






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Music2P: A Multi-Modal AI-Driven Tool for Simplifying Album Cover Design
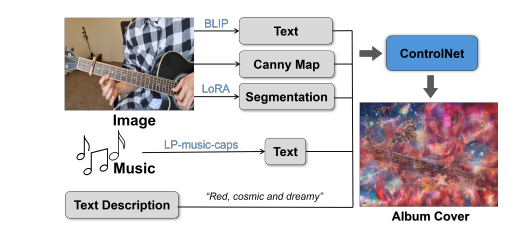
在当今的音乐产业中,专辑封面设计与音乐本身同样重要,反映了艺术家的愿景和品牌。然而,许多由人工智能驱动的专辑封面服务需要订阅或技术专长,限制了其可访问性。为了解决这些挑战,开发了Music2P,这是一款开源的多模态人工智能工具,通过Ngrok简化了专辑封面制作过程,使其高效、易于访问且具有成本效益。Music2P通过使用诸如Bootstrapping Language Image Pre-training (BLIP)、音乐转文本(LP-musiccaps)、图像分割(LoRA)以及专辑封面与二维码生成(ControlNet)等技术,自动化了设计过程。本文展示了Music2P的界面,详细说明了这些技术的应用,并概述了未来的改进方向。其最终目标是提供一个工具,使音乐家和制作人,尤其是那些资源或专业知识有限的人,能够创建引人注目的专辑封面。



文章链接:
https://arxiv.org/pdf/2408.01651
02
Optimus: Accelerating Large-Scale Multi-Modal LLM Training by Bubble Exploitation
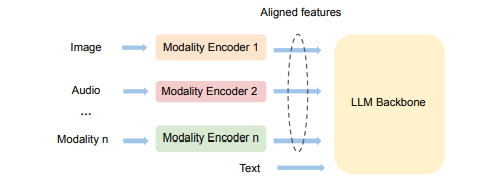
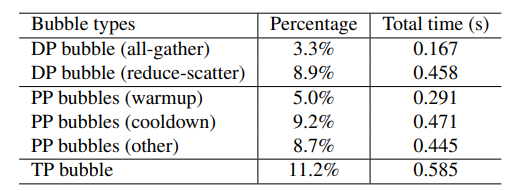
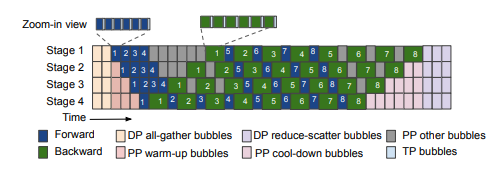
多模态大语言模型 (MLLMs) 已将大语言模型 (LLMs) 的成功扩展到图像、文本和音频等多种数据类型,在多模态翻译、视觉问答和内容生成等多个领域取得了显著的性能。然而,由于异构模态模型和3D并行中的复杂数据依赖性,现有系统在训练MLLMs时效率较低,导致大量GPU气泡。本文提出了一种名为Optimus的分布式MLLM训练系统,旨在减少端到端MLLM的训练时间。Optimus基于对LLM气泡内调度编码器计算的系统性分析,能够减少MLLM训练中的气泡。为使所有GPU都能进行编码器计算调度,Optimus为编码器和LLM分别搜索并行方案,并采用气泡调度算法,在不破坏MLLM模型架构原始数据依赖性的情况下利用LLM气泡。作者进一步将编码器层的计算分解为一系列内核,并分析了3D并行的常见气泡模式,以精细优化亚毫秒级气泡调度,最大限度地缩短整体训练时间。在生产集群中的实验表明,与基线相比,Optimus在使用3072个GPU进行ViT-22B和GPT-175B模型训练时,能将MLLM训练速度提高20.5%-21.3%。
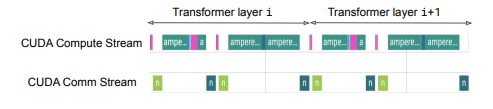
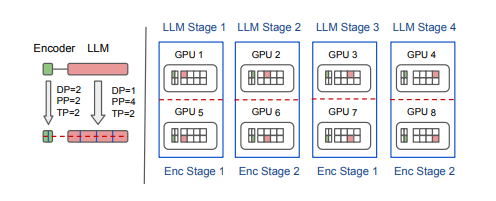
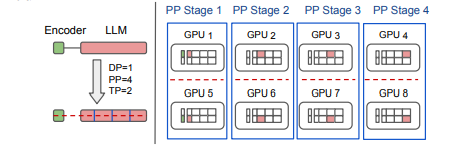
文章链接:
https://arxiv.org/pdf/2408.03505
03
FANNO: Augmenting High-Quality Instruction Data with Open-Sourced LLMs Only
指令微调是利用大语言模型(LLMs)提升任务性能的重要进展。然而,指令数据集的标注通常昂贵且费时,往往依赖于手工标注或高成本的专有LLM API调用。为了解决这些问题,本文介绍了FANNO,这是一种完全自主的开源框架,通过无需预先存在的标注数据,彻底革新了标注过程。FANNO利用Mistral-7b-instruct模型,通过文档预筛选、指令生成和响应生成等结构化过程,高效地产生多样且高质量的数据集。实验结果显示,在Open LLM Leaderboard和AlpacaEval基准上,FANNO生成的高质量数据在多样性和复杂性上可与人工标注或清洗后的数据集(如Alpaca-GPT4-Cleaned)相媲美,而且是免费的。
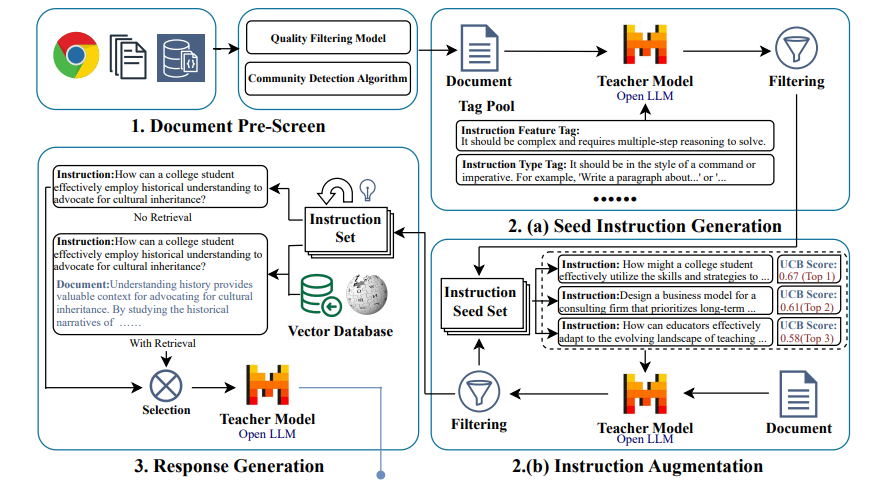
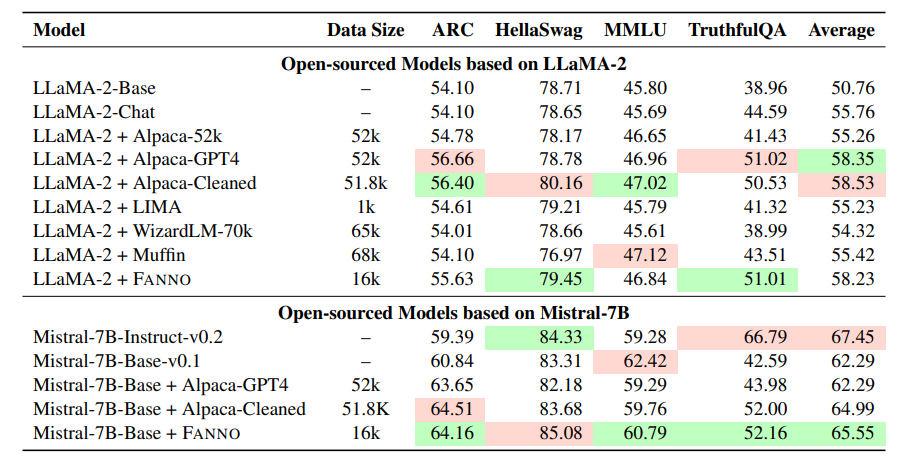
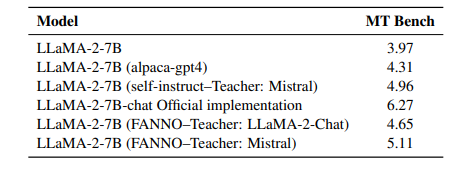
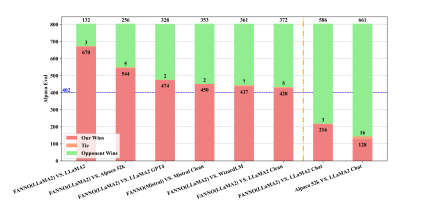
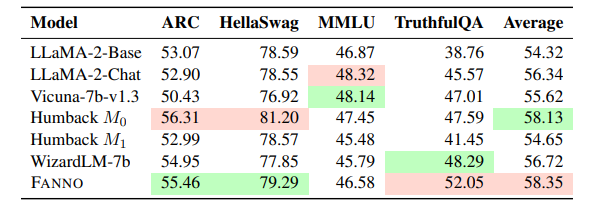
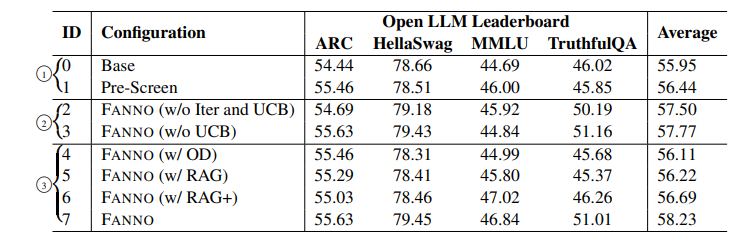
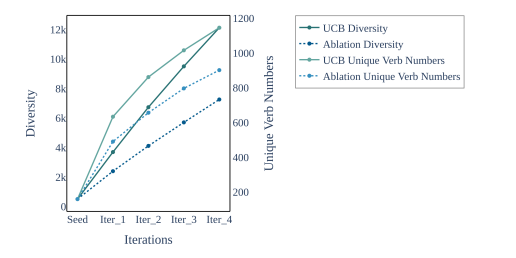
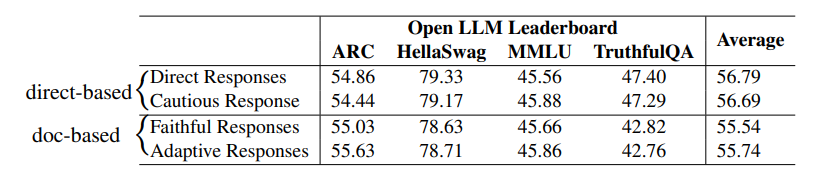
文章链接:
https://arxiv.org/pdf/2408.01323
04
Open-domain Implicit Format Control for Large Language Model Generation
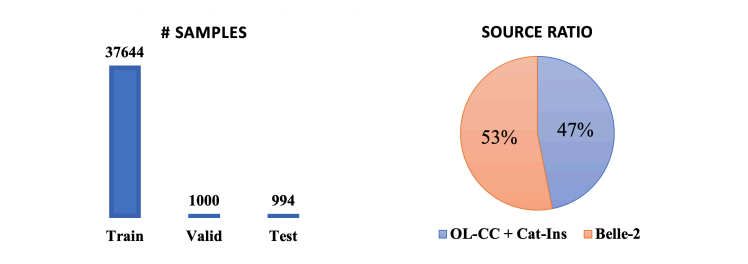
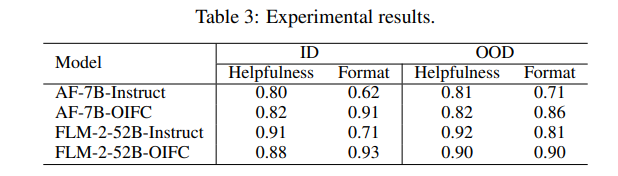
控制大语言模型(LLMs)生成输出的格式在各种应用中是关键功能。目前的方法通常采用基于规则的自动机约束解码或通过手工制作的格式指令进行微调,但这些方法在开放域的格式要求下表现不佳。为了解决这一限制,本文提出了一种新的框架,通过用户提供的一次性问答对,进行LLMs的受控生成。本研究探讨了LLMs在遵循开放域的一次性约束并复制示例答案格式方面的能力。这对于现有的LLMs来说是一个非凡的挑战。作者还开发了一种数据集收集方法用于监督微调,以增强LLMs在开放域格式控制中的能力,同时不降低输出质量,并提出了一个基准,用于评估LLMs输出的有用性和格式正确性。最终生成的数据集被命名为OIFC-SFT。
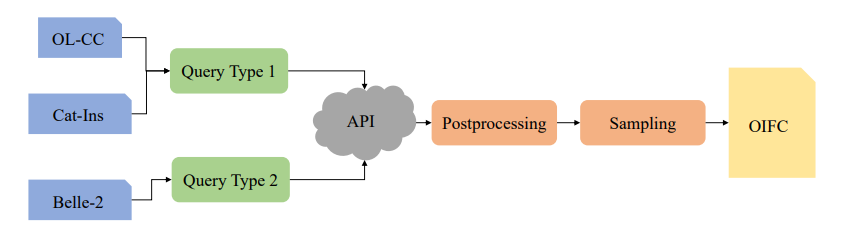

文章链接:
https://arxiv.org/pdf/2408.04392
05
Addressing Model and Data Heterogeneity in Multimodal Large Language Model Training
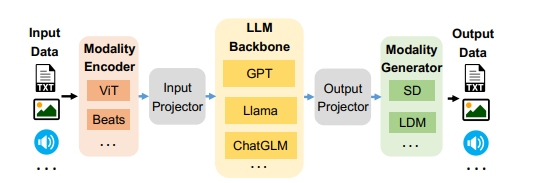
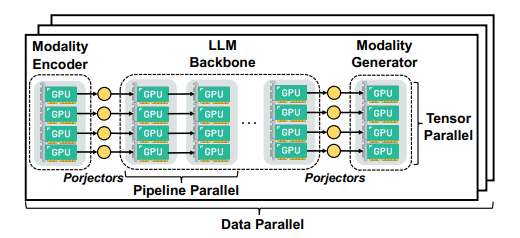
多模态大语言模型(LLMs)在广泛的人工智能应用中展示了显著的潜力。然而,由于模型异质性和不同模态之间的数据异质性,训练多模态LLMs的效率和可扩展性较低。本文提出了DistTrain,这是一种高效且适应性强的框架,用于在大规模集群上改革多模态大语言模型的训练。DistTrain的核心是分解训练技术,它利用多模态LLM训练的特点,以实现高效性和可扩展性。具体而言,它通过分解模型调度和分解数据重排序,分别解决模型和数据的异质性。本文还针对多模态LLM训练优化了系统,以重叠GPU通信和计算。作者在具有数千个GPU的大规模生产集群上评估了DistTrain。实验结果表明,在1172个GPU上训练一个72B的多模态LLM时,DistTrain达到了54.7%的模型FLOPs利用率(MFU),并且在吞吐量方面比Megatron-LM提高了最多2.2倍。消融研究表明,DistTrain的主要技术既有效又轻量。
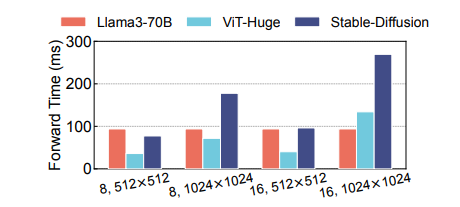
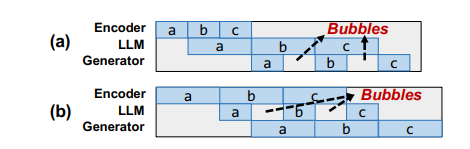
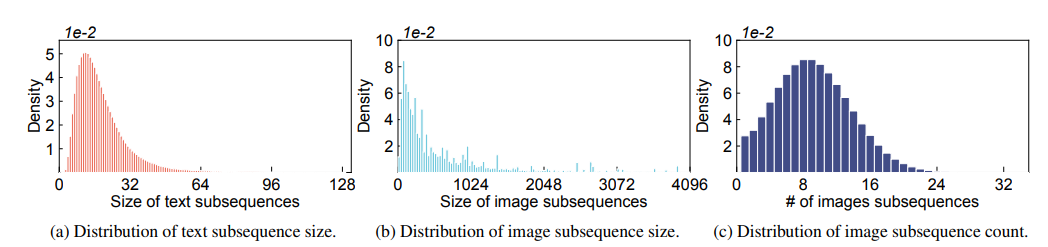


文章链接:
https://arxiv.org/pdf/2408.04275
06
Semantic Skill Grounding for Embodied Instruction-Following in Cross-Domain Environments
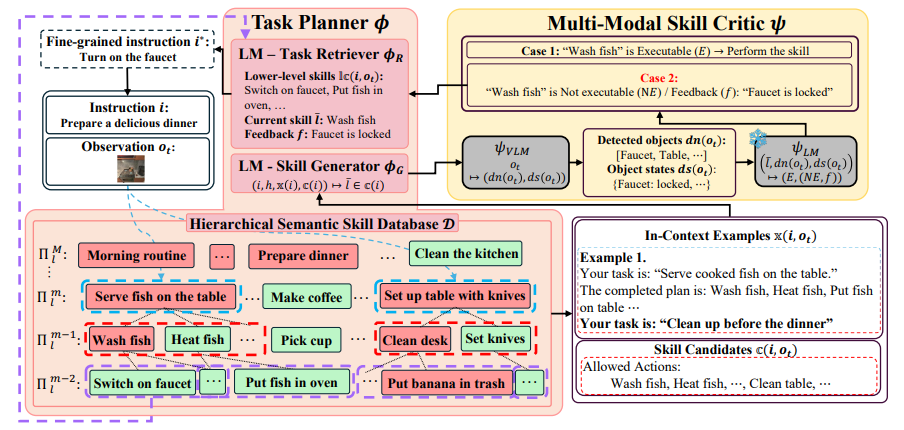
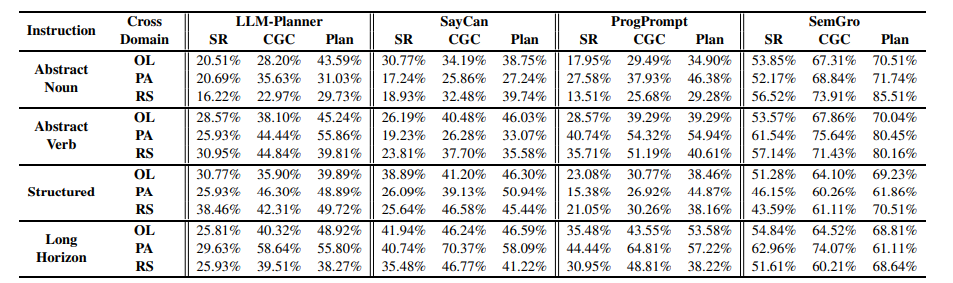
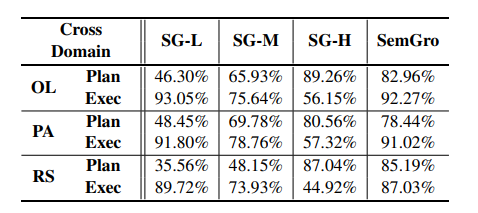
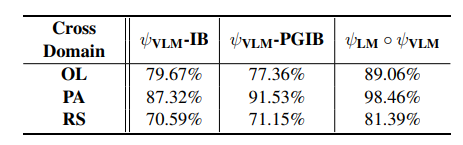
在具身指令跟随(EIF)中,将预训练语言模型(LMs)作为任务规划者的整合成为一个重要分支,其中任务是通过提供预训练技能和用户指令来按技能级别进行规划。然而,将这些预训练技能在不同领域中进行基础化仍然具有挑战性,因为它们与领域特定知识的复杂纠缠。为了解决这一挑战,本文提出了语义技能基础化(SemGro)框架,该框架利用语义技能的层次结构。SemGro认识到这些技能的广泛范围,从短期低语义技能(在各个领域中普遍适用)到长期丰富语义技能(高度专业化且针对特定领域量身定制)。该框架采用一种迭代的技能分解方法,从语义技能层次结构的较高层次开始,然后逐步向下,旨在将每个规划的技能基础化到目标领域内可执行的水平。为此,作者利用LMs的推理能力进行语义技能的组合和分解,以及其多模态扩展来评估技能在目标领域的可行性。在VirtualHome基准上的实验显示,SemGro在300个跨领域EIF场景中的有效性。
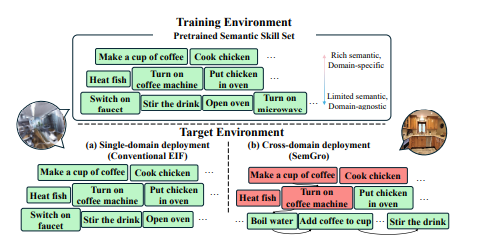

文章链接:
https://arxiv.org/pdf/2408.01024
07
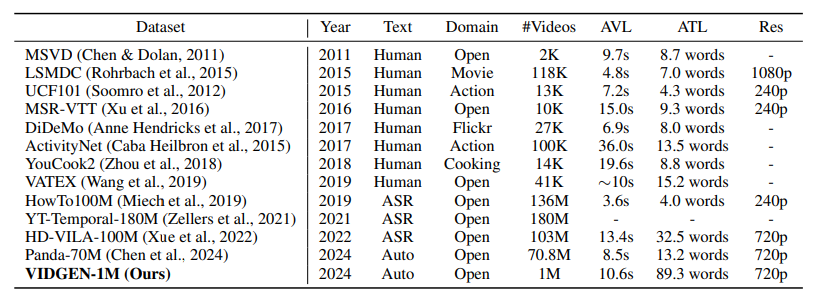
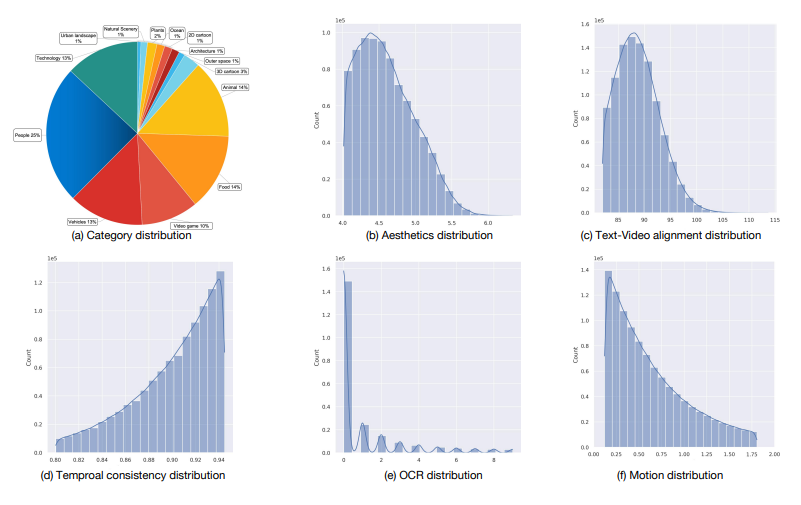
VidGen-1M: A Large-Scale Dataset for Text-to-video Generation
视频-文本对的质量在根本上决定了文本到视频模型的上限。目前,用于训练这些模型的数据集存在显著缺陷,包括时间一致性差、字幕质量差、视频质量低下以及数据分布不平衡。现有的视频策展过程依赖于图像模型进行标记和手工规则驱动的策展,导致了高计算负载,并留下了未清理的数据。因此,缺乏适合训练文本到视频模型的合适数据集。为了解决这个问题,本文提出了VidGen-1M,这是一种优质的文本到视频模型训练数据集。通过粗到细的策展策略生成,该数据集保证了高质量的视频和详细的字幕,同时具备卓越的时间一致性。在用于训练视频生成模型时,该数据集的实验结果超越了其他模型的表现。


文章链接:
https://arxiv.org/pdf/2408.02629
本期文章由陈研整理
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!
















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









