






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

作者简介
陈牧,悉尼科技大学博士生,ReLER实验室成员,研究方向包括自动驾驶、机器感知等
概述
我们提出了GvSeg,这是一个通用的视频分割框架,用于处理四种不同的视频分割任务(即实例、语义、全景和示例引导),同时保持一致的架构设计。目前,开发能够跨多个任务应用的通用视频分割解决方案的趋势正在增长。这简化了研究工作并简化了部署。然而,目前设计中高度统一的框架,其每个模块都保持着一致性,很容易忽视不同任务之间的固有特性,从而导致较差的性能。为了解决这个问题,GvSeg:i)提供了一个全面的解耦式建模来分割目标,从外观、位置和形状的角度彻底审视它们的内在特点,基于此,ii)重新制定了查询初始化、匹配和采样策略,以符合特定任务的需求。这些与架构无关的创新使GvSeg能够在统一的框架内通过适应性定义它们的独特属性来有效处理每个独特的任务。在七个广泛使用的标准基准数据集上的广泛实验表明,GvSeg在四种不同的视频分割任务上都显著超过了所有现有的专有/通用解决方案。
论文地址:https://arxiv.org/pdf/2407.06540
代码链接:https://github.com/kagawa588/GvSeg
Background
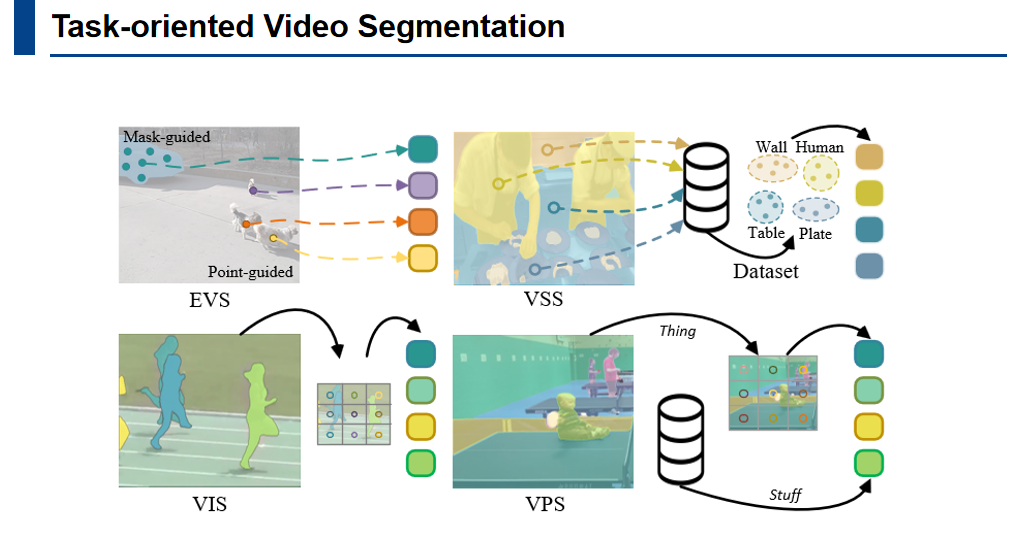
Task-specific Video Segmentation
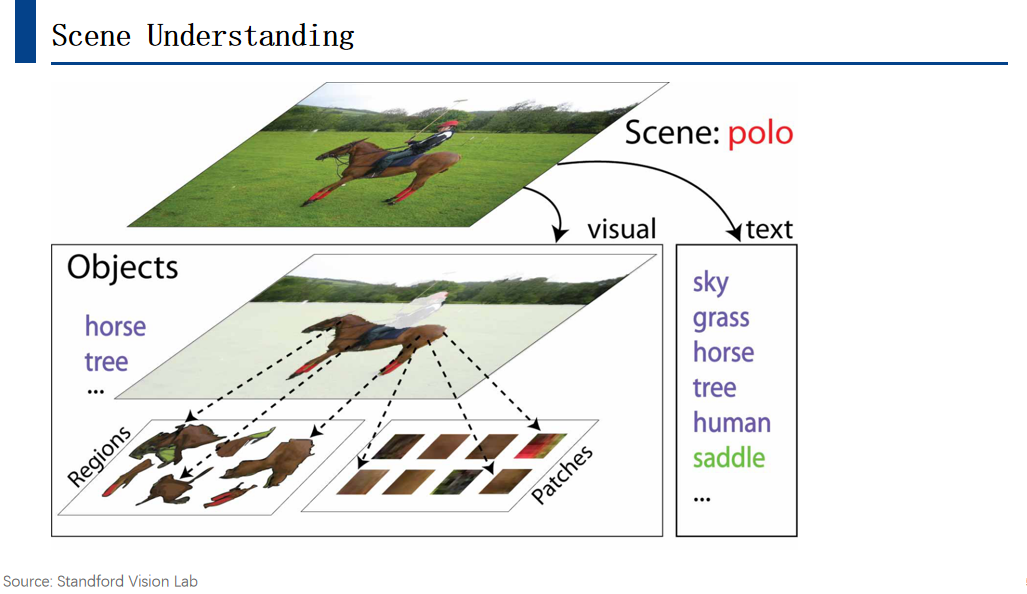
Scene Understanding
视觉场景理解任务。首先需在图像中识别出场景类别,例如图中所示的马球场景。该场景包含若干对象,如骑手及其所骑乘的小马。通过对象识别与检测,我们能理解这些对象及其交互过程。进一步地,小马可被细分为不同区域和区块,这些更细小的区域有助于进行更精细的特征提取。此外,结合文本信息亦可提升理解效果。
做多模态的场景理解,而分割任务是场景理解任务的基础之一。根据分割信号的形式,可以分为静态的图像分割和动态的视频分割。然后再根据分割对象的差异,分割任务可以被拆解设置成各种不同的子任务。比如分割场景中的每一个单独的个体叫做实例分割,将某些像素根据语义分割成一个类别,则是语义分割。还有,可以将对象和背景区分开来,这个任务是视频物体分割。进一步的,我们还能够将分割结合到检测、追踪等任务。
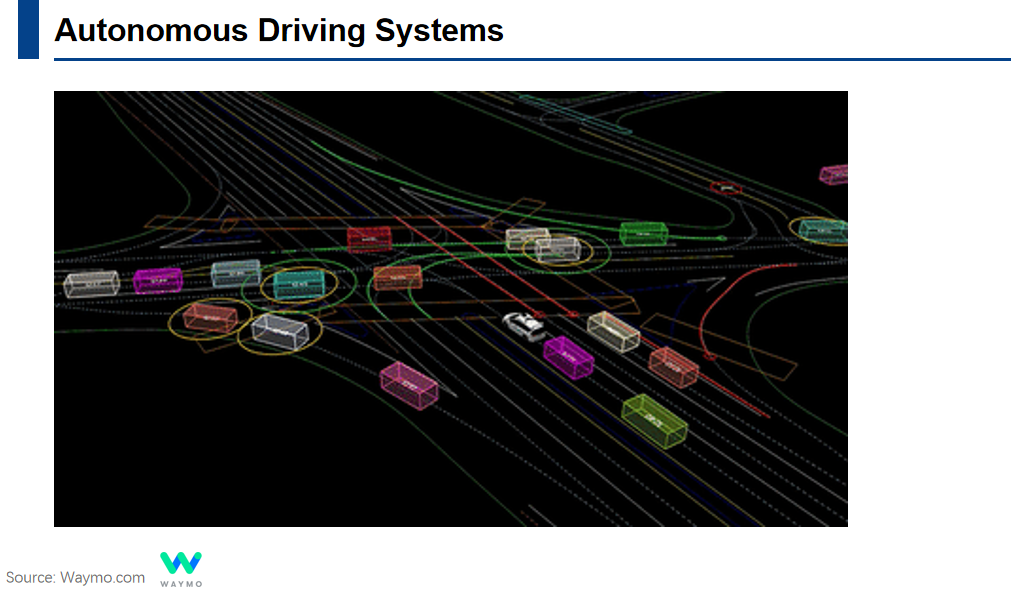
Autonomous Driving Systems
自动驾驶系统依赖于对周围环境的准确感知和理解。因此,视频场景理解技术是推动自动驾驶技术的关键。目前的研究者们对于视频领域的各个子任务设计了不同的网络架构,采用了不同的训练方法以及优化策略。深度学习时代,虽然各个子任务都取得了很大的发展,但每个子任务都有自己专用的网络。这意味着在实际应用中,往往需要同时部署多个模型来处理不同任务。这不仅增加了系统的复杂性以及计算资源的浪费,也导致不同任务之间的信息不能够有效共享。
General Video Segmentation
AI大模型的发展促使视觉领域的研究者们探索如何设计一个能够同时处理多种视频任务的模型。已有部分工作尝试使用统一的框架来涵盖分割领域的多个基础任务。这虽然实现了架构的统一,然而这些工作无法在每个子任务取得很好的效果。
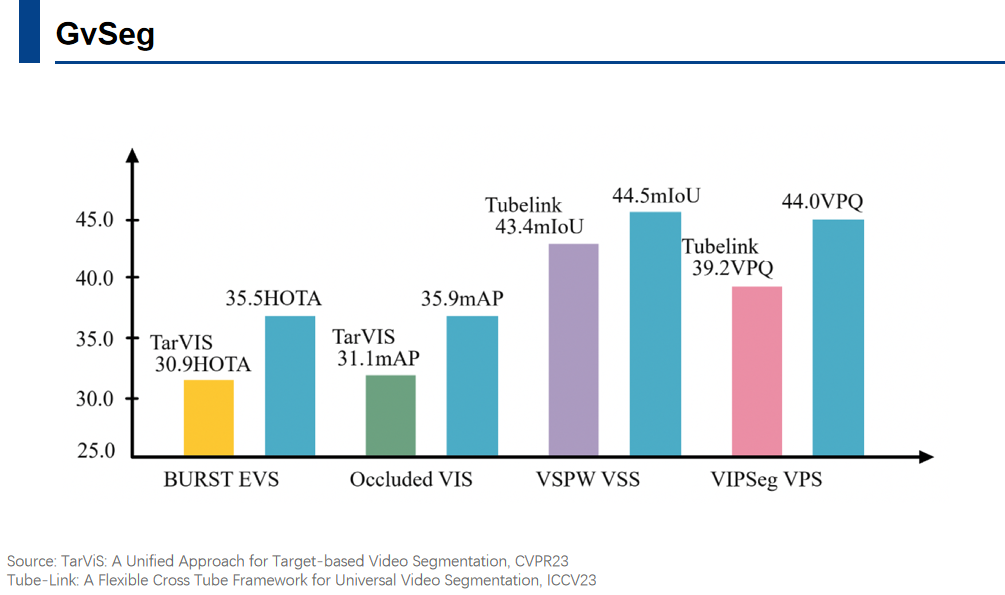
GvSeg
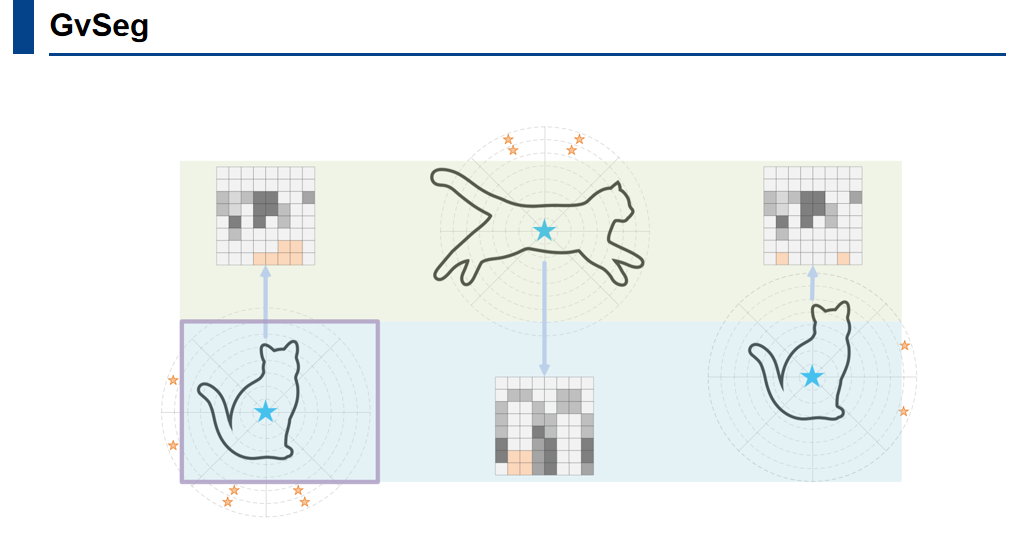
GvSeg框架旨在打破这种任务专用的限制。如图所示,蓝色条代表GvSeg达到的SOTA结果,其他彩色条则代表目前视频中统一框架所能达到的最佳性能。本文在EVS、VS、VSS、NVPS四个任务中共涉及七个benchmark。
Motivation and Methods
经过研究发现,现有工作未能取得最好的结果,是因为他们保持架构所有部分的统一特性,忽视了对每个任务固有属性的探索。
因此,作者对不同的分割目标进行了一个整体的建模,探索这些分割目标的固有特点,并且对框架进行微调,使构建的统一框架适用于各种任务。
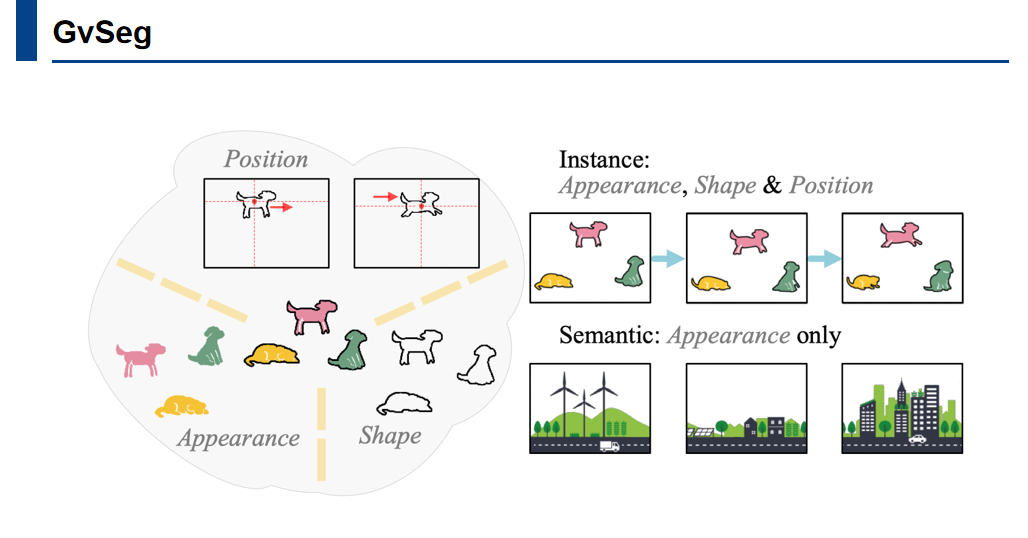
在各种任务中,作者重点研究两个核心问题:是什么和怎么做?1. 在视频分割任务中,哪些因素是决定对象分割效果的关键?2. 我们如何利用这些因素,在一个通用的模型中适应不同任务的需求?
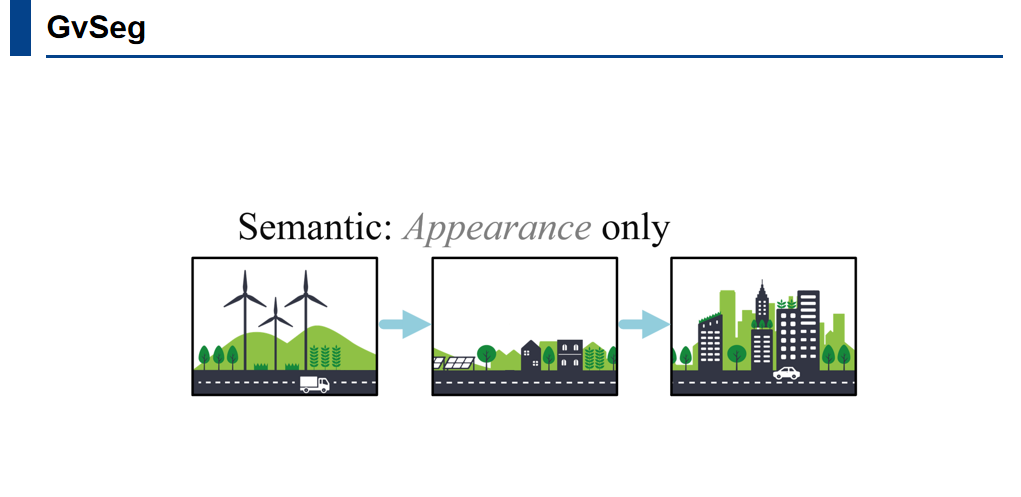
传统的分割模型通常关注事物的外观信息,对于语义分割来说,这是合理的,因为外观信息有助于机器对语义的理解。
然而,发表在《人类视觉与成像》会议上的一篇文章《观察物质:人类与机器的材料感知》中,作者指出,人类在感知物体时不仅依赖于物体的外观,还利用了更多的信息,如物体的结构。

发表在实验心理学期刊的《视觉空间中位置与形状的分离》一文中,作者探讨了人类在感知物体时,虽然物体的位置和形状都是非常重要的视觉线索,但它们在大脑中是通过不同的路径或机制处理的。
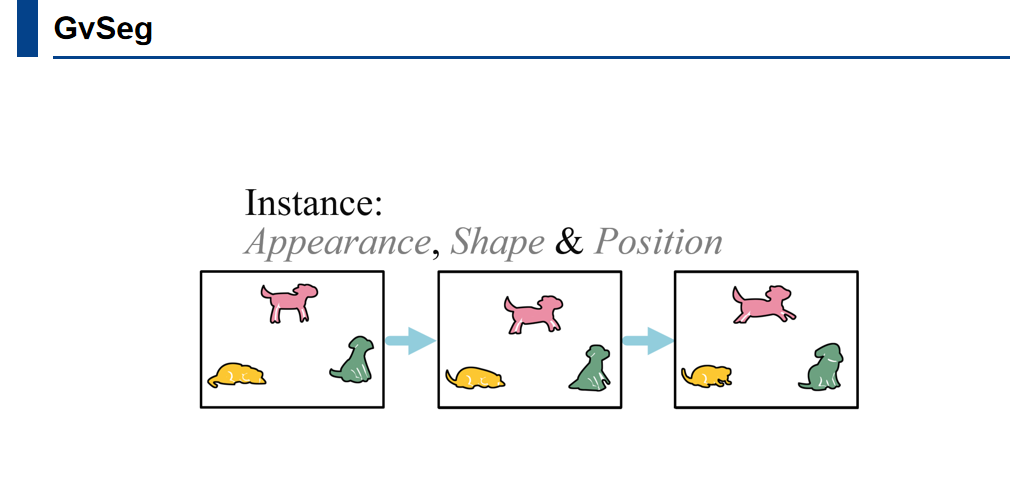
作者认为机器感知不应仅仅依赖外观信息,尤其是对于视频实例分割而言,外观、形状和位置信息也至关重要。

因为在视频中,对象的特征通常保持一致,例如小动物的纹理、颜色等。视频中的小白猫在运动过程中,其颜色和纹理材质基本保持不变。

因此,作者认为Appearance可以作为感知系统在描述物体时的重要变量之一。然而,物体的Position在运动过程中可能会发生显著变化,同时小动物在移动时其Shape也会不断变化,例如从坐姿变为趴姿。尽管意识到了这一点,但现有方法在设计模型时却未能充分考虑到这一点。例如,在进行Temporal Contrastive Learning时,如果机器将形状和位置变化极大的两只小动物视为同一类样本,这将导致机器在理解对象时出现偏差。
然而外观,位置,形状这三个对象的固有特性深度地耦合在一起,人的大脑感知能够轻松的将他们区分开来,机器却很难做到这一点。这就导致在处理语义分割和实例分割等任务的时候,如果使用同一个框架处理不同的目标,设计好的网络往往只在一个任务上表现好,其他任务表现较差。
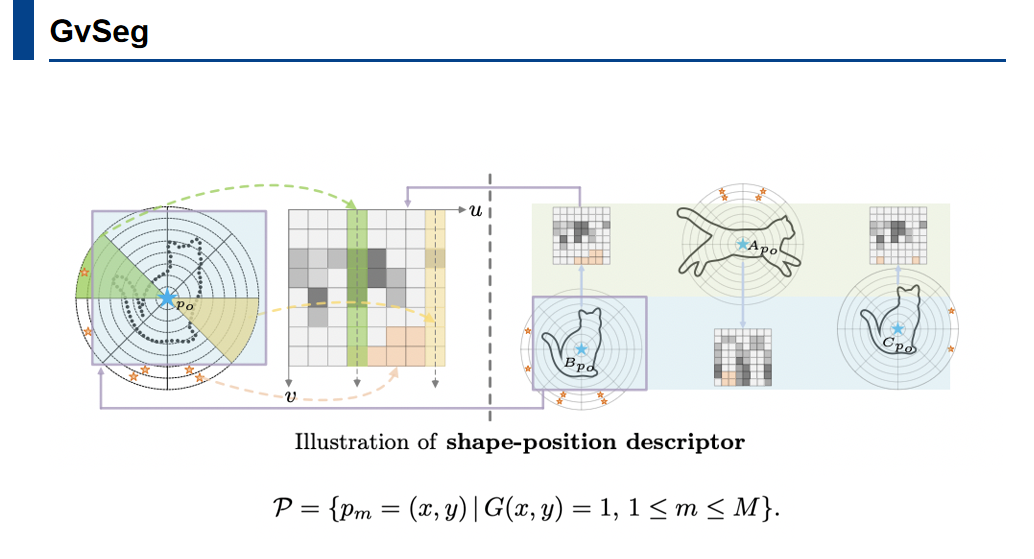
为了解决这个问题,文中为每个目标生成了一个“形状-位置描述符”,并将其编码到跨帧的查询匹配过程中,这使得模型能够结合三种关键因素来进行实例区分。
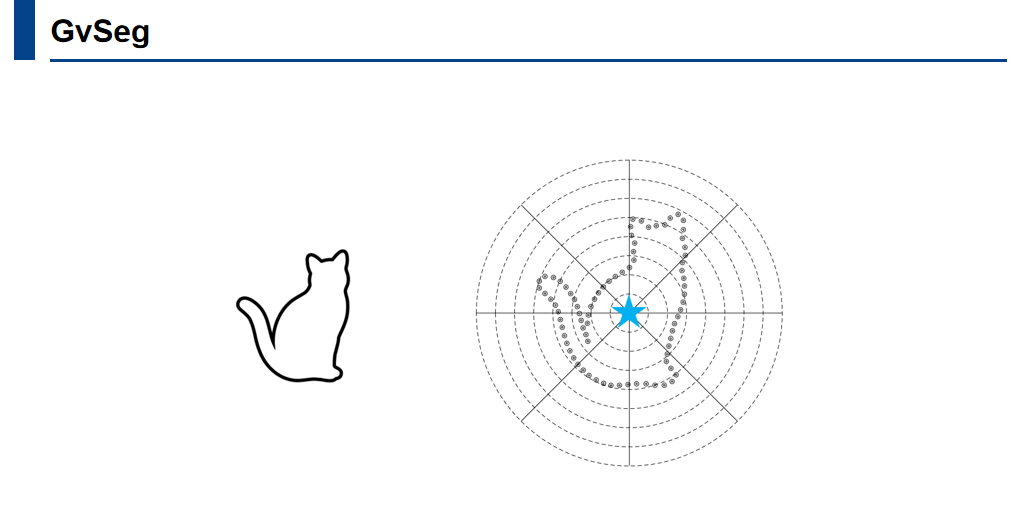
描述符的核心思想在于捕捉目标对象的形状和位置特征。通过编码对象轮廓上的点相对于对象中心的几何关系,描述符能够描述其形状。这一过程建立在极坐标系中。具体而言,给定一个目标对象的轮廓,在轮廓上均匀采样一组锚点,这些锚点随后被转换到以对象的中心作为参考点的极坐标系中。
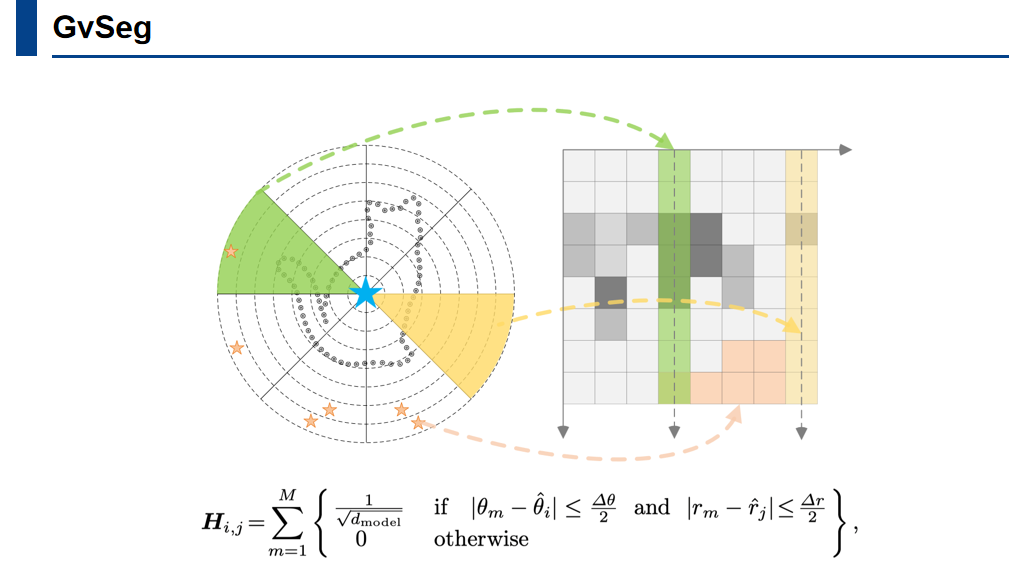
极坐标系被划分为不同的角度和半径区间,通过高效地计算每个区间内的锚点数量,形成一个直方图,该直方图代表了对象的空间配置。
描述符通过几何关系捕捉目标对象的形状特征。例如,形状不同的两个目标在直方图中的表示会有显著差异。描述符不仅考虑形状,还引入了空间位置信息。描述符会在特定区域设定一个特定值,即使两个对象形状相似,但位置不同,其描述符也会有区别。一旦为每个对象生成了形状位置描述符,这些描述符就会被整合到跨帧匹配过程中,帮助模型根据外观、形状和位置三个关键因素来区分整个视频中的对象。
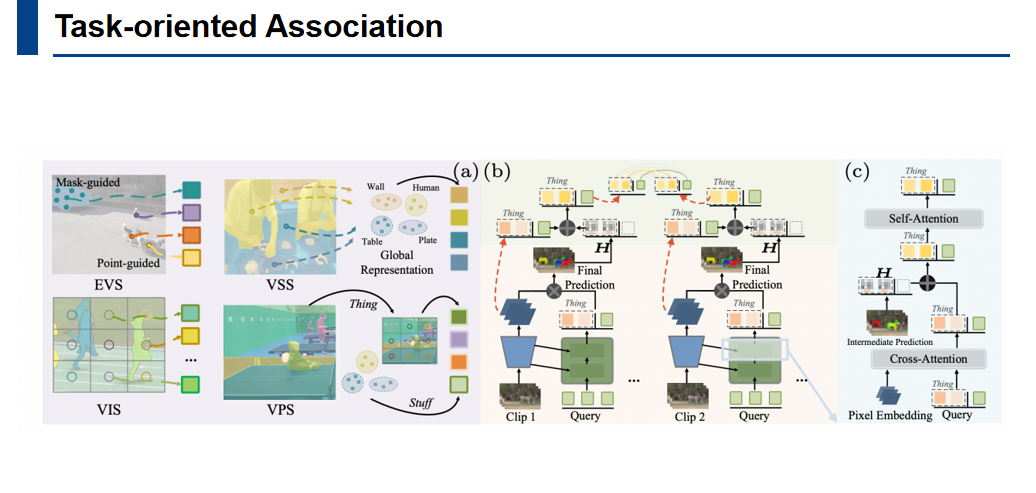
在跨帧匹配的过程中,首先关注对象的初始状态,因为分割对象的初始状态会极大影响后续的预测。因此,针对不同任务的属性,设置了独立的查询生成方法。后续帧与之前的帧进行关联匹配,从而保证了整个视频的时间连续性。
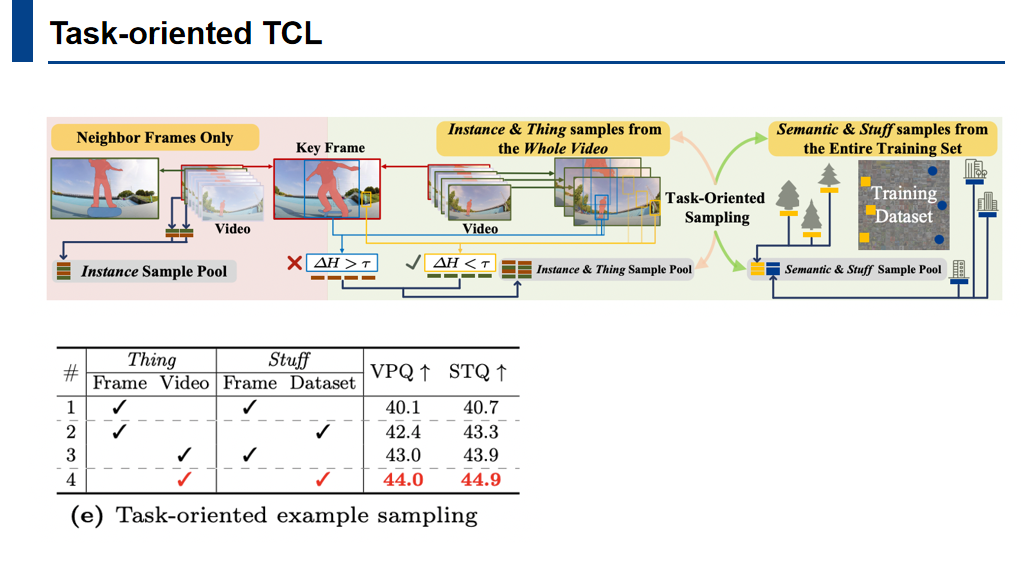
有了之前设计好的描述符,对视频对象就可以进行显式的操作,以设计出更合理的训练策略。比如在时序对比学习的过程中,可以通过设定一个阈值来判断物体的位置和形状在视频中的变化程度。在正负样本的选取过程中考虑到任务本身的属性,形成了一种Task-Oriented Example Sampling。
Results
在描述符的帮助下,可以针对不同任务进行适当的微调,并将这些微调限制在统一的框架内。作者通过广泛实验验证了所提出方法的有效性与泛化性。
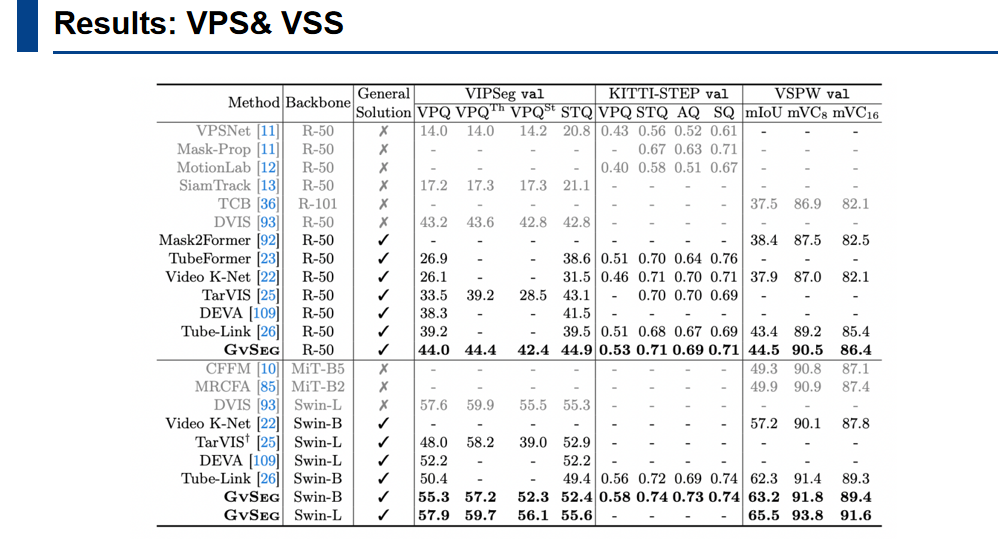
上图是GvSeg在VPS和VSS两个任务的结果,采用了res50,swin-base和swin-large的backbone。
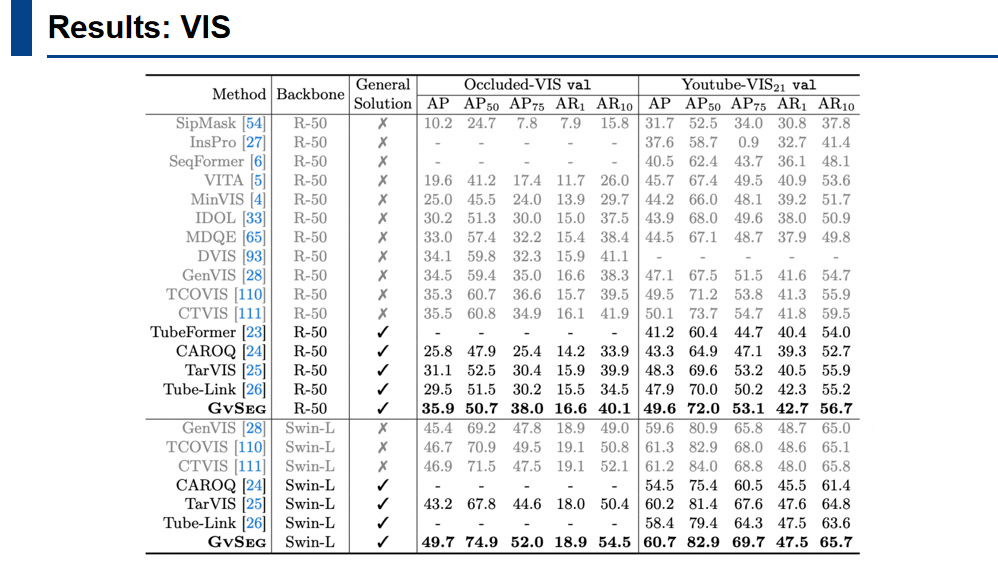
上图是VIS的结果,作者使用了resnet50和swin-large架构与现有方法进行比较。
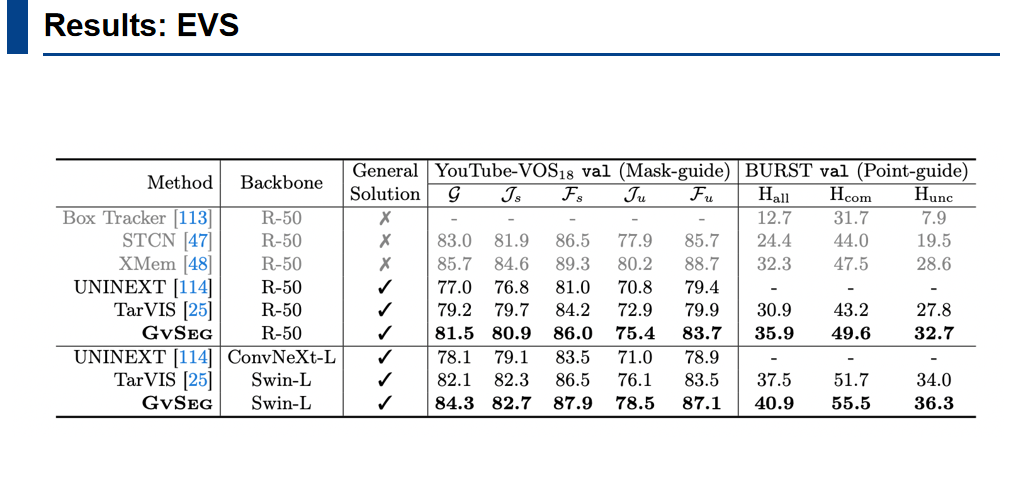
作者还在 mask和point guide两种 evs任务进行了实验。
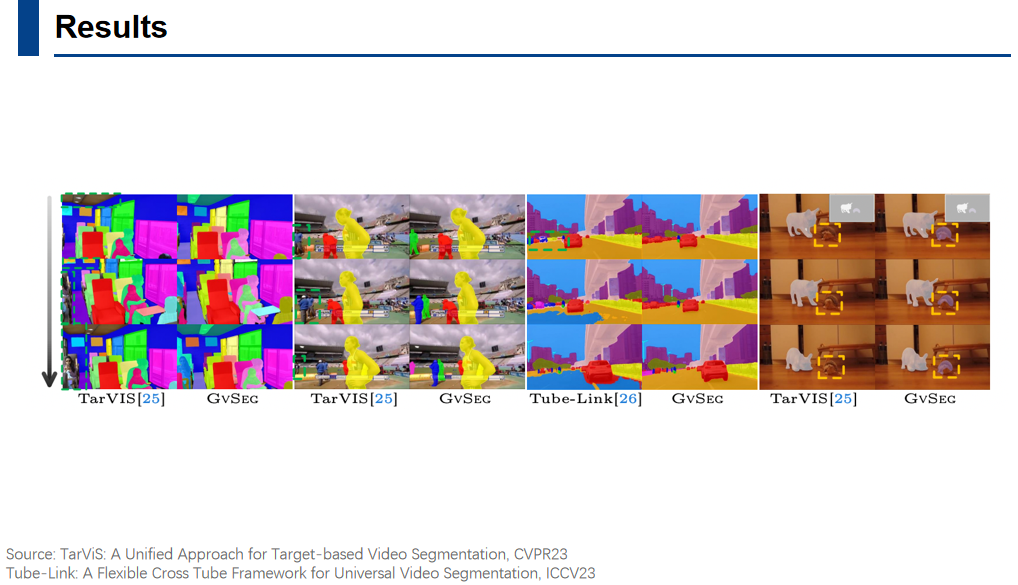
这里展示了一些可视化分割结果。
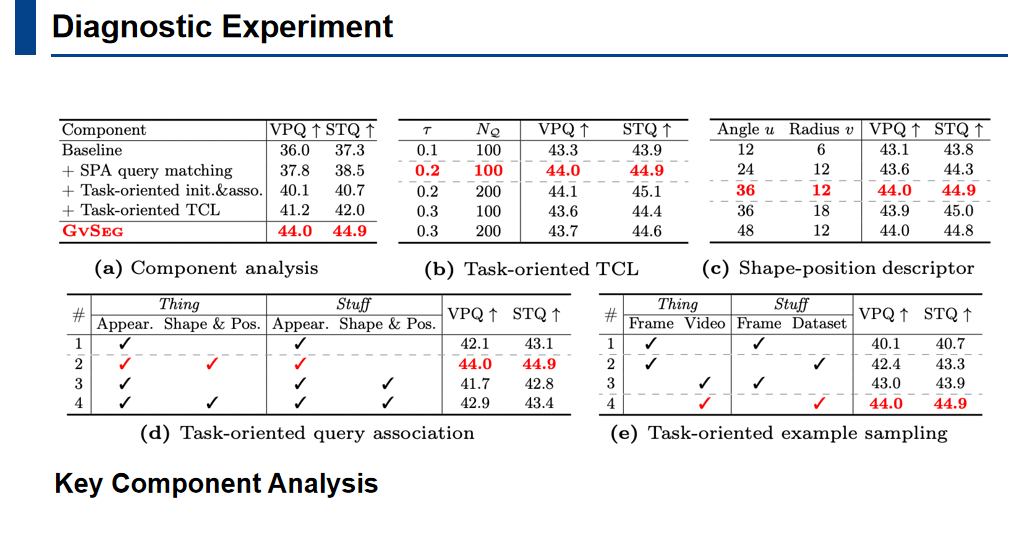
这里展示了一些消融实验的结果。作者对关键部件进行分析,并且对架构设计的关键参数进行了消融实验,验证了每个子方法对整体性能的贡献。

GvSeg从每个独立的任务出发,为构建一个通用或普遍适用的框架提供了必要的见解。这项工作可以轻松扩展到视频理解领域的更多任务中,如MOTS(Multi-object tracking and segmentation)等。在此基础上,实现一个基础模型是非常值得尝试的。
本篇文章由陈研整理
往期精彩文章推荐

仅一行代码,使LLaMA3在知识编辑任务上表现暴涨35%!您确定不来试试嘛?
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 9
9

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









