






科研圈也“吃瓜”!
最近关于ChatGPT参数只有200亿的事情在各大社区、社群引起讨论。问题源于微软发布的一篇题为《CodeFusion: A Pre-trained Diffusion Model for Code Generation》的论文,在做对比的时候透露出了重要信息:ChatGPT 是“只有”20B(200 亿)参数的模型。后续微软撤稿两次,并表示文章中对 ChatGPT 参数数量的猜测来自于一篇博客,作者们并未了解或者验证ChatGPT的参数,直接用了博客的内容,这才带来了公众的误导。
这篇论文提出了一种预训练的扩散代码生成模型 ——CodeFusion。现有的自动回归代码生成模型在生成代码时存在一个限制,即不能轻易地重新考虑之前生成的令牌。CodeFusion通过迭代去噪一个基于编码自然语言的条件程序,从而解决了这一问题。
另外,Agents更加火爆。如果说之前的火爆只是硅谷大佬或者OpenAI等大型公司的“狂欢”,那现在是越来越多Agents方向的创业公司和社区,越来越多的AI Agents出现在人们生活的各个场景下。
10月,一共整理了22篇论文,包括DALL-E 3论文、大模型下一阶段-Auto-Instruct,清华大学提出AgentTuning等。让我们通过AMiner AI功能,一起探寻论文背后的核心思想和创新点,快速了解论文细节。
1. Auto-Instruct: Automatic Instruction Generation and Ranking for Black-Box Language Models
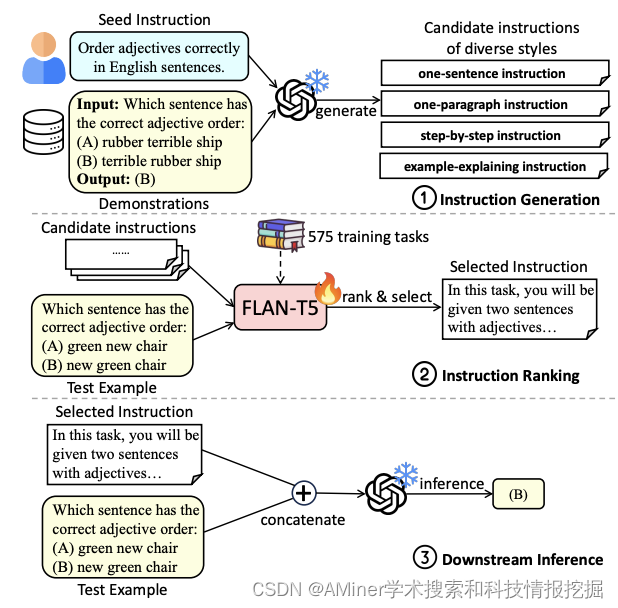
这篇论文介绍了一种名为 Auto-Instruct 的方法,用于自动提高向大型语言模型(LLM)提供的指令的质量。该方法利用 LLM 的生成能力为给定任务生成多种候选指令,然后使用一种训练于多种 575 个现有 NLP 任务的评分模型对它们进行排名。在 118 个领域外任务的实验中,Auto-Instruct 超过了人类编写的指令和现有的 LLM 生成的指令基线。此外,即使对于那些没有包含在其训练过程中的其他 LLM,我们的方法也表现出显著的泛化能力。
链接:https://www.aminer.cn/pub/6535d747939a5f408295c42e/?f=cs
2. AgentTuning: Enabling Generalized Agent Abilities for LLM
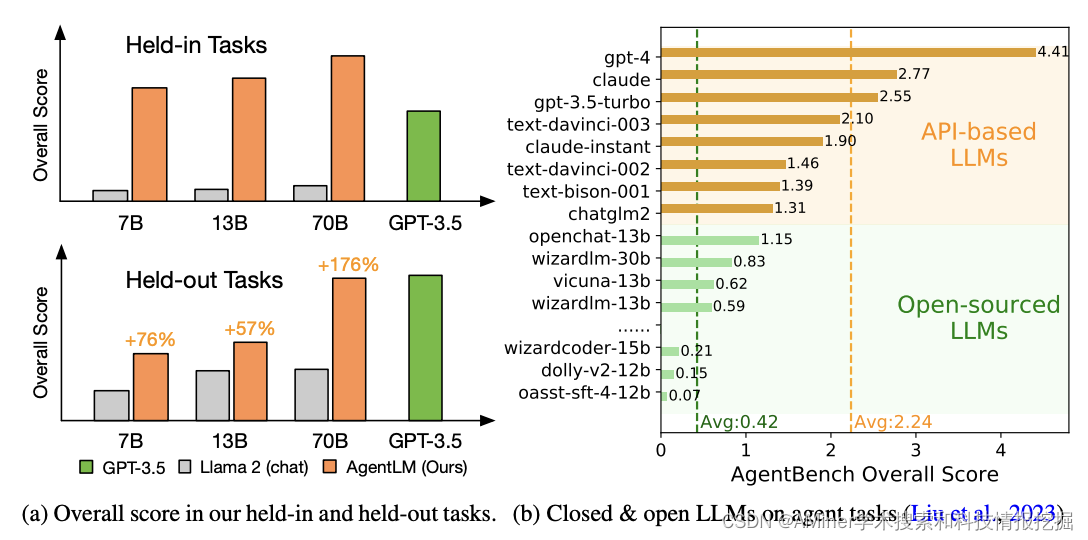
这篇论文介绍了 AgentTuning 方法,该方法可以增强大型语言模型 (LLM) 的代理能力,同时不影响其通用能力。在现实世界中的复杂任务中,LLM 作为中心控制器负责规划、记忆和工具利用,需要细粒度的提示方法以及健壮的 LLM 才能实现满意的性能。虽然已经提出了许多提示方法来完成特定的代理任务,但缺乏针对提高 LLM 本身代理能力的研究,而无需牺牲其通用能力。该研究提出了 AgentTuning 方法,这是一种简单且通用的方法,可以增强 LLM 的代理能力,同时保持其通用 LLM 能力。通过构建包含高质量交互轨迹的轻量级指令调整数据集 AgentInstruct,并采用混合指令调整策略将 AgentInstruct 与开源指令相结合,从而实现了对 Llama 2 系列模型的调整,得到了 AgentLM。实验结果表明,AgentTuning 可以在不影响通用能力的情况下增强 LLM 的代理能力。AgentLM-7B 在未见过的代理任务上与 GPT-3.5-turbo 相当,证明了其具有泛化的代理能力。该研究在 GitHub 上开源了 AgentInstruct 和 AgentLM-7B、13B 和 70B 模型,为代理任务提供了开放且强大的替代方案。
链接:https://www.aminer.cn/pub/6531e2ca939a5f4082f5d5f7/?f=cs
3. Contrastive Prefence Learning: Learning from Human Feedback without RL
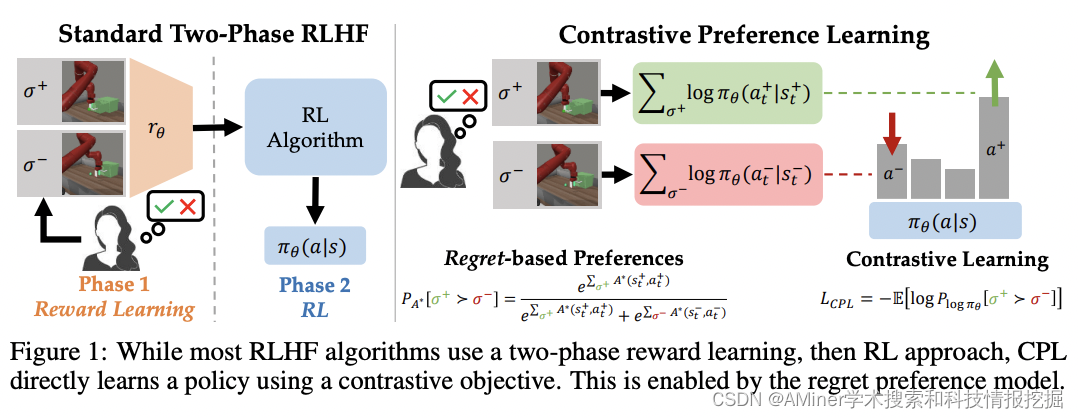
这篇论文介绍了一种名为对比偏好学习(CPL)的新算法,该算法可以从人类反馈中学习最优策略,而无需学习奖励函数。传统的强化学习从人类反馈(RLHF)方法分为两个阶段:首先,使用人类偏好学习奖励函数;然后,通过强化学习(RL)优化所学奖励以使模型与人类意图对齐。然而,这种范式不仅基于对人类偏好的错误假设,而且由于策略梯度或 bootstrapping 在 RL 阶段导致的优化挑战,还导致难以处理的优化问题。为了解决这些问题,现有的 RLHF 方法限制自己仅在上下文性随机化设置(例如大型语言模型)或限制观察维数(例如基于状态的机器人技术)。
通过引入一种基于后悔的人类偏好模型来优化人类反馈的行为的新算法,我们克服了这些局限。利用最大熵原理,我们推导出对比偏好学习(CPL),一种无需学习奖励函数即可从偏好中学习最优策略的算法,从而绕过了 RL 的需求。CPL 是完全离线的,仅使用简单的对比目标,并可以应用于任意 MDP。这使得 CPL 可以优雅地扩展到高维和序列 RLHF 问题,同时比以前的方法更简单。
链接:https://www.aminer.cn/pub/6535d747939a5f408295c635/?f=cs
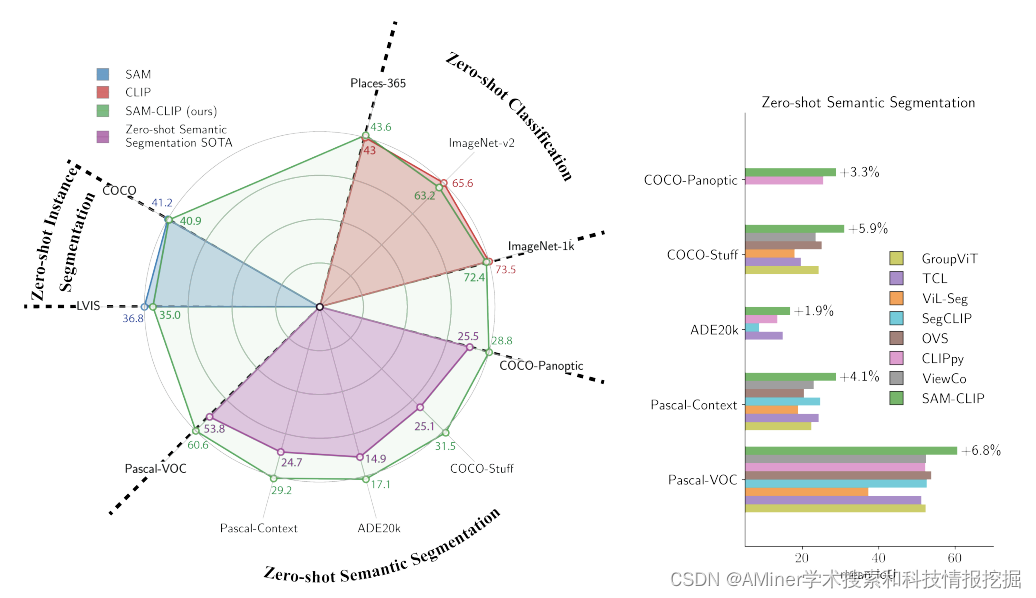
4. SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding
这篇论文介绍了"上下文预训练"(In-Context Pretraining)这一新方法,用于训练大型语言模型(LMs)。现有的预训练流程通过将随机短文档拼接在一起来创建输入上下文,但这些先前的文档无法为预测下一个文档提供信号。而"上下文预训练"则是将语言模型在相关文档序列上进行预训练,从而明确鼓励模型阅读和跨越文档边界进行推理。通过简单地改变文档排序,使每个上下文包含相关文档,并直接应用现有的预训练流程,我们可以实现"上下文预训练"。但是,文档排序问题具有挑战性,因为数据量达到数十亿,我们希望对每一份文档最大化上下文相似性而不重复任何数据。为了解决这个问题,我们引入了高效的近邻搜索和图遍历算法来寻找相关文档和构建一致的输入上下文。实验结果表明,"上下文预训练"能够简单且大规模地显著提高 LM 的性能,在需要更复杂上下文推理的任务中(包括上下文学习、阅读理解、对先前上下文的忠实度、长上下文推理和检索增强),都取得了明显的改进(+8%、+15%、+16%、+5%、+9%)。
链接:https://www.aminer.cn/pub/65387a3d939a5f4082980293/?f=cs
5. In-Context Pretraining: Language Modeling Beyond Document Boundaries
这篇论文介绍了"上下文预训练"(In-Context Pretraining)这一新方法,用于训练大型语言模型(LMs)。现有的预训练流程通过将随机短文档拼接在一起来创建输入上下文,但这些先前的文档无法为预测下一个文档提供信号。而"上下文预训练"则是将语言模型在相关文档序列上进行预训练,从而明确鼓励模型阅读和跨越文档边界进行推理。通过简单地改变文档排序,使每个上下文包含相关文档,并直接应用现有的预训练流程,我们可以实现"上下文预训练"。但是,文档排序问题具有挑战性,因为数据量达到数十亿,我们希望对每一份文档最大化上下文相似性而不重复任何数据。为了解决这个问题,我们引入了高效的近邻搜索和图遍历算法来寻找相关文档和构建一致的输入上下文。实验结果表明,"上下文预训练"能够简单且大规模地显著提高 LM 的性能,在需要更复杂上下文推理的任务中(包括上下文学习、阅读理解、对先前上下文的忠实度、长上下文推理和检索增强),都取得了明显的改进(+8%、+15%、+16%、+5%、+9%)。
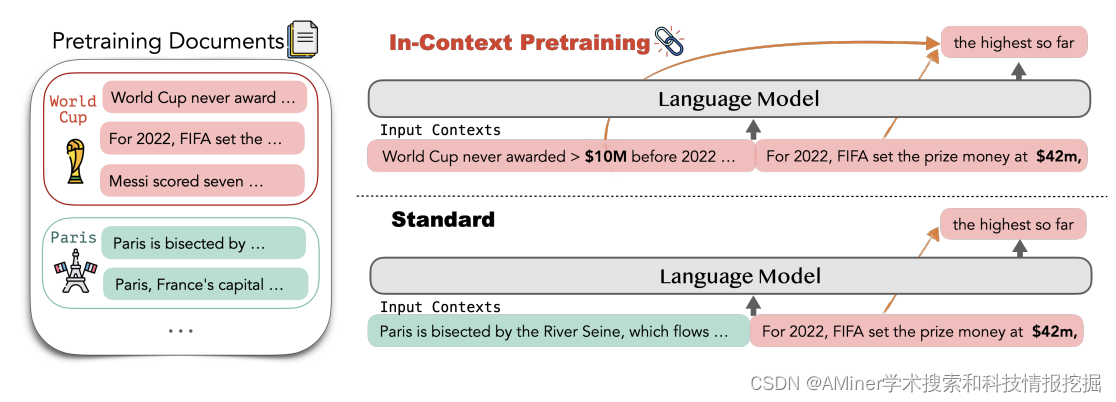
链接:https://www.aminer.cn/pub/652def0c939a5f4082b54103/?f=cs
6. A Comprehensive Survey on Vector Database: Storage and Retrieval Technique, Challenge
这篇论文对向量数据库进行了全面的调查,包括存储和检索技术以及挑战。向量数据库用于存储传统数据库管理系统无法描述的高维数据。尽管关于现有或新型向量数据库架构的文章并不多,但向量数据库背后的近似最近邻搜索问题已经研究了很长时间,可以在文献中找到很多相关的算法文章。本文试图全面回顾相关算法,为读者提供一个关于这个繁荣的研究领域的全面了解。我们的框架基于解决 ANNS 问题的方法对这些研究进行了分类,分别是基于哈希、树、图和量化方法的。然后,我们概述了向量数据库目前面临的挑战。最后,我们勾画了如何将向量数据库与大型语言模型相结合,从而提供新的可能性。
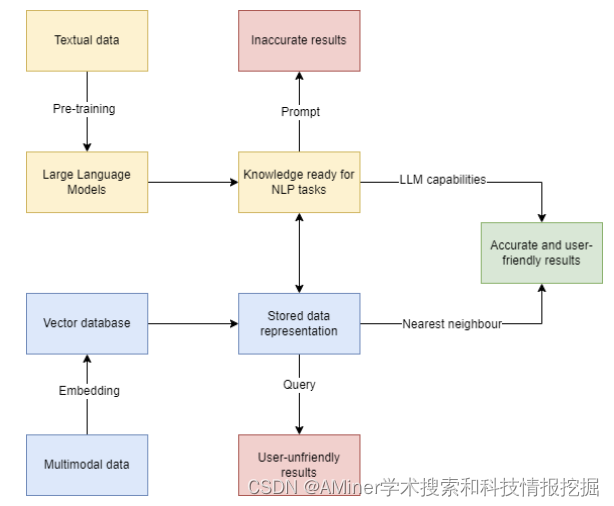
链接:https://www.aminer.cn/pub/65309159939a5f4082843ddf/?f=cs
7. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
这篇论文介绍了一种名为 Self-RAG 的新框架,通过自我反思来提高语言模型的质量和真实性。现有的大型语言模型 (LLMs) 通常由于仅依赖于它们参数化的知识而产生包含事实错误的响应。检索增强生成 (RAG) 是一种临时方法,通过检索相关知识来增强 LLMs,从而减少这种问题。然而,不论检索是否必要,不分检索到的段落是否相关,一概检索并包含固定数量的检索到的段落,会降低 LLM 的灵活性,或导致生成无帮助的响应。Self-RAG 框架通过检索和自我反思来增强 LLM 的质量和平事实性。该框架训练一个单一的任意 LLM,根据需要自适应地检索段落,并使用特殊标记(称为反思标记)生成和反思检索到的段落及其自身的生成。生成反思标记使得 LLM 在推理阶段可控,从而使其行为适应多样化的任务要求。实验结果表明,Self-RAG(7B 和 13B 参数)在多样化的任务上显著优于最先进的 LLMs 和检索增强模型。具体而言,Self-RAG 在开放领域问答、推理和事实验证任务上优于 ChatGPT 和检索增强的 Llama2-chat,并且相对于这些模型,它在提高长篇生成的准确性和引文准确性方面取得了显著的进步。
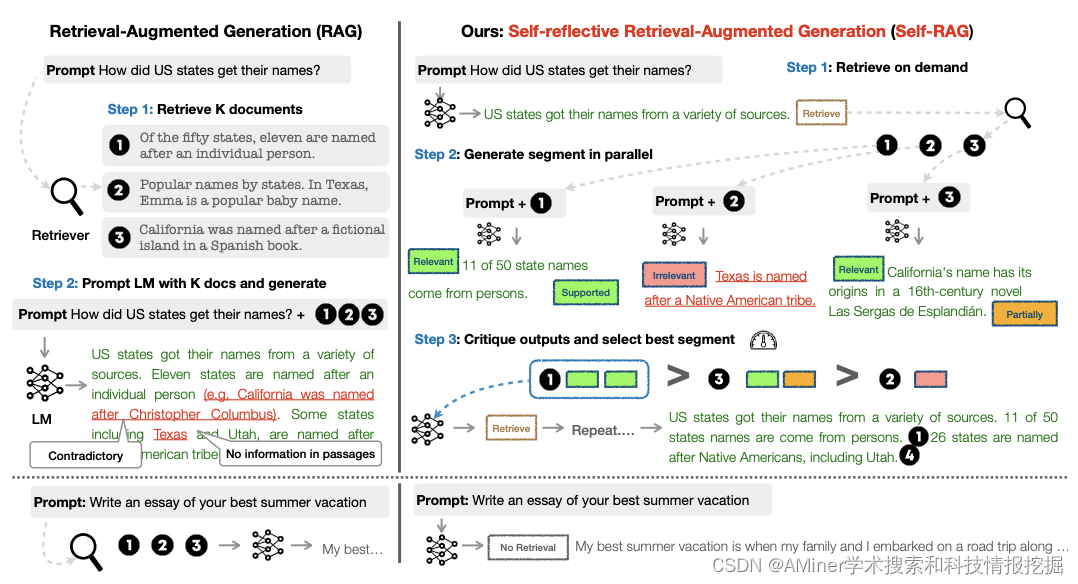
链接:https://www.aminer.cn/pub/65309159939a5f4082843d1b/?f=cs
8. ToolChain: Efficient Action Space Navigation in Large Language Models with A Search**
这篇论文介绍了一种名为 ToolChain的方法,用于解决大型语言模型(LLM)在处理复杂现实问题时面临的行动空间导航问题。该方法基于 A搜索算法,将整个行动空间视为一棵决策树,每个节点代表可能参与解决方案计划的 API 函数调用。通过结合任务特定的成本函数设计,ToolChain能够有效地剪枝可能涉及错误行动的高成本分支,找出最短路径作为解决方案。在多个工具使用和推理任务上的大量实验证明,ToolChain能够在扩展的行动空间内平衡探索和利用,在规划和推理任务上分别比最先进的基线高 3.1% 和 3.5%,同时分别需要 7.35 倍和 2.31 倍的时间。
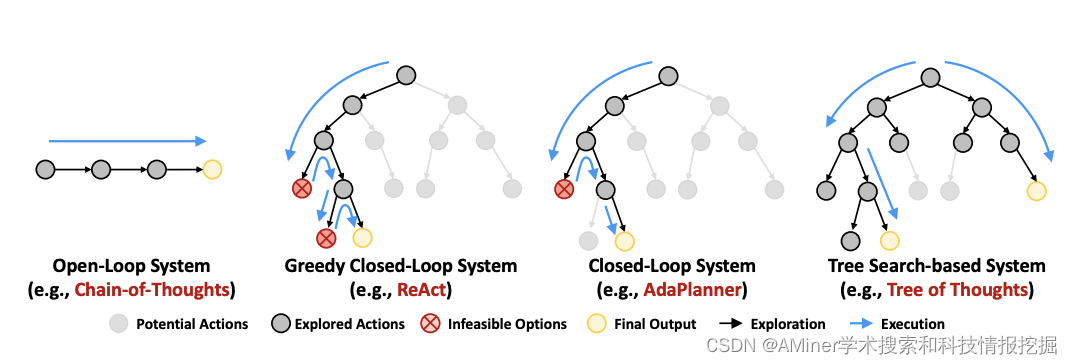
链接:https://www.aminer.cn/pub/6535d747939a5f408295c495/?f=cs
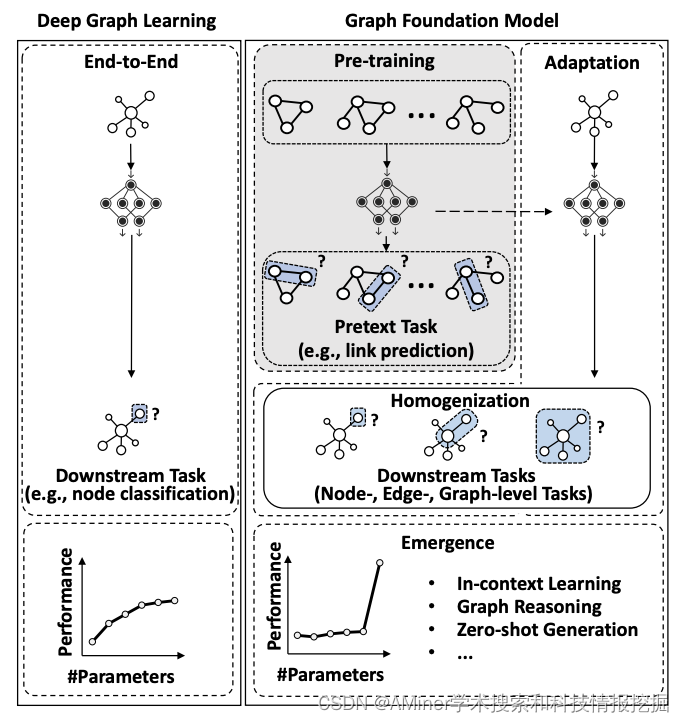
9. Towards Graph Foundation Models: A Survey and Beyond
这篇论文探讨了图基础模型(Graph Foundation Models, GFMs)的发展趋势。基础模型作为人工智能应用的基本构建块,已经在自然语言处理等多个领域取得了显著的成功。与此同时,图机器学习也经历了革命性的转变,浅层方法逐渐被深度学习方法所取代。基础模型的出现和同质化能力引起了图机器学习研究者的兴趣,激发了关于开发基于广泛图数据预训练且能适应广泛下游图任务的下一个图学习范式的讨论。然而,目前还没有关于这类工作的明确定义和系统分析。在这篇文章中,作者提出了图基础模型的概念,并首次全面阐述了它们的关键特性和技术。随后,作者将现有关于 GFMs 的研究分为三类,根据它们对图神经网络和大型语言模型的依赖性进行分类。除了对图基础模型的当前研究进行全面概述外,本文还讨论了该领域未来可能的研究方向。
链接:https://www.aminer.cn/pub/65309159939a5f4082843e5f/?f=cs
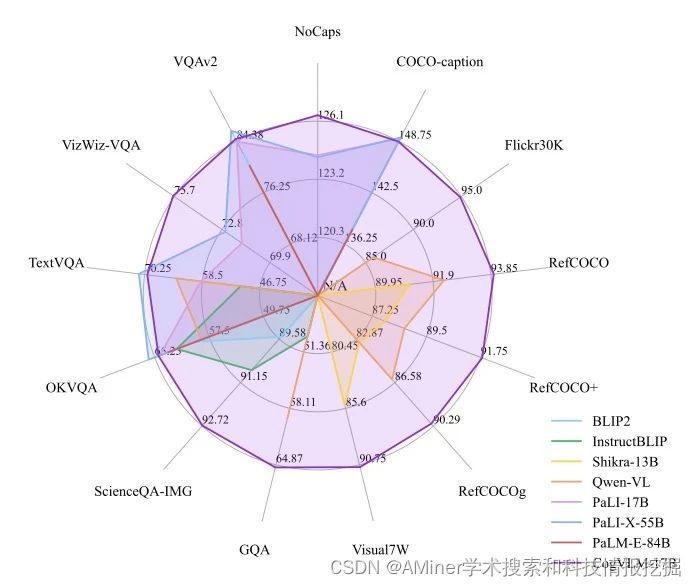
10. COGVLM: VISUAL EXPERT FOR LARGE LANGUAGE MODELS
这篇论文介绍了 CogVLM,一个强大的开源视觉语言基础模型。与流行的浅层对齐方法不同,CogVLM 通过在注意力和 FFN 层中的可训练视觉专家模块,弥合了预训练语言模型和图像编码器之间的差距。因此,CogVLM 能够在不牺牲 NLP 任务性能的情况下,实现视觉语言特征的深度融合。CogVLM-17B 在 10 个经典的跨模态基准测试中取得了最先进的性能,包括 NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA 和 TDIUC,并且在 VQAv2、OKVQA、TextVQA、COCO captioning 等任务中排名第二,超过了或与 PaLI-X 55B 相媲美。
链接:https://www.aminer.cn/pub/65260ee8cd549670787e1513/?f=cs
11. Improving Image Generation with Better Captions
这篇论文研究了如何通过更好的字幕来提高图像生成效果。作者发现,现有的文本到图像模型在遵循详细图像描述方面存在困难,常常忽略一些词或混淆提示的意义。他们认为,这一问题源于训练数据集中的噪声和不准确的图像字幕。为了解决这个问题,作者训练了一个定制的图像字幕生成器,并用它重新为训练数据集生成字幕。然后,作者训练了几个文本到图像模型,并发现通过训练这些合成的字幕,可以可靠地提高模型遵循提示的能力。最后,作者利用这些发现构建了 DALL-E 3:一个新的文本到图像生成系统,并在针对提示跟随、连贯性和美学设计的评估中对其性能进行了基准测试,发现其表现优于竞争对手。为了便于未来的研究,作者发布了这些评估的样本和代码,以便继续优化文本到图像系统的重要方面。

链接:https://www.aminer.cn/pub/65325de4a196276d21d6afcb/?f=cs
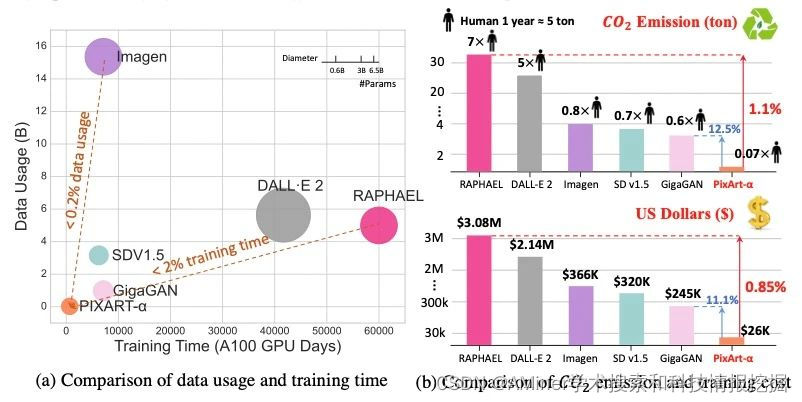
12. PIXART-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
这篇论文介绍了 PIXART-α,一种基于 Transformer 的文本到图像(T2I)扩散模型,其图像生成质量可与最先进的图像生成器(如 Imagen、SDXL 和 Midjourney)相媲美,接近商业应用标准。此外,它支持高达 1024px 的高分辨率图像合成,且训练成本较低。为了实现这一目标,提出了三种核心设计:(1)训练策略分解:设计了三个分别优化像素依赖性、文本图像对齐和图像美学质量的训练步骤;(2)高效的 T2I Transformer:将交叉注意力模块融入扩散 Transformer(DiT)中,注入文本条件并简化计算密集型的类条件分支;(3)高信息数据:强调文本图像对中概念密度的意义,并利用大型视觉语言模型自动为密集伪字幕进行自动标注,以协助文本图像对齐学习。结果表明,PIXART-α的训练速度大大超过了现有的大规模 T2I 模型,例如,PIXART-α仅用了 Stable Diffusion v1.5 训练时间的 10.8%(675 vs. 6,250 A100 GPU 天),节省了近 30 万美元(26,000 vs. 320,000),并减少了 90%的 CO2 排放。此外,与更大的 SOTA 模型 RAPHAEL 相比,我们的训练成本仅为 1%。大量实验证明,PIXART-α在图像质量、艺术性和语义控制方面表现优异。我们希望 PIXART-α能为 AIGC 社区和初创公司加速从零开始构建高质量、低成本生成模型提供新的启示。
链接:https://www.aminer.cn/pub/651b79af3fda6d7f0628eaed/?f=cs
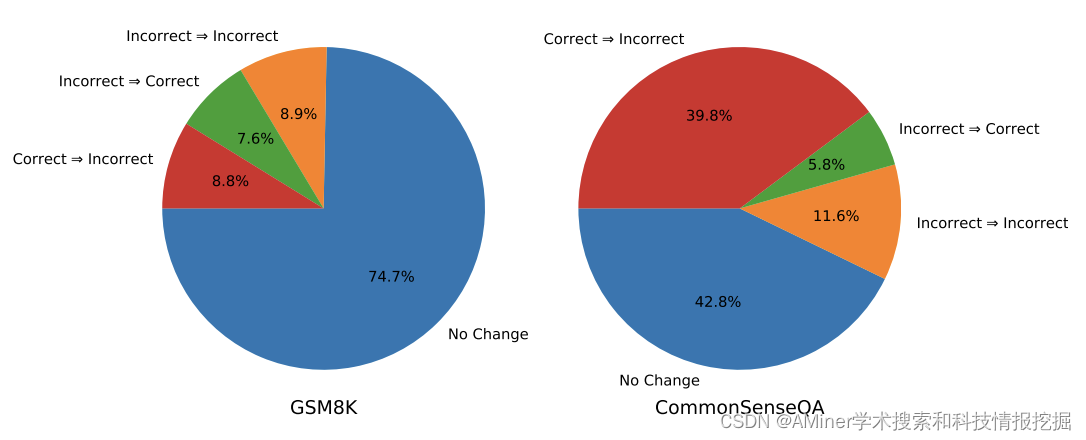
13. Large Language Models Cannot Self-Correct Reasoning Yet
这篇论文探讨了大语言模型(LLMs)在自我纠正推理方面的局限性。尽管 LLMs 在各种应用中展现了无与伦比的文本生成能力,但人们对它们生成的内容的准确性和适当性仍存在担忧。为了解决这些问题,人们提出了自我纠正的方法。然而,这篇论文对自我纠正在 LLMs 中的作用和效果进行了批判性审查,揭示了其真正潜力和局限性。特别是,论文关注了内在自我纠正的概念,即 LLM 试图仅根据其固有能力来纠正其初始反应,而无需外部反馈。论文的研究表明,在没有外部反馈的情况下,LLMs 很难自我纠正其推理反应,甚至在某些情况下,经过自我纠正后的表现可能会恶化。基于这些见解,论文提出了该领域未来研究和实际应用的建议。
链接:https://www.aminer.cn/pub/651ccb383fda6d7f066353c4/?f=cs
14. Kandinsky: an Improved Text-to-Image Synthesis with Image Prior and Latent Diffusion
这篇论文介绍了一种名为 Kandinsky 的新型文本到图像生成模型,该模型结合了图像先验模型和潜在扩散技术的原理。与现有的基于扩散的模型(分为像素级和潜在级方法)不同,Kandinsky 采用了一种新的潜在扩散架构。该模型包括一个单独训练的图像先验模型,用于将文本嵌入映射到 CLIP 的图像嵌入。另一个独特的特点是修改后的 MoVQ 实现,作为图像自动编码器组件。整个模型包含 33 亿个参数。此外,作者还部署了一个用户友好的演示系统,支持多种生成模式,如文本到图像生成、图像融合、文本和图像融合、图像变异生成以及文本引导的修复/扩展。实验评估显示,Kandinsky 模型在 COCO-30K 数据集上的 FID 得分为 8.03,成为在图像生成质量方面最优秀的开源模型。
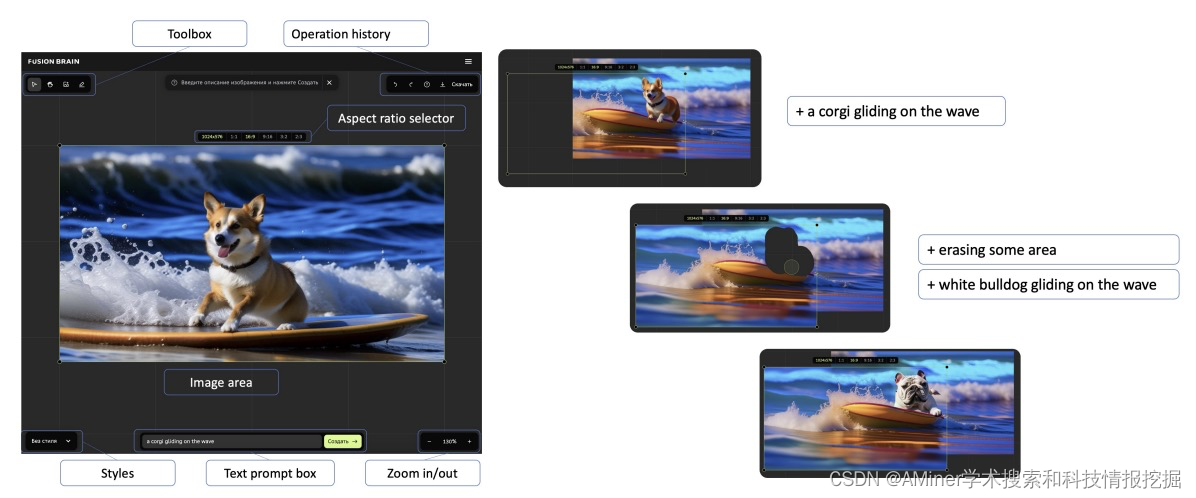
链接:https://www.aminer.cn/pub/651f6e093fda6d7f06d0c68f/?f=cs
15. Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
这篇论文介绍了 Prometheus 语言模型,旨在为语言模型引入细粒度的评估能力。目前,使用强大的专有大型语言模型 (LLM) (例如 GPT-4) 作为长篇回答的评估者已成为默认标准。然而,对于具有大规模评估任务和考虑自定义标准 (例如儿童可读性) 的实践者来说,使用专有 LLM 作为评估者不可靠,因为其闭源特性,无法控制版本,且成本过高。在这项工作中,作者提出了 Prometheus,一个完全开源的 LLM,当提供适当的参考材料 (参考答案,评分标准) 时,其评估能力与 GPT-4 相当。作者首先构建了 Feedback Collection 数据集,其中包括 1K 个细粒度评分标准,20K 个指令,以及由 GPT-4 生成的 100K 个语言反馈和响应。利用 Feedback Collection 数据集,作者训练了 Prometheus,一个 13B 的评估者 LLM,可以根据用户提供自定义评分标准评估任何给定的长篇文本。实验结果表明,当使用 45 个自定义评分标准进行评估时,Prometheus 与人类评估者之间的 Pearson 相关性为 0.897,与 GPT-4 相当 (0.882),大大优于 ChatGPT(0.392)。此外,在使用 1222 个自定义评分标准进行评估的四个基准测试 (MT Bench,Vicuna Bench,Feedback Bench,Flask Eval) 中,与 GPT-4 的相关性测量也显示出类似趋势,进一步证实了 Prometheus 作为评估者 LLM 的能力。最后,Prometheus 在两个人类偏好基准测试 (HHH 对齐和 MT Bench 人类评判) 上取得了最高准确度,超过了明确训练在人类偏好数据集上的开源奖励模型的准确度,突显了其作为通用奖励模型的潜力。
作者将在 https://github.com/kaistAI/Prometheus 上开源他们的代码、数据集和模型。
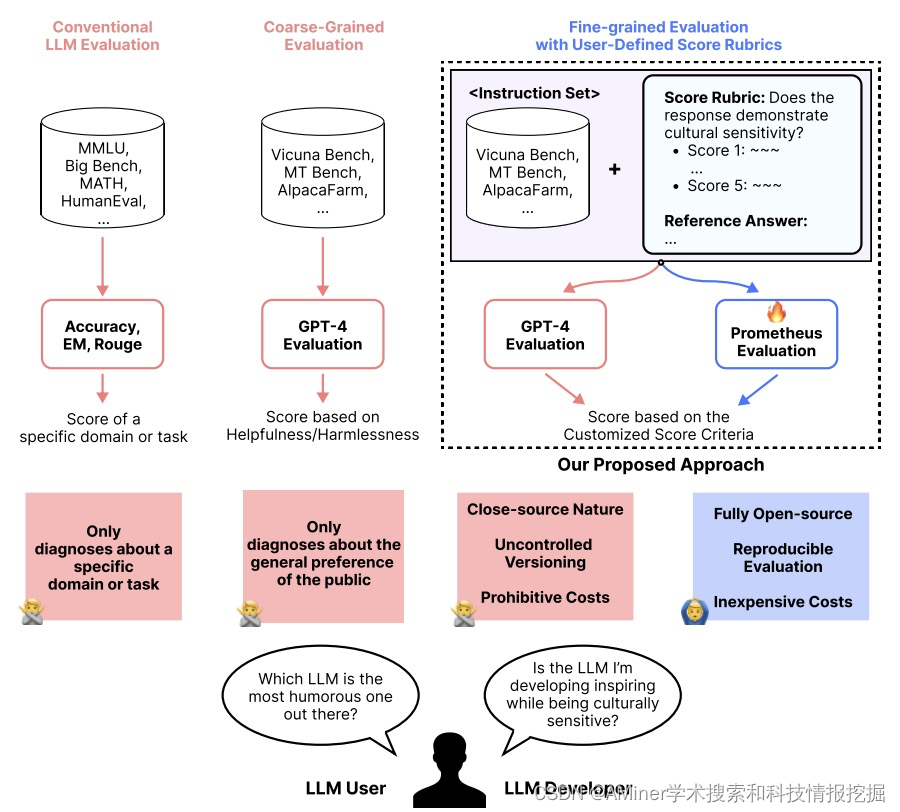
链接:https://www.aminer.cn/pub/6528a864939a5f408257a0e1/?f=cs
16. Table-GPT: Table-tuned GPT for Diverse Table Tasks
这篇论文介绍了 Table-GPT:一种用于多样化表格任务的表格调整 GPT。语言模型 GPT-3.5 和 ChatGPT 展示了出色的能力,可以遵循各种人类指令并执行广泛的任务。然而,当用一系列基本的表格理解任务探测这些语言模型时,我们发现今天的语言模型在许多表格相关任务上仍然不够理想,这可能是由于它们主要是在一维自然语言文本上进行预训练的,而关系表格是二维对象。在本文中,作者提出了一个新的表格调整范式,继续使用来自真实表格的多样化表格任务合成训练数据,以提高语言模型理解表格和执行表格任务的能力。作者展示了他们的 Table-GPT 模型在广泛的表格任务中表现出更好的表格理解能力,包括超出训练任务范围的未见任务,并且具有强大的泛化能力,能够以类似于 GPT-3.5 和 ChatGPT 的方式响应各种人类指令来执行新的表格任务。
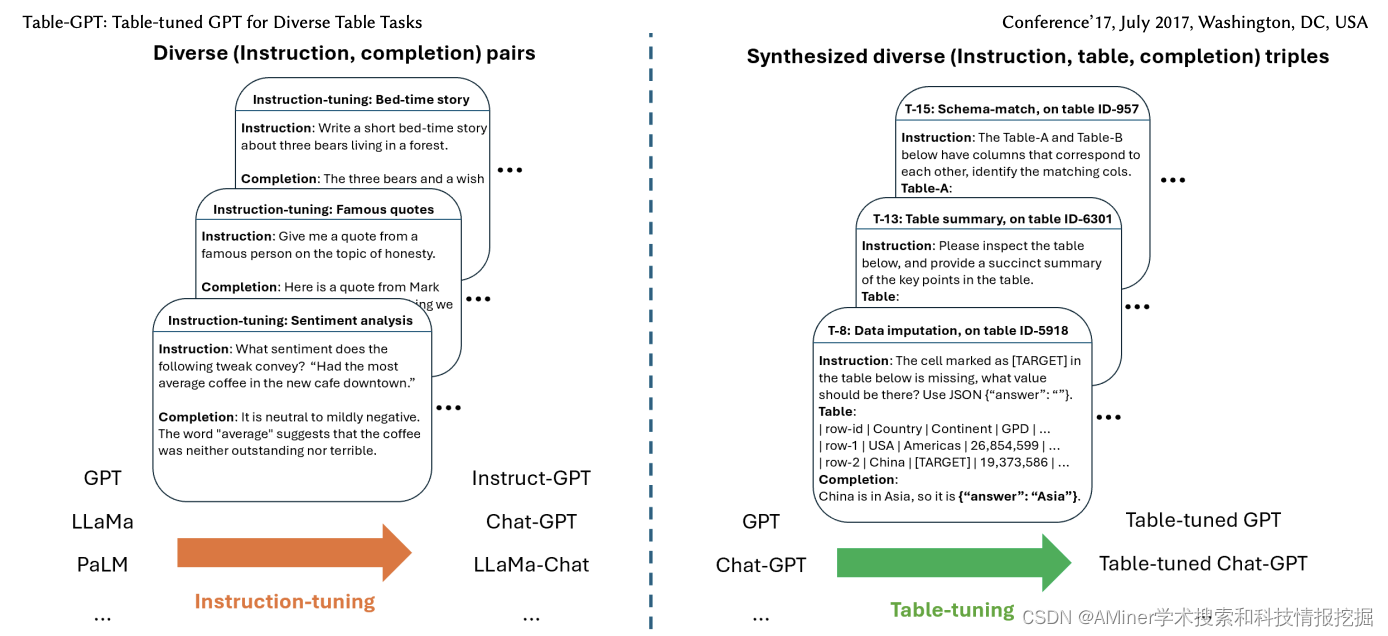
链接:https://www.aminer.cn/pub/652c9d07939a5f40825c0e29/?f=cs
17. Llemma: An Open Language Model For Mathematics
这篇论文介绍了一个名为 Llemma 的大型数学语言模型。该模型在 Proof-Pile-2 数据集上对 Code Llama 进行预训练,该数据集包括科学论文、包含数学的网页数据和数学代码。在 MATH 基准测试中,Llemma 在等参数基础上优于所有已知的开放基础模型,以及尚未发布的 Minerva 模型套件。此外,Llemma 无需进一步微调即可实现工具使用和正式定理证明。作者公开发布了所有相关资料,包括 70 亿和 340 亿参数模型、Proof-Pile-2 数据集以及复制实验的代码。

链接:https://www.aminer.cn/pub/652def02939a5f4082b53043/?f=cs
18. BitNet: Scaling 1-bit Transformers for Large Language Models
这篇论文介绍了 BitNet,一种可扩展且稳定的 1 位 Transformer 架构,专为大型语言模型设计。为了解决大型语言模型在部署方面面临的挑战以及高能耗带来的环境影响问题,作者引入了 BitNet。具体来说,作者引入了 BitLinear 作为 nn.Linear 层的替换,以便从零开始训练 1 位权重。在语言建模的实验结果表明,BitNet 在保持竞争力性能的同时,大大减少了内存占用和能源消耗,相较于最先进的 8 位量化方法和 FP16 Transformer 基线。此外,BitNet 呈现出与全精度 Transformer 类似的扩展规律,表明其在保持效率和性能优势的同时,有望有效地扩展到更大的语言模型。
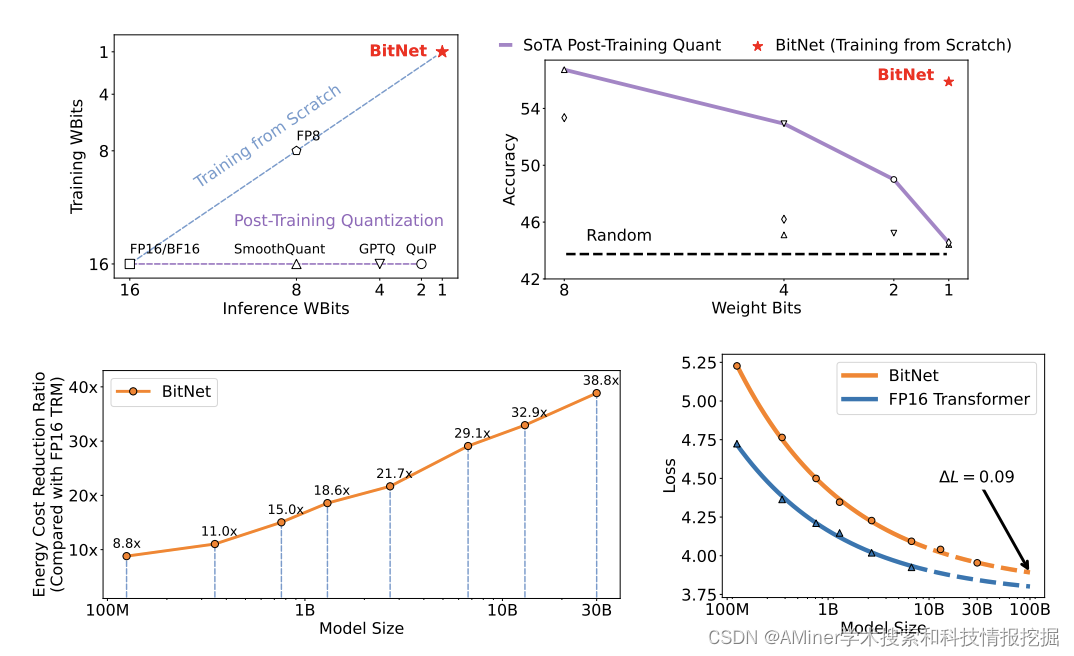
链接:https://www.aminer.cn/pub/652f3ff0939a5f4082e74d9f/?f=cs
19. 3D-GPT: Procedural 3D Modeling with Large Language Models
这篇论文介绍了一种名为 3D-GPT 的框架,用于使用大型语言模型进行基于指令的 3D 建模。该框架利用大型语言模型(LLMs)作为高效的问题解决者,将程序化的 3D 建模任务分解为可访问的片段,并为每个任务分配适当的代理。3D-GPT 集成了三个核心代理:任务调度代理、概念化代理和建模代理。它们共同实现了两个目标:首先,它增强了简洁的初始场景描述,将它们发展为详细形式,并根据后续指令动态适应文本;其次,它集成了程序化生成,从丰富的文本中提取参数值,以便轻松地与 3D 软件进行资产创建接口。实验证明,3D-GPT 不仅可以解释和执行指令,提供可靠的结果,而且还可以有效地与设计师协作。此外,它还可以与 Blender 无缝集成,解锁更广泛的操作可能性。这项工作突显了 LLMs 在 3D 建模中的潜力,为场景生成和动画的未来发展提供了基本框架。
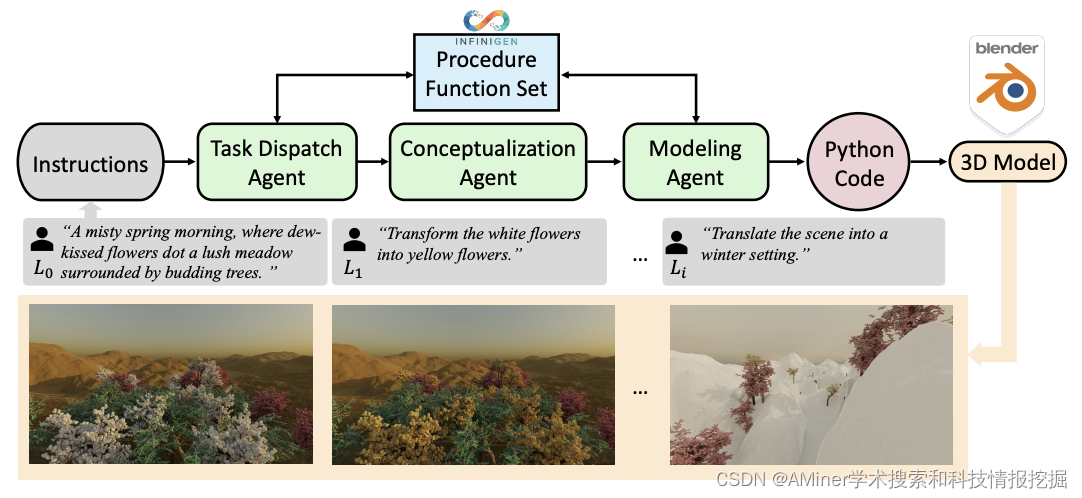
链接:https://www.aminer.cn/pub/6531e2ca939a5f4082f5d67a/?f=cs
20. Matryoshka Diffusion Models
这篇论文介绍了Matryoshka扩散模型(MDM),这是一个端到端的高分辨率图像和视频合成框架。现有的扩散模型生成高分辨率图像和视频通常采用 这篇论文介绍了一种名为Matryoshka Diffusion Models(MDM)的高分辨率图像和视频合成的端到端框架。现有的扩散模型生成高维模型仍然面临着计算和优化方面的挑战,因此学习高维模型仍然是一项艰巨的任务。在本文中,作者提出了一种扩散过程,可以同时在多个分辨率下联合去噪输入,并使用嵌套的UNet架构,其中小尺度输入的特征和参数嵌套在大型输入的特征和参数中。此外,MDM允许从低分辨率到高分辨率的渐进训练计划,从而在优化高分辨率生成方面取得了显著的改进。作者在各种基准测试中展示了他们方法的有效性,包括类条件图像生成、高分辨率文本到图像和文本到视频应用。值得注意的是,他们可以在高达1024x1024像素的分辨率下训练一个像素空间模型,并使用仅包含1200万张图片的CC12M数据集展示了强大的零散泛化能力。

链接:https://www.aminer.cn/pub/65372d08939a5f40823b2cf5/?f=cs
21. In-Context Learning Creates Task Vectors
这篇论文探讨了大型语言模型(LLMs)中的上下文学习(ICL)机制。尽管ICL已经成为一种强大且新兴的学习范式,但其内在机制仍不太为人所理解。尤其是将其映射到“标准”机器学习框架中时,即使用训练集 S S S来寻找某个假设类中的最佳拟合函数 f ( x ) f(x) f(x)。本文通过展示ICL学习的函数结构通常非常简单:它们对应于仅使用查询 x x x和从训练集计算出的单个“任务向量”的变压器LLM。因此,ICL可以被视为将 S S S压缩成一个任务向量 θ ( S ) \boldsymbol{\theta}(S) θ(S),然后使用此任务向量来调节变换器以产生输出。本文通过在多种模型和任务上进行全面的实验来支持上述主张。
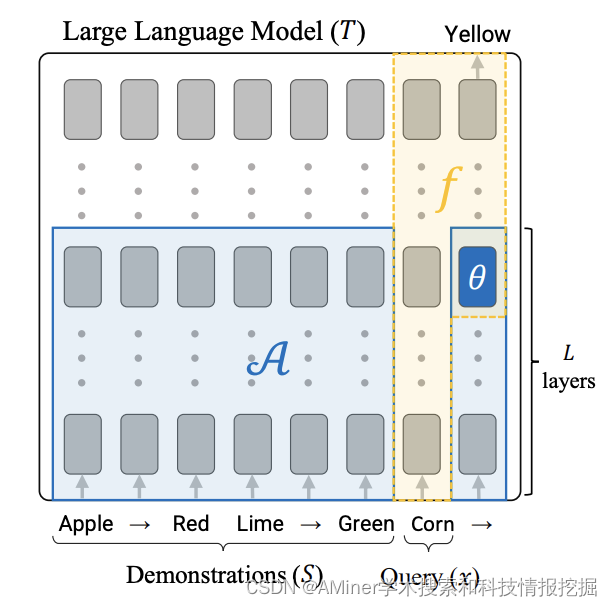
链接:https://www.aminer.cn/pub/65387a42939a5f40829806ab/?f=cs
22. CodeFusion: A Pre-trained Diffusion Model for Code Generation
这篇论文介绍了一种名为CodeFusion的预训练扩散模型,用于代码生成。现有的自动回归代码生成模型在生成代码时存在一个限制,即不能轻易地重新考虑之前生成的令牌。CodeFusion通过迭代去噪一个基于编码自然语言的条件程序,从而解决了这一问题。作者在Bash、Python和Microsoft Excel条件格式化(CF)规则的自然语言到代码生成任务上评估了CodeFusion。实验结果表明,CodeFusion(7500万参数)在 top-1 精度上与最先进的自动回归系统(3.5亿-1750亿参数)相当,并且在top-3和top-5精度上由于其更好的多样性与质量平衡而优于它们。
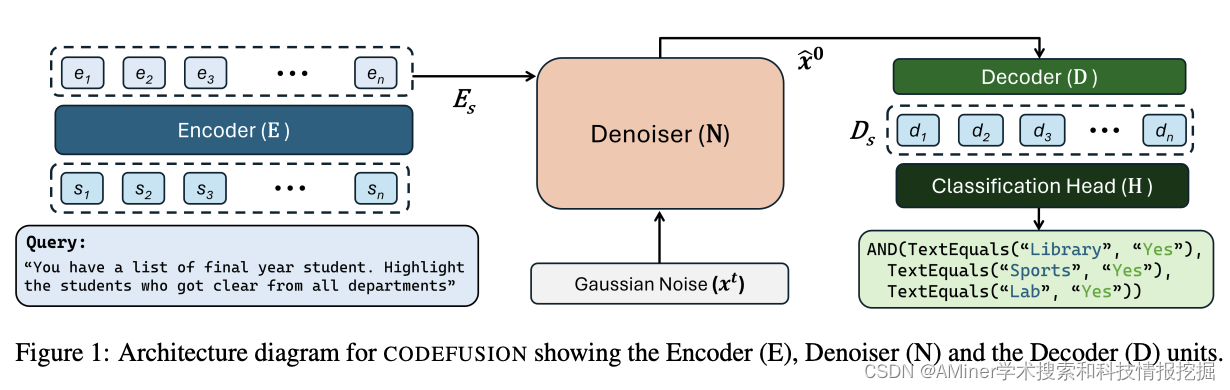















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









