






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
随着年初ChatGPT的爆红,多模态领域也涌现出一大批可以处理多种模态输入的对话模型,如LLaVA, BLIP-2等等。为了进一步扩展多模态大模型的区域理解能力,近期新加坡国立大学和清华大学的小伙伴打造了一个可以同时进行对话和检测、分割的多模态模型NExT-Chat:
题目:NExT-Chat: An LMM for Chat, Detection and Segmentation
作者:张傲,姚远,吉炜,刘知远,Chua Tat-Seng
单位:新加坡国立大学,清华大学
多模态对话模型Demo
https://next-chatv.github.io/
论文
https://arxiv.org/pdf/2311.04498.pdf
代码
https://github.com/NExT-ChatV/NExT-Chat

方法简介
1 目标
文章探索了如何在多模态模型中引入位置输入和输出的能力。其中位置输入能力指的是根据指定的区域回答问题,比如图1中的左图。位置输出能力指的是定位对话中提及的物体,如图1右图的小熊定位:

图 1:位置输入和输出示例
2 现有方法
现有的方法主要通过pix2seq的方式进行LLM相关的位置建模。比如Kosmos-2将图像划分成32x32的区块,用每个区块的id来代表点的坐标。Shikra将物体框的坐标转化为纯文本的形式从而使得LLM可以理解坐标。
但使用pix2seq方法的模型输出主要局限在框和点这样的简单格式,而很难泛化到其他更密集的位置表示格式,比如segmentation mask。为了解决这个问题,本文提出了一种全新的基于embedding的位置建模方式pix2emb。
3 pix2emb方法
不同于pix2seq,所有的位置信息都通过对应的encoder和decoder进行编码和解码,而不是借助LLM本身的文字预测头

图 2:pix2emb方法简单示例
如图2所示,位置输入被对应的encoder编码为位置embedding,而输出的位置embedding则通过Box Decoder和Mask Decoder转化为框和掩模。
这样做带来了两个好处:(1) 模型的输出格式可以非常方便的扩展到更多复杂形式,比如segmentation mask。(2) 模型可以非常容易的定位任务中已有的实践方式,比如本文的detection loss采用L1 Loss和GIoU Loss (pix2seq则只能使用文本生成loss),本文的mask decoder借助了已有的SAM来做初始化。
3 NExT-Chat模型
通过借助pix2emb方法,作者训练了一个全新的NExT-Chat模型。
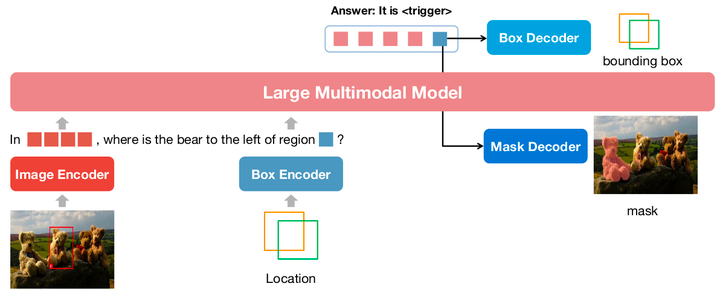
图 3:NExT-Chat模型架构
NExT-Chat整体采用了LLaVA架构,即通过Image Encoder来编码图像信息并输入LLM进行理解,并在此基础上添加了对应的Box Encoder和两种位置输出的Decoder。
然而在正常情况下,LLM不知道何时该使用语言的LM head还是位置解码器。为了解决这一问题,NExT-Chat额外引入一个全新的token类型<trigger>来标识位置信息。如果模型输出了,则的embedding会被送入对应的位置解码器进行解码而不是语言解码器。
此外,为了维持输入阶段和输出阶段,位置信息的一致性。NExT-Chat额外引入了一个对齐约束:

图 4:位置输入、输出约束
如图4所示,box和位置embedding会被分别通过解码器、编码器或解码器编码器组合,并要求前后不发生变化。作者发现该方法可以极大程度促进位置输入能力的收敛。
4 NExT-Chat训练
模型训练主要包括3个阶段:
(1)第一阶段:该阶段目的在于训练模型基本的框输入输出基本能力。NExT-Chat采用Flickr-30K,RefCOCO,VisualGenome等包含框输入输出的数据集进行预训练。训练过程中,LLM参数会被全部训练。
(2)第二阶段:该阶段目的在于调整LLM的指令遵循能力。通过一些Shikra-RD,LLaVA-instruct之类的指令微调数据使得模型可以更好的响应人类的要求,输出更人性化的结果。
(3)第三阶段:该阶段目的在于赋予NExT-Chat模型分割能力。通过以上两阶段训练,模型已经有了很好的位置建模能力。作者进一步将这种能力扩展到mask输出上。实验发现,通过使用极少量的mask标注数据和训练时间(大约3小时),NExT-Chat可以快速的拥有良好的分割能力。
这样的训练流程的好处在于:检测框数据丰富且训练开销更小。NExT-Chat通过在充沛的检测框数据训练基本的位置建模能力,之后可以快速的扩展到难度更大且标注更稀缺的分割任务上
二、实验
在实验部分,NExT-Chat展示了多个任务数据集上的数值结果和多个任务场景下的对话示例。
2.1 RES任务
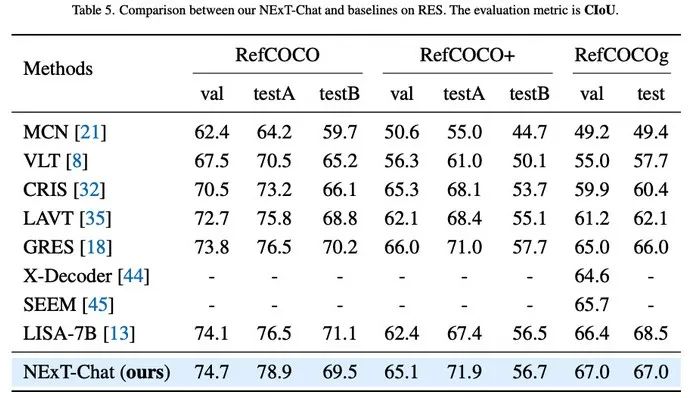
表1:RES任务上NExT-Chat结果
作者首先展示了NExT-Chat在RES任务上的实验结果。虽然仅仅用了极少量的分割数据,NExT-Chat却展现出了良好的指代分割能力,甚至打败了一系列有监督模型(如MCN,VLT等)和用了5倍以上分割掩模标注的LISA方法。
2.2 REC任务

表2:REC任务上NExT-Chat结果
作者然后展示了NExT-Chat在REC任务上的实验结果。如表2所示,相比于相当一系列的有监督方法(如UNITER),NExT-Chat都可以取得更优的效果。一个有意思的发现是NExT-Chat比使用了类似框训练数据的Shikra效果要稍差一些。作者猜测是由于pix2emb方法中LM loss和detection loss更难以平衡,以及Shikra更贴近现有的纯文本大模型的预训练形式。
2.3 图像幻觉任务
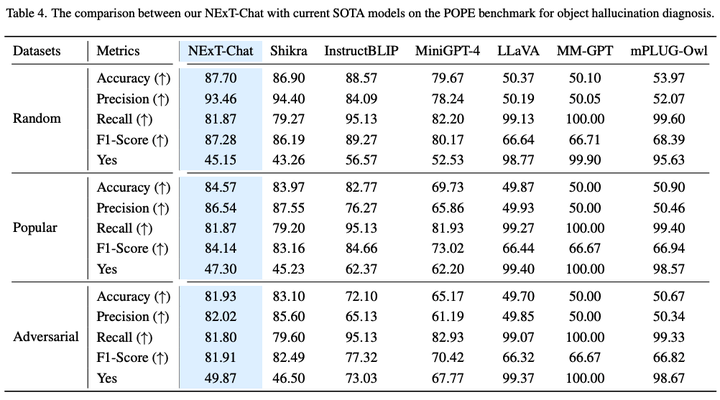
表3:POPE数据集上NExT-Chat结果
如表3所示,NExT-Chat可以在Random和Popular数据集上取得最优的准确率。
2.4 区域描述任务
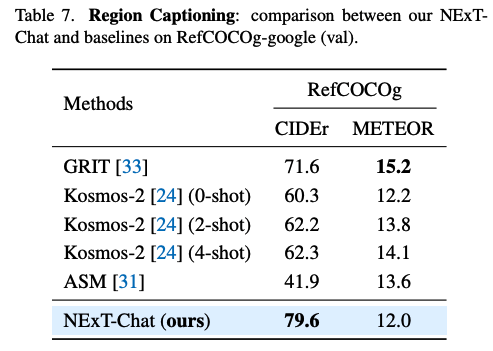
表4:RefCOCOg数据集上NExT-Chat结果
在区域描述任务上,NExT-Chat可以取得最优的CIDEr表现,且在该指标打败了4-shot情况下的Kosmos-2。
2.5 Demo展示
在文中,作者展示了多个相关demo:
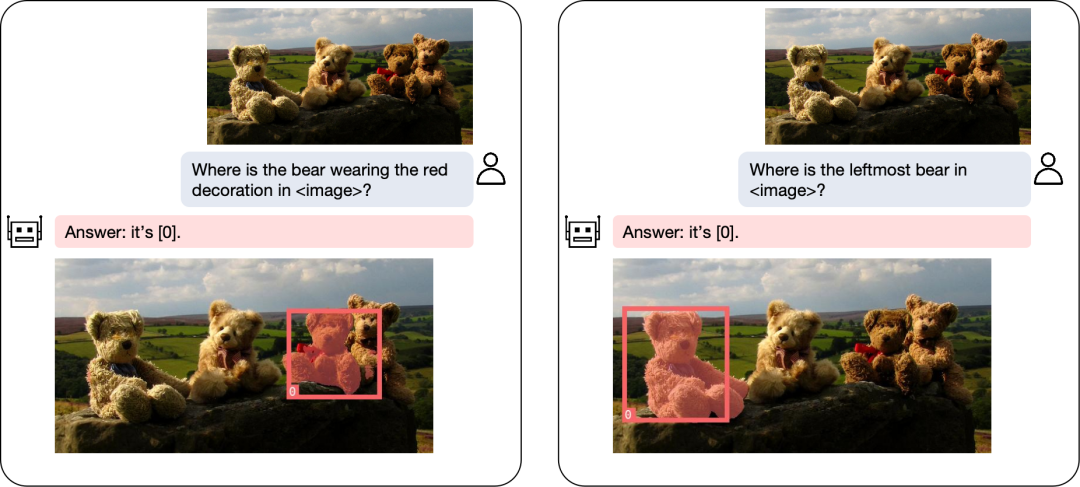
图5:定位小熊

图6:复杂定位

图7:描述图片

图8:区域描述

图9:推理
五、总结
本文探索了一种不同于pix2seq形式的位置建模方式pixemb。通过pix2emb方法,作者构建了NExT-Chat多模态大模型。NExT-Chat大模型可以在对话过程中完成相关物体的检测、分割并对指定区域进行描述。通过充足的实验评测,作者展示了NExT-Chat在多种场景下的优秀数值表现和展示效果。
往期精彩文章推荐
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1400多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 关注我们!
















 14
14











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









