








文章链接:https://arxiv.org/pdf/2406.15305
代码地址:https://github.com/PKU-ML/Diffusion-PID-Protection
亮点直击
- 本文在实证观察中发现,保护阶段和利用阶段之间的提示不匹配可能会削弱当前数据保护算法的有效性。
- 本文深入探讨了利用LDMs中的视觉编码器实现更强大数据保护的可能性,并提出了一种名为PID的新算法。
- 通过广泛的验证,本文展示了PID对不同训练算法、数据集和自适应攻击的有效性。
最近,对潜在扩散模型(LDMs)进行少样本微调使其能够从少量图像中掌握新概念。然而,考虑到在线上可获得的大量个人图像,这种能力引发了对隐私的重要关注。虽然先前已开发了几种防御方法来防止LDMs的滥用,但它们通常假设数据保护者使用的文本提示与数据剥削者完全相匹配。在本文中,首先通过实证方法证明,打破这一假设,即在数据保护者和数据剥削者之间存在文本条件的差异情况下,这些防御方法的有效性可能会大幅降低。此外,考虑到视觉编码器独立于文本提示的特性,本文深入研究了如何通过操纵视觉编码器来影响LDMs的少样本微调过程。基于这些见解,本文提出了一种简单而有效的方法,名为Prompt-Independent Defense(PID),用于保护免受LDMs的侵害。本文展示了PID可以单独作为强大的隐私屏障,同时需要显著较少的计算资源。本文的研究以及全面的理解和新的防御方法,为可靠地对抗LDMs的数据保护迈出了重要的一步。
本文提出以下研究问题(RQs):
- 问题1:保护阶段和滥用阶段使用的提示不匹配是否会影响现有防御算法的有效性?
- 问题2:像素空间中的扰动如何影响LDMs中视觉编码器的输出,从而影响微调过程?
- 问题3:如果问题1的答案是肯定的,我们能否通过更好地利用独立于提示的视觉编码器来提升保护的鲁棒性?
本文首先研究了在提示不匹配情况下当前防御方法的鲁棒性。为了模拟恶意环境,其中滥用者有意设计文本提示来破坏防御,本文定义了一组候选提示,标记为 c p r o t c_{prot} cprot,供滥用者在微调潜力扩散模型时选择。本文从CelebA-HQ数据集中随机选择一个个体,并使用ASPL算法及其推荐的超参数对其图像进行保护。在保护阶段,本文将文本提示固定为“一张sks人的照片”(表示为 c p r o t c_{prot} cprot)。随后,分别使用Stable Diffusion v1.5与DreamBooth 在每个恶意候选提示( c e x p l o c_{explo} cexplo)的条件下进行微调。最后,本文使用微调过的模型生成图像,并展示了部分生成图像如下图1a所示。对于 c prot ≠ c explo c_{\text{prot}} \neq c_{\text{explo}} cprot=cexplo 的情况,显示的图像来自候选模型中视觉效果最佳的模型。观察到,提示依赖型防御在面对有意多样化的提示时,其保护性能显著降低。本文假设这种退化是由于扰动与文本条件之间的纠缠所致。针对上述观察结果的深刻关注,深入探讨了LDMs中的潜空间,并充分调查了利用视觉编码器构建更具抗变提示性的数据保护的可能性。基于本文的发现,提出了一种新的防御方法系列,名为独立于提示的防御(PID)。PID完全独立于文本提示,显示出对多样化微调提示的鲁棒性,如下图1b中定性展示的,并在后面章节中定量展示。
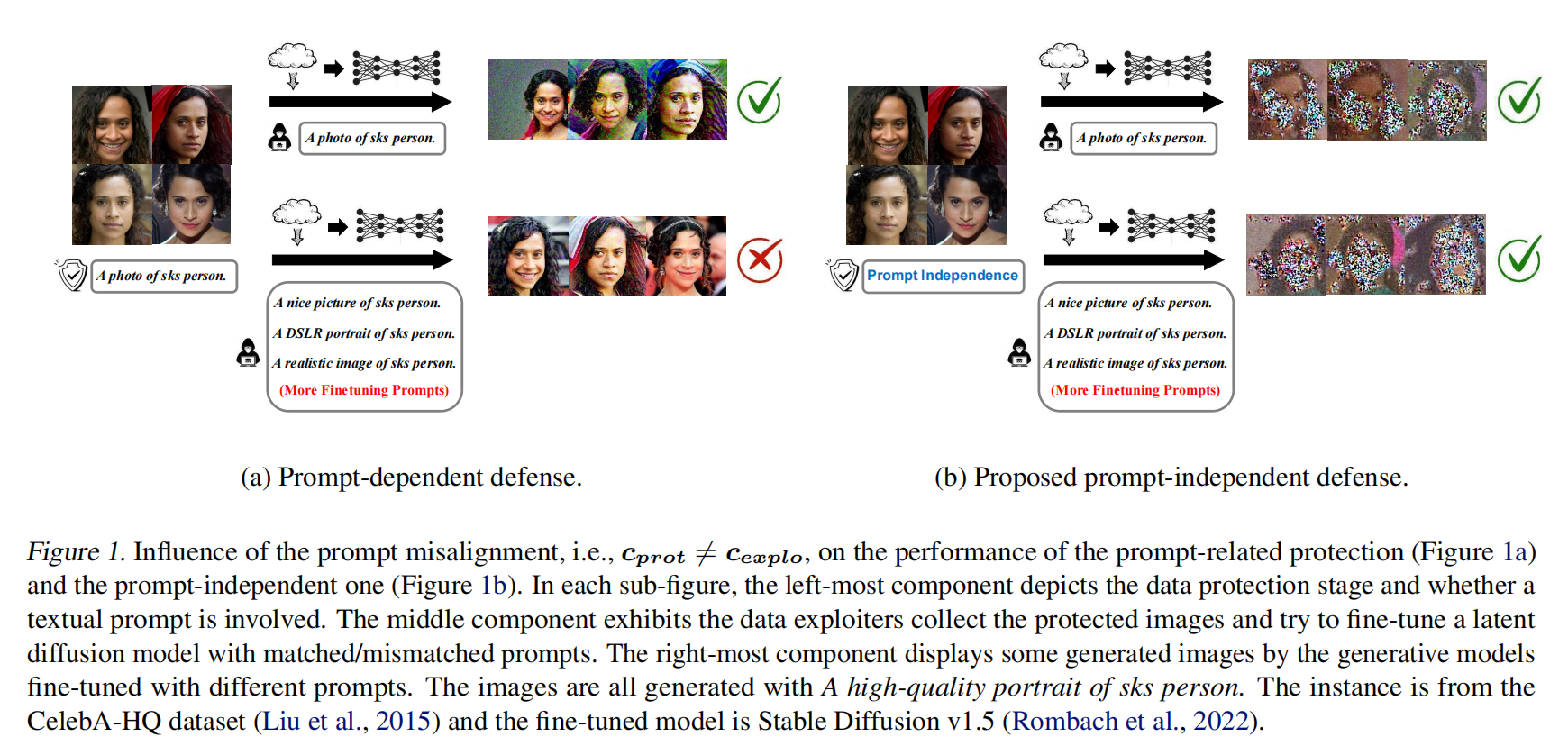
文本提示相关的防御对变化的提示是否具有鲁棒性?
在这一部分,本文对与不同提示面对的变化提示的相关防御进行了定量评估。
数据与模型:本文的实验主要使用CelebA-HQ 数据集,随机选择了10位名人,并为每位名人选择了4张图片。本文使用Stable Diffusion v1.5 作为默认模型,DreamBooth 作为默认的微调方法。
防御方法:本文考虑了Van Le等人提出的FSGM和ASPL方法,它们的目标完全与文本提示相关。扰动预算设置为0.05,并且在本文中扰动后的图片以PNG格式保存,除非另有说明。
度量标准:本文使用两个度量标准来衡量生成的图像与训练图像之间的相似性:人脸检测分数(FDS)和Fréchet Inception Distance(FID)。此外,本文还使用两个度量标准评估图像质量:图像质量分数(IQS)和盲/无参考图像空间质量评估器(BRISQUE)。本文使用↑(数值增加)和↓(数值减少)表示更好的保护效果的方向,例如,较大的FID表示生成图像与训练图像的分布之间存在更大的距离,表明生成的图像未能很好地捕捉训练数据,从而保护了训练数据的隐私。
结果:针对每位名人选择的4张图像,本文采用了FSGM和ASPL防御方法,并使用保护提示 c prot c_{\text{prot}} cprot生成相应的受保护版本。这些受保护的图像随后用于使用微调提示 c explo c_{\text{explo}} cexplo微调模型,从而生成不同的微调模型。在测试阶段,本文使用任意提示生成一组图像,并使用上述四个指标对其进行评估。跨不同微调模型的平均结果显示在下图2中。可以看到,当保护提示与微调提示不匹配时,保护性能明显受到影响。例如,在FSGM方法中,当微调提示与保护提示不匹配时,FDS指标增加了超过35%(从0.277增加到0.387),而FID指标减少了30%(从307.421降低到203.916)。其他指标和方法的情况也是一致的。深感关切的是,本文观察到破坏数据保护者所做的提示一致性假设,可能使数据探测者能够生成高质量的模拟图像,即使在某种程度上对数据进行了保护。因此,本文旨在设计一种无关提示的防御方法,以应对这一问题。

扰动视觉编码器会影响微调过程吗?
回想一下,潜在分布是通过基于KL散度的变分自编码器(VAE)建模为多项式高斯分布, N ( μ ϵ ( x ) , σ ϵ 2 ( x ) ) N(\mu_\epsilon(x), \sigma^2_\epsilon(x)) N(μϵ(x),σϵ2(x)),这是与提示无关的。这个属性可以用来解决在提示不匹配时防御性能下降的问题。在深入探讨这个潜在的解决方案之前,本文首先研究了潜在分布的变化,即均值 μ ϵ ( x ) \mu_\epsilon(x) μϵ(x) 和方差 σ ϵ 2 ( x ) \sigma^2_\epsilon(x) σϵ2(x) ,对微调的影响。
L mean L_\text{mean} Lmean 用于最大化扰动图像均值与原始图像之间的距离,而 L var L_\text{var} Lvar 则用于最大化两个分布方差之间的距离。具体而言, L mean L_\text{mean} Lmean 和 L var L_\text{var} Lvar 定义如下:
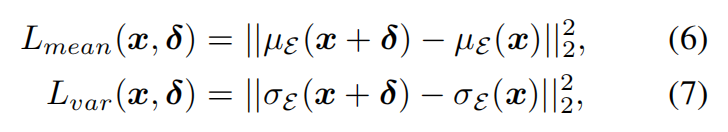
其中 δ \delta δ 表示添加的扰动,使用 ℓ ∞ -PGD1000 \ell_\infty\text{-PGD1000} ℓ∞-PGD1000 最大化上述损失函数。 δ \delta δ 受到 ∥ δ ∥ ∞ ≤ ϵ = 0.05 \| \delta \|_\infty \leq \epsilon = 0.05 ∥δ∥∞≤ϵ=0.05 的限制。然后,本文对通过优化上述两个目标得到的图像进行微调,并使用上面相同的评估框架评估微调后的模型。
下表1中呈现的结果表明,显著重塑潜在分布确实对微调产生了重大影响。为了直观展示扭曲的潜在分布对结果的影响,本文使用视觉解码器解码在优化过程中从分布中采样的表示 z,并在下图3中显示解码后的图像。结合表1的结果和图3,本文发现大的均值差异主要影响输出图像的质地,使其看起来覆盖有大量噪声(低IQS和高BRISQUE)。相反,大的方差显著阻止模型理解图像的核心概念(低FDS和高FID)。
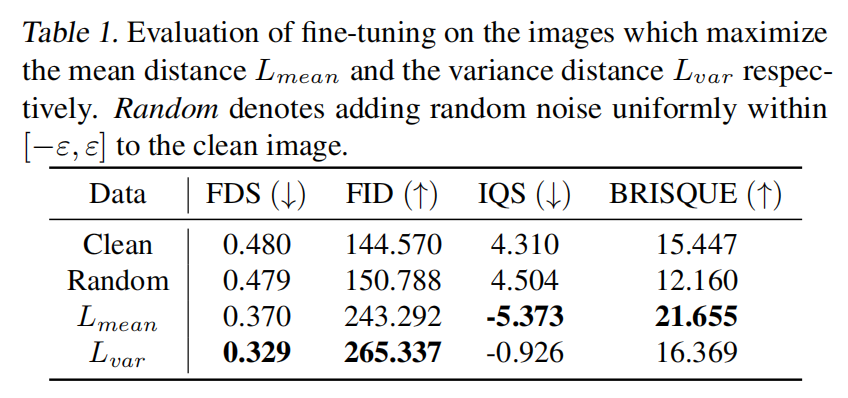

最后,如下图4所示,本文绘制了均值差异和方差差异的 ℓ 2 \ell_2 ℓ2 范数,揭示了即使在像素空间中添加的小扰动(0.05),也可以显著改变潜在分布。方差的变化如此剧烈,以至于干净图像和扰动图像之间的方差差距范围从约 $ 2^{-15} \sim 2^{12}$。此外,本文观察到均值变化和方差变化并不完全相关。无论是在图4a还是图4b中,一个经历了显著波动,而另一个则没有显著变化,这表明它们对微调结果的影响是不同的。
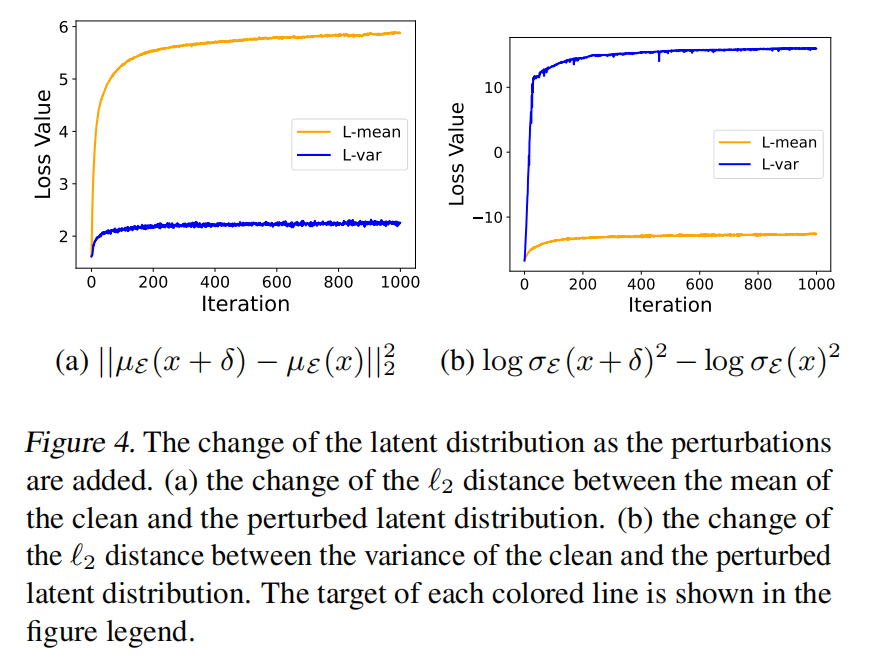
总体而言,通过在像素空间引入扰动,本文可以操控潜在分布的这两个统计量,从而显著影响微调结果的不同方面。
如何更好地利用视觉编码器进行数据保护?
扰动潜在分布显著影响微调过程,而这种潜在分布是与提示无关的。因此,在本节中,本文旨在利用视觉编码器实现一种有效的独立于提示的防御机制。
Proposed Prompt-Independent Defense
根据前面表1的结果,可以知道影响均值和方差会对学习过程的不同方面产生影响。观察上图4发现仅改变其中一个统计量不足以同时在两者中引起显著变化。这一观察促使本文探索通过设计一个复杂的目标来更有效地操纵潜在分布的可能性,充分利用影响均值和方差的好处。
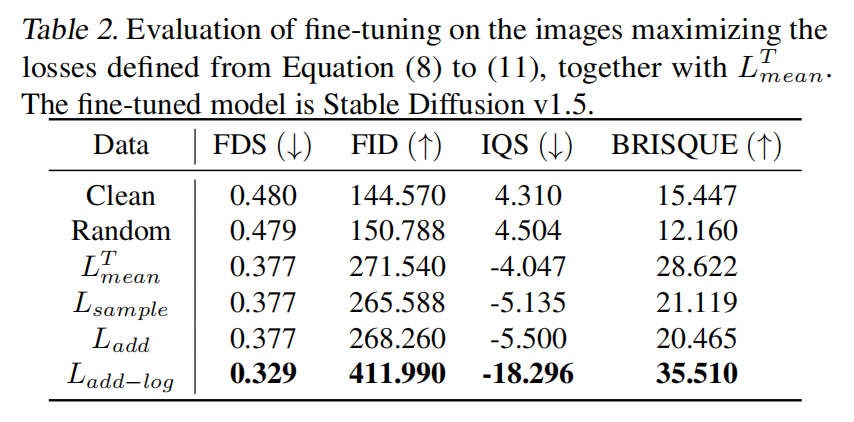
本文首先尝试干扰从潜在分布中抽样的表示 z = E ( x , ϵ ) z=E(x, \epsilon) z=E(x,ϵ),这导致了损失函数 L sample L_\text{sample} Lsample 的应用,这也是Liang所使用的。为了减少优化过程中不必要的随机性,接着尝试在 L sample L_\text{sample} Lsample 中排除 ϵ \epsilon ϵ,得到了损失函数 L add L_\text{add} Ladd。考虑到在上图4中观察到的均值和方差的显著差异,本文提出了 L add-log L_\text{add-log} Ladd-log,它联合优化了方差的对数和均值。此外,本文探索了对均值 x target x_\text{target} xtarget 的有针对性操作,这类似于Liang和Wu 所做的工作,其中目标是他们论文中指定的默认图像。本文将这种损失称为 L mean T L^T_\text{mean} LmeanT。
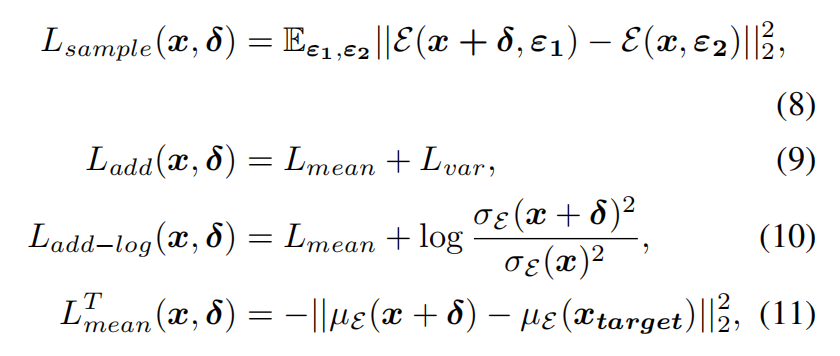
本文接着评估上述提出的防御目标对潜在分布的影响,如下图5所示。值得注意的是, L add-log L_\text{add-log} Ladd-log(图5a和图5b中的紫色线)是唯一能显著偏离其正常值的防御目标,均值的平均 ℓ 2 \ell_2 ℓ2 距离为3.5,方差为0.06。相比之下, L sample L_\text{sample} Lsample 和 L add L_\text{add} Ladd 在扰动方差方面表现明显较差。
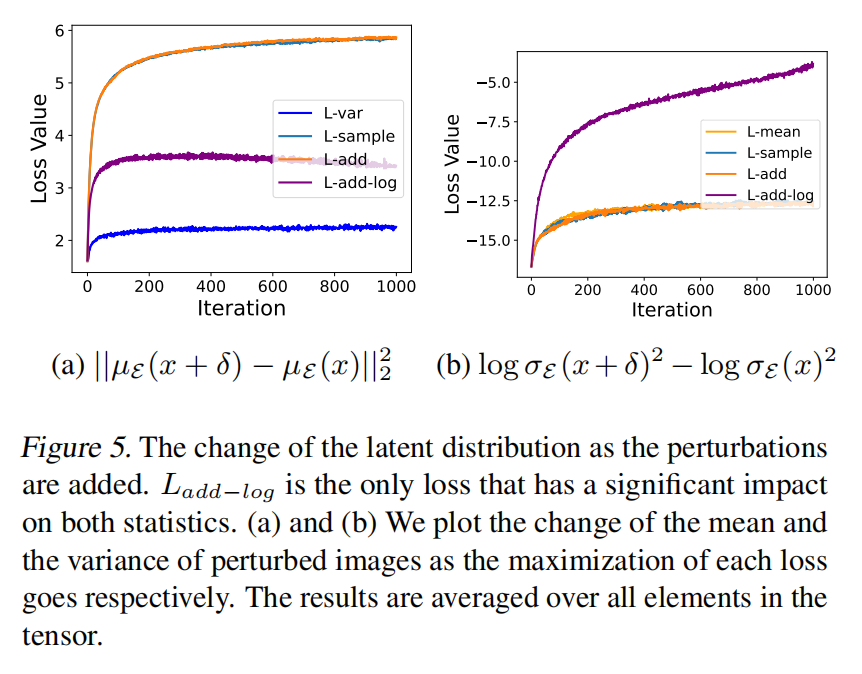
有了合适的目标后,本文接着检查它是否比之前对精细调整有更大影响。下表2中呈现的结果显示,以前文献中采用的损失函数,如 L mean L_\text{mean} Lmean、 L mean T L^T_\text{mean} LmeanT 和 L add L_\text{add} Ladd,与 L add-log L_\text{add-log} Ladd-log 相比表现不佳。本文注意到, L mean L_\text{mean} Lmean、 L sample L_\text{sample} Lsample 和 L add L_\text{add} Ladd 的类似行为可以通过上图5a和图5b中的观察得到很好的解释,因为它们大多集中在均值上。
经过精心设计的优化目标, L add-log L_\text{add-log} Ladd-log,证明结合了影响均值 µ 和方差 σ 的优势。它不仅成功阻止模型学习人脸(低FDS,高FID),还显著影响了输出图像的结构和纹理(低IQS和高BRISQUE)。本文惊讶地发现,在这种精细调整配置下, L add-log L_\text{add-log} Ladd-log 甚至优于FSGM(c = c1)和ASPL(c = c1)的表现。考虑到后者的防御需要更多的GPU内存,因为它们涉及UNet 模型,这比视觉编码器更为沉重,因此本文认为视觉编码器在对抗LDM数据保护中应该发挥不减的作用。鉴于其优越的保护效果和不依赖文本条件的特性,本文将由 L add-log L_\text{add-log} Ladd-log 定义的防御目标实施为Prompt-Independent Defense(PID)。
整合PID与现有的防御方法
本文继续探索如何通过PID改进当前的防御方法。为了结合两种不同类型的防御,即通过编码器进行防御和通过攻击训练损失函数进行防御,本文采用了一种联合优化的方法,涉及两种防御目标的加权组合,类似于Liang et al 和Liang & Wu 的做法。具体而言,给定结合了LDM训练损失的防御目标 T T T 和旨在操控潜在分布的防御目标 L L L ,我们定义一个权衡系数 λ \lambda λ 来平衡这两个目标。结合的防御方法表达如下:
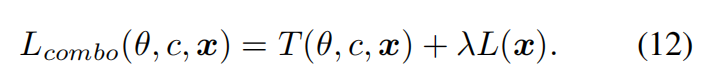
这里, θ \theta θ 再次表示模型参数, c c c 表示文本条件, x x x 表示待保护的数据。 T ( θ , c , x ) T(\theta,c, x) T(θ,c,x) 可以是方程3和方程5中定义的防御方法。
本文选择 L = L add-log L = L_{\text{add-log}} L=Ladd-log 作为观察到的最强防御目标,并且 T ∈ { ASPL , FSGM } T \in \{ \text{ASPL}, \text{FSGM} \} T∈{ASPL,FSGM}。在本文的默认设置中,经验上确定 λ = 0.05 \lambda = 0.05 λ=0.05 是最佳参数。尽管可以在所有设置中穷尽搜索最优 λ \lambda λ ,但由于计算需求巨大,本文在以下实验中一致采用 λ ∗ = 0.05 \lambda^* = 0.05 λ∗=0.05。
实验
在这部分,本文首先评估PID在 c prot = c explo c_{\text{prot}} = c_{\text{explo}} cprot=cexplo 和 c prot ≠ c explo c_{\text{prot}} \neq c_{\text{explo}} cprot=cexplo 两种情况下与现有算法的性能。其次,本文尝试将PID与现有的防御方法结合。最后测试PID在恶劣条件下的稳健性。
PID在提示一致性假设下表现出色
实验设置:本文在CelebA-HQ 和VGGFACE 数据集上比较PID与三种符号防御方法,包括AdvDM、FSGM和ASPL。在运行防御算法时,本文主要采用它们的默认配置。使用 P G D 1000 PGD_{1000} PGD1000 生成PID,并将扰动预算设置为 ε ∞ = 0.05 \varepsilon_\infty = 0.05 ε∞=0.05。作为基础模型,本文使用Stable Diffusion v1.5 和 Stable Diffusion v2.1。评估协议与前面章节介绍的相同,实验细节见原文附录A。
结果:CelebA-HQ数据集的完整结果列在下表3中。显著地,尽管消耗的计算资源显著较少(大约20%的GPU内存,5G vs 24G),PID在所有四种训练配置下表现出与包含UNet的三种算法相媲美甚至更优越的性能。具体来说,在文本编码器在微调期间冻结(即未进行训练)时,PID始终阻止LDMs学习有用的语义信息,导致显著较差的面部相似度(对于SD v1.5为0.254,对于SD v2.1为0.285)。在文本编码器也进行微调的情况下,PID引发严重的噪声、低质量图像,这些图像与训练数据几乎没有语义相关性,表现为降低的FDS(0.303和0.288)、显著降低的IQS(-8.979和-14.764)、高的BRISQUE(28.927和50.112)。由于视觉编码器独立于文本编码器,PID在所有设置中始终导致大于300的FID,使生成的图像与训练数据无关。这些结果显示,PID作为一种强大的基准方法,能够有效保护数据免受LDMs的影响,而不受不同提示的影响。关于VGGFACE(Cao et al., 2018)和LoRA微调(Hu et al., 2021)的结果详见原文附录C部分,原文附录F中展示了在受保护数据上微调的LDMs生成的图像。

混合PID增强现有算法的鲁棒性
接下来,本文比较依赖于提示的防御方法与它们与PID混合的变体。如下表4 所示,PID能够增强当前算法的鲁棒性。无论文本编码器是否被冻结,ASPL+PID都比单独的ASPL更加鲁棒,这表现在显著较低的FDS(0.254 vs 0.370,0.335 vs 0.412)和更高的FID(352 vs 271,208 vs 199)。此外,FSGM+PID始终生成比FSGM更差的语义信息的图像(更低的FDS)。基于以上结果,本文认为PID可以整合到现有的防御策略中,以实现对LDMs更可靠的数据保护。
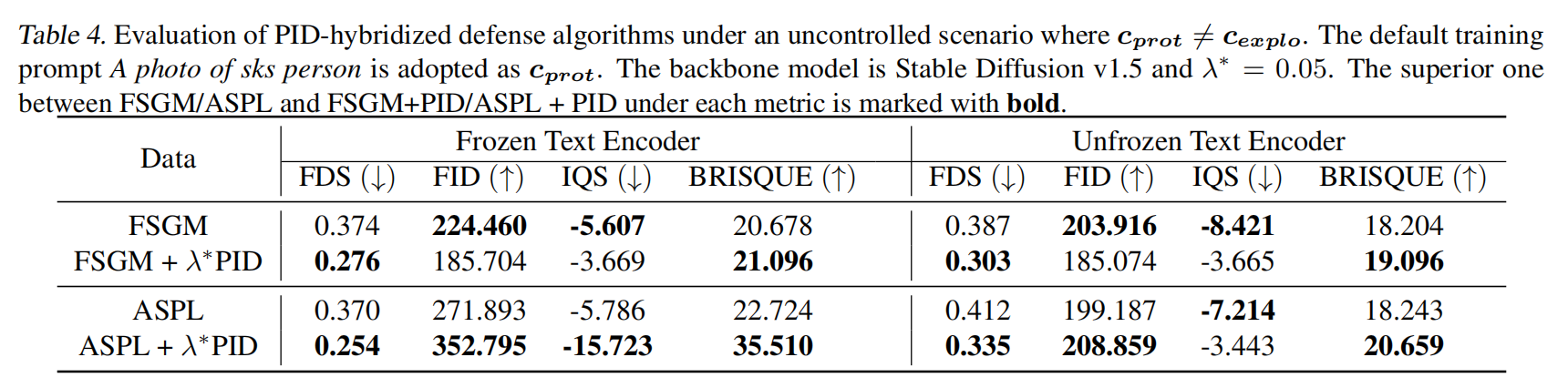
本文也注意到,将PID与FSGM结合在图像质量上并未表现得更好,这可能归因于 λ ∗ \lambda^* λ∗选择不当或联合优化的困难。尽管效果不佳,FSGM+PID仍然对语义信息(更低的FDS)有较大的影响,因此仍然适用于有效的防御策略。
提升跨模型的转移性
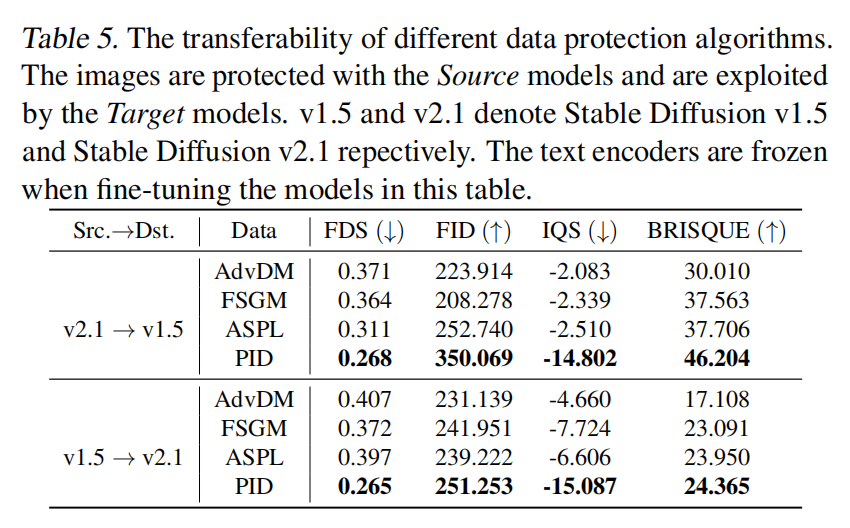
由于数据保护者无法控制下游利用者使用的模型,可能在两个阶段采用不同的模型。 本文在 c prot ≠ c explo c_{\text{prot}} \neq c_{\text{explo}} cprot=cexplo 设置下考察PID以及现有算法在不同模型之间的可转移性。
结果:如下表5所示,PID在两个模型版本之间表现出良好的可转移性,这可能是由于图像的压缩表示相似性所致。此外,本文注意到现有算法从SD v2.1到SD v1.5的转移性相对较弱,反之则较强。
对抗自适应攻击
本文继续研究 PID 在面对自适应攻击时的鲁棒性,详细的定量结果见下表6。
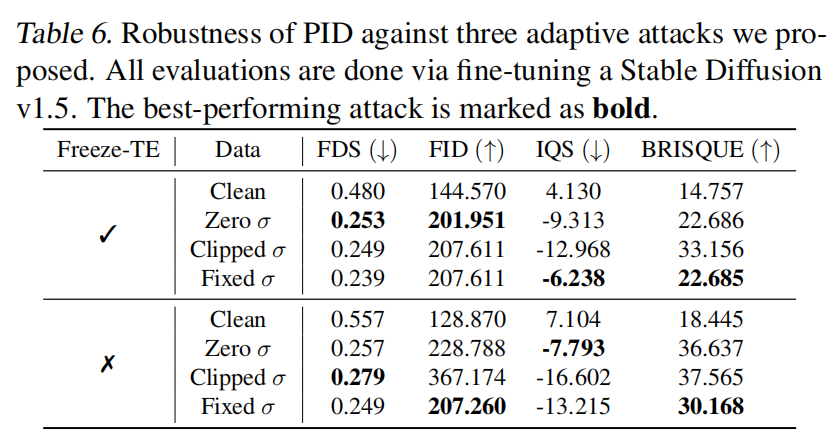
自适应攻击:由于本文提出的 PID 专注于操纵潜在分布的均值和方差,可能会有自适应攻击试图破坏我们的防御条件以提高有效性。本文提出了三种可能的自适应攻击,并测试本文提出的防御措施针对其鲁棒性。
- 零方差攻击:如上图5b所示,PID 导致潜在分布的方差显著增加。因此,攻击可能会将扰动图像的潜在分布 σ E ( x ) \sigma_E(x) σE(x) 的标准值固定为0,以减轻这种影响。然而,零标准值将使得微调过程更容易过拟合,导致生成结果质量下降。本文的结果显示,在这种训练设置下,PID 表现非常出色,得到的面部相似性评分 FDS=0.253 和图像质量评分 IQS=-9.313。
- 截断的 σ 和 固定的 σ \sigma σ:更智能的攻击者可能会尝试将标准值 σ E ( x ) \sigma_E(x) σE(x) 截断或固定为一个相对正常的值,例如 1 0 − 7 10^{-7} 10−7,而不是直接固定为0。采用这种攻击,本文观察到 PID 对图像质量的影响有所减弱,表现为改善的 IQS 和降低的 FID。然而,FDS 仍然非常低(小于0.3),使攻击失效。
总之,PID 被认为能够抵御本文上述提出的自适应攻击,并表现出令人信服的鲁棒性。
数据损坏的鲁棒性
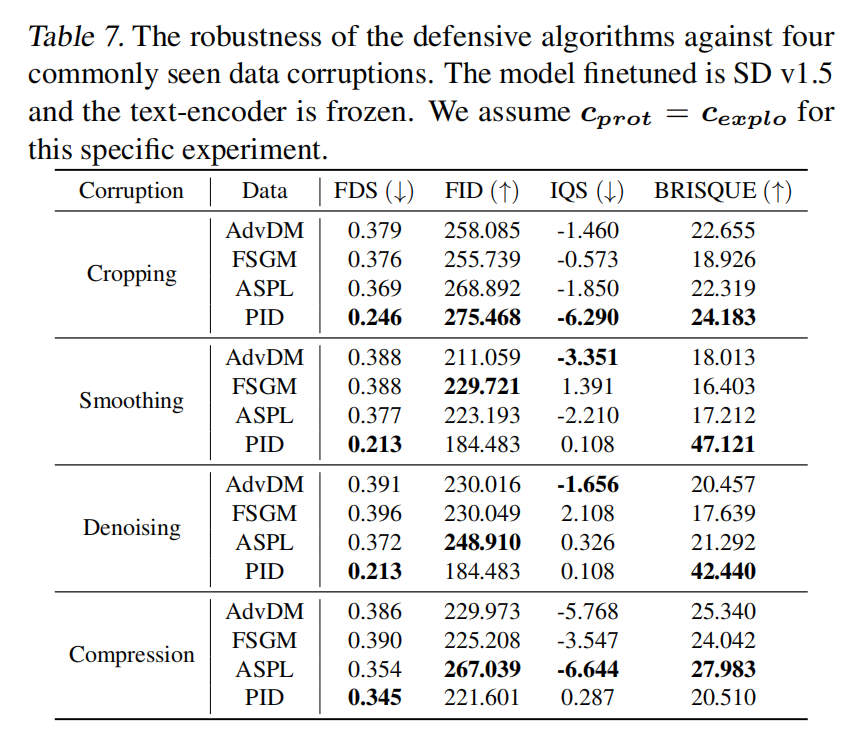
在发布受保护的数据后,数据保护者无法控制数据利用者对图像的处理方式。这里本文考虑四种常见的数据损坏方式,它们可能影响保护性扰动的效果,即随机调整大小和裁剪、均匀噪声平滑、图像去噪和 JPEG 压缩。在这部分本文使用的模型是 SD v1.5,并在微调过程中冻结文本编码器。报告的实验都是在 c prot = c explo c_{\text{prot}} = c_{\text{explo}} cprot=cexplo 的情况下进行的。
结果:如下表7所示,可以观察到 PID 在所有四种数据损坏情况下都表现出色,表现为始终较低的 FDS 和较高的 FID。即使在最严重的情况下,即 JPEG 压缩时,PID 也显示出与 AdvDM 和 FSGM 相当的性能。然而,当受到压缩影响时性能显著下降,这表明需要设计更为强大的保护算法来应对图像压缩。
结论
本文深入探讨了当前针对潜在扩散模型(LDMs)的数据保护算法在没有提示一致性假设的情况下的可靠性。揭示了当数据利用者有意制定微调提示时,基于提示的防御方法可能会显著降低性能。受到视觉编码器独立于文本提示的启发,本文彻底分析了扰动视觉编码器对微调过程的影响,并提出了一种名为PID的提示无关防御算法。通过对PID的经验验证有效性以及其改进现有算法的能力,相信本文提出的提示无关算法标志着朝着可靠保护数据免受潜在扩散模型利用的重要一步。
参考文献
[1] PID: Prompt-Independent Data Protection Against Latent Diffusion Models
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









