 Tiktok 的 App;
比如让 AI 去写一篇文章中 Nature;
还有其他的技术报告没来得及看,准备后面继续探索。可以等我们后续推文的更新。
同样从不一样的技术报告中,也发现了一个华点,在大家的技术报告中,都会表现出自己的模型能力在不同的 Benchmark 的排名都接近甚至超越 O1,这个更深层次看到的是各家厂商的能力排名可能还没有统一标准;同时公开数据集是否会存在测试过拟合情况,排名是否会有影响。
在前段时间有个瓜,关于 FrontierMath(包含了由陶哲轩等 60 多名权威数学家命制的高难度题目), OpenAI 曾给了他们经费赞助,是否可能出现泄露问题?同样我们也在探寻防止数据穿越的问题,构建公平全面的私有Benchmark。打造权威具有公信力的大模型榜单,是我们 AGI-Eval 评测社区一直在探寻的。从第三方视角去评判大模型能力,帮助各家模型发现自己的差异,并进行能力补足,大家继续提升继续卷起来。
以下是一些技术报告指路,有兴趣大家也可以按需研究。
字节跳动
1.Doubao-1.5-realtime-voice-pro
-
GitHub 网页地址:https://github.com/LLM-Red-Team/doubao-free-api
-
项目主题地址:豆包 app 7.2.0版本
2.Doubao-1.5-vision-pro
-
GitHub 网页地址:https://github.com/LLM-Red-Team/doubao-free-api
-
项目主题地址:豆包 app
深度求索
DeepSeek-R1
-
GitHub 网页地址:https://github.com/deepseek-ai/DeepSeek-R1
-
论文地址:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
-
项目主题地址:https://www.deepseek.com/
月之暗面
Kimi k1.5
-
GitHub 网页地址:https://github.com/LLM-Red-Team/kimi-free-ap
-
论文地址:https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf
-
项目主题地址:https://kimi.moonshot.cn/kimiplus-square
阶跃星辰
1.Step R-mini
-
项目主题地址:https://yuewen.cn/chats/new
2.Step 2 文学大师版
-
项目主题地址:https://yuewen.cn/chats/new
3.Step-2 mini
-
论文地址:https://arxiv.org/abs/2412.01925
-
项目主题地址:https://yuewen.cn/chats/new
智谱
1.GLM-Realtime
-
项目主题地址:https://bigmodel.cn/
2.GLM-4-Air(升级)
-
GitHub 网页地址:https://github.com/THUDM/GLM-4
-
论文地址:https://arxiv.org/abs/2406.12793
-
项目主题地址:https://open.bigmodel.cn/
3.GLM-4V-Plus(升级)
-
GitHub 网页地址:https://github.com/THUDM/GLM-4
-
论文地址:https://arxiv.org/abs/2406.12793
-
项目主题地址:https://bigmodel.cn/
Vidu
Vidu 2.0
-
论文地址:https://arxiv.org/pdf/2405.04233
-
项目主题地址:https://www.vidu.cn/
MinMax
1.T2A-01-HD
-
项目主题地址:https://hailuoai.com/audio
2.MiniMax-VL-01
-
GitHub 网页地址::https://github.com/MiniMax-AI/MiniMax-01
-
项目主题地址:https://hailuoai.com/
3.MiniMax-Text-01
-
GitHub 网页地址:https://github.com/MiniMax-AI/MiniMax-01
-
项目主题地址:https://hailuoai.com/
科大讯飞
星火深度推理模型X1
-
项目主题地址:https://xinghuo.xfyun.cn/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









