






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
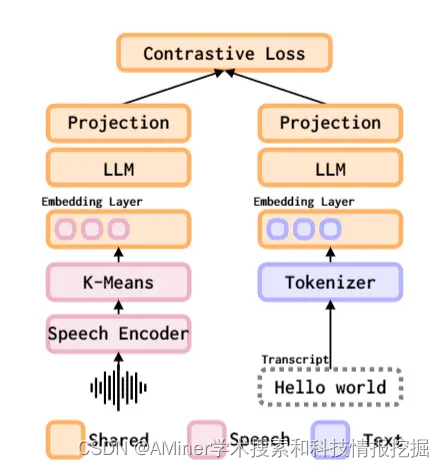
1.Transforming LLMs into Cross-modal and Cross-lingual Retrieval Systems
这篇论文提出了一种将大型语言模型(LLM)转化为跨模态和跨语言检索系统的方法。由于大型语言模型是在仅包含文本数据的语料库上训练的,而这些数据远远超出了具有配对语音和文本数据的语言范围,因此,该论文提出使用LLM来初始化多模态的检索系统。与传统方法不同,该系统在LLM预训练阶段不需要语音数据,并可以利用LLM的多语言文本理解能力来匹配在检索训练阶段未见过的语音和文本。该多模态的LLM基础检索系统尽管只在21种语言上进行训练,但却能够匹配102种语言中的语音和文本。研究发现,该系统在所有这些语言上的平均Recall@1达到了10,并且优于之前在所有102种语言上专门训练的系统。此外,该模型还展示了跨语言语音和文本匹配的能力,并且通过可用的机器翻译数据进一步增强了这一能力。
链接:https://www.aminer.cn/pub/660cb7f713fb2c6cf66b3b2d/?f=cs
2.Evaluating LLMs at Detecting Errors in LLM Responses
本文研究了大语言模型(LLM)在检测自身回答错误方面的表现。随着LLM在各种任务中的广泛应用,检测其回答中的错误变得越来越重要。然而,目前关于LLM回答错误检测的研究很少。由于许多NLP任务具有主观性,收集LLM回答的错误注释极具挑战性,因此以往的研究主要关注实际价值不大或错误类型有限的任务(如单词排序、总结的忠实性等)。本文介绍了ReaLMistake,这是首个包含由LLM做出的客观、现实和多样化的错误检测基准。ReaLMistake包含了三个具有挑战性和实际意义的任务,引入了四个类别的客观可评估错误(推理正确性、指令遵循性、上下文忠实性和参数化知识),从而在GPT-4和Llama 2 70B的回答中诱发出专家标注的自然观察到的和多样化的错误。我们使用ReaLMistake评估了基于12个LLM的错误检测器。研究发现:1)顶级LLM如GPT-4和Claude 3能够以非常低的召回率检测出LLM做出的错误,所有基于LLM的错误检测器的表现都远远不如人类。2)基于LLM的错误检测器的解释缺乏可靠性。3)基于LLM的错误检测对提示中的小变化很敏感,但仍然难以改进。4)改进LLM的流行方法,包括自一致性和多数投票,并不能提高错误检测性能。

链接:https://www.aminer.cn/pub/660f5aea13fb2c6cf6543daa/?f=cs
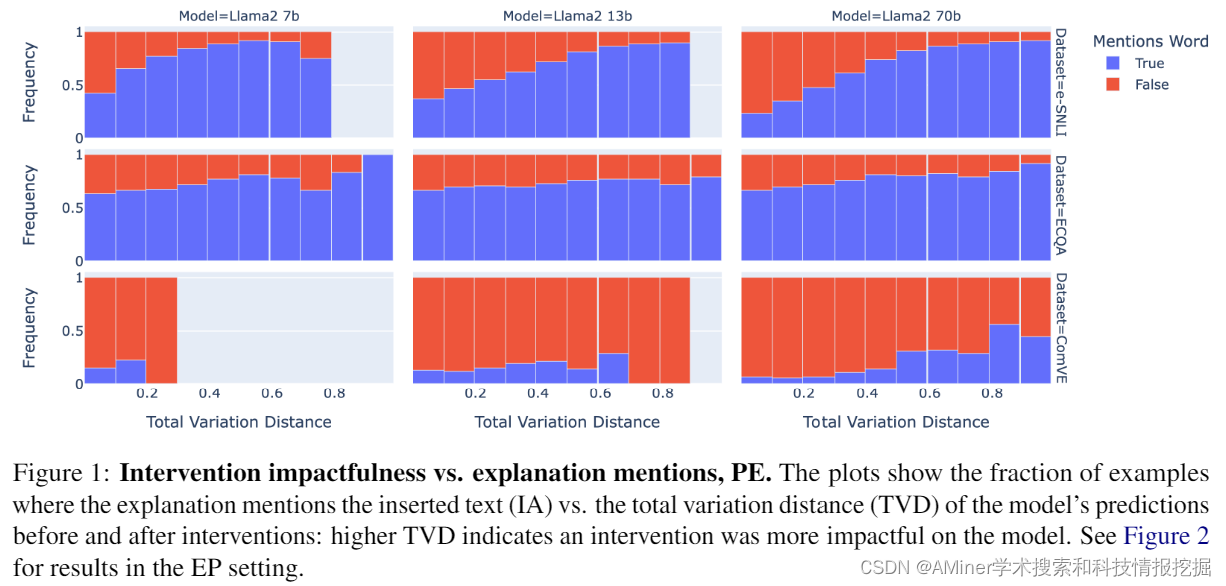
3.The Probabilities Also Matter: A More Faithful Metric for Faithfulness of Free-Text Explanations in Large Language Models
为了监管先进的人工智能系统,了解其决策过程非常重要。当被要求时,大型语言模型(LLM)可以提供听起来合理且能获得人类标注者高评分的自然语言解释或推理痕迹。然而,这些解释的忠实度如何,即是否真正捕捉到模型预测因素,目前尚不清楚。在这项工作中,我们引入了基于输入干预的忠实度测试的关联解释忠实度(CEF)指标。之前在此类测试中使用的指标只考虑了预测中的二进制变化。我们的指标考虑了模型预测标签分布的总变化,更准确地反映了解释的忠实度。然后,我们通过在Atanasova等人(2023)的Counterfactual Test(CT)上实例化CEF来引入关联反事实测试(CCT)。我们在三个NLP任务上评估了来自Llama2家族的少数样本提示LLM生成的自由文本解释的忠实度。我们发现,我们的指标衡量了CT所忽视的忠实度的方面。
链接:https://www.aminer.cn/pub/660f5aea13fb2c6cf6543c06/?f=cs
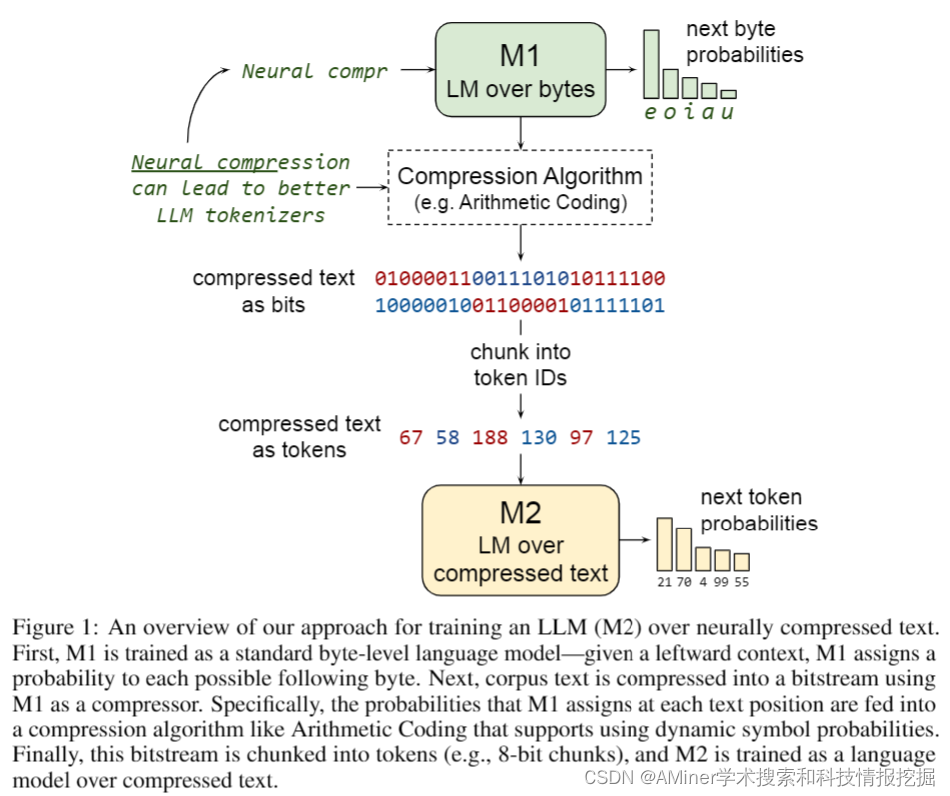
4.Training LLMs over Neurally Compressed Text
这篇论文探讨了在高度压缩的文本上训练大型语言模型(LLM)的构想。与标准亚词素分词器相比,神经文本压缩器能实现更高的压缩率。如果能够直接在神经压缩的文本上训练LLM,这将在培训和服务的效率上带来优势,并使处理长文本跨度变得更加容易。但实现这一目标的主要障碍是强烈的压缩往往会产生晦涩的输出,不适合学习。特别是,我们发现通过算术编码简单压缩的文本不适合LLM学习。为克服这一问题,我们提出了Equal-Info Windows,这是一种新颖的压缩技术,将文本分割成块,每个块压缩到相同的比特长度。使用这种方法,我们证明了在神经压缩文本上的有效学习,并且随着规模的增加而提高,在困惑度和推理速度基准测试中大幅超越了字节级基线。虽然我们的方法在参数计数相同的模型上的困惑度不如亚词素分词器,但它具有更短的序列长度的优势。更短的序列长度需要的自动回归生成步骤较少,可以减少延迟。最后,我们详细分析了有助于可学习性的属性,并提供了具体的建议,以进一步改进高压缩分词器的性能。
链接:https://www.aminer.cn/pub/660f5aea13fb2c6cf6543dc3/?f=cs
5.Are large language models superhuman chemists?
大型语言模型(LLM)因其能够处理人类语言并在未明确训练的Task上表现出色而受到广泛关注。这对于化学科学领域具有重要意义,因为该领域面临着小而多样化数据集的问题,这些数据集通常以文本形式存在。LLM已经在解决这些问题方面显示出潜力,并且越来越多地被用来预测化学性质、优化反应,甚至自主设计并执行实验。然而,我们对LLM的化学推理能力的系统性理解仍然非常有限,这需要改进模型并减轻潜在的危害。在这篇论文中,我们引入了“ChemBench”自动化框架,旨在严格评估最先进的LLM在化学知识推理能力方面与人类化学家相比的表现。我们为化学科学的各个子领域精心挑选了7000多个问答对,评估了领先的开源和闭源LLM,并发现最好的模型在我们的研究中平均表现优于最佳的人类化学家。然而,模型在某些对人类专家来说简单的化学推理任务上仍然存在困难,并提供了过于自信的误导性预测,例如关于化学物质的安全性。这些发现强调了双重视角:尽管LLM在化学任务上表现出色,但进一步研究至关重要,以提高它们在化学科学中的安全性和实用性。我们的发现还表明,需要对化学课程进行调整,并强调了继续开发评估框架以改进安全和实用的LLM的重要性。

链接:https://www.aminer.cn/pub/660cb81113fb2c6cf66b6a94/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









