






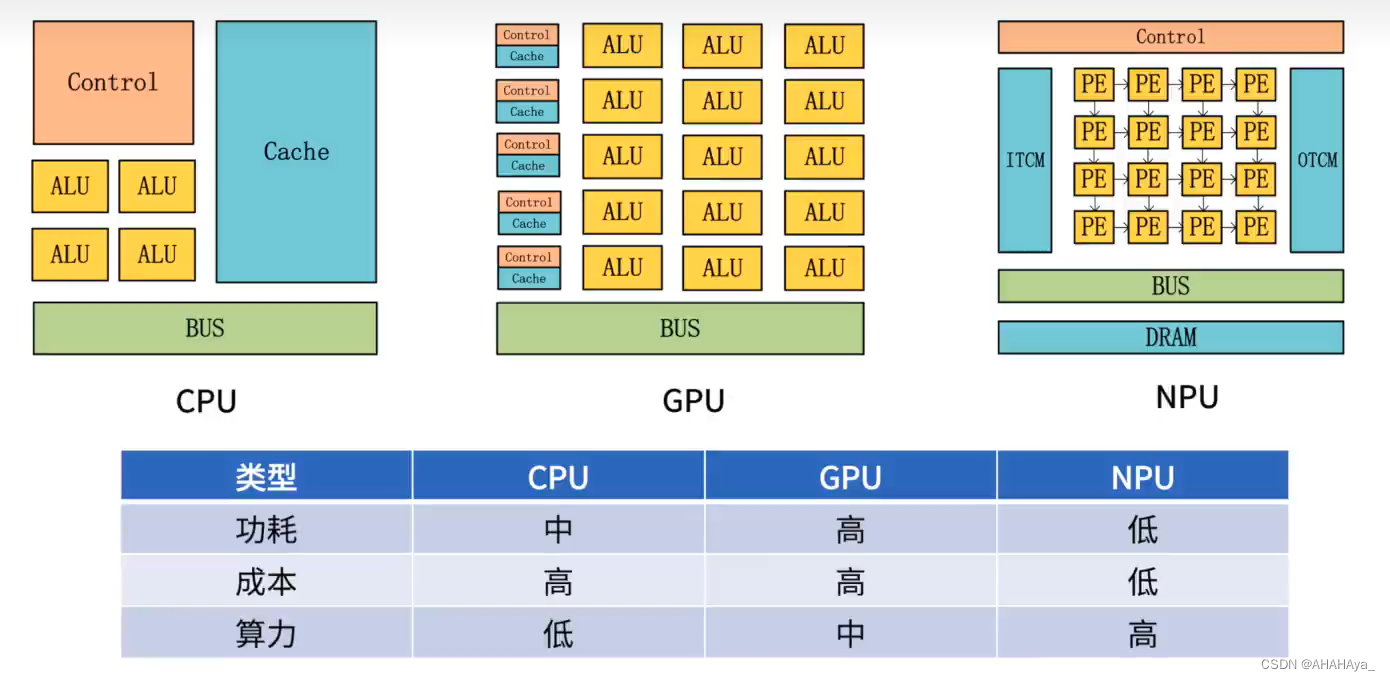
CPU:Central Processing Unit,主要架构包括控制单元,ALU,Cache以及各个单元连接的总线;
GPU:Graphics Processing Unit,主要架构包括大量简单ALU,CU和存储单元,主要用于图像数据的并行计算;
NPU:Neural Network Processing Unit,神经网络处理单元(AI处理器),通过结合深度学习计算的特点,实现存储和计算一体化的架构,从而提高AI任务的运行效率,主要分为终端,云端和边缘端。
DPU: Data Processing Unit ,数据处理器,对CPU的部分工作利用自身算力特长进行加速,且实现了计算的隔离,相比于CPU而言,DPU更擅长基础层应用任务,例如网络协议处理,交换路由计算,加密解密,数据压缩等。
MPU: Microprocessor unit 微处理器
MCU: Microcontroller Unit 微控制单元
MPU注重通过较为强大的运算/处理能力,执行复杂多样的大型程序,通常需要外挂大容量的存储器,例如intel的X86,ARM的一些Cortex-A,飞思卡尔的i.MX6、全志A20、TI AM335X等都属于MPU。而MCU通常运行较为单一的任务,执行对于硬件设备的管理/控制功能。通常不需要很强的运算/处理能力,因此也不需要有大容量的存储器来支撑运行大程序。通常以单片集成的方式在单个芯片内部集成小容量的存储器实现系统的“单片化”,例如51,STM,Cortex-M这些芯片。
TPU: Tensor Processing Unit, 张量处理器。
(1)深度学习的定制化研发:TPU 是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,其实也是一款 ASIC(专用集成电路)。
(2)大规模片上内存:TPU 在芯片上使用了高达 24MB 的局部内存,6MB 的累加器内存以及用于与主控处理器进行对接的内存。
(3)低精度 (8-bit) 计算:TPU 的高性能还来源于对于低运算精度的容忍,TPU 采用了 8-bit 的低精度运算,也就是说每一步操作 TPU 将会需要更少的晶体管。
DSP:是由大规模或超大规模集成电路芯片组成的用来完成数字信号处理任务的处理器。DSP主要用来开发嵌入式的信号处理系统,不强调人机交互,不需要太多通信接口,结构也较为简单,便于开发。

















 3068
3068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









