






 本文介绍了一种名为DBE的算法,用于解决联邦学习中的数据异构问题,通过消除表征偏移和退化,提升服务器与客户机之间的知识迁移。实验显示,DBE在泛化能力和个性化方面均有显著改进,尤其在与SOTA方法的对比中表现出色。
本文介绍了一种名为DBE的算法,用于解决联邦学习中的数据异构问题,通过消除表征偏移和退化,提升服务器与客户机之间的知识迁移。实验显示,DBE在泛化能力和个性化方面均有显著改进,尤其在与SOTA方法的对比中表现出色。
以下文章来源于PaperWeekly,作者 张剑清
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
本文介绍的是我们的一篇收录于 NeurIPS 2023 的论文。我们设计了一个领域偏差消除器(DBE)来解决联邦学习(FL)中的数据异构问题。该方法可以提升服务器-客户机之间的双向知识迁移过程,并提供了理论保障,能够在泛化能力和个性化能力两个方面进一步为其他联邦学习方法带来提升。
大量实验表明,我们可以在各种场景下为传统联邦学习方法实现最多 22.35% 的泛化能力提升,而且 FedAvg+DBE 能在个性化方面比现有的 SOTA 个性化联邦学习(pFL)方法高了 11.36 的准确率。

论文标题:
Eliminating Domain Bias for Federated Learning in Representation Space
论文链接:
https://arxiv.org/pdf/2311.14975.pdf
代码链接:
https://github.com/TsingZ0/DBE(含有PPT和Poster)
https://github.com/TsingZ0/PFLlib

联邦学习简介
不论是隐私保护的需求还是在数据财产保护的需要,将本地的私有数据进行外传都是需要尽量避免的。联邦学习是一种新型的分布式机器学习范式,它能够在保留数据在本地是前提下,以中央服务器作为媒介,进行多个客户机(设备或机构)间的协作学习和信息传递。
在联邦学习过程中,参与协作学习的客户机之间约定一种信息的传递方式(一般是传递模型参数),并以该方式进行一轮又一轮的迭代,实现本地模型(和全局模型)的学习。每一轮传递的信息,作为一种外部信息,弥补了单一客户机独自学习时本地数据不足的问题。
区别于传统的分布式机器学习范式,在联邦学习(如 FedAvg [1])中,由于各个客户机的本地数据不能进行操作和修改,没有办法保证每个客户机上的数据的分布是一致的,于是导致了关键的“数据异质性(或统计异质性)问题”。我们用下图描述了联邦学习过程,其中不同的颜色代表不同的数据分布。
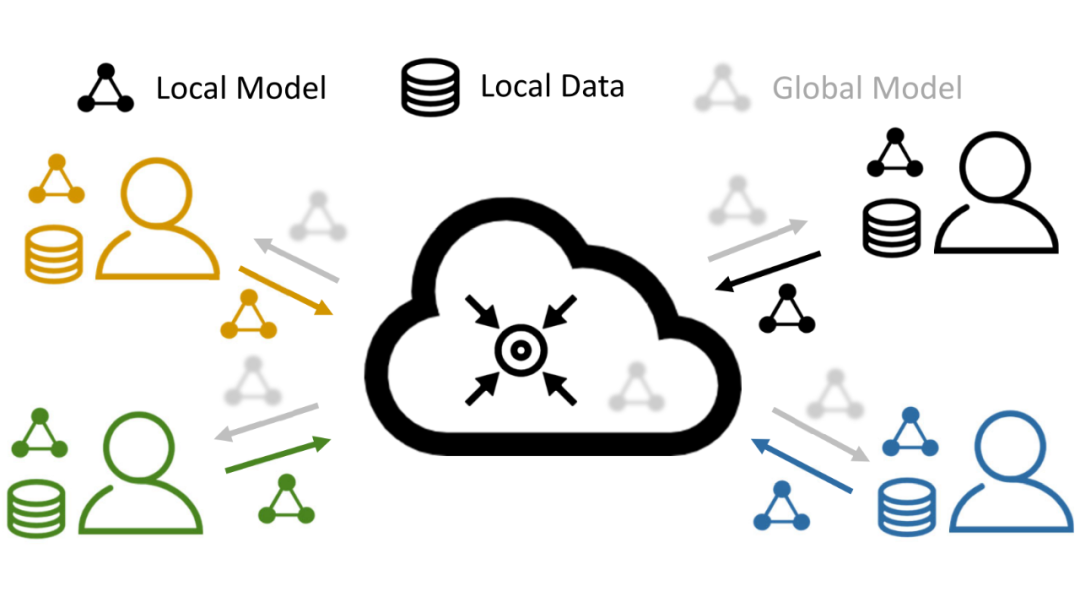
▲ 图1:联邦学习及其数据异质性问题

表征偏移和表征退化现象
在每一次迭代学习过程中,每个客户机在收到全局模型后,会在其本地数据上进行训练。这个过程会将全局模型转化为本地模型,如下图所示。
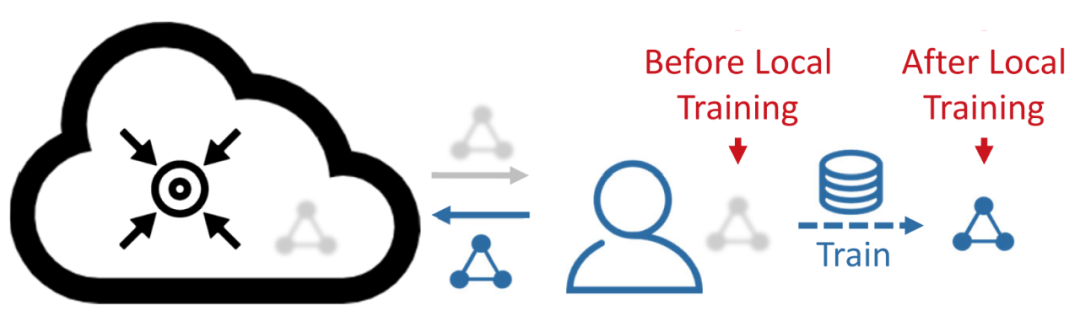
▲ 图2:联邦学习中客户机上的本地训练过程
在客户机的本地训练过程中,我们发现了表征偏移和表征退化这两个现象。具体来说,表征偏移(如图 3 所示)指的是:如果我们把所有客户机(总共 20 个)上的数据在经过模型后得到的表征向量进行 t-SNE 可视化,我们可以看到:客户机收到全局模型的时候可视化的图像(图 3 左)中所有表征都是混杂在一起的,不论客户机 ID 和样本标签。
而在进行了本地训练后,这些通过本地模型输出的表征却都偏移到每个客户机各自的域上了(图 3 右),形成了 20 个簇。这是由于模型吸收了本地数据中“有偏”的数据,导致模型对于表征的学习也变得“有偏”了。
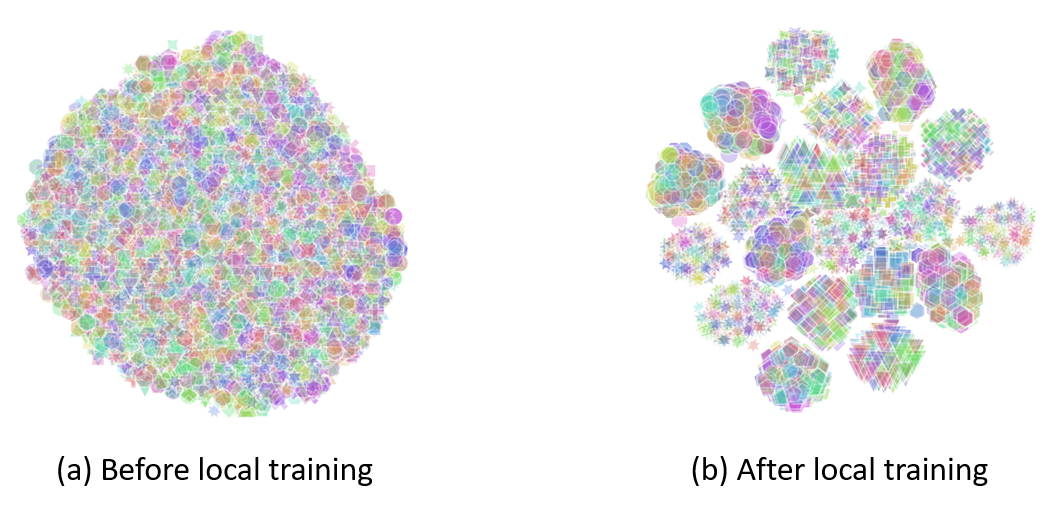
▲ 图3:FedAvg 本地训练前后所有客户机上表征向量的 t-SNE 可视化。我们用颜色和形状分别来区分标签和客户。
伴随着表征偏移的出现,表征退化也同步出现。我们用 MDL [2] 这种经典的、与模型和任务无关的度量标准来评估模型。进一步观察后,我们发现这种表征偏移并不是使得模型变得更好,而是使之变得更差,而且这种情况在模型的每一层都有发生,如图 4 所示。
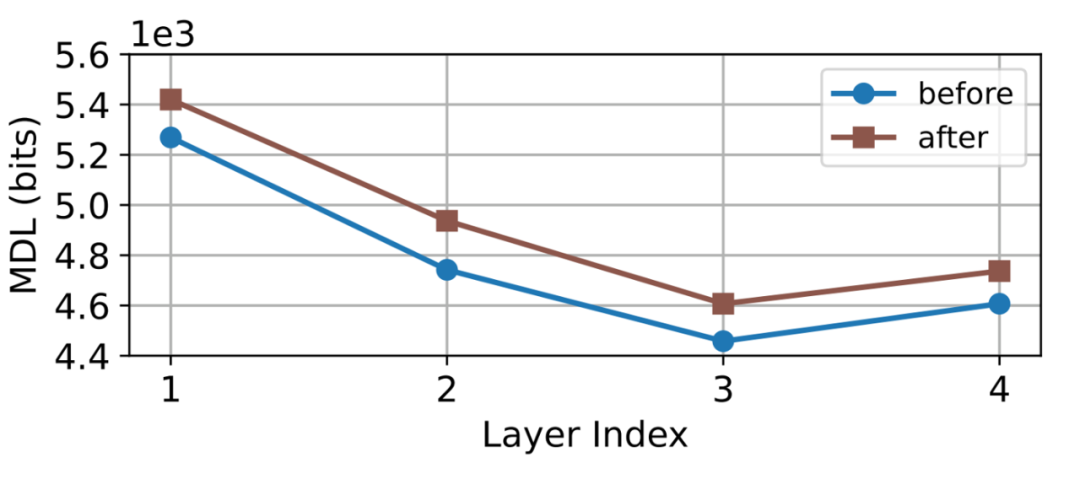
▲ 图4:FedAvg 中本地训练前后表征向量的逐层 MDL 值。MDL 值越大,学到的表征向量质量越低,模型质量越差。
我们把表征偏移和表征退化现象的成因,归咎于数据异质性导致的域偏移问题,于是提出了域偏移消除器(Domain Bias Eliminator, DBE)。

域偏移消除器
这里我抛去论文中详细的公式表达,只用图示的方式来说明我们的域偏移消除器,细节上有不清楚的可以查看我们论文中的公式。首先,由于我们主要关注在表征提取层面,我们便将模型分割为前后两部分,第一部分为“特征提取器”,第二部分为“分类器”,如图 5 所示。
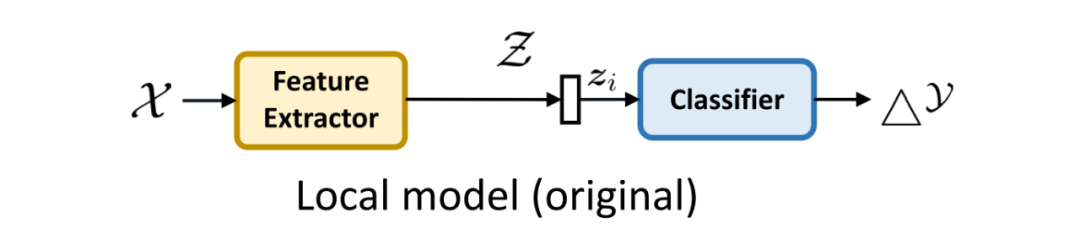
▲ 图5:本地模型
既然域偏移导致了表征偏移,我们就需要通过某种部件去抵消偏移,从而达到消除偏移的目的。鉴于此,我们提出了个性化表征偏移记忆(Personalized Representation Bias Memory, PRBM)这个模块来实现抵消效果。
如图 6 所示,我们将原本只有一级的表征,分离为两为两级,然后在两级中间插入 PRBM 模块(一个与表征形状一致的可学习的向量)。 是原本的表征向量,蕴含了偏移的和不偏移的特征信息。我们训练这个 PRBM 模块,希望它能够记忆表征 中偏移的那部分信息,这样特征提取器就只需要学习不偏移的信息来提取不偏移的 就可以了。
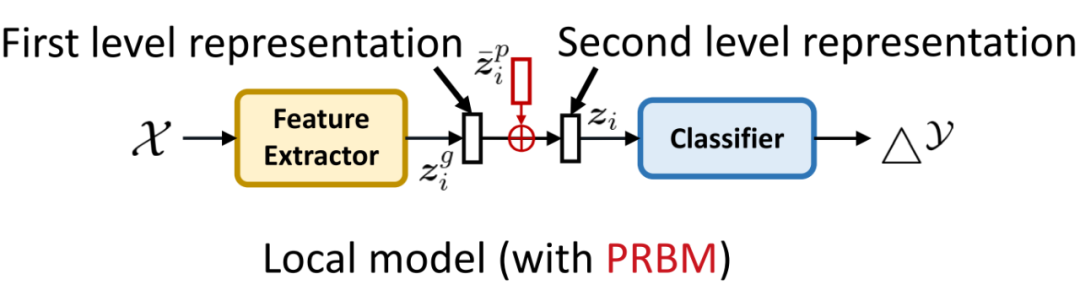
▲ 图5:本地模型中引入我们提出的PRBM模块
然而,事实却并没有想象的容易。单纯学习一个 PRBM 模块的话,该模块本身在没有引导的情况下,并不知道自己在学什么。这就导致 和 PRBM 模块中的信息,很难说哪个蕴含偏移的信息。
所以我们需要一个引导,来给 PRBM 模块指引偏移的信息或给 指引不偏移的信息。因为目前对于偏移的信息的定量方法还不具备,考虑到联邦学习的协同特性,语义上不偏移的信息很容易通过聚合来得到。所以我们选择了后者,即给 指引不偏移的信息。
具体来说,我们提出均值约束(Mean Regularization, MR)方法,在联邦学习开始之前的初始化准备阶段,让每个客户机本地训练一轮模型,然后计算各自的一个“表征均值向量”,再上传到中央服务器聚合得到一个“全局表征均值向量” 。这样,该向量就拥有了不偏移的特征信息。我们让 去靠近 ,从而促使特征提取器学习不偏移的全局信息。将 PRBM 和 MR 结合,就得到我们的 DBE,如图 6 所示。
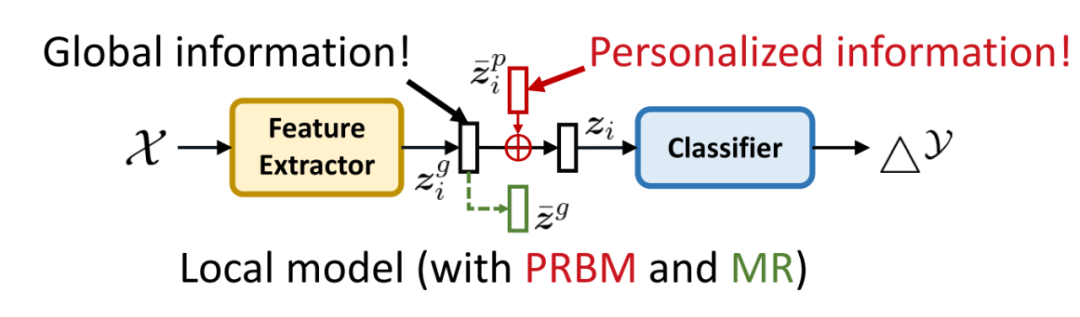
▲ 图6:本地模型中引入我们提出的 DBE(PRBM 模块和 MR 模块)

对双向知识迁移的增强
我们也通过理论证明,引入 DBE 后,可以同时增强“本地到全局的知识迁移”和“全局到本地的知识迁移”这两个过程(图 7 和图 8)。具体证明和理论分析,详见我们的论文。

▲ 图7:本地到全局的知识迁移

▲ 图8:全局到本地的知识迁移

实验
我们首先研究了 DBE 的性质,并证实了它能够1)消除域偏移;2)可以插入到任意两层之间产生效果;3)可以在泛化能力和个性化能力方面提升其他现有的方法。
1. 如下图所示,FedAvg+DBE 中的第一级表征 在经过本地训练后不再偏向于每个客户端的本地域。通过个性化表征偏移记忆 PRBM, 可以在本地训练之前或之后所在域不变,因为偏移的信息在训练之前已经都存储到 PRBM 中了。

▲ 图9:FedAvg+DBE 本地训练前后所有客户机上表征向量的 t-SNE 可视化。
2. 我们尝试了在不同层之间插入 DBE,结果显示:DBE 都能带来泛化能力和个性化能力方面一定的提升。当然,不同位置的表征形状不同,这会使得 PRBM 中可训练参数不同。越靠近输出端的表征维度越低,所以 PRBM 中可训练参数越少。至于在哪个位置插入 PRBM,可根据实际情况取舍。
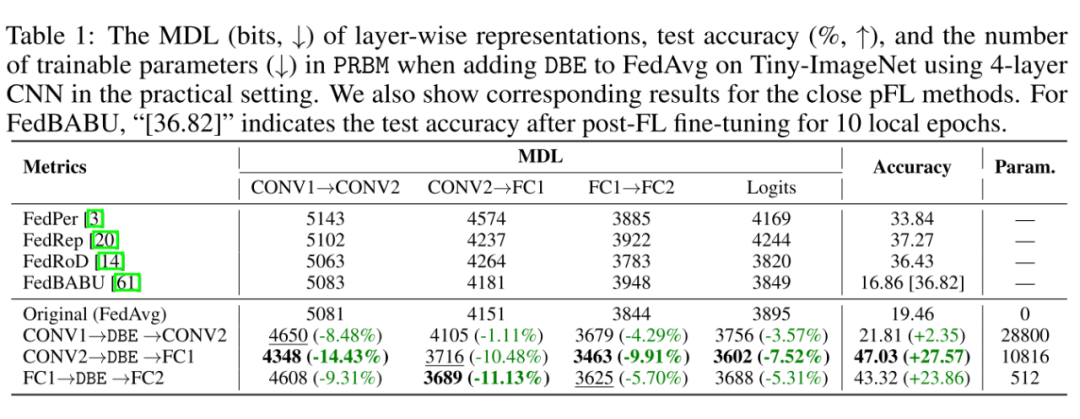
▲ 表1:FedAvg+DBE 中,DBE 插入到不同层之间的效果
3. 如表 2 所示,DBE 可以提升现有的传统联邦学习方法。其中,TINY 和 TINY* 分别表示在 Tiny-imagenet 上使用 4 层 CNN 和 ResNet-18。DBE 比传统联邦学习方法最多提高 -22.35% 的 MDL(bits)和 +32.30 的精度(%)。
如表 3 和表 4 所示,FedAvg+DBE 的个性化表现可以超越现有的 SOTA 个性化联邦学习方法 +11.36 的精度。如表 4 所示,DBE 中的 MR 也能够进一步提升这些 SOTA 个性化联邦学习方法。引入 DBE 只会带来少量的计算开销且几乎没有额外的通讯开销。
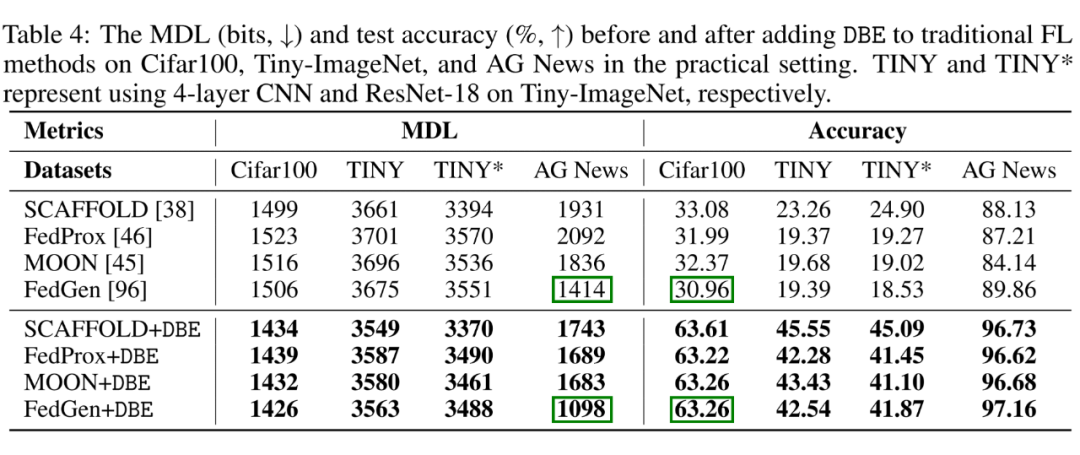
▲ 表2:DBE 应用到代表性传统联邦学习方法上的效果。
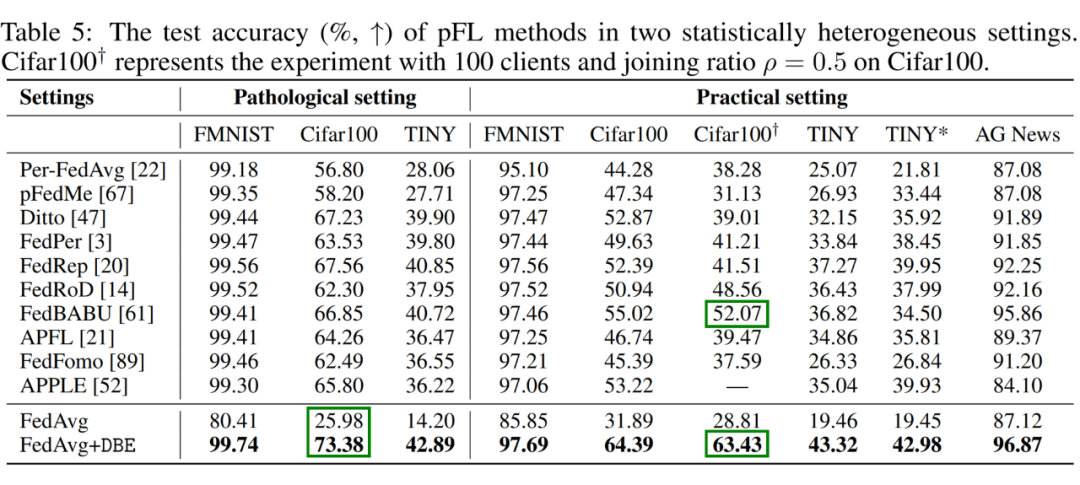
▲ 表3:FedAvg+DBE 与 SOTA 个性化联邦学习方法的对比实验。
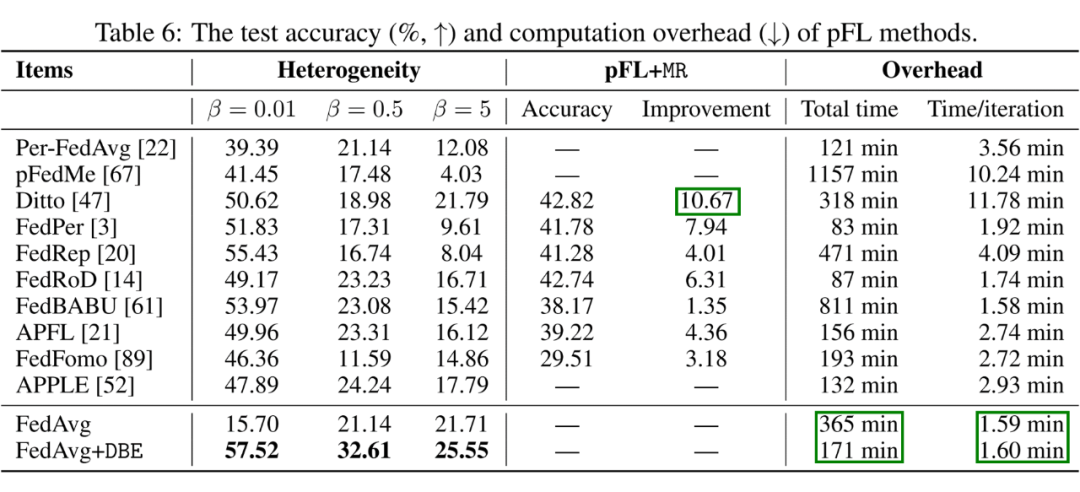
▲ 表4:FedAvg+DBE 与 SOTA 个性化联邦学习方法的对比实验(续)和 DBE 应用到 SOTA 个性化联邦学习方法上的效果。

参考文献
[1] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-Efficient Learning of Deep Networks from Decentralized Data. In International Conference on Artificial Intelligence and Statistics (AISTATS), 2017.
[2] Ethan Perez, Douwe Kiela, and Kyunghyun Cho. True Few-Shot Learning with Language Models. In International Conference on Advances in Neural Information Processing Systems (NeurIPS), 2021.
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1600多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看更多!


















 57
57

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









