






最近模型都在集中发布,才评完DeepSeek V3-0324版本,接踵而来的就是GPT-4o的图像生成能力的升级以及Gemini-2.5-pro版本的发布,最近我们也在马不停蹄的进行评测分析中,下面可以看看我们最新的关于GPT-4o图像生成能力的评测。

图片
目录:
1.GPT-4o的发布信息
2.AGI-Eval图像生成能力评测分析
2.1 评测结论
2.2评测说明
2.3 综合维度表现
2.4 GPT4o具体表现分析
3.GPT-4o VS 其他模型实测对比
01 GPT-4o的发布信息
25 日 Open AI 宣布将自己迄今为止最先进的图像生成器构建到 GPT‑4o 中。使用能够实现精确、准确、逼真的输出的原生多模式模型来解锁有用且有价值的图像生成。此次发布的报告中能和其他多模态模型对比突出的亮点:
1.可以在聊天环境中基于图像和文本进行构建,从而确保始终保持一致性。
2.同时GPT‑4o 的图像生成遵循详细的提示,注重细节。其他系统在处理约 5-8 个对象时会遇到困难,而 GPT‑4o 可以处理多达 10-20 个不同的对象,对象与其特征和关系的更紧密绑定可以实现更好的控制。
image.jpeg
02 AGI-Eval图像生成能力评测分析
2.1 评测结论
实际GPT‑4o 的图像生成能力如何,AGI-Eval大模型评测团队第一时间开始了评测,得出以下评测结果:
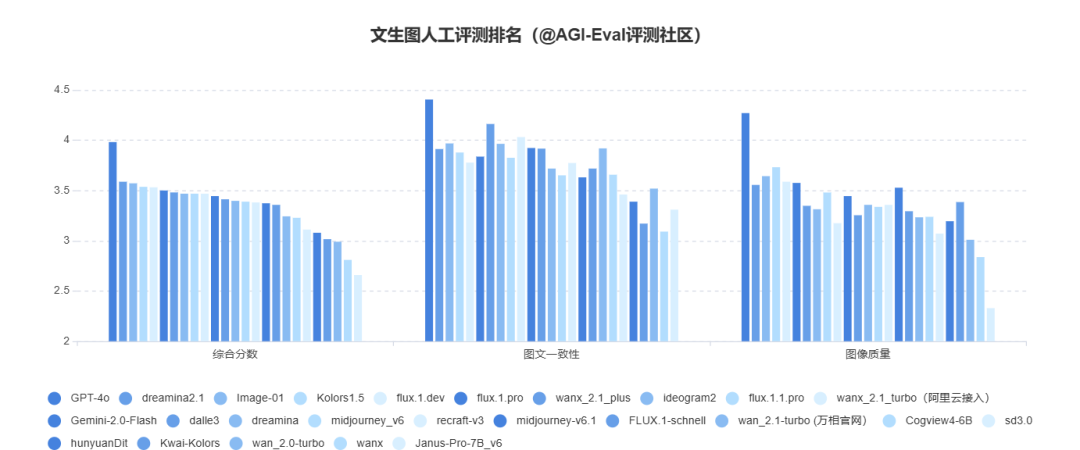
- GPT-4o文生图能力全维度排名第一,且综合得分显著高于第二名Dreamina2.1。
- 同属于原生多模态模型的Gemini-2.0-Flash表现相对,排名为第11名,与DALLE3,MJ等模型在同一水位。
- 原生多模态模型在结构化生成(图表、字符)和常识推理任务上有更好的表现,且GPT-4o在创意设计类任务(海报、插画)上明显强于业界其他模型。
参与对比模型基础信息
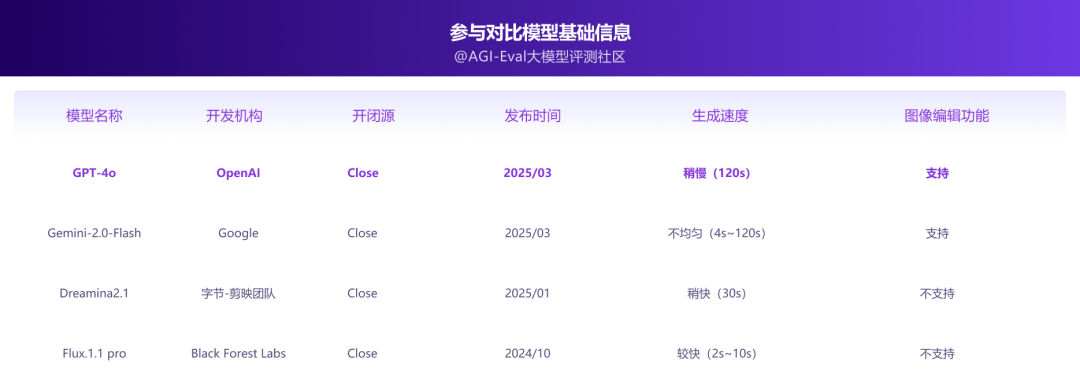
image.jpeg
注释1:不均匀:简单、清晰的prompt生成速度10s内,含推理类prompt生成速度120s左右。
注释2:在实际生成时,仅有Gemini会根据任务的复杂性(是否涵盖分析推理为准)在生成速度上表现出明显的差异(来自人工爬取实际体验)。
注释3:因GPT-4o仅网页端暂不提供API,所以本次测评从文生图V6评测集中进行采样评测能力不同能力水位。待开放API后可补充自动评测结果,以及本次评测暂不包含多轮编辑图像能力,仅在单图维度对各类能力进行评测。
想获得最新模型评测报告,记得关注我们哦~
2.2 评测说明
此次评测的测试基准为人工评测,采用AGI-Eval社区的私有自建评测集,以快速反应模型能力水位为主,暂不具备对同梯队的模型进行精细区分。
- 评测数据集:采样全量人工评测集,考察生成能力项包括实体生成、人像、风格&主题等,共计42条评测数据。
- 评测方法:采用人工评测的方式,在给定prompt和对应的图片上结合打分标准,对图片在图文一致性、图像质量维度进行1分~5分打分,并再结合图片整体生成质量给出综合评分。最终结果取多标均值代表模型在主观体感上的综合表现。
此次数据集中包含9个标签分类(主体、事件、场景、风格、文化、主题等),其中占比较高的3个标签分别是:
主体占比最高达到48%,主要包括人物、建筑物,以及与人产生交互的其他日常物品,如餐厨用品、动物、日常用品、食物等;
其次为事件,包括日常人物行为如行走、吃东西、学习、情感表达,现实世常见现象如事件推测、物理模拟等以及其他事件;
场景包括现代城市以及其他自然场景。其中现代城市相对集中如街道、道路、城市,自然场景种类相对丰富如草地、沙漠、山野、海面、江河等多个类别。
注释1:图文一致性:评估图片是否全面包含文本提到的信息,能否精确地理解文本中的字面意义。需要准确理解用户prompt中的每一个要求和细节:包括对物体、人物、场景、风格等所有相关要素的描述。
注释2:图像质量:评估图像生成合理性、真实性水平,关注生成的图像在逻辑、结构、设计等方面是否符合常规的要求,例如:是否符合物理规律,是否存在形变、畸形、粘黏。生成的图像被识别为AI生成的难度,有无明显的拼接痕迹等。
2.3 文生图模型评测榜单
- GPT-4o模型的综合分数最高,且在图文一致性、图像质量维度上均领先于其他模型,整体性能最佳。其他模型的分数相对接近,竞争较为激烈;
- 图文一致性维度上除GPT-4o模型,wanx_2.1_plus排名第二,其次为wanx_2.1_turbo(阿里云接入)、Image-01(Minimax)、ideogram2;
- 图像质量维度上GPT-4o领先优势更明显,其次为Kolors1.5、Image-01(Minimax)、flux.1.dev;
整体表现相对均衡的模型是flux.1.dev、midjourney-v6.1,在维度上差异较大的模型是wanx_2.1_plus、dalle3。
图片
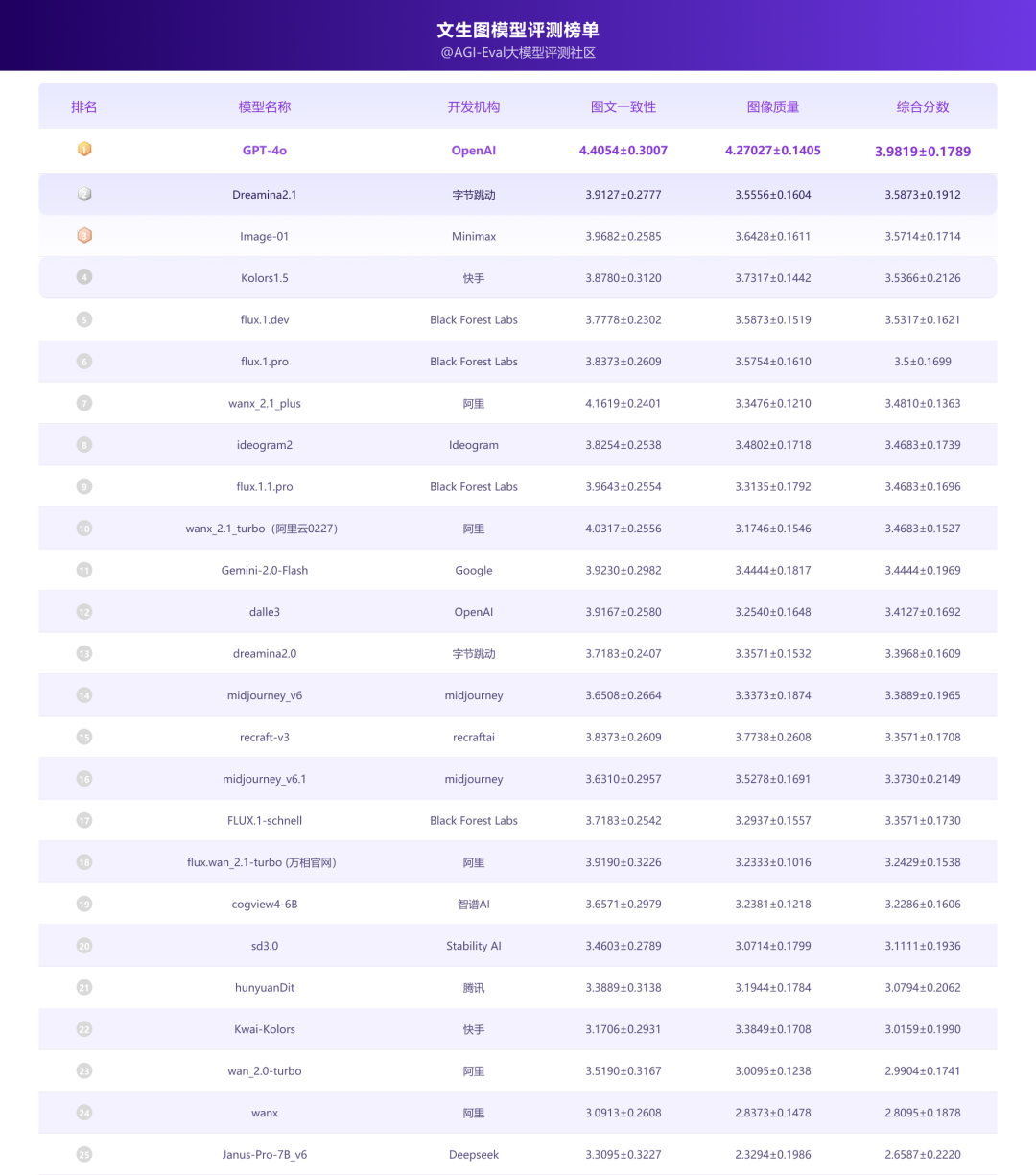
image.jpeg
2.4 GPT4o具体表现分析
1. 优势维度:GPT-4o在创意设计、复杂实体生成、学科知识、字符图表中均有突出表现;
- 在字符生成上,过往的生图模型会存在字母畸形、字符混乱的问题(包括Gemini-2.0-Flash),GPT-4o模型生图中没有这类问题且生成的字体也更加美观;
- 在图表生成上,GPT-4o和Gemini-2.0-Flash均有更好的表现,表格结构清晰、美观,对比其他生图模型则是无法生成;
- 在复杂人像生成上,GPT-4o的生图合理性上表现更好,没有出现大幅度的肢体畸形、五官扭曲现象,Gemini-2.0-Flash目前还做不到。
2. 劣势维度:GPT4o在多图生成上存在理解偏差 ,导致指令遵循能力下降,以及在部分图像中依然存在生图类模型均存在的真实性问题有轻微AI感;
03 GPT-4o VS 其他模型实测对比
下面也将从创意设计、插画、实体生成、多图生成等八大生成任务进行实际案例展示和对比分析。
以下实测排序从左到右依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
创意设计
prompt:Please create this image:A movie poster of mountain and sea(一张描绘山和海的电影海报)
一致性维度:GPT-4o与Gemini-2.0-Flash满足“海报”定义(即需要生成文字),其余模型不满足;
图像质量维度:GPT-4o生成的单词正确,整体合理性好;Gemini-2.0-Flash疑似试图生成中文,但字符乱码,Dreamina2.1与Flux.1.1 pro合理性维度均无明显问题,但Flux.1.1 pro的真实感较差。

image.jpeg

image.jpeg

image.jpeg

image.jpeg
从上到下依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
插画
prompt:Please create this image:A painting depicting a crowd on a busy street, with the focus on a street performer, deliberately blurring the foreground and background crowds to create a sense of depth and spatial layering.(一幅插画,描绘一条繁忙街道上的人群,将焦点放在一个街头艺人身上,使前景和背景的人群适当模糊,产生深度感和空间层次)
一致性维度:GPT-4o准确表达“焦点”和“空间层次”,完全符合要求;Gemini-2.0-Flash未明确体现出“街头艺人”,也不符合插画风格,其余模型未体现出“前景和背景的人群适当模糊”;
图像质量维度:GPT-4o画风下可接受背景人物模糊,整体合理性较好;Gemini-2.0-Flash右侧人物与箱子交叠处、疑似遮阳伞重叠处不合理较明显,其余模型人物手部、远景较不合理。

image.jpeg

image.jpeg


从上到下依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
实体生成
prompt:Please create this image:A tea pot with the Yin Yang Bagua symbol imprinted on it, made of purple clay material. There is a tea cup next to it, and it is filled with tea.(一把印有阴阳八卦图的茶壶,茶壶是紫砂材质,旁边还有个茶杯,并且倒满茶了。)
一致性维度:GPT-4o完全符合prompt要求,是目前唯一将“阴阳八卦”生成正确的模型,其余模型则不完全符合。
图像质量维度:GPT-4o的合理性、真实性均体现较好,实体的材质与光影真实;Gemini-2.0-Flash的真实性稍有欠缺,其余模型生成的壶身上的花纹不合理较明显。

image.jpeg

image.jpeg

image.jpeg

image.jpeg
从上到下依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
多图生成
prompt:Please create this image:Create a set of pictures depicting a person walking on the street when suddenly it starts raining. As they didn't carry an umbrella, they end up getting drenched like a wet chicken. Showcase a humorous and comical atmosphere in a stick figure style.(生成一组图片,展示一个人走在路上忽然开始下雨了,因为没带伞最终被淋成了落汤鸡,用简笔画风格体现出滑稽搞笑的氛围。)
一致性维度:GPT-4o能正确理解“getting drenched like a wet chicken”,风格与粗粒度情感都表现较好,完全符合要求;Gemini-2.0-Flash与Dreamina2.1未生成多图,且错误理解“a wet chicken”;Flux.1.1 逻辑较为混乱,未能体现“没带伞”和“淋湿”之间的关系。
图像质量维度:GPT-4o画风合理性较好,Gemini-2.0-Flash与Dreamina2.1因误生成鸡导致画面整体合理性较差,Flux.1.1 pro人物与雨伞交互处合理性较差。
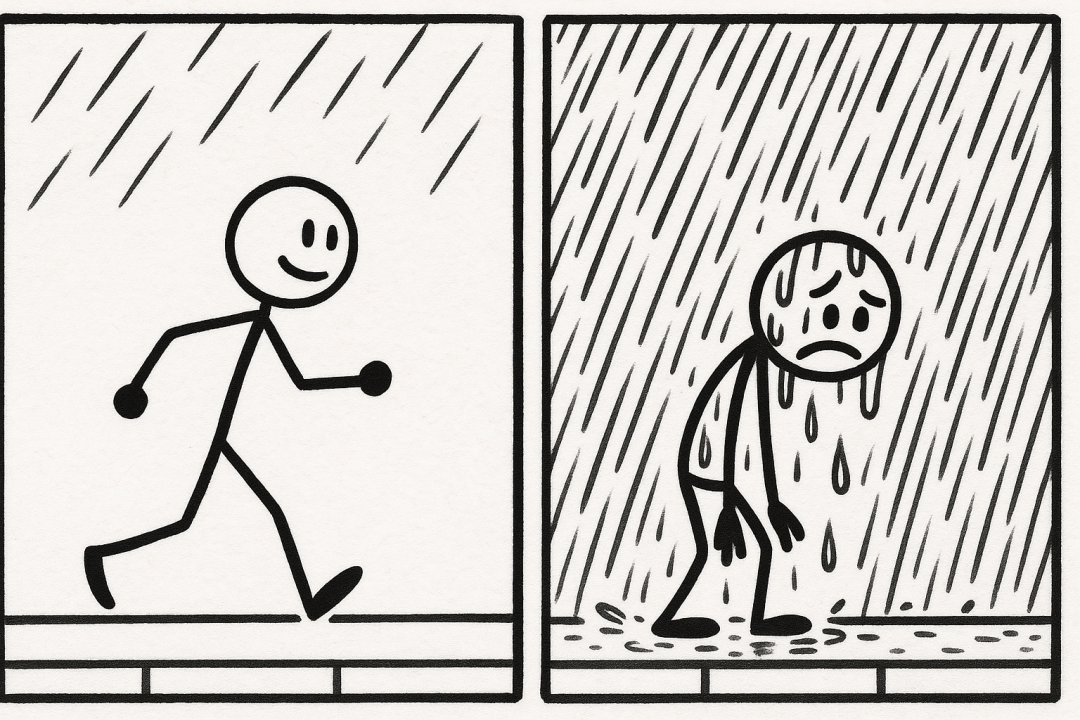
image.jpeg

image.jpeg

image.jpeg

image.jpeg
从上到下依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
学科知识
prompt:Please create this image:Can you generate an analysis chart of Earth's crust structure for Xiao Ming, who is starting to study geography but suddenly forgot the relevant knowledge while reviewing?(小明开始学习地理课程,但是复习时突然忘记地壳结构的相关知识,你可以给小明生成一张地壳结构分析图吗?)
一致性维度:地壳结构分析图存在2D与3D的形式,因此基本形态均能认可,但在专业知识上,GPT-4o能给出正确分层及标注,优于其他模型。
图像质量维度:GPT-4o生成的单词正确,地壳结构大体合理,其他模型的字符乱码及结构错乱较明显。

image.jpeg
image.jpeg
image.jpeg

image.jpeg
从上到下依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
常识推理
prompt:Please create this image:Two doctors riding the tallest animal in the world.(两个医生骑着现今世界上最高的动物。)
一致性维度:GPT-4o与Gemini-2.0-Flash推理正确,给出的是符合prompt要求的长颈鹿;Dreamina2.1推理出错,Flux.1.1 pro疑似自创生物,未进行推理。
图像质量维度:GPT-4o出现听诊器、人物手指的细节问题,整体真实性较好;Gemini-2.0-Flash与Dreamina2.1的人物面部、肢体畸形较明显;Flux.1.1 pro人物无明显畸形,但因推理出的生物不符合现实世界,也视为合理性扣分。

image.jpeg

image.jpeg

image.jpeg

image.jpeg
从上到下依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
复杂人物生成
prompt:Please create this image:Real Photography: In a lively hotpot restaurant, five young people are gathered together, enjoying a hotpot meal. Various side dishes and condiments are spread out on the table, while their faces are filled with joy and smiles.(真实摄影,一家热闹的火锅店里,5个年轻人围在一起吃火锅,各种配菜和调味品铺在桌子上,脸上充满了喜悦和笑容。)
一致性维度:GPT-4o、Dreamina2.1、Flux.1.1 pro均符合prompt基本要求;在“热闹的火锅店”氛围体现中,GPT-4o和Flux.1.1 pro较好;Gemini-2.0-Flash生成人数出错。
图像质量维度:GPT-4o仅筷子及菜品细节存在不合理,其他模型均存在不同程度的人物手部扭曲畸形,不合理程度相对较严重;同时GPT-4o的光影效果、人物皮肤质感等真实性较好,其他模型则在质感上稍有欠缺。

image.jpeg

image.jpeg

image.jpeg

image.jpeg
从上到下依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
文字图表
prompt:Please create this image:Design a grid chart to record students' final grades, with each column clearly differentiated by colors. The first column is "Name," the second column is "Mathematics," and the third column is "Science."(设计一个方格图表,记录学生的期末成绩,要求每一列使用明显的颜色区分,第一列是“姓名”,第二列是“数学”,第三列是“科学”。)
一致性维度:GPT-4o与Gemini-2.0-Flash完全符合prompt要求,Dreamina2.1和Flux.1.1 pro则仅能体现“方格图表”的大致模式,无法将字符与表格内正确位置对应。
图像质量维度:GPT-4o与Gemini-2.0-Flash单词生成正确,表格清晰,Dreamina2.1和Flux.1.1 pro单词乱码错误明显,对图表整体表现较差。
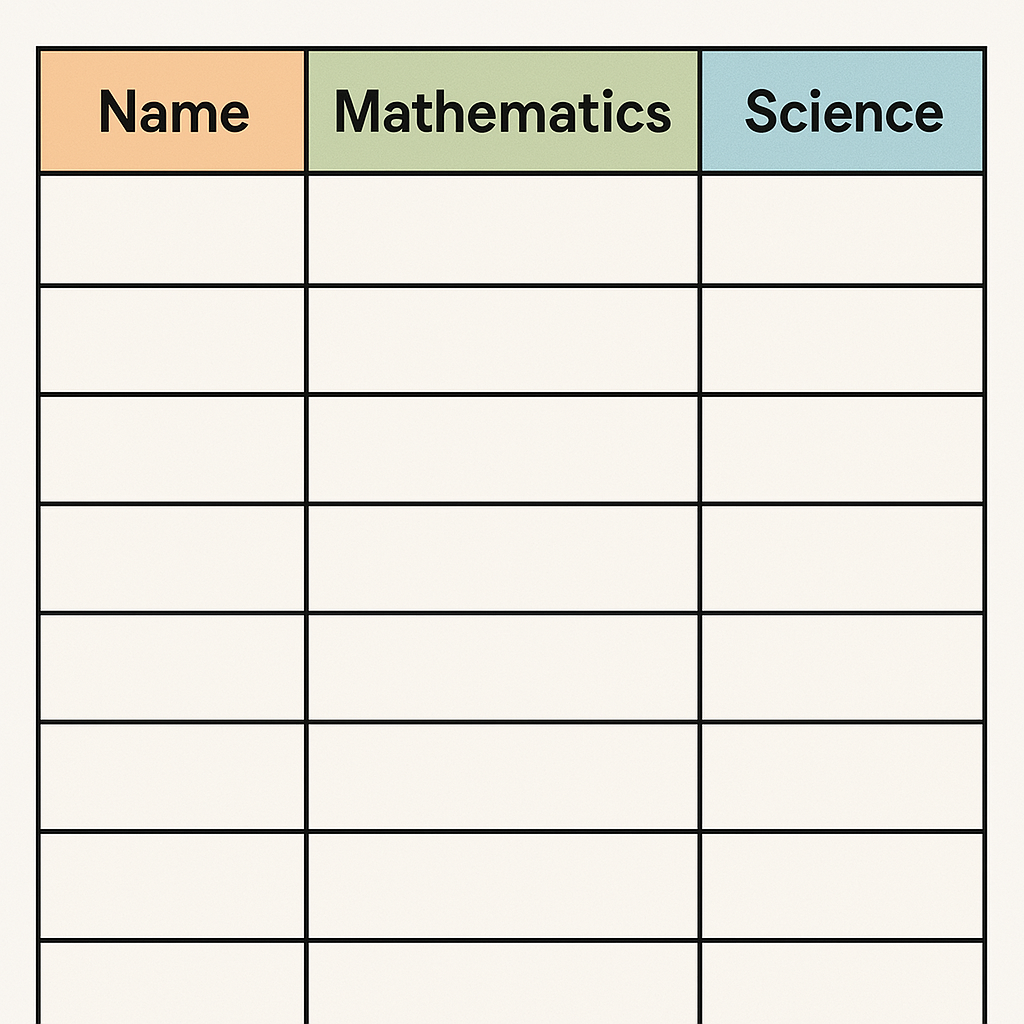
image.jpeg
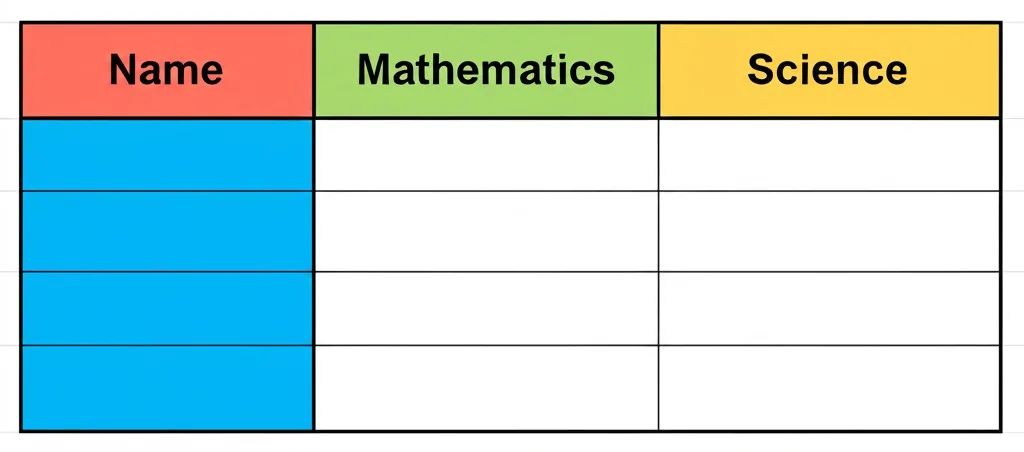
image.jpeg

从上到下依次为GPT-4o->Gemini-2.0-Flash->Dreamina2.1->Flux.1.1 pro
之后我们会持续跟进最新的模型更新,持续输出最快、最新、最权威的评测报告,让大家掌握一手的模型能力信息。别忘了关注我们哦!
下一期评测报告预告抢先告诉大家,Gemini-2.5-Pro!!想看的朋友别忘了关注我们哦!期待下期和大家的分享。
往期回顾
1.【AGI-Eval行业动态 NO.6】Manus爆火48小时:一场关于AI未来的“乐观”与“警惕”
2.【AGI-Eval行业动态 NO.5】今年太卷了,30+的模型已发布,还有10款模型即将发布!
3.【AGI-Eval行业动态 NO.4】Claude 3.7 Sonnet将模型行业卷向了新高度,但背后仍然还有新的问题
我们也在探索Agent能力评测的新方式,同时文末也期待大家参与我们社群,一起探寻 AGI 的更多可能性,发现更多不一样的视角,提出问题才有机会解决问题。



















 3975
3975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









