






作为一名资深NLP算法工程师,大模型在日常工作中扮演了非常重要的角色,辅助处理很多工作。但是,大模型的使用非常麻烦:
-
主流大模型通过网页对话方式交互,手工输入Promt,通过对话的方式获取结果,长度有限且非常不方便。
-
资源有限,市面上很少大模型API资源可供使用,并且都是收费的。
今天一位从事大模型的老同学跟我说:“智谱AI BigModel开放平台的GLM-4-Flash大模型含API全部免费开放了,支持处理高达128K上下文,主要支持个人使用,每个新用户免费支持2个并发。”
这简直是打工人狂喜,更让我震惊的是“这次活动还开放了GLM-4-Flash免费微调活动,开放2000名500万token的免费训练资源;可以微调的GLM-4-Flash模型权重下载本地,部署到其他平台”。我赶紧上BigModel开放平台搜索GLM-4-Flash模型及其使用方式。
GLM-4-Flash是什么
GLM-4-Flash采用了10TB的高质量多语言训练数据和FP8技术加速模型训练,海量数据、高效训练加之小体量赋予GLM-4-Flash功能强大,主要体现在:
-
强大基础能力:GLM-4-Flash基于智谱最新GLM-4训练的极速大语言模型。
2. 推理性能强:支持最大128K的上下文推理和多语言处理能力。
3. 极速推理:生成速度72.14token/s,约等于115字符/s。
GLM-4-Flash可以用于智能对话助手、辅助论文翻译、ppt及会议内容生产、网页智能搜索、数据生成和抽取、网页解析、智能规划和决策、辅助科研等丰富场景。
GLM-4-Flash体验
对于NLP码农而言,大模型可以用于日常数据抽取,如实体识别、关键词抽取等构造训练数据,英语文献辅助阅读,脚本及模型代码生成,模型优化建议等等。下面我将选择几个日常任务,使用GLM-4-Flash网页端和Python API分别体验下效果。
任务1:学术论文翻译

任务2:编码能力:C语言实现Transformer的网络结构。
任务3:模型优化:对transformer网络结构进行优化,并给出c代码实现。
任务4:信息抽取:

网页端使用
BigModel开放平台提供网页端体验地址:https://open.bigmodel.cn/console/trialcenter?modelCode=glm-4-flash
通过对话的方式,直接输入指令获取结果,测试结果如下方视频。
,时长01:27
从网页端体验结果看,GLM-4-Flash模型响应速度非常快,刚输出指令就开始生成结果。英文翻译结果的质量非常高。代码生成能力这块非常强,先介绍了Transformer结构,然后分模块想写给出了模型网络结构的c语言实现结果;对网络结构也给出了常见优化方式,并选择其一给出了详细结构实现,对于日常工作中模型代码开发非常具有启发意义。
Python API调用
BigModel开放平台所有模型都提供了API的调用方式,仅需1行代码就可以完成对模型的调用,非常方便。
我这里调用的代码如下:
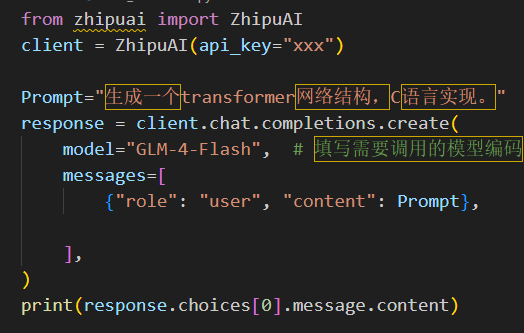
api_key替换成自己的,对应的Prompt替换成对应的指令就可以了,API调用的结果如下视频:
,时长00:49
从上视频可以看到,API的调用非常方便,反应速度非常快,效果和网页端结果是对齐的,可以方便将模型嵌入各种后台开发系统中,整体体验非常顺滑。
GLM-4-Flash微调“NLP算法助手”大模型
大模型微调非常重要,本次活动还开放了GLM-4-Flash微调活动,我也尝试微调了一个“NLP算法助手”发模型。大模型使用过程中,经常需要加入企业独有的场景数据,对平台的基础模型进行微调。微调模型可以快速得到符合业务场景需求的专属大模型,相比训练新模型高效且低成本。
但本地化微调非常麻烦,因为:
1、环境复杂:需要配置负责的开发环境,安装一些列开发包和插件。
2、成本高:大模型都比较大,模型下载、预训练和部署对网速和机器内存和计算资源要求较高。
3、预训练和部署代码开发复杂:预训微调和和部署时数据预处理、加载、调参、预训练、模型评估、模型加载保存等代码开发。
BigModel开放的GLM-4-Flash微调非常简单,仅需3步,无需额外代码开发,无需额外环境配置,即可完成模型微调和部署,体验非常好。浏览器打开BigModel微调的页面:https://open.bigmodel.cn/console/modelft/finetuning,模型微调分为3步:准备训练数据、创建微调任务、使用微调模型。支持LoRA少量参数微调和全参微调两种方式,官方给出了详细的模型微调使用指南:https://open.bigmodel.cn/dev/howuse/finetuning。
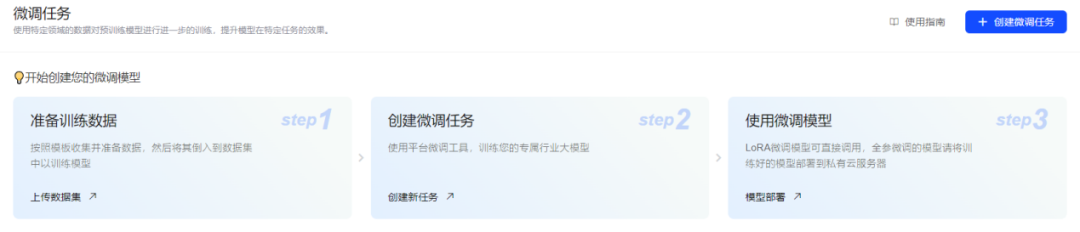
1. 创建数据集
点击页面“上传数据集”跳转到训练数据上传页面。
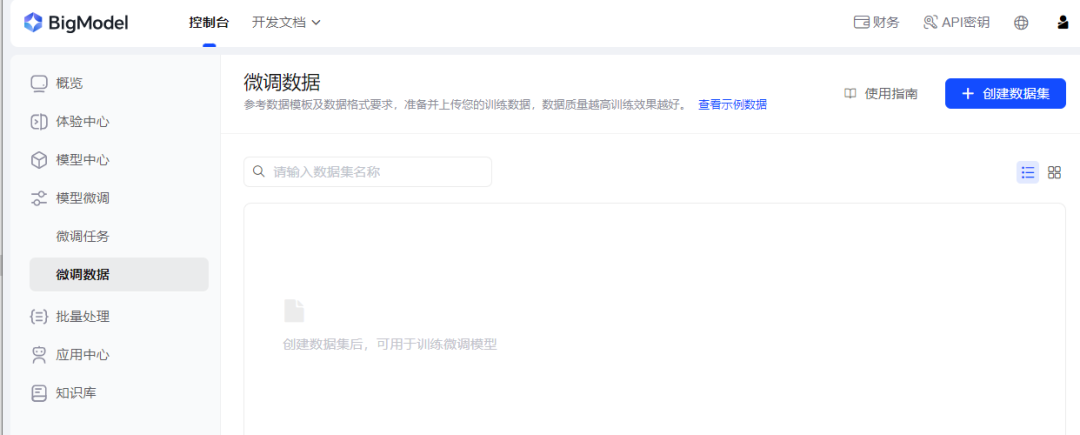
点击右上角的“创建数据集”按钮,上传处理成指定格式的数据集,格式可参考官方文档,离线处理成指定jsonl格式。我这里创建NLP领域知识数据格式如下,保存train.jsonl:

跳转到数据创建页面,添加数据描述,点击上传本地处理好的训练数据。
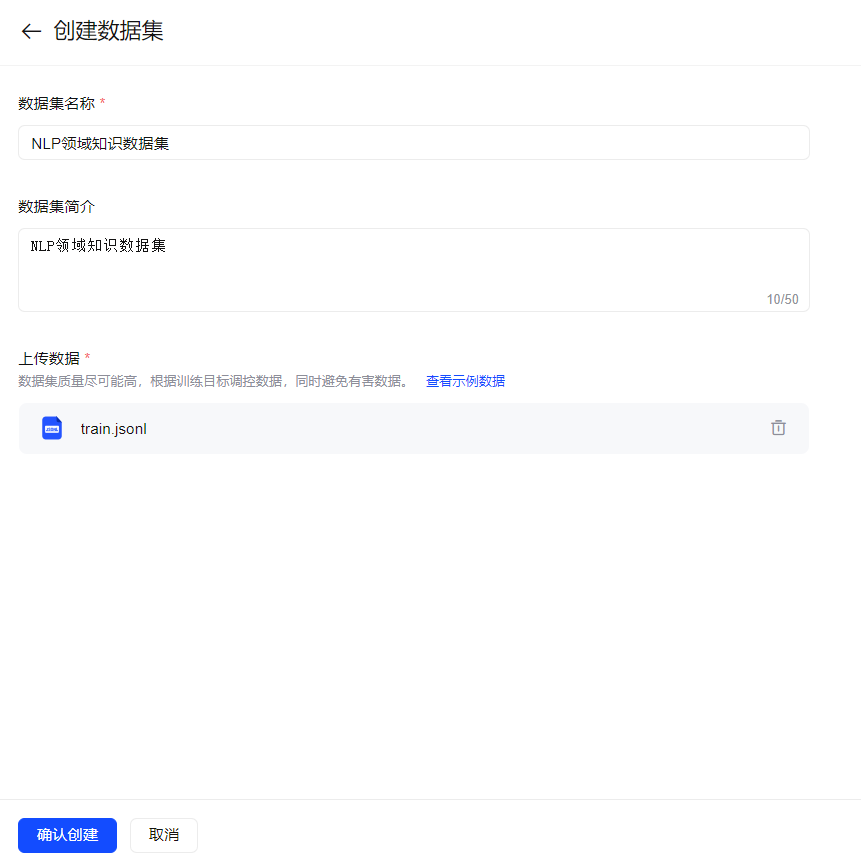
点击“确认创建”就完成了。

2. 创建微调任务
完成数据集创建之后,点击左侧“创建任务”回到任务微调主界面,点击step-2创建新任务。
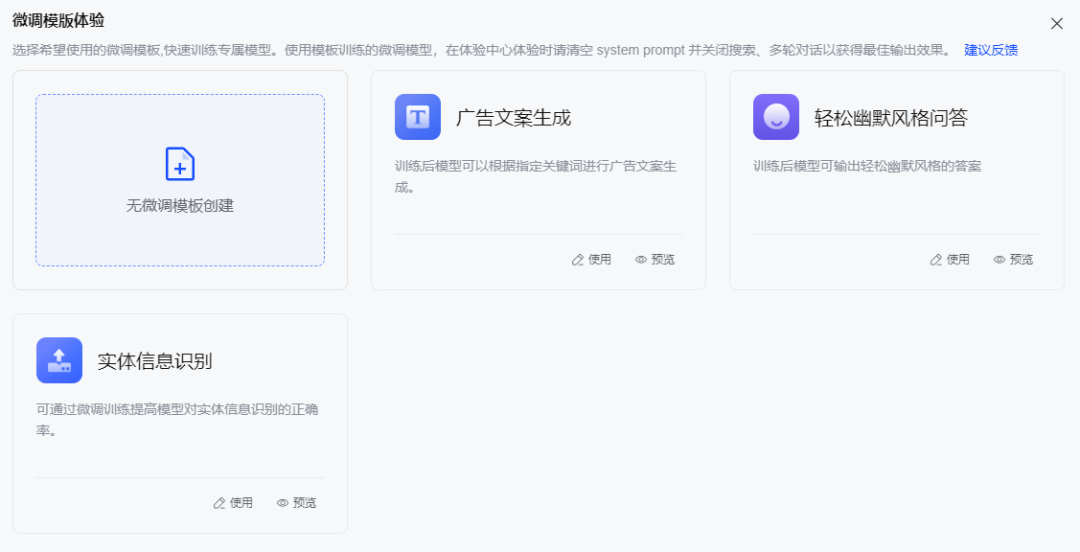
选择无模板微调,跳转到微调任务配置界面。
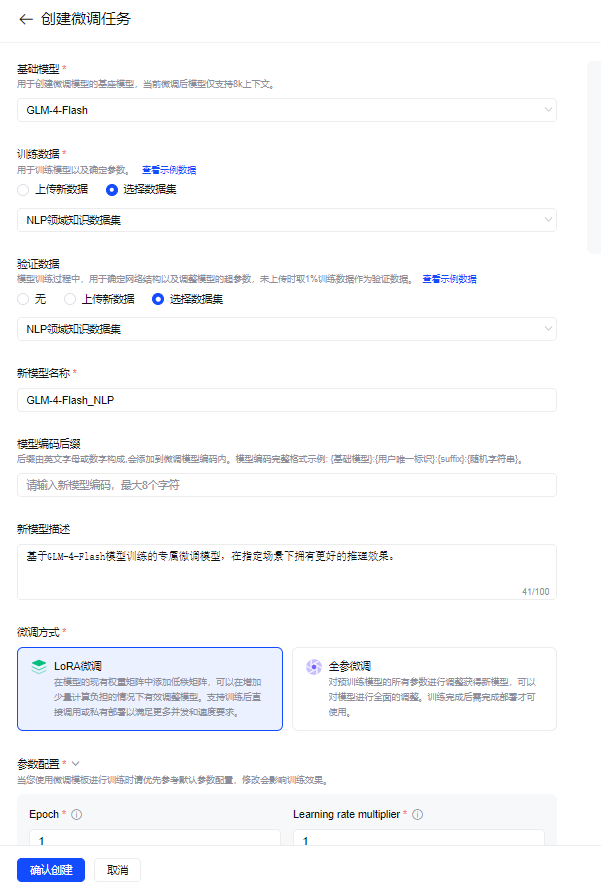
选择需要微调的模型GLM-4-Flash,选择刚刚上传的NLP领域数据集,配置好新模型的名字和描述;根据需求选择微调的方式以及对应超惨配置,点击“确认创建”就完成微调任务创建。界面会自动跳转到模型微调的界面,如下图:

可以看到模型微调的状态以及预计训练完成的时间,只需等待一段时间模型训练完成。单击任务跳转到任务训练详情页。
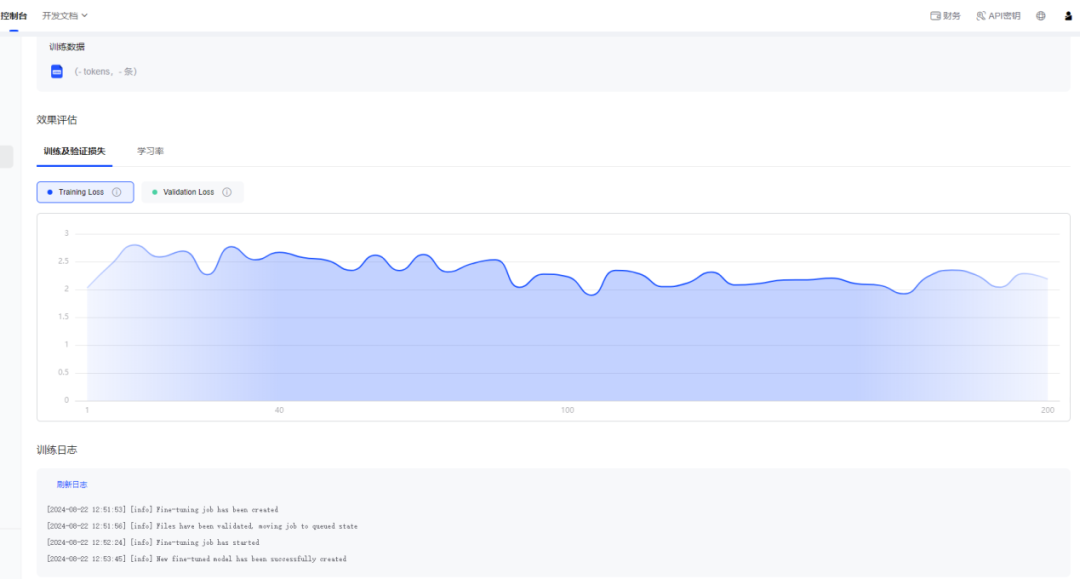
可以看到模型微调具体日志,训练及验证的loss和学习率等数据。
3. 模型部署
在微调任务界面,点击任务末尾的三个“...”号
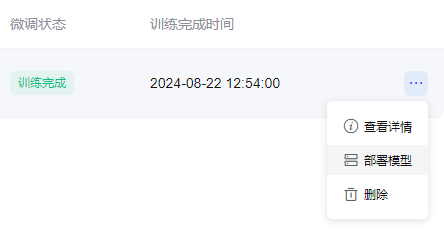
点击“部署模型”跳转到模型部署配置页面。
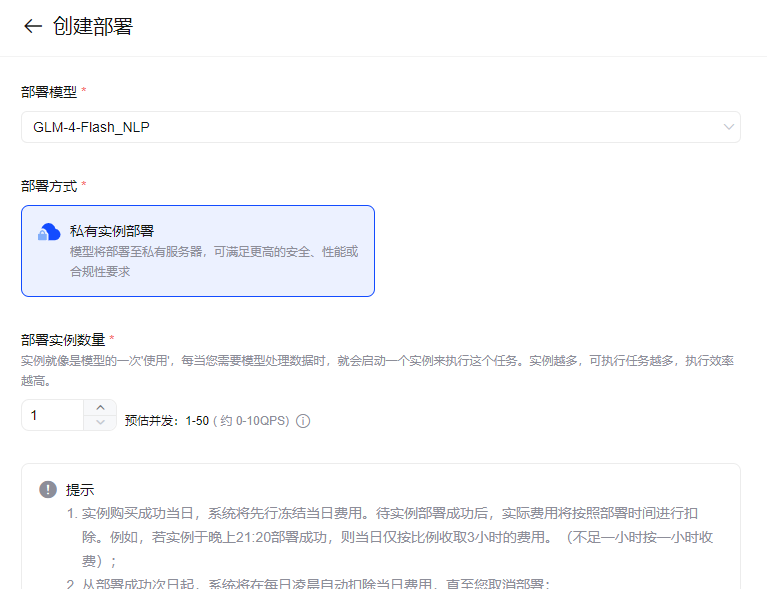
选择模型业绩并发数,点击“确认创建”就完成了模型部署了。部署成功后将生成新的私有部署后微调模型卡片,您可以在「模型广场」卡片内或在「私有实例」页面详情页查看模型编码进行调用。
部署完整之后,就可以通过API请求私有模型了,如下:
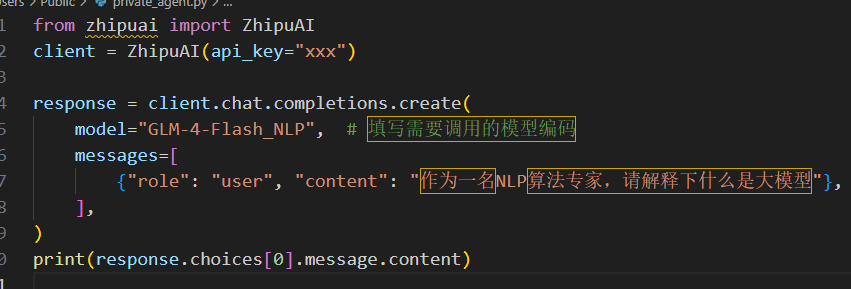
填写自己私有的api_key,将模型名字替换成私有模型名就可以了,cmd环境执行代码获取结果。

通过api的方式,可以方便将私有大模型嵌入到各种应用场景。
使用GLM-4-Flash微调和部署自己的专属大模型,省去很多开发和部署的时间,可以空出更多的时间优化业务的数据,提升预训练模型的效果,加速自己的业务产出以获得更高业务回报。
最后附上GLM-4-Flash免费API获取链接:点击“阅读原文”或链接https://zhipuaishengchan.datasink.sensorsdata.cn/t/fA

















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









