






作者丨Taki@知乎
来源丨https://zhuanlan.zhihu.com/p/704761512
编辑丨极市平台
导读
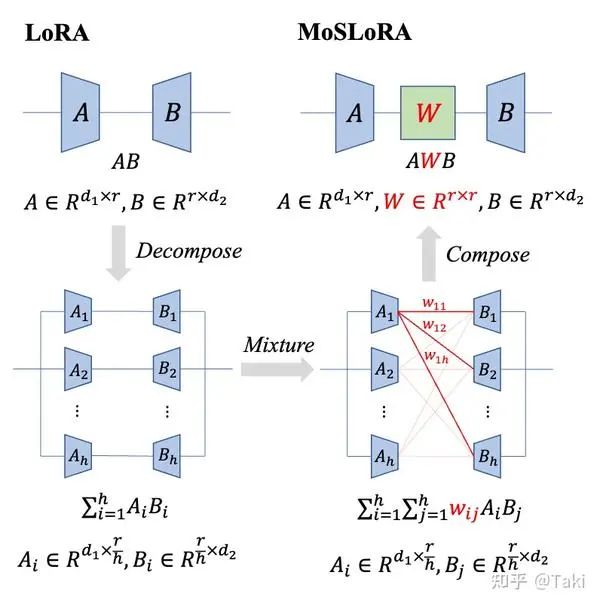
在传统的 LoRA 中加入一个 Mixer 矩阵,进行混个不同子空间的信息。
Nothing will work unless you do. --Maya Angelou
本文主要介绍一篇论文是怎么诞生。
文章的基本信息是:
标题:Mixture-of-Subspaces in Low-Rank Adaptation
链接:
https://arxiv.org/pdf/2406.11909
代码:
https://github.com/wutaiqiang/MoSLoRA
简介:在传统的 LoRA 中加入一个 Mixer 矩阵,进行混个不同子空间的信息。设计非常简单:
最初的想法
说来也是巧合,之前有很多的文章尝试将 LoRA 和 MoE 结合起来,他们基本上都是把 LoRA 当做 MoE 的 Expert,然后塞到 MoE 结构之中,之前也介绍过一些,如文章 https://zhuanlan.zhihu.com/p/676782109、 https://zhuanlan.zhihu.com/p/676557458、 https://zhuanlan.zhihu.com/p/676268097、https://zhuanlan.zhihu.com/p/675186369。这些文章无疑都是将 LoRA 看作 MoE 的 expert,一来缺乏动机,二来影响了 LoRA 的可合并性,三来 训练还慢。
闲来与同事聊天,同事说没见过有文章把 MoE 塞到 LoRA 里面,我当时愣了一下。啊?MoE 塞到 LoRA 里面,意思是说把 MoE 的那种 gate+多专家去做 LoRA 的 lora_A 和 lora_B ?
最直观的设计就是:
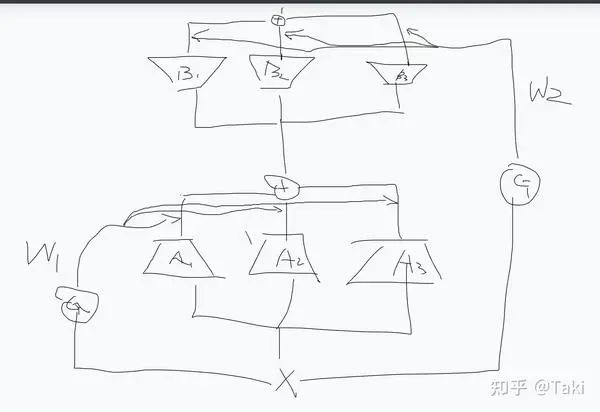
有点抽象,但稍微知道点 MoE 和 LoRA 的应该都能懂
其实想出这种设计还是很直接的,毕竟 lora 和 MoE 都是很成熟,很简单的设计。
先不谈有没有动机,反正水文章嘛,都能找到点。就说这个设计,其实有点不合适,为什么呢?
核心就在于 Gate 这玩意,MoE 是希望尽可能训多点参数但计算量不要大太多,因此整了多个Expert 选用一部分并设计了 Gate Router 的机制。但是,LoRA 本身参数量就不大,且rank 大又不一定效果好,堆这个参数属实没必要。此外,LoRA 的好处就在于可以 Merge 回原来的权重,infer 的时候 0 延迟。这个Router Gate 因为和输入 x 耦合,因此没法 merge 回去了。这就带来了推理延迟。
去掉Gate,直接上
有了上面的分析,下一步自然就是要去掉 Gate 了。为了确保能合并,因此所有的 expert 都得用,此时就变成了:
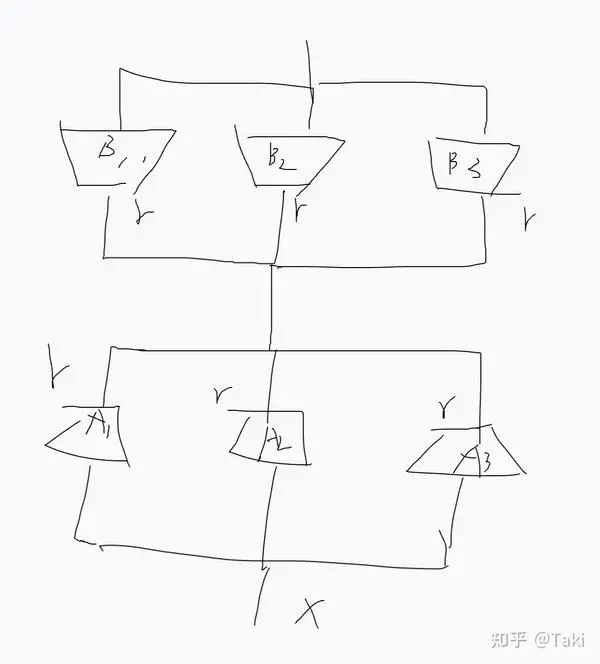
仿佛在拼积木
有了这个设计以后,同时又出现了一些 concern:虽然说 infer 的时候,大家都可以合并到原始权重,都是 0 延迟。但是训练的时候,比如我这个图画的,训的参数是之前的 3 倍多。(在当今这个大环境下,怕是要被审稿人喷)
所以说,要说公平,那就不能设置为 r,每个模块还是得设置成r/k,上图的 case 对应的就是 r/3,这样训练的参数没变,同时 infer 都是 0 延迟。
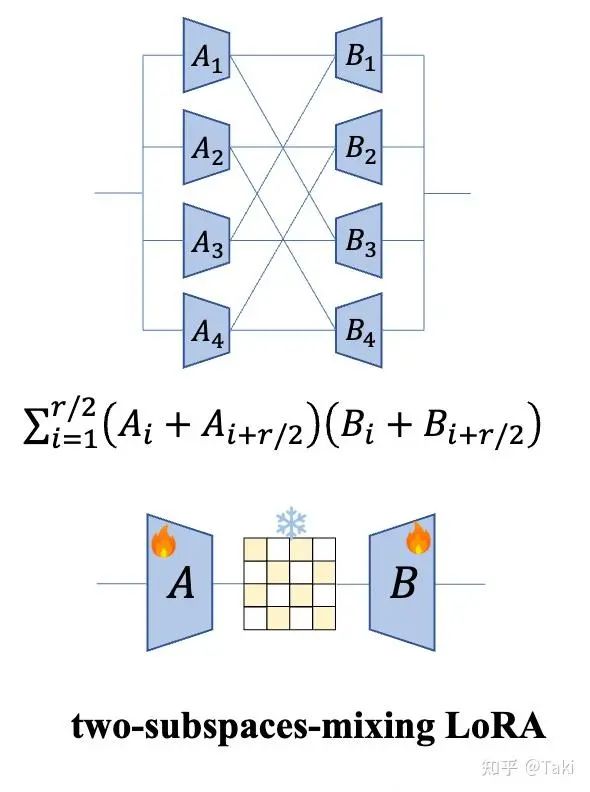
这也就是论文里面的two-subspace-mixing 的方法的由来。
'多头注意力'的视角
既然把每个专家设置成了 r/k 的大小,这玩意就很像是多头注意力了,有 维度切分+并行操作+最后合并 的操作。这不禁让我思考,这和多头注意力有什么关系?原始的 LoRA 能不能等价拆开?
说到拆开,有两个量可以拆,一个是 rank,一个是输入的维度 d。若是直接说多头,可能大家想到的都是直接把 d 拆开,而不是把 rank拆开。那么这两种拆开我们都可以分析:
i) 把 d 拆开的视角 :
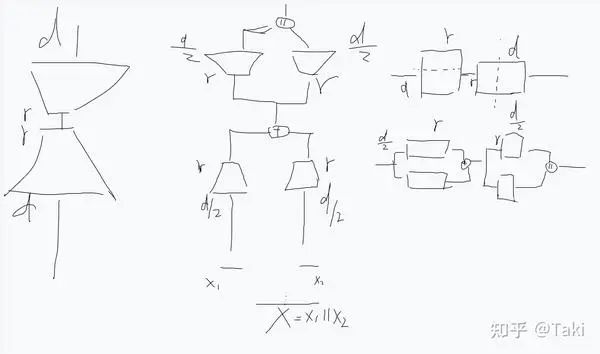
一如既往的抽象,熟悉矩阵运算的应该能一眼看明白
图中展示的是 d拆分2 个 d/2 的 case,为了好理解,我刻意画了矩阵视角。从矩阵运算角度来看,在 d 维度 切分以后,相当于过了两个 A,求和,然后再过两个 B,最后拼接在一起。这三个视角都是等价的。
说实话,要说改进这个,真就没啥好改的。
ii) 把 r 拆开的视角 :
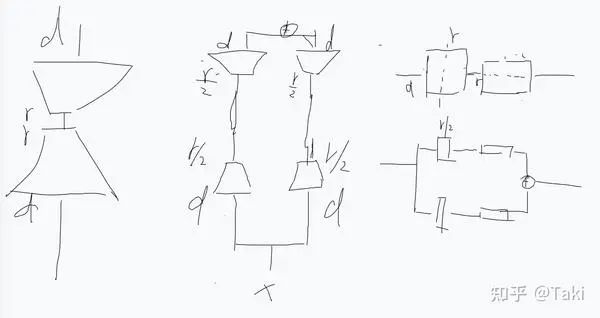
这个视角去看,就挺好的,也比较简介
类似地,也可以将 rank 去拆开。上图展示了将 rank 拆开成两个子块的过程。可以看出,等价于两条支路,每个支路 rank=r/2,最后求和。明显比上面的拆分 d 的方法更优雅。
在这个视角下,一个很简单的改进,就呼之欲出了:

思路很简单的,其实就是将中间的平行支路扭在一起,从公式的角度来看,从A1B1+A2B2 变成了 (A1+A2)(B1+B2)=A1B1+A2B2+A1B2+A2B1.
这么来,相当于多了两项。暂且称这个为扭麻花方案吧。
阶段性结果,但还不够
有了上面的分析,那么就开始做实验了:
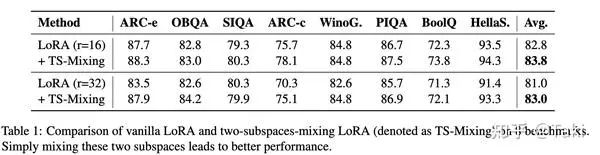
微调 LLaMA3做 commonsense reasoning,发现还是有提高的。
不过,这么做还有个问题,那就是 代码效率其实不高。划几条并行的线然后扭个麻花很简单,但是实现起来得看怎么去实现。我初始化了两个 expert 依次去 forward,因此计算效率不高。当然,也可以学习 MHA 的代码,先整个 infer,然后再拆分向量(相当于 A1和A2两个线性层拼在一起 forward,得到结果后再将向量拆开)。
这就启发了另外一个思考,也就是说,这一通操作有很多的线性层的拆分与合并操作,我们之前的分析都是从 linear 层的拆分合并去考虑的,没有考虑向量的拆分合并操作。向量角度等价于:
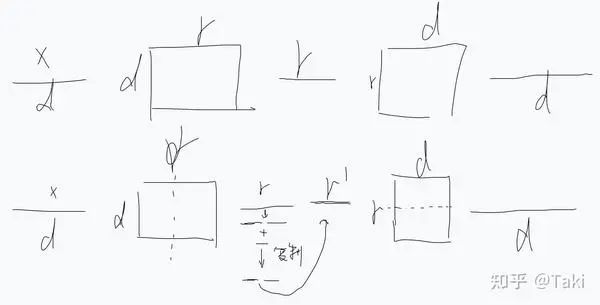
核心在于中间的 r 向量进行一系列操作(切分,求和,复制)
之前提到的扭麻花操作,等价于中间的 r维度的向量,拆分,逐位相加成一半长度,然后复制,再拼接,获得最终的r'。从这个视角去看,这种多 expert 的扭麻花本质就是在 r 维的向量上加一套组合拳。
混合矩阵的引入
既然是加一套组合拳,这个组合拳 (r维度的向量,拆分,逐位相加成一半长度,然后复制,再拼接)用矩阵来看,是什么呢?
一番分析下来,不难得到相当于中间加了一个固定的蝴蝶矩阵因子(关于蝴蝶矩阵因子,可以参考:https://weld.stanford.edu/2019/06/13/butterfly/ )。
既然如此,那么有没有可能模仿 Tri Dao 的做法, 引入一堆蝴蝶矩阵因子?想想还是没啥必要,因为lora 本身计算量不大,无需这样的拆分,其次就是延迟可能变大很多 (此外,调研发现,蝴蝶矩阵序列在 OFT 系列里面是有应用的,也就是 BOFT)。
不往蝴蝶矩阵序列走,另外一个直观的想法就是把这个矩阵升级为可学习的矩阵了。我在论文中把这个矩阵称为 Mixer 矩阵,那么:
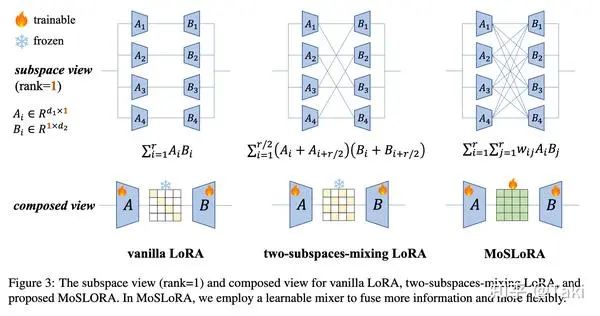
原始的 LoRA 相当于使用固定的单位矩阵 做 Mixer,中间的扭麻花方案相当于插入固定的蝴蝶因子矩阵做 Mixer,论文里升级为可学习的 Mixer,且矩阵全部元素可学习,也就是所提出的MoSLoRA方法。
注1:这种形式和 AdaLoRA 还是蛮像的,不过 AdaLoRA 中间是一个 SVD 分解的特征值,且前后矩阵都加上了正交化约束。
注2:我在写论文的时候,发现了 Arxiv 有个优秀的同期工作 FLoRA: Low-Rank Core Space for N-dimension,他们的论文是从 Tucker 分解的角度去切入的,思路很巧妙,也很优雅,感兴趣的也可以看看他们文章和解读。
回到MoE的视角
回到 MoE 的视角去看,也就是回到论文最开始的图:

我们可以简单地将 Mixer 理解为 MoE 的 Gate 生成的 weight,此外这个 Gate有几个特性:
-
这个 weight 和输入无关,进而确保可合并性
-
这个 weight 是稠密的,意思是所有的 expert 都用上,而不是 MoE 的那种选取 top-k
-
原始的 vanilla LoRA 可以看作是 这个 Mixer 矩阵固定为单位矩阵。
看到这,还可以看明白另外一件事,也就是:
【多个并行的LoRA分支 选 top-k个输出 最后求和】 这种常规 LoRA+MoE 设计,本质上相当于 Mixer 具备:i)每行都是同一个元素 ii)部分行全行为 0 iii) 非 0 行的元素由输入来确定 iv) 不可合并 这些性质或者特点。
后记
写到这里,其实也把整个思维的推进过程都说清楚了。当然,论文不可能这么写,太冗长且难以理解。知乎上尚且没几个人有耐心看完,更别说审稿人了。不过整个的思考过程还是收获很多的,可能一个东西刚开始想的时候复杂,换个角度以后,竟然会如此简单。
2024/07/06 补充证明
这点也正如@dt3t的评论,直觉上来说,中间插一个 W,如果把 AW 合并看作 A',那岂不是和直接学 A‘B 效果是一样的?
其实,并不是一回事,就算是初始化等价,不代表后续优化的路径是一致的。正如重参数化,虽然看起来是等价的,但是学的结果就是不一样。这个角度去看,Mixer 也可以看作是重参数化分支的形式:

其中 I 是固定的不学习的矩阵。这样就相当于原始 LoRA的旁边加了一个并行分支,和 RegVGG等重参数化一致了。
当然,这里也给出一个【后续优化的路径是不一致的】的简单证明:
https://github.com/wutaiqiang/MoSLoRA/blob/main/MoSLoRA_proof.pdf
也可以直接看图:

只有当 W 是固定的正交矩阵 ,才是等价的,不然就算初始化一致,优化过程也会有差异。
在 MoSLoRA 中,W 是可学习的,且我们分析了初始化对结果的影响。















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









