







大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
这篇论文探讨了如何利用大型语言模型从头开始撰写有根据且结构化的长篇文章,其广度和深度与维基百科页面相当。这个问题尚未得到充分研究,但在写作前的阶段提出了新的挑战,包括如何研究主题并制定提纲。作者提出了STORM,一个通过检索和多角度提问合成主题提纲的写作系统。STORM通过发现研究给定主题的不同视角、模拟作者基于可信的互联网来源向话题专家提出问题的对话,以及 curated 收集的信息来创建提纲,来模拟写作前的阶段。为了评估,作者整理了FreshWiki,一个最近的高质量维基百科文章数据集,并制定了一个评估提纲阶段的评估指标。他们还收集了经验丰富的维基百科编辑的反馈。与基于提纲驱动的检索增强型基线生成的文章相比,更多的STORM文章被认为是有组织的。专家反馈还帮助识别了生成有根据的长文章的新挑战,例如源偏见转移和无关事实的过度关联。
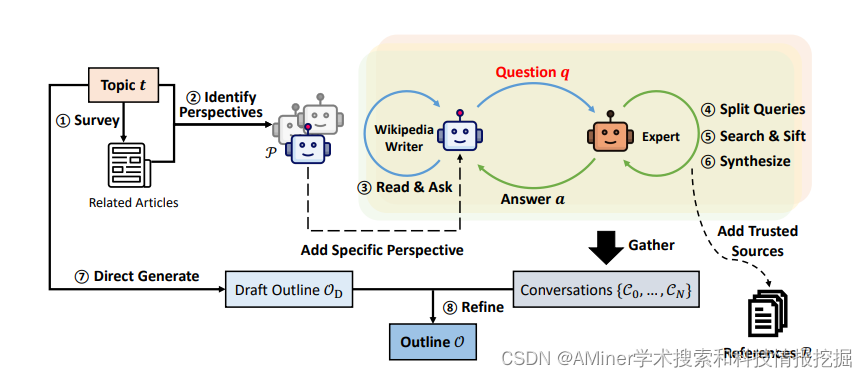
链接:https://www.aminer.cn/pub/65d80195939a5f408243e904/?f=cs
2.Can Large Language Models Reason and Plan?
这篇论文主要探讨了大型语言模型(Large Language Models, LLMs)是否能够进行推理和规划。文章主要包括对大型语言模型能力的评估,即分析LLMs在理解和生成语言方面的表现,探讨它们是否能够超越简单的模式匹配或重复训练数据中的信息;对推理能力的探讨,即研究LLMs是否能够进行逻辑推理,包括理解因果关系、推导结论以及处理抽象概念;对规划能力的评估,即分析LLMs是否能够理解长期目标,并制定实现这些目标的计划或策略;自我批判的比较,即研究人类如何通过自我批评来纠正错误,并探讨LLMs是否具备类似的能力;实验和证据,即提供实验证据来支持或反驳LLMs在推理和规划方面的能力;潜在的限制和未来的研究方向,即讨论LLMs目前存在的限制,以及如何改进这些模型,以便它们在未来能够更好地进行推理和规划。
链接:https://www.aminer.cn/pub/65ea772a13fb2c6cf61f70b6/?f=cs
3.DéjàVu: KV-cache Streaming for Fast, Fault-tolerant Generative LLM Serving
这篇论文主要介绍了一种名为DéjàVu的系统,旨在解决分布式大型语言模型(LLM)服务中的三个关键挑战:一是管道并行部署中的气泡问题:在管道并行部署中,由于提示(prompt)和令牌(token)处理的双模延迟特性,会形成“气泡”,导致硬件加速器利用率低下。二是GPU内存过度配置:为了应对大型模型可能出现的内存需求峰值,往往需要过度配置GPU内存,这样既浪费资源,又降低了内存利用效率。三是故障恢复时间长:在出现故障时,传统的系统需要较长时间来恢复,这期间系统无法正常提供服务。DéjàVu系统通过一个高效的关键值(KV)缓存流媒体库——DéjàVuLib来解决这些问题。具体来说,作者提出并实现了以下解决方案:一是提示-令牌分解:通过高效的方式分解提示和令牌处理,减少管道中的气泡,提高流水线的连续性和硬件加速器的利用率。二是微批次交换:为了有效管理GPU内存,引入了微批次交换机制,这允许在不同的任务之间动态分配GPU内存,从而避免内存过度配置。三是状态复制:为了提高系统的容错能力,作者实现了状态复制机制,在发生故障时能够快速恢复服务,减少系统的停机时间。论文还强调了这些解决方案在各种大规模模型和云部署中的有效性。通过这些方法,可以显著提高生成式LLM服务的速度、效率和可靠性。
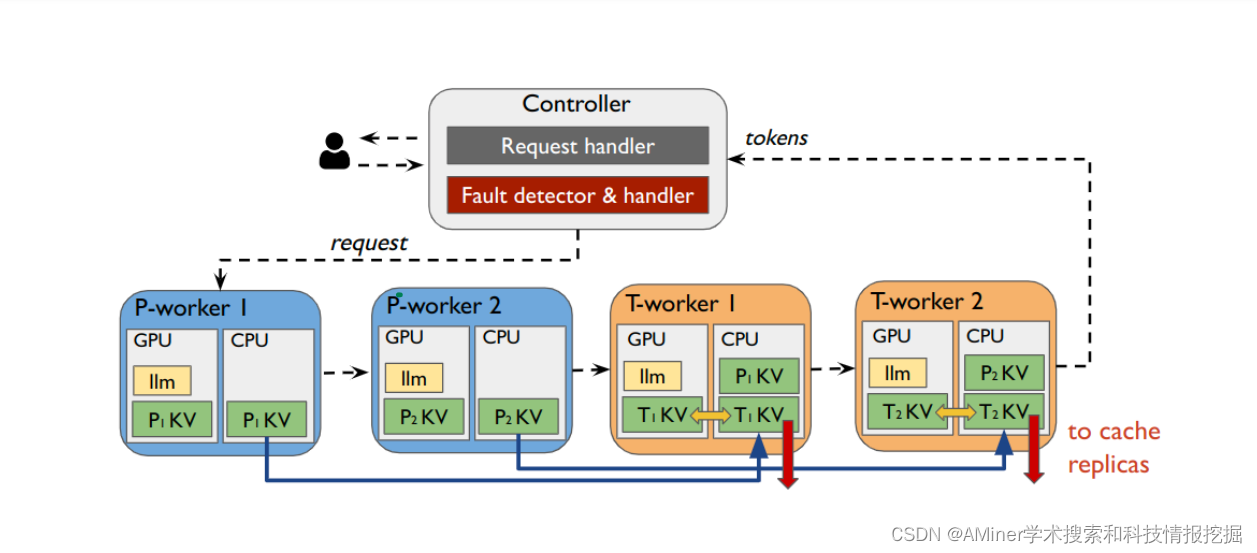
链接:https://www.aminer.cn/pub/65e7dcc013fb2c6cf6fddcf5/?f=cs
4.Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy
这篇论文主要介绍了一项研究,探讨了大型语言模型(LLM)的预测能力是否可以与人类群体的预测准确性相媲美。传统的人类预测准确性依赖于“群体智慧”效应,即通过汇总多个个体预测者对未来事件的预测来显著提高预测准确性。过去的研究表明,作为个体预测者的前沿LLM在与人类群体预测锦标赛汇总相比较时表现不佳。在这项研究中,作者扩展了这一研究领域,通过使用由12个LLM组成的群体(LLM 群体)来预测。研究分为两部分:第一部分:作者将LLM群体对31个二元问题的预测与一个由925名人类预测者组成的群体在一个三个月的预测锦标赛中的预测进行了比较。预先注册的主要分析显示,LLM群体的表现优于简单的无信息基准,并且与人类群体的表现没有统计学上的差异。在探索性分析中,作者发现这两种方法在中等效应大小等效边界方面是相当的。还观察到一致性效应,平均模型预测显著高于50。第二部分:作者测试了是否可以通过利用人类认知输出来提高LLM(GPT-4和Claude 2)的预测准确性。研究发现,两种模型的预测准确性都从接触到中位数人类预测的信息中受益,通过这种信息提高准确性,准确性提高了17%。然而,这种结合了人类和机器预测的平均值不如单独使用人类预测准确。综上所述,这项研究表明,LLM可以通过简单的预测汇总方法实现与人类群体预测锦标赛相媲美的预测准确性,这复制了“群体智慧”效应,为LLM在社会各领域的应用开启了可能性。
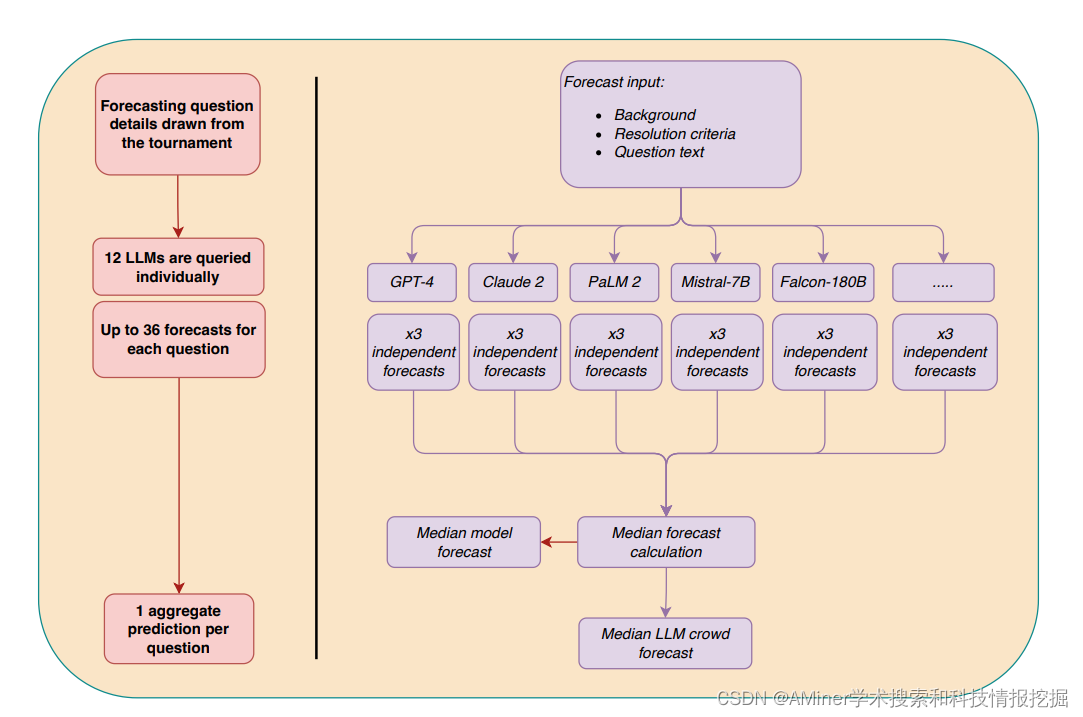
链接:https://www.aminer.cn/pub/65e14a1d13fb2c6cf612d425/?f=cs
5.Artifacts or Abduction: How Do LLMs Answer Multiple-Choice Questions Without the Question?
这篇论文探讨了大型语言模型(LLM)在多项选择题解答(MCQA)中的表现。通常,MCQA被用来评估LLM。作者调查了LLM是否仅凭选项提示就能完成MCQA,即模型必须仅从选项中选择正确答案。在三个MCQA数据集和四个LLM中,这种提示在12/12情况下胜过了大多数基线,准确率提高了最多0.33。为了帮助解释这种行为,作者对记忆、选择动态和问题推断进行了深入的黑色盒子分析。主要发现有三点。首先,我们没有找到选择唯一准确性的来源仅仅是记忆。其次,个体选择的前验并不能完全解释选择唯一准确性,这暗示LLM利用了选择的小组动态。第三,LLM具有一些从选项中推断相关问题的能力,有时甚至可以与原始问题相匹配。作者希望这项研究能推动在MCQA基准测试中使用更强的基线、设计稳健的MCQA数据集,以及进一步解释LLM决策过程的努力。
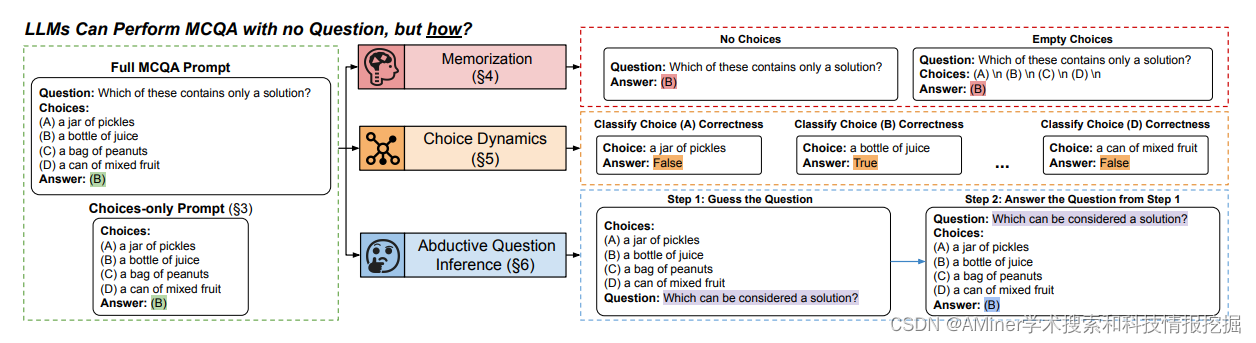
链接:https://www.aminer.cn/pub/65d5654f939a5f40828f2382/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









