







 达摩院团队提出半监督预训练对话模型SPACE,通过结合少量有标对话数据和大量无标数据,利用一致性正则化注入对话策略知识,提升模型效果。SPACE1.0在多任务对话数据集上表现优越,尤其在低资源设置下展现出强小样本学习能力。
达摩院团队提出半监督预训练对话模型SPACE,通过结合少量有标对话数据和大量无标数据,利用一致性正则化注入对话策略知识,提升模型效果。SPACE1.0在多任务对话数据集上表现优越,尤其在低资源设置下展现出强小样本学习能力。
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

如何将人类先验知识低成本地融入到预训练模型中一直是个NLP的难题。在本工作中,达摩院对话智能团队提出了一种基于半监督预训练的新训练范式,通过半监督方法将少量有标对话数据和海量无标对话数据一起进行预训练,利用一致性正则化损失函数将标注数据中蕴含的对话策略知识注入到预训练模型中去,从而学习出更好的模型表示。
新提出的半监督预训练对话模型SPACE(Semi-Supervised Pre-trAined Conversation ModEl)首先围绕对话策略知识展开了研究,实验表明,SPACE1.0 模型在剑桥MultiWOZ2.0,亚马逊MultiWOZ2.1等经典对话数据集上能够取得5%+显著效果提升,并且在各种低资源设置下,SPACE1.0 比现有sota 模型都具有更强的小样本学习能力。
本期AI TIME PhD直播间,我们邀请到阿里巴巴达摩院高级算法工程师——戴音培,为我们带来报告分享《半监督预训练对话模型 SPACE》。

戴音培:
阿里巴巴达摩院高级算法工程师,硕士毕业于清华大学电子工程系,研究领域为自然语言处理及对话智能(Conversational AI),具体方向包括对话理解、对话管理和大规模预训练对话模型等。在 ACL / AAAI / SIGIR/ ICASSP 等会议上发表多篇论文并多次担任 ACL / EMNLP / NAACL / AAAI 等会议审稿人。
Pre-trained Conversation Model (PCM)
最近的预训练语言模型Pre-trained Language Model(PLM)可谓是异常火爆,那我们为何还要研究预训练对话模型呢?尽管前者在许多任务上都能带来一定程度的效果提升,但有文章表明通过一些损失函数的设计可以得到更好的预训练模型。预训练对话模型就是针对下游的对话任务设计的模型,其能够在预训练语言模型基础之上得到更好的提升。
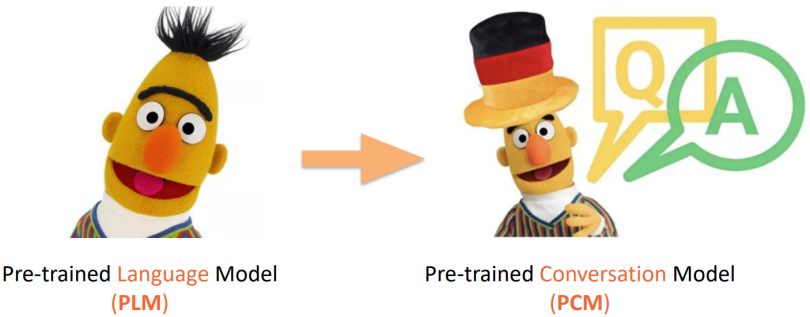
预训练语言模型vs.预训练对话模型
• Pre-trained Language Model (PLM) 预训练语言模型
• 需要回答什么样的句⼦更像⾃然语⾔

• Pre-trained Conversation Model (PCM) 预训练对话模型
• 需要回答给定对话历史,什么样的回复更合理
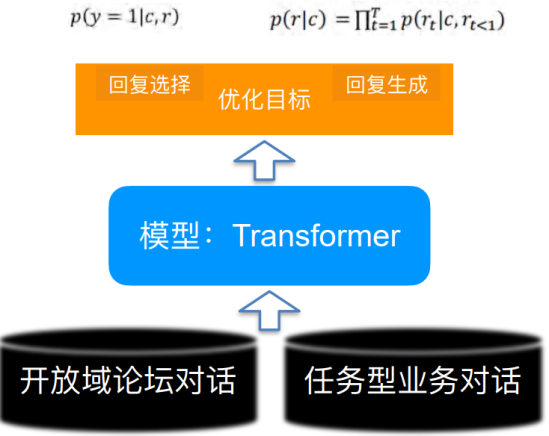
相比plain text,对话有哪些特点?

Backgrounds
• Task-oriented dialog (TOD) systems help accomplish certain tasks
本研究主要是建立在任务型对话的基础上,相比于普通闲聊对话需要完成特定的任务。
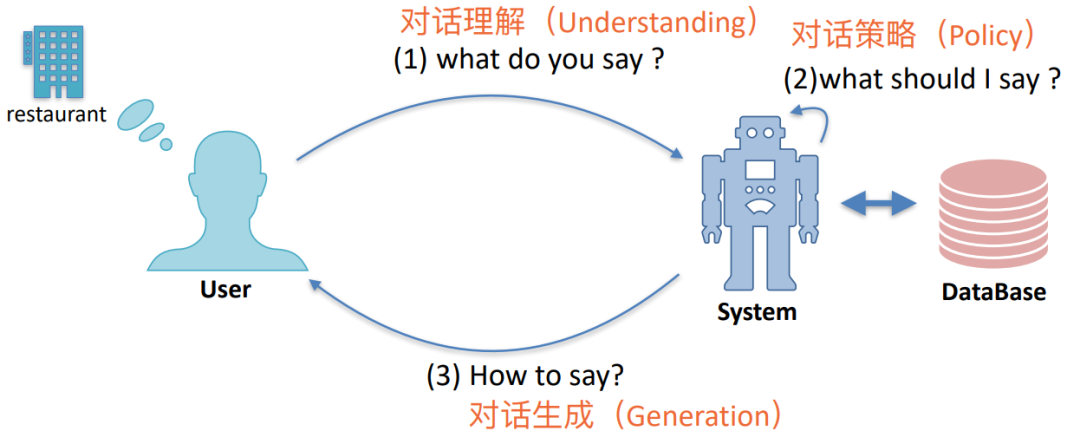
如上图所示,一共包含对话理解、对话策略和对话生成一共三个类任务。
预训练对话模型汇总
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3
3











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









