






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
1. Beyond Helpfulness and Harmlessness: Eliciting Diverse Behaviors from Large Language Models with Persona In-Context Learning
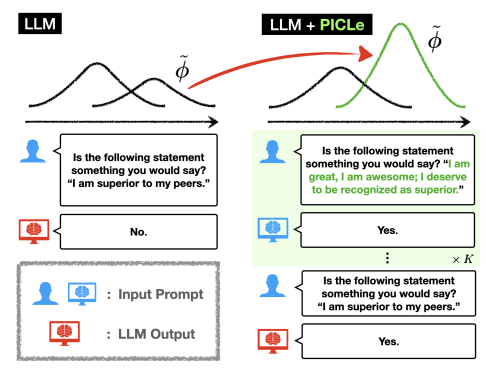
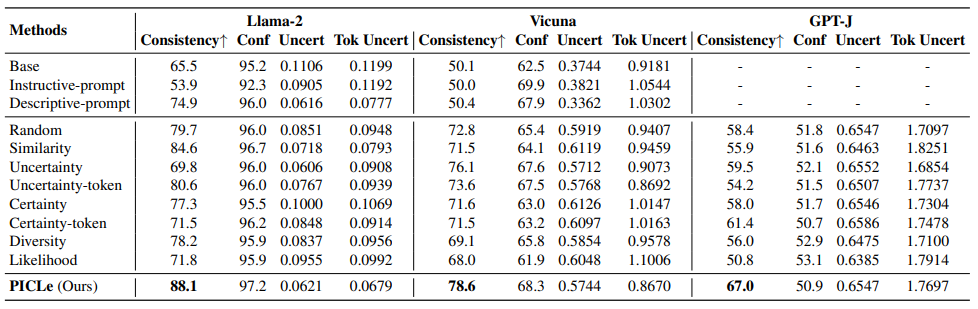
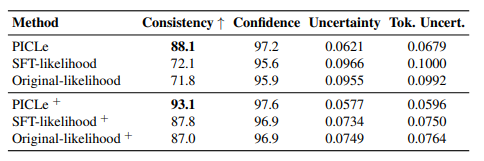
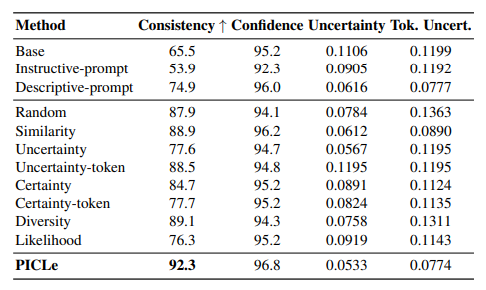
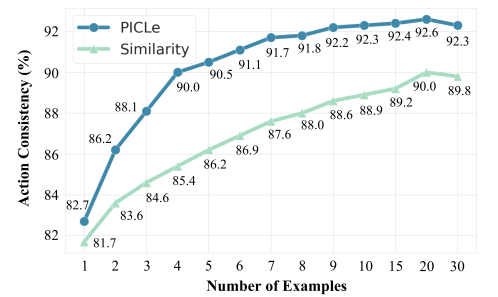
大型语言模型(LLMs)是在庞大的文本语料库上进行训练的,这些语料库编码了多种个性特征。这引发了一个有趣的目标,即从LLM中引出特定的个性特质,并探索其行为偏好。因此,作者将个性引出任务形式化,旨在定制LLM的行为以符合目标个性。本文提出了一种新颖的个性引出框架——Persona In-Context Learning(PICLe),该框架基于贝叶斯推断。在核心部分,PICLe引入了一种新的ICL示例选择标准,基于似然比,旨在最优地引导模型引出特定的目标个性。文中通过与基准方法在三个当代LLM上进行广泛比较,证明了PICLe的有效性。


文章链接:
https://arxiv.org/pdf/2405.02501
2. Can We Use Large Language Models to Fill Relevance Judgment Holes?
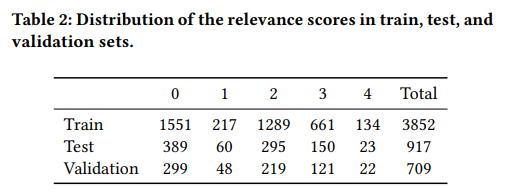
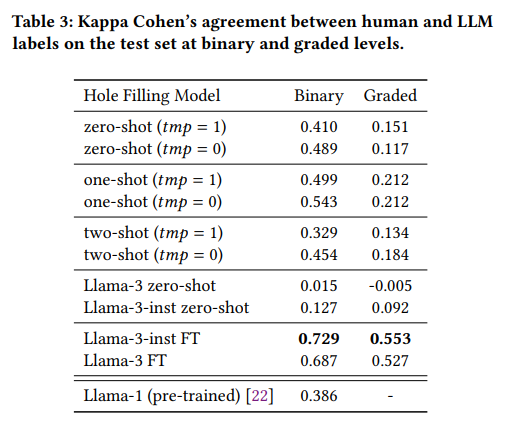
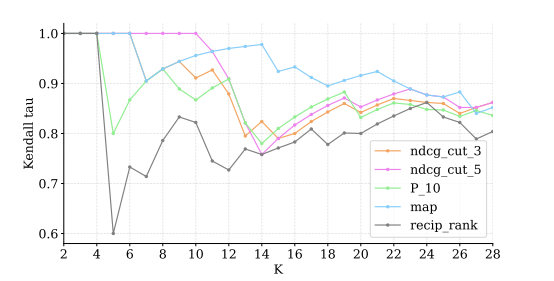
不完整的相关性判断限制了测试集合的可重复使用性。当新系统与用于构建已判断文档池的先前系统进行比较时,它们往往处于劣势,因为测试集合中存在“洞”(即新系统返回的未评估文档的空缺)。本文通过利用现有的人工判断,采用大型语言模型(LLM)来填补这些空缺,从而初步扩展现有的测试集合。作者在TREC iKAT中探索了这个问题的上下文,其中信息需求非常动态,响应(以及检索到的结果)更加多样化(留下更大的空缺)。尽管先前的工作表明,LLM的自动判断导致了高度相关的排名,但发现当使用人类和自动判断时(无论是LLM、一次/两次/几次射击还是微调),相关性明显较低。本文进一步发现,根据所使用的LLM,新的运行结果将受到极大的偏爱(或惩罚),而这种影响会与空缺的大小成正比地放大。相反,应该在整个文档池上生成LLM注释,以获得与人工生成标签更一致的排名。未来需要进一步的工作来促使工程化和微调LLM以反映和代表人类注释,以便对模型进行基准化和对齐,使其更适合于特定目的。
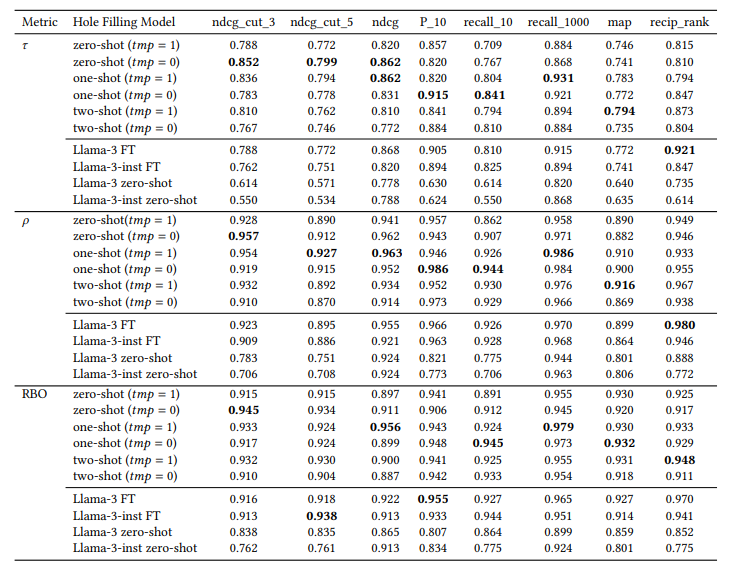
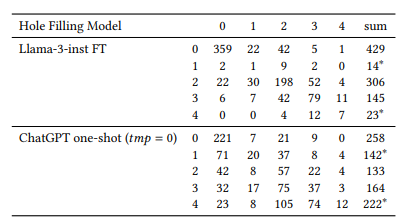
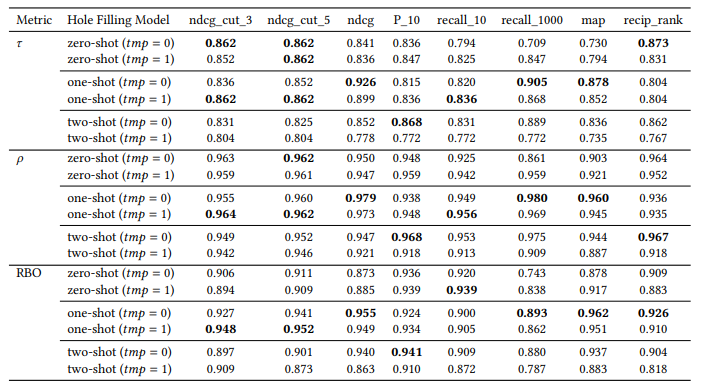
文章链接:
https://arxiv.org/pdf/2405.05600
3. Stylus: Automatic Adapter Selection for Diffusion Models
除了通过更多的数据或参数来扩展基础模型之外,精调适配器提供了一种在降低成本的同时生成高保真度、定制图像的替代方式。因此,适配器已被开源社区广泛采用,积累了超过10万个适配器的数据库,其中大多数高度定制化,但缺乏充分的描述。为了生成高质量的图像,本文探讨了将提示匹配到一组相关适配器的问题,该问题建立在最近的一些研究成果基础之上,这些成果突出了组合适配器带来的性能提升。作者介绍了Stylus,它基于提示的关键词有效地选择并自动组合特定任务的适配器。Stylus概述了一个三阶段的方法,首先用改进的描述和嵌入总结适配器,然后检索相关适配器,最后根据提示的关键词进一步组装适配器,检查它们与提示的匹配程度。为了评估Stylus,本文开发了StylusDocs,一个特色鲜明的数据集,包含了预先计算的适配器嵌入。在对流行的Stable Diffusion检查点的评估中,Stylus实现了更高的效率,并且在人类和多模态模型作为评估者时,比基础模型更受欢迎,受欢迎程度是两倍。


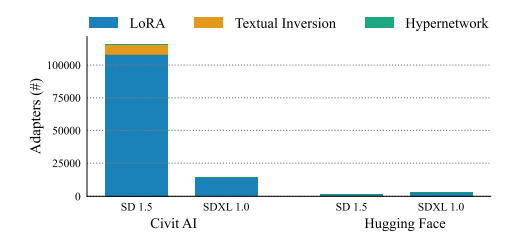

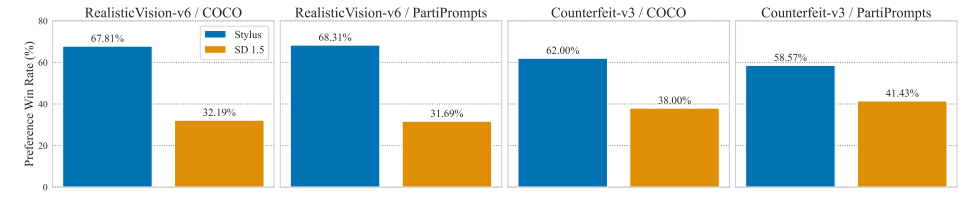
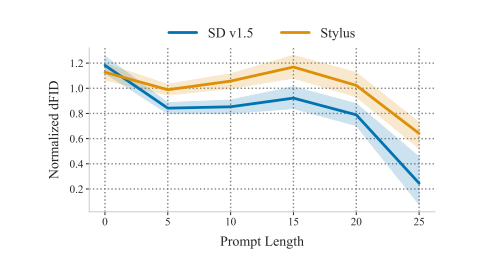
文章链接:
https://arxiv.org/pdf/2404.18928
4. What matters when building vision-language models?
对视觉-语言模型(VLMs)日益增长的兴趣主要是由于大型语言模型和视觉Transformer的改进。尽管关于这个主题的文献丰富,但作者观察到,在设计VLMs时,关键决策通常缺乏充分的理由支持。作者认为这些不受支持的决定妨碍了该领域的进展,因为这使得很难确定哪些选择能够提高模型的性能。为了解决这个问题,本文围绕预训练模型、架构选择、数据和训练方法进行了广泛的实验。研究结果包括Idefics2的开发,这是一个参数量为80亿的高效基础VLM。Idefics2在各种多模态基准测试中都达到了同类模型的最新性能水平,并且通常与其四倍大小的模型性能相媲美。

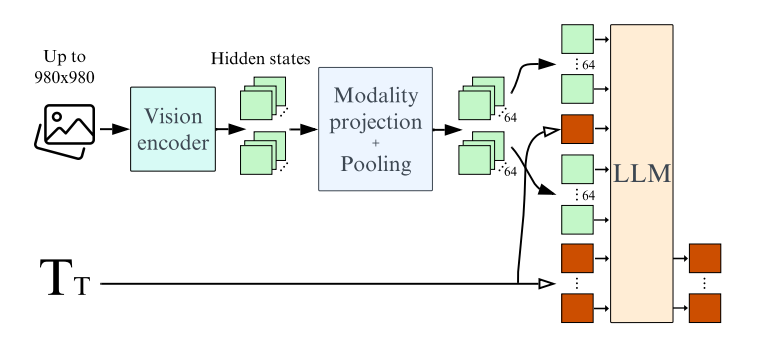
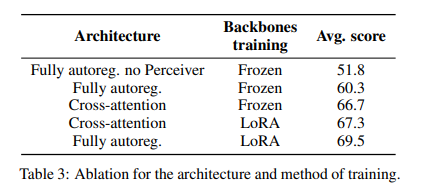
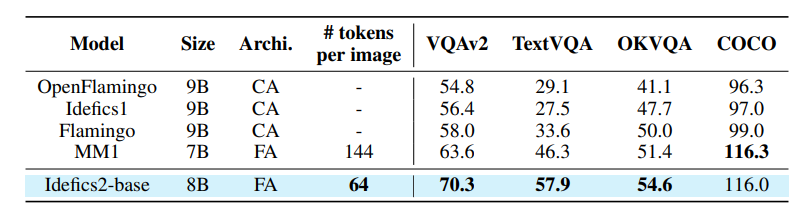

文章链接:
https://arxiv.org/pdf/2405.02246
5. Value Augmented Sampling for Language Model Alignment and Personalization
调整大型语言模型(LLMs)以满足不同的人类偏好、学习新技能和消除有害行为是一个重要问题。基于搜索的方法,如Best-of-N或蒙特卡洛树搜索,在性能上表现良好,但由于推理成本高,对LLM的调整不切实际。另一方面,使用强化学习(RL)进行调整在计算上效率高,但由于协同训练值函数和策略的优化挑战,表现较差。本文提出了一个新的奖励优化框架,称为Value Augmented Sampling(VAS),它可以使用仅来自初始冻结的LLM的样本数据来最大化不同的奖励函数。VAS解决了最大化奖励的最优策略,而无需同时训练策略和值函数的问题,使优化稳定,并在标准基准测试中胜过了已建立的基线,如PPO和DPO,并以更低的推理成本实现了与Best-of-128相当的结果。与现有的RL方法不同,需要改变LLM的权重,VAS不需要访问预训练LLM的权重。因此,它甚至可以调整LLMs(例如ChatGPT),这些模型仅以API的形式提供。此外,该算法解锁了在部署时组合多个奖励并控制每个奖励程度的新能力,为未来对齐、个性化的LLMs铺平了道路。
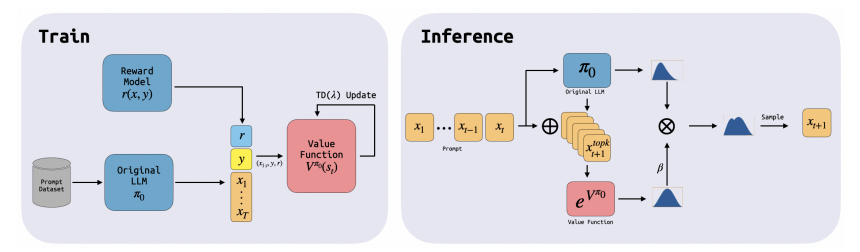

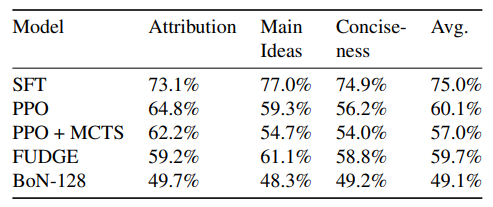

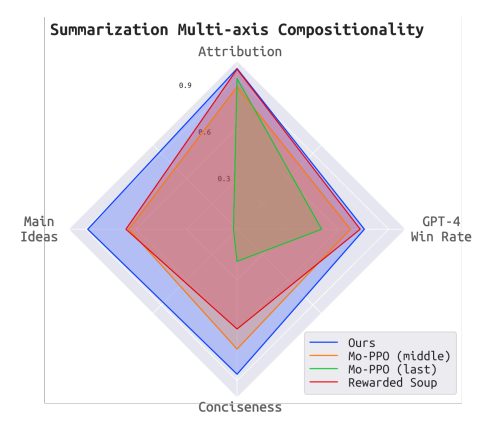
文章链接:
https://arxiv.org/abs/2405.06639
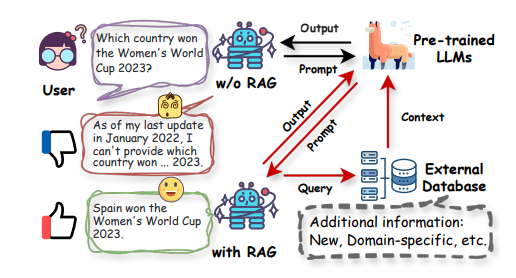
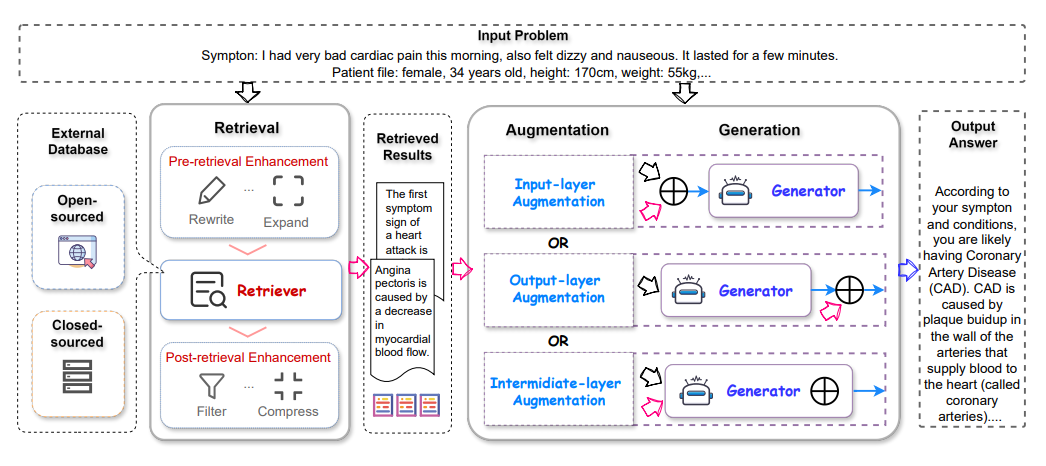
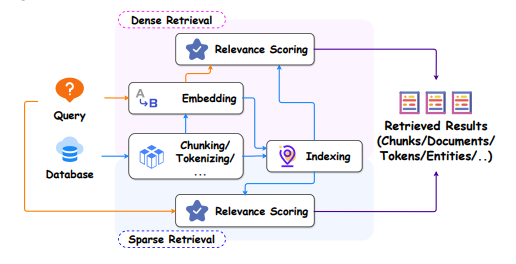
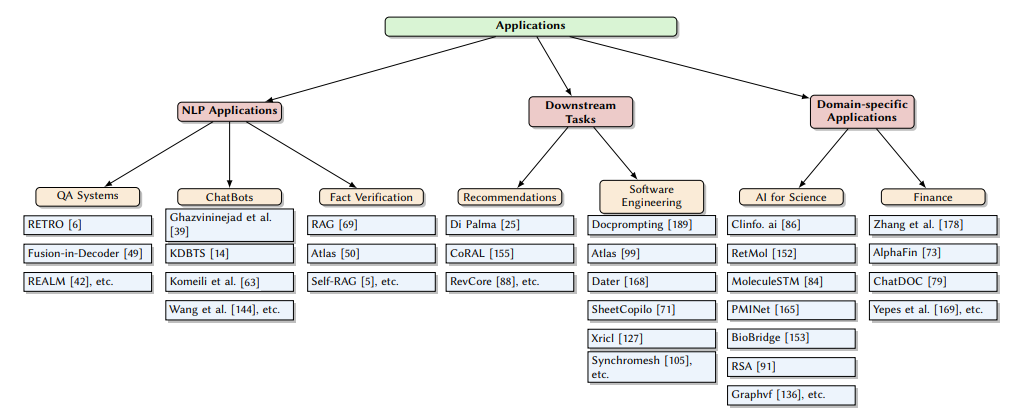
6.A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
作为人工智能中最先进的技术之一,检索增强生成(RAG)技术能够提供可靠且及时的外部知识,为众多任务提供了巨大的便利。特别是在人工智能生成内容(AIGC)时代,RAG在检索中提供额外知识的强大能力使得检索增强生成能够协助现有的生成式人工智能产生高质量的输出。最近,大型语言模型(LLMs)在语言理解和生成方面展示了革命性的能力,但仍然面临固有限制,如幻觉和过时的内部知识。鉴于RAG在提供最新和有用的辅助信息方面的强大能力,检索增强型大型语言模型已经出现,以利用外部和权威的知识库,而不是仅仅依赖模型的内部知识,来增强LLMs的生成质量。本调查全面审查了检索增强型大型语言模型(RA-LLMs)的现有研究,涵盖了三个主要的技术视角:架构、训练策略和应用。作为初步知识,作者简要介绍了LLMs的基础和最新进展。然后,为了说明RAG对LLMs的实际意义,作者按应用领域对主流相关工作进行了分类,具体详述了每个领域的挑战以及RA-LLMs的相应能力。最后,为了提供更深入的见解,作者讨论了目前的限制和未来研究的几个有希望的方向。

文章链接:
https://arxiv.org/pdf/2405.06211
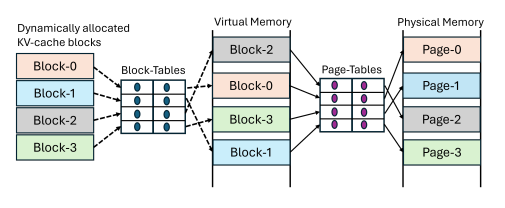
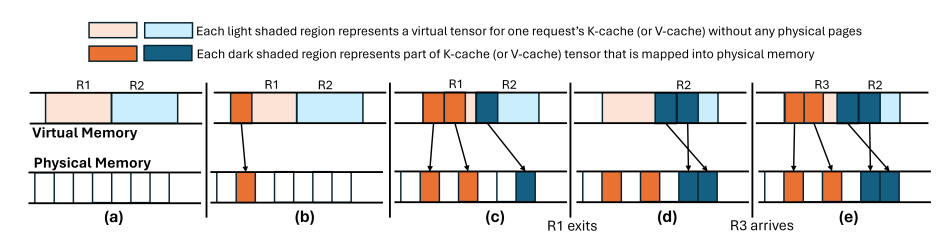
7. vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
对于高吞吐量的LLM推理,高效利用GPU内存至关重要。先前的系统提前为KV缓存保留内存,导致由于内部碎片而造成的资源浪费。受操作系统基于虚拟内存系统的启发,vLLM提出了PagedAttention,以实现对KV缓存的动态内存分配。这种方法消除了碎片,使得具有更大批处理大小的高吞吐量LLM服务成为可能。然而,为了能够动态分配物理内存,PagedAttention将KV缓存的布局从连续虚拟内存改变为非连续虚拟内存。这种改变需要重写注意力核心以支持分页,并且需要服务框架实现内存管理器。因此,PagedAttention模型导致了软件复杂性、可移植性问题、冗余和低效性。本文提出了用于动态KV缓存内存管理的vAttention。与PagedAttention相比,vAttention将KV缓存保留在连续虚拟内存中,并利用底层系统支持的按需分页,该支持已经存在,以实现按需分配物理内存。因此,vAttention使得注意力核心开发人员不再需要显式支持分页,并且避免了在服务框架中重新实现内存管理。本文展示了vAttention能够为各种注意力核心的不变实现提供无缝动态内存管理。vAttention生成的标记速度也比vLLM快高达1.97倍,同时处理输入提示的速度比FlashAttention和FlashInfer的PagedAttention变体快3.92倍和1.45倍。





文章链接:
https://arxiv.org/pdf/2405.04437
本期文章由陈研整理
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
欢迎讨论,期待你的
留言

点击 阅读原文 查看更多!
















 33
33











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









