






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者介绍
刘芳甫,清华大学博士生
内容简介
最近,通过利用2D和3D扩散模型,从文本提示创建3D内容取得了显著进展。虽然3D扩散模型确保了良好的几何一致性,但由于3D数据有限,其生成高质量和多样化3D内容的能力受到限制。相比之下,2D扩散模型通过一种提炼方法,在不使用任何3D数据的情况下实现了卓越的泛化能力和丰富的细节。然而,2D提升方法由于固有的视角不可知的模糊性,导致了严重的多面性问题,即文本提示无法提供足够的指导来学习一致的3D结果。我们没有重新训练一个昂贵的视点感知模型,而是研究如何充分利用易于获取的粗略3D先验知识来增强提示并引导2D提升优化进行细化。在本文中,我们提出了Sherpa3D,一个新的文本到3D框架,能够同时实现高保真度、通用性和几何一致性。具体而言,我们设计了一对指导策略,来自由3D扩散模型生成的粗略3D先验:几何保真度的结构指导和3D一致性的语义指导。通过采用这两种指导,2D扩散模型丰富了3D内容,产生了多样化和高质量的结果。大量实验证明了我们的Sherpa3D在质量和3D一致性方面优于最新的文本到3D方法。
论文地址:https://arxiv.org/pdf/2312.06655
代码地址:https://liuff19.github.io/Sherpa3D/
项目地址:https://jamesyjl.github.io/DreamReward/
01
Gallery of Sherpa3D
Sherpa3D 是一个全新的文本到3D生成框架。该框架能够在25分钟内生成高保真度、多样化且符合几何一致性的三维物体。相比于现有的方法,Sherpa3D在生成质量和时间上均有显著提升。
3D生成技术的发展历程可以从ICLR 2023年的DreamFusion开始,该方法在生成质量和时间效率上存在一定局限。随后在ICLR 2024年提出的SweetDreamer,虽然在生成质量上有所提升,但需要大量的3D数据进行训练。本文的研究表明,Sherpa3D的性能与SweetDreamer相当,但在时间效率上更具优势。
此外,ICLR 2024年的Dream Gaussian在生成速度上实现了突破,但其生成的纹理质量仍有提升空间。相比之下,Sherpa3D有效解决了现有方法中的诸多问题,并提出了一个全新的框架,显著提升了3D生成的质量和效率。

02
Background of 3D AIGC
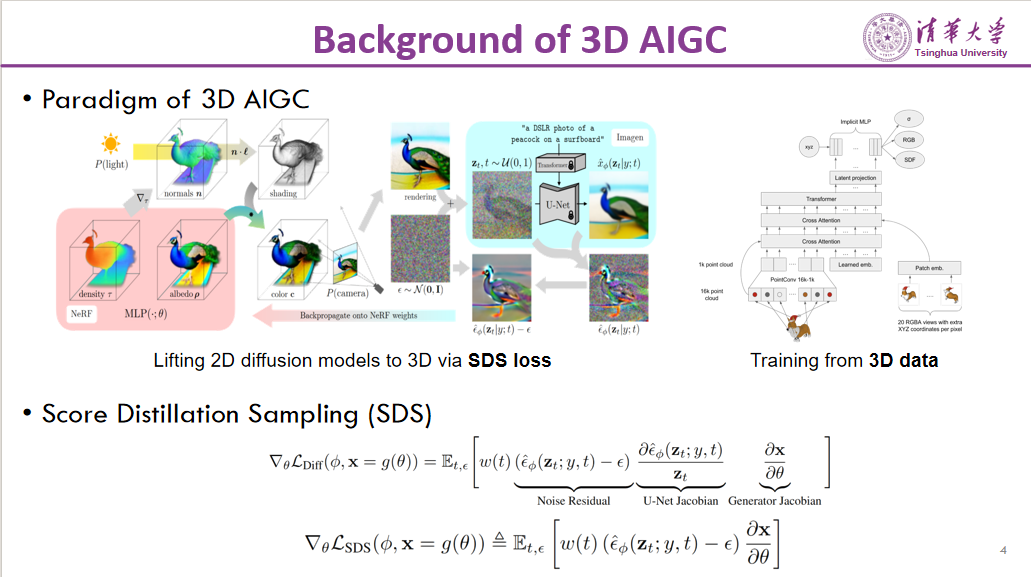
3D AIGC的发展分为两个主要范式。第一个范式以DreamFusion为代表,采用优化的方式。该方法旨在将2D扩散模型的能力提升到3D空间,通过SDS损失(Score Distillation Sampling loss)实现。具体来说,3D物体的每一个侧面都在2D世界中见到过,因此可以通过2D扩散模型来监督整个3D物体的生成。SDS的本质是将2D扩散模型的能力进行蒸馏,通过对损失函数直接求梯度的方式,监督3D物体的生成。
第二个范式是从合成数据进行训练,称为合成数据原生推理的方法。主要代表方法包括早期的CP、PointE以及近期利用ObjectVerse训练多视图数据的生成方法。
03
Motivation
本文的研究动机在于分析现有的2D和3D扩散模型,即前面提到的两种范式。2D扩散模型的优势在于其训练数据集非常丰富,2D图像数量庞大,具备很强的泛化能力,能够生成细节丰富的图像。然而,2D扩散模型的局限在于其仅见过2D图像,而且2D图像数据集存在长尾分布问题,例如正面图像远多于背面图像,导致其缺乏3D先验,容易出现多面(multi-face)问题,例如DreamFusion生成的图像可能正面和背面都有脸。
相比之下,3D扩散模型因为直接使用3D数据进行训练,具备很好的多视角一致性,不会出现多面的问题。但其不足在于3D数据相对于2D数据量非常少,导致模型的质量和泛化能力较差。
因此,该研究的目标是同时解决上述问题,提出一个质量高、泛化性好,并且能够保证几何一致性的模型。

04
Method Overview
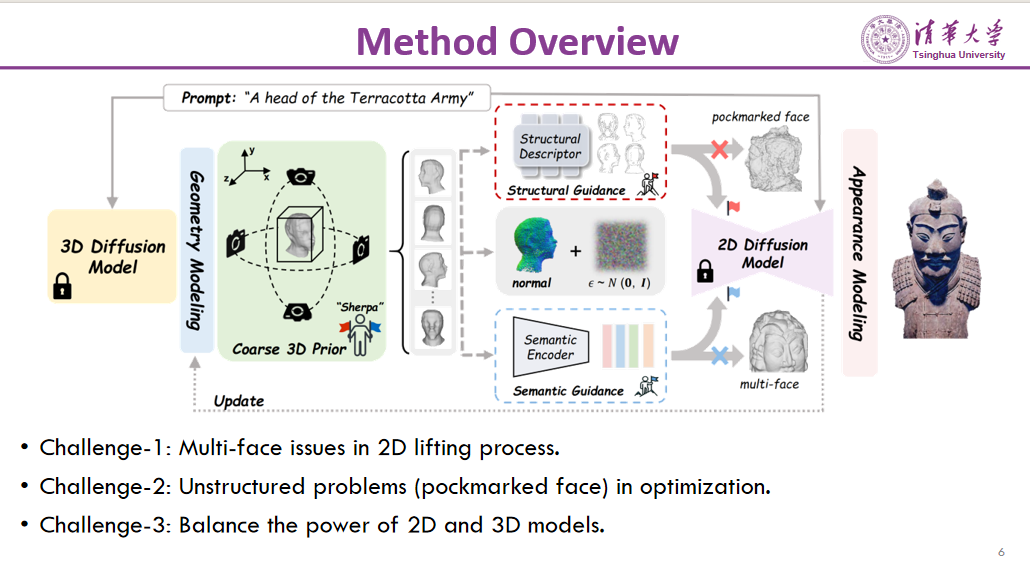
作者提出了Sherpa3D框架。Sherpa意指喜马拉雅山的向导,引导登山者攀登高峰。类似地,本文所提框架引导2D扩散模型逐步优化,最终生成高质量且具备3D一致性的模型。
首先,需要解决以下三个挑战。第一个挑战是在2D转3D的过程中,容易出现多个面部的情况。第二个挑战是仅使用2D扩散模型时,可能生成的几何结构不稳定。第三个挑战是引入3D扩散模型作为先验时,需要平衡2D和3D扩散模型在整个优化过程中的作用权重。
为了解决这些挑战,本文方法如下。首先通过3D扩散模型生成一个粗略的3D先验,然后将3D先验投影成不同的侧面图像。接着,使用结构引导和语义引导来辅助2D提升过程。结构引导利用3D先验引导后续的2D提升过程,避免出现结构不良的几何现象;语义引导则通过3D先验提供正面、背面和侧面的语义信息,从而缓解多面问题。最后,作者提出了一个分步退火策略(Step Annealing Strategy),在整个优化过程中平衡2D和3D扩散模型的作用。
Method in detail
在该方法中,作者首先讨论了哪些知识可以作为优化过程的引导。通过实验,作者发现几何不一致性是导致3D性能不佳的一个主要原因。因此,优化过程主要集中在几何优化上的设计和改进。
首先,在结构引导方面,为了保留粗略3D先验的结构,本文采用了一个简单的边缘提取算子来描述其轮廓。这使得在后续的优化过程中,生成的3D形状能够与初始的3D形状保持几何大小的一致,避免几何结构出现问题。
其次,在语义引导方面,作者通过约束语义一致性来避免多面问题。这样可以确保生成的3D物体在不同视角下具有一致的外观。
第三,本文引入了一个分步退火策略(step annealing strategy)来平衡2D和3D优化的作用。如果没有分步退火,3D扩散模型可能会过度发挥作用,从而导致生成的细节不足。因此,通过分步退火策略,就能够在优化过程中适当调整2D和3D扩散模型的作用权重,保证生成结果的细节和一致性。
最后,文中的优化是在几何空间进行的,而不是在RGB空间。具体来说,通过对法线向量进行SDS优化。在早些时候的SCP 2023和Fantasia 3D研究中,已经证明了这种方法的有效性。Stable diffusion使用的训练数据中包含了一部分法线数据,因此可以很快地对SDS进行收敛。

05
Visualization
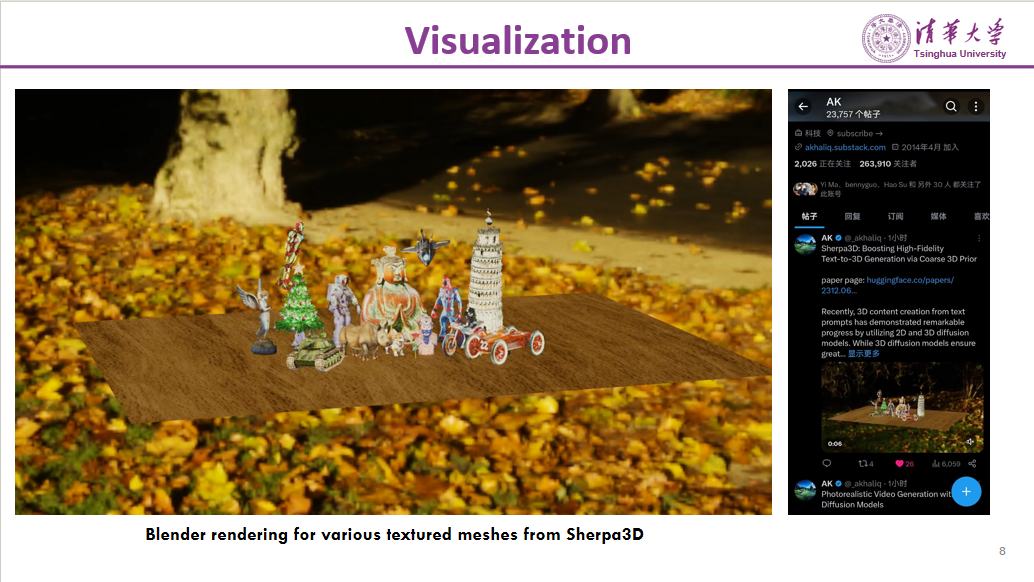
以下是生成的一个模型的可视化结果,这是使用Blender进行渲染的。
06
Experiment Results
以下是更多的实验结果。可以看到,早期的方法如CPE尽管在3D一致性上表现良好,但生成的质量非常粗糙。DreamFusion、Magic3D、Fantasia3D和ProlificDreamer等方法在生成时间上都非常长,并且经常出现多脸和多头的问题,质量也较差。
相比之下,本文方法在解决多面问题上表现出色。最左边的结果是Sherpa3D生成的3D模型,显示出Sherpa3D不仅有效解决了多面问题,还在质量和逼真度上达到了更高水平,生成的3D模型更加真实可信。

More Experiment Results
进一步的实验结果表明,在CLIP上的验证中,Sherpa3D表现出最高的性能。此外,用户研究也显示,Sherpa3D更受大众欢迎。
值得一提的是,由于Sherpa3D仅在几何空间进行优化,因此可以充分发挥Stable Diffusion的上色能力和泛化能力。在整个优化过程中,不会改变Stable Diffusion的特性,这使得Sherpa3D在生成质量上优于直接使用3D数据训练的模型。例如,ObjectVerse和MV-Dream等方法可能会过拟合到特定的数据集颜色空间,而Sherpa3D则能够避免这种情况。
此外,Sherpa3D在解决OOD(Out-of-Distribution)现象时表现出色。无论是生成多样化和具有高度泛化能力的提示,还是进行简单的编辑操作(如只改变纹理而不改变几何结构),Sherpa3D都能很好地完成任务。

07
Zero-shot 3D Generation
下面展示了Sherpa3D在零样本(zero-shot)3D生成任务中的结果。可以看到,Sherpa3D在3D一致性和纹理质量方面表现出色。生成的3D模型不仅具备高度的几何一致性,还在纹理细节上保持了很高的质量。

08
Future Work
Subject-Driven 3D Generation:Make-Your-3D
未来工作包括一个以主体为驱动的3D生成(subject-driven 3D generation)。当前的3D生成大多数是基于给定的文本或图片生成一个3D物体,而这篇文章提出了一种新方法,即只需提供一张图片并添加一些文本提示,就可以在保持主体特征不变的情况下,为其添加帽子、墨镜等配件。例如,我们可以让格鲁特坐着或者穿上制服。这实际上是一种定制化的过程。
该方法只需五分钟内就可以生成,有些案例甚至可以在几十秒内完成。此外,还可以对人物风格进行修改,比如让奥巴马穿上不同的衣服,这都是定制化生成的表现。这是在后期进行的主体驱动的3D生成工作。具体工作参见:https://liuff19.github.io/Make-Your-3D/

Human Preference Alignment:DreamReward
另一个未来工作是解决当前3D生成与人类偏好不对齐的问题。研究发现,目前的3D生成模型在理解文本提示的语义方面存在局限。例如,当我们希望给自行车添加花篮装饰时,使用MV-Dream等3D数据训练的模型可能无法很好地理解这一文本提示的语义。类似地,对于“狮子在阳光下”这样的提示,模型可能无法捕捉到其中的语义信息。
为了解决这一问题,本文采用了ILHF(Instruction Learning from Human Feedback)的方法,使人类偏好与3D生成模型实现一定程度的对齐。右侧展示的结果表明,所提方法在这一方面取得了显著的进展,生成的3D模型与文本提示产生了更好的对齐效果。具体工作参见:https://jamesyjl.github.io/DreamReward/

本篇文章由陈研整理
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看讲者精彩回放!
















 52
52

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









