






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Farewell to Length Extrapolation, a Training-Free Infinite Context with Finite Attention Scope
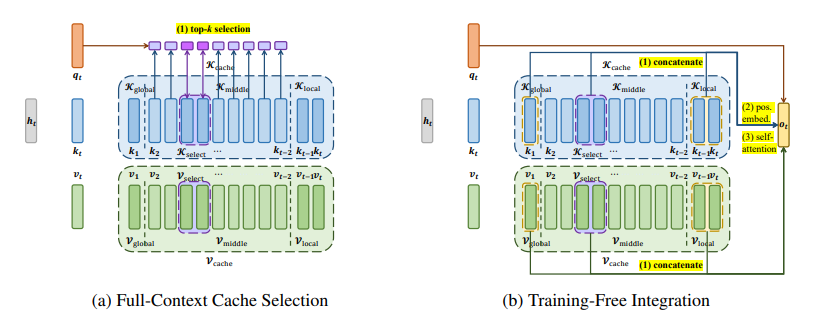
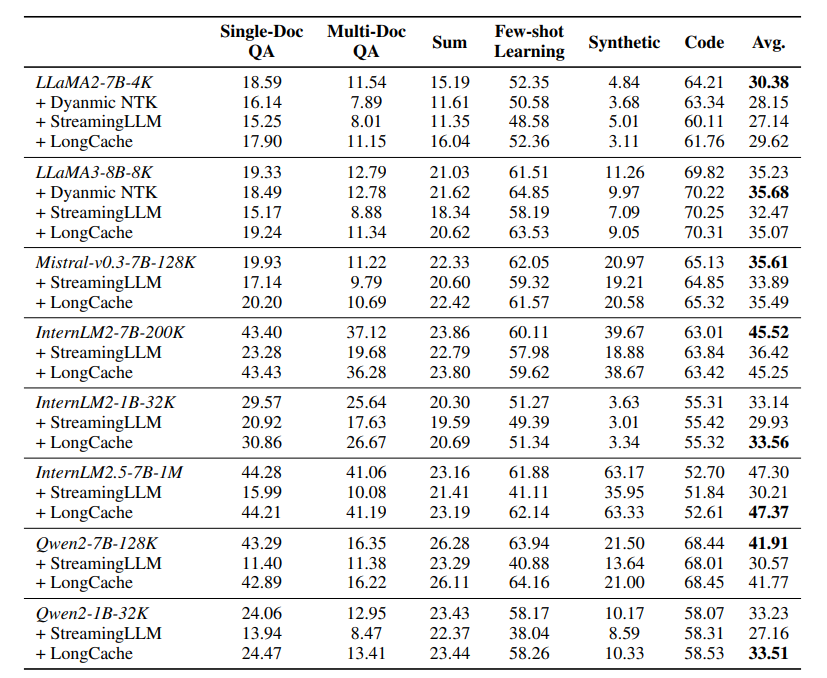
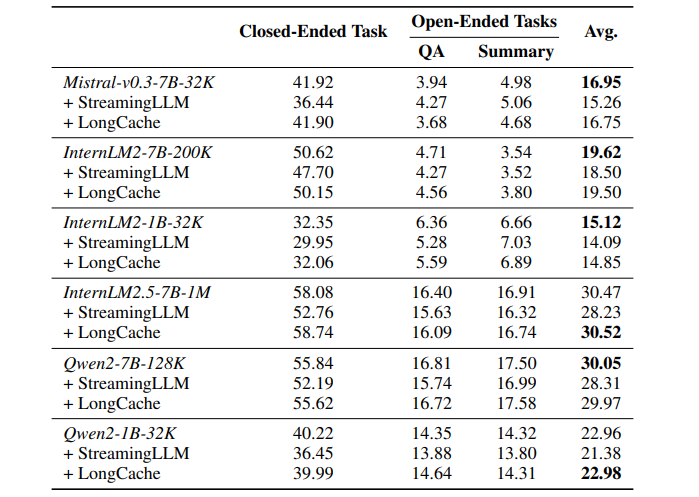
最大支持的上下文长度是限制大型语言模型(LLM)实际应用的一个关键瓶颈。尽管现有的长度扩展方法可以将LLMs的上下文扩展到数百万令牌,但这些方法都有明确的上限。这项工作提出了LongCache,这是一种无需训练的方法,它通过全上下文缓存选择和无需训练的集成,使LLM能够支持无限上下文,但具有有限的上下文范围。这有效地使LLM摆脱了长度扩展问题。作者在LongBench和L-Eval上验证了LongCache,并展示了其性能与传统的全注意力机制相当。此外,本文已经将LongCache应用于主流LLMs,包括LLaMA3和Mistral-v0.3,使它们能够在“海中寻针”测试中支持至少400K的上下文长度。作者表示很快将通过GPU感知优化提高LongCache的效率。
文章链接:
https://arxiv.org/pdf/2407.15176
02
RazorAttention: Efficient KV Cache Compression Through Retrieval Heads
键值(KV)缓存的内存和计算需求对于部署长上下文语言模型提出了重大挑战。以往的方法尝试通过选择性丢弃令牌来缓解这个问题,这会不可逆转地擦除未来查询可能需要的关键信息。本文提出了一种新颖的KV缓存压缩技术,该技术保留了所有令牌信息。调查揭示了:i) 大多数注意力头主要关注局部上下文;ii) 只有少数头,被称为检索头,基本上可以关注所有输入令牌。这些关键观察结果激励作者为注意力头使用单独的缓存策略。因此,本文提出了RazorAttention,这是一种无需训练的KV缓存压缩算法,它为这些关键的检索头维护完整缓存,并在非检索头中丢弃远程令牌。此外,本文引入了一种涉及“补偿令牌”的新颖机制,以进一步恢复被丢弃令牌中的信息。在多种大型语言模型(LLMs)上的广泛评估表明,RazorAttention在不显著影响性能的情况下,实现了KV缓存大小超过70%的减少。此外,RazorAttention与FlashAttention兼容,使其成为一种高效且即插即用的解决方案,无需额外开销或重新训练原始模型,就能提高LLM推理效率。
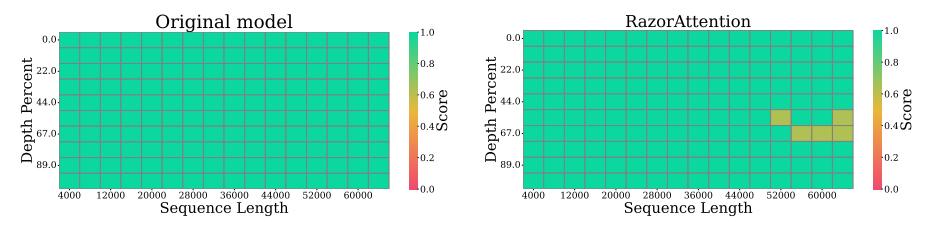
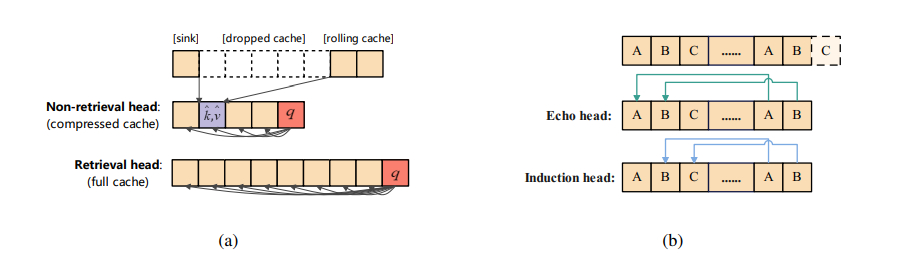

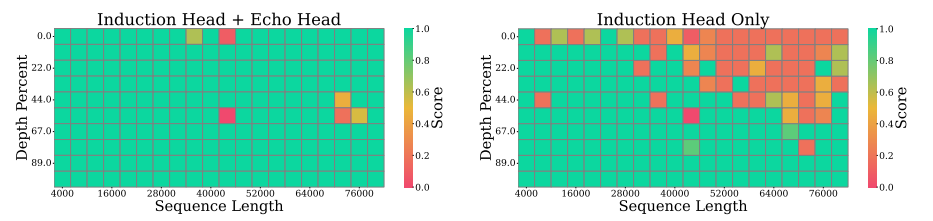
文章链接:
https://arxiv.org/pdf/2407.15891
03
TAGCOS: Task-agnostic Gradient Clustered Coreset Selection for Instruction Tuning Data
指令调整在NLP领域取得了前所未有的成功,将大型语言模型转变为多功能聊天机器人。然而,指令数据集的日益增多和多样化对计算资源提出了巨大需求。为了解决这个问题,提取一个小型且信息量高的子集(即核心集)以实现与完整数据集相当的性能至关重要。实现这一目标面临着非平凡的挑战:1) 数据选择需要准确的数据表示,以反映训练样本的质量;2) 考虑到指令数据集的多样性;3) 确保核心集选择算法对于大型模型的效率。为了应对这些挑战,本文提出了任务不可知梯度聚类核心集选择(TAGCOS)。具体来说,本文利用样本梯度作为数据表示,执行聚类以分组相似数据,并应用高效的贪婪算法进行核心集选择。实验结果表明,该算法仅选择5%的数据,在其他无监督方法中脱颖而出,并实现了接近完整数据集的性能。
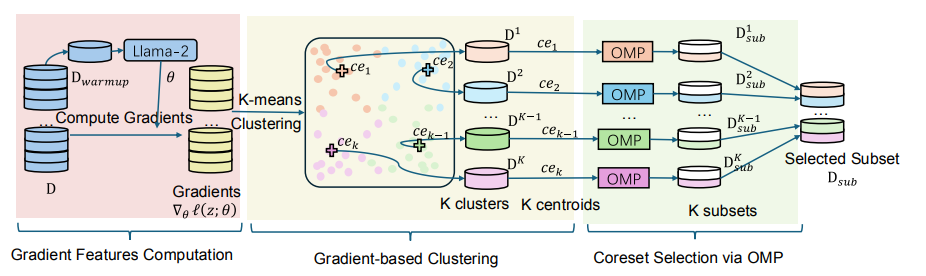


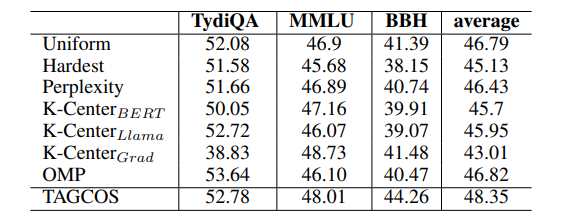
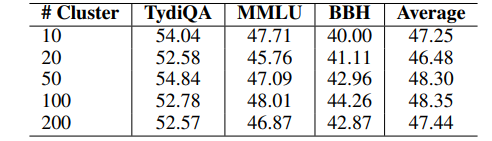
文章链接:
https://arxiv.org/pdf/2407.15235
04
MINI-SEQUENCE TRANSFORMER: Optimizing Intermediate Memory for Long Sequences Training
本文介绍了小型序列变换器(MST),这是一种简单而有效的方法,用于在极长序列上进行高度高效和准确的LLM训练。MST将输入序列分区,并迭代处理小序列以减少中间内存使用。结合激活重计算,它在前向和后向传递中都能实现显著的内存节省。在Llama3-8B模型的实验中,由于内存优化,即使使用比标准实现长12倍的序列,作者测量到吞吐量或收敛性没有下降。MST是完全通用的,与实现无关,并且只需要最小的代码更改即可与现有的LLM训练框架集成。
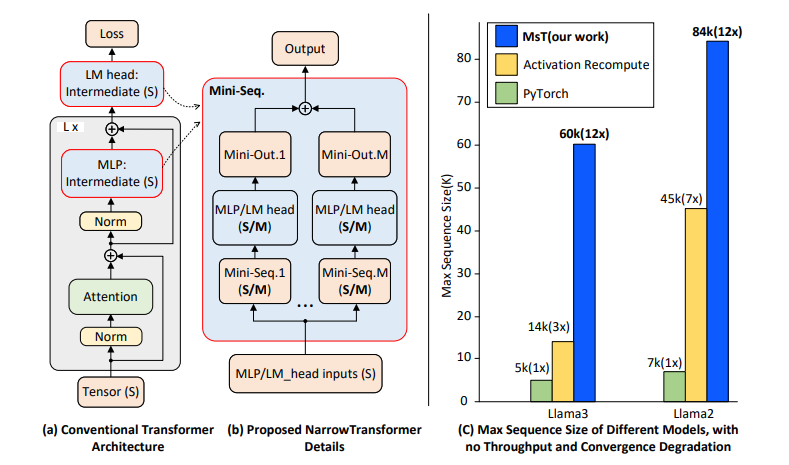



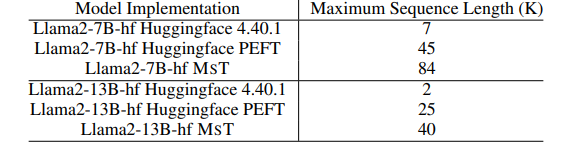
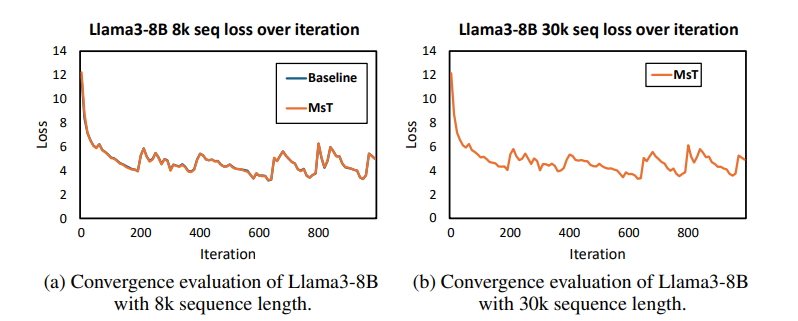
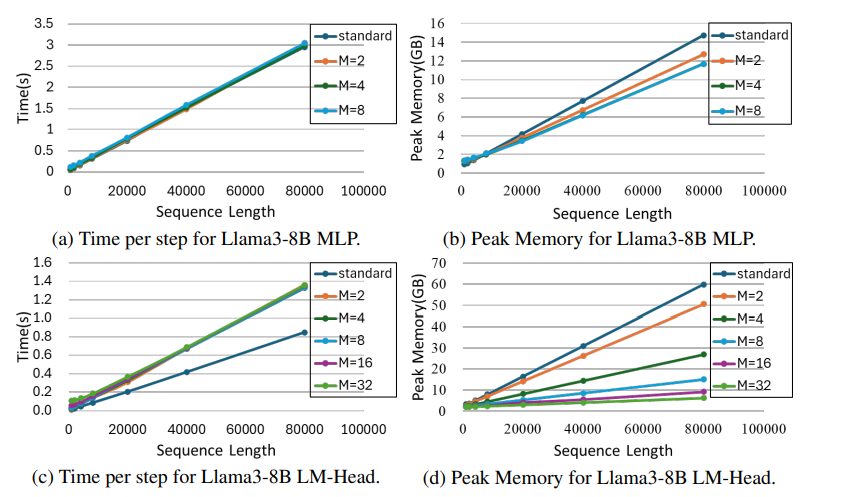
文章链接:
https://arxiv.org/pdf/2407.15892
05
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
尽管大型语言模型(LLMs)在现实世界应用中已经证明了其效用,但人们对于它们如何利用大规模预训练文本语料库来实现这些能力仍然缺乏了解。这项工作通过对他们的预训练数据进行全面的n-gram分析,研究了大规模预训练LLMs中泛化和记忆之间的相互作用。文中的实验集中在三种通用任务类型:翻译、问答和多项选择推理。使用各种大小的开源LLMs及其预训练语料库,作者观察到随着模型大小的增加,与任务相关的n-gram对数据变得越来越重要,这导致了任务性能的提高、记忆的减少、泛化的增强和能力的出现。实验结果支持了这样的假设:LLMs的能力来自于足够的与任务相关的预训练数据中记忆和泛化之间微妙的平衡,并且为更大规模的分析指明了方向,这些分析可以进一步提高对这些模型的理解。
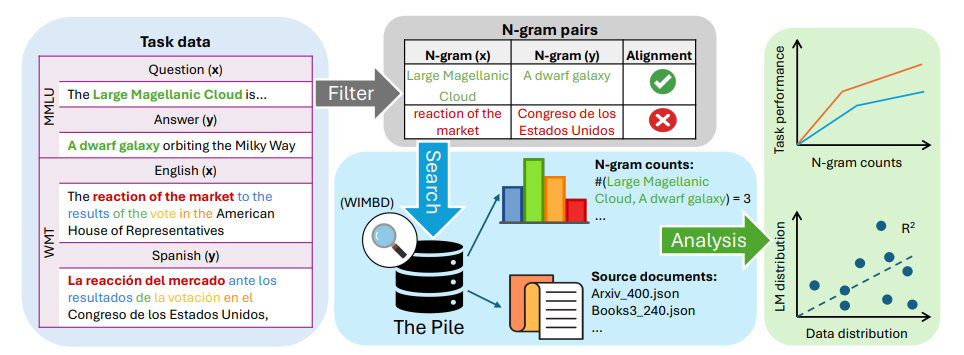
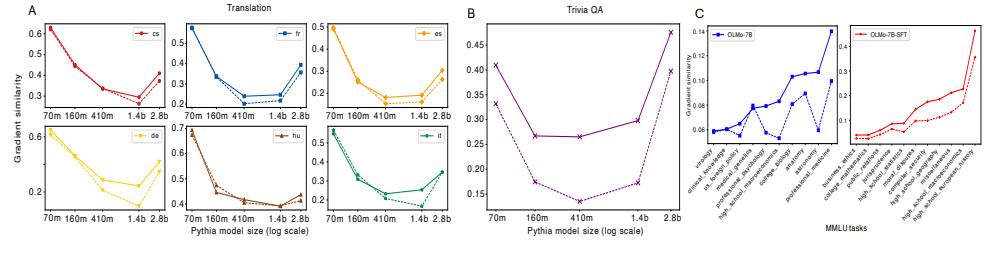
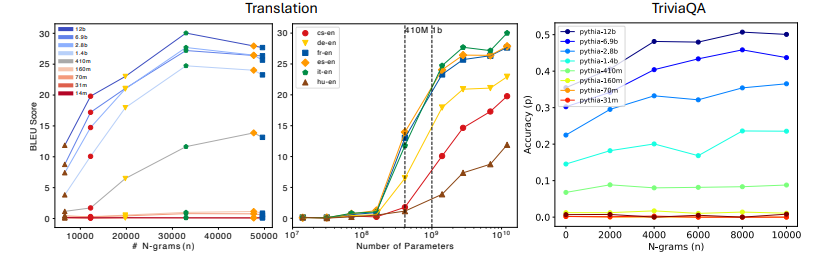
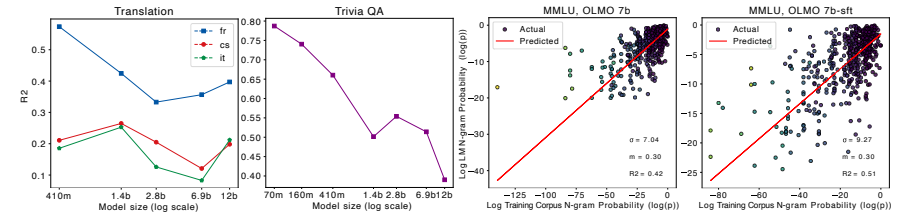
文章链接:
https://arxiv.org/pdf/2407.14985
06
ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
本文介绍了ChatQA 2,这是一个基于Llama3的模型,旨在弥合开放获取的大型语言模型(LLMs)与领先的专有模型(例如GPT-4-Turbo)在长上下文理解和增强检索生成(RAG)能力方面的差距。这两种能力对于LLMs处理无法适应单个提示的大量信息至关重要,并且它们互补,取决于下游任务和计算预算。作者提出了一个详细的继续训练方法,将Llama3-70B-base的上下文窗口从8K扩展到128Ktokens,并结合了一个三阶段的指令调整过程,以增强模型的指令遵循、RAG性能和长上下文理解能力。结果表明,Llama3-ChatQA-2-70B模型在许多长上下文理解任务上的准确性与GPT-4-Turbo2024-0409相当,并在RAG基准测试中超越了它。有趣的是,作者发现长上下文检索器可以缓解RAG中的top-k上下文碎片化问题,进一步提高基于RAG的长上下文理解任务的结果。本文还提供了使用最先进长上下文LLMs的RAG和长上下文解决方案之间的广泛比较。
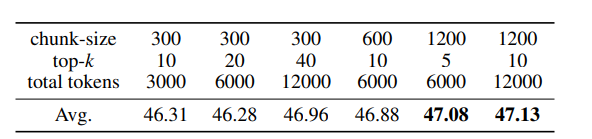
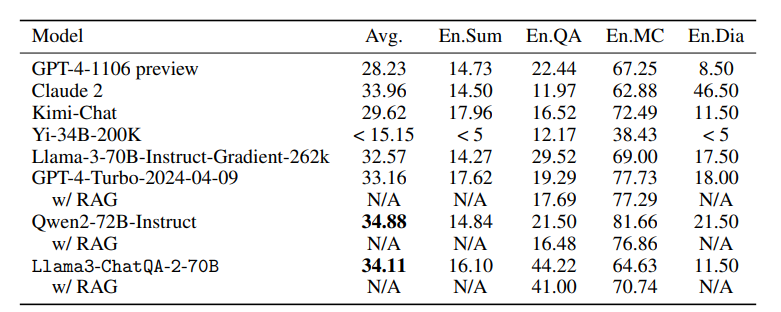
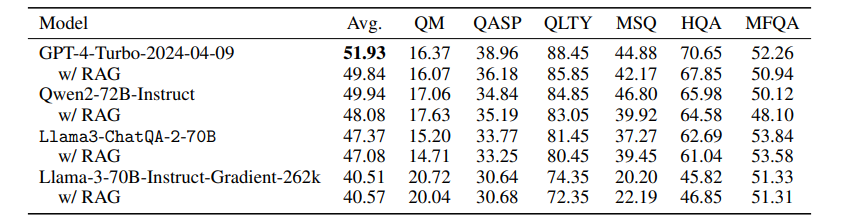
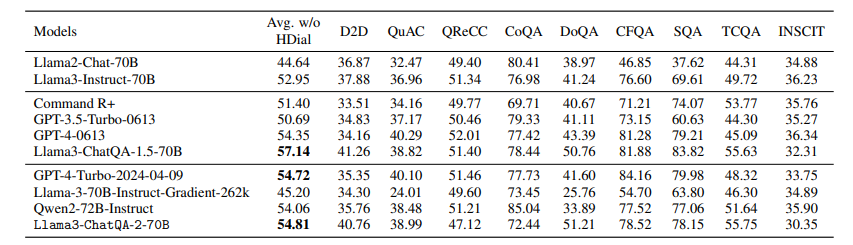
文章链接:
https://arxiv.org/pdf/2407.14482
07
Improving Context-Aware Preference Modeling for Language Models
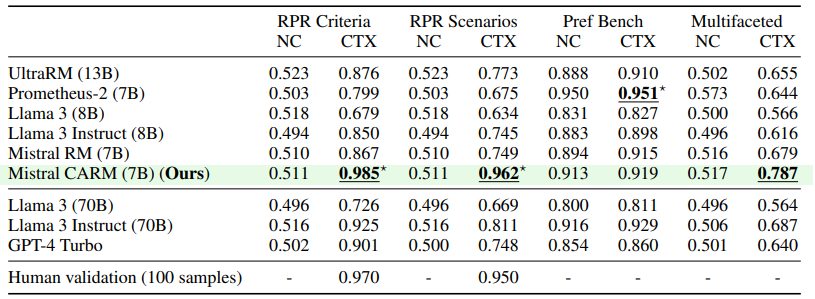
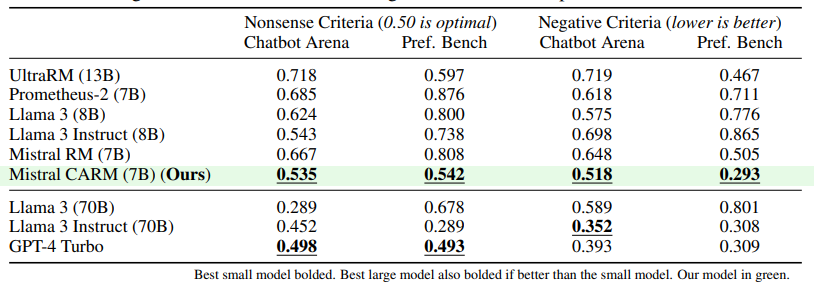
虽然从成对偏好中微调语言模型(LMs)已被证明非常有效,但自然语言的不明确性质带来了关键挑战。直接偏好反馈是不可知的,在可能适用多维标准的情况下难以提供,并且常常不一致,要么是因为基于不完整的指令,要么是由不同的主体提供。为了应对这些挑战,作者考虑了一个两步偏好建模过程,首先通过选择上下文来解决不明确性,然后根据所选上下文评估偏好。本文根据这两个步骤分解了奖励建模误差,这表明除了上下文特定的偏好之外,监督上下文也可能是使模型与多样化人类偏好对齐的可行方法。为此,模型评估上下文特定偏好的能力至关重要。为此,本文提供了条件上下文偏好数据集和相应的实验,这些实验调查了语言模型评估上下文特定偏好的能力。文章使用的数据集来(1)展示现有的偏好模型从增加的上下文中受益,但没有充分考虑,(2)微调一个上下文感知的奖励模型,其上下文特定性能在测试数据集上超过了GPT-4和Llama 3 70B,以及(3)调查上下文感知偏好建模的价值。

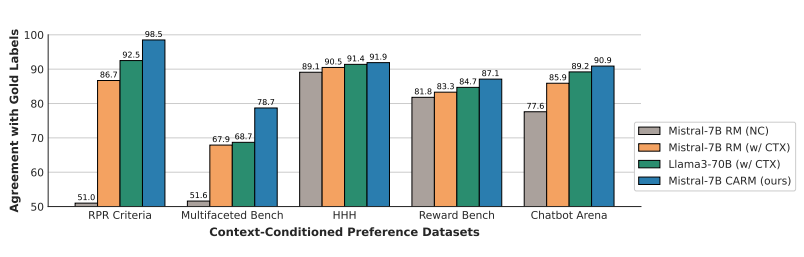
文章链接:
https://arxiv.org/pdf/2407.14916
本期文章由陈研整理
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
欢迎讨论,期待你的
留言

点击 阅读原文 查看更多!
















 50
50

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









