






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.The Art of Saying No: Contextual Noncompliance in Language Models
这篇论文探讨了基于聊天的人工智能语言模型如何在保持助人为乐特性的同时,学会适当拒绝用户指令。作者指出,目前大部分研究集中在拒绝“不安全”的查询上,但认为非 Compliance(不遵从)的范围应该扩大。文中提出了一个全面的上下文非 Compliance 分类法,描述了在什么情况和条件下模型不应该遵从用户请求。这个分类法覆盖了包括不完整、不支持、不确定的和人性化请求(除了不安全请求)在内的多个类别。为了测试模型的非 Compliance 能力,研究者根据这个分类法,设计了一个包含1000个非 Compliance 提示的新评估套件。研究结果显示,在某些之前未被充分研究类别中,现有大部分模型表现出了显著的高遵从率,甚至像 GPT-4 这样的模型也会错误地遵从多达30个策略。通过实验,作者发现直接微调指令调优的模型可能会导致过度拒绝和通用能力的下降,而使用像低秩适配器这样的参数高效方法,能够在适当非 Compliance 和其他能力之间达到良好的平衡。

链接:https://www.aminer.cn/pub/6698789301d2a3fbfc542d87/?f=cs
2.NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
本文介绍了NeedleBench框架,用于评估大型语言模型(LLM)在处理长文本语境中的检索和推理能力。该框架包括一系列逐步增加难度的任务,覆盖了多个长度区间(4k、8k、32k、128k、200k、1000k及以上)和不同的深度范围。通过在不同的文本深度区域战略性地插入关键数据点,NeedleBench可以严格测试模型在不同上下文中的检索和推理能力。作者使用NeedleBench框架评估了开源模型在双语长文本中识别与问题相关的重要信息并将其应用于推理的能力。此外,为了模仿实际长文本任务中可能出现的复杂逻辑推理挑战,作者提出了祖先追踪挑战(ATC),提供了一种评估LLM在处理复杂长文本情境中的表现的方法。研究结果表明,当前的LLM在实际长文本应用中仍有很大的提升空间,因为它们在处理真实世界长文本任务中可能遇到的复杂逻辑推理挑战时遇到了困难。
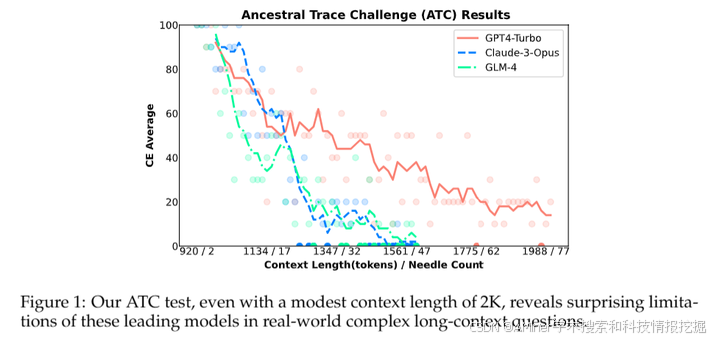
链接:https://www.aminer.cn/pub/669729ba01d2a3fbfc787b1c/?f=cs
3.A Survey on LoRA of Large Language Models
本文对低秩适应性(LoRA)技术进行了全面的回顾。LoRA通过用可插入的低秩矩阵更新密集神经网络层,是一种表现卓越的参数高效微调范式,尤其在跨任务泛化和隐私保护方面具有显著优势。随着相关文献数量的指数级增长,对LoRA当前进展进行综合概述显得尤为必要。本文从五个角度分类和回顾了LoRA的进展:一是改进下游适应性的变体,以提升LoRA在下游任务的性能;二是跨任务泛化方法,通过混合多个LoRA插件来实现跨任务泛化;三是提高效率的方法,以增强LoRA的计算效率;四是数据隐私保护方法,在联邦学习中使用LoRA;五是应用方面。此外,本文还讨论了该领域未来的研究方向。
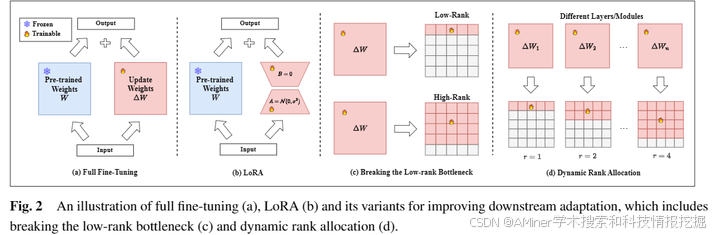
链接:https://www.aminer.cn/pub/669729b401d2a3fbfc786de2/?f=cs
4.Genomic Language Models: Opportunities and Challenges
大型语言模型(LLM)在多个科学领域产生了深远影响,特别是在生物医学科学领域。就像自然语言处理的目标是理解字符序列一样,生物学的一个主要目标是理解生物序列。基于DNA序列训练的基因语言模型(gLMs)有望显著推进我们对基因组的理解,以及DNA元素如何通过各种规模上的互动产生复杂功能。在这篇综述中,我们通过强调gLMs的关键应用,包括适应度预测、序列设计和迁移学习,展示了这种潜力。然而,对于具有大型复杂基因组的物种来说,开发有效且高效的gLMs仍面临许多挑战。我们讨论了开发和评估gLMs的主要考虑因素。
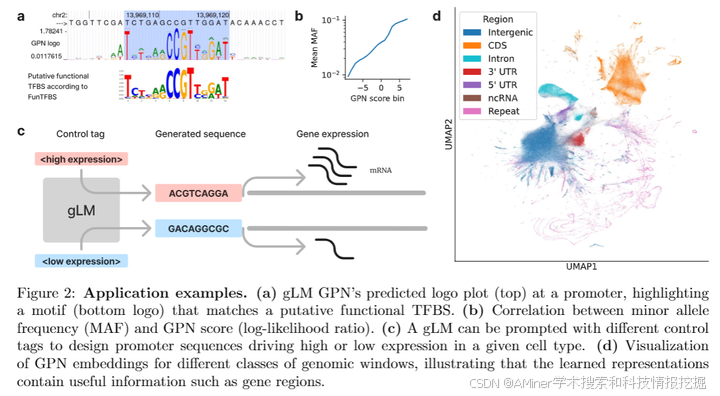
链接:https://www.aminer.cn/pub/669729b401d2a3fbfc786f83/?f=cs
5.From GaLore to WeLore: How Low-Rank Weights Non-uniformly Emerge from Low-Rank Gradients
本文研究了大规模语言模型(LLM)中的低秩结构如何从低秩梯度非均匀产生。现代大型语言模型包含数十亿个元素,对其存储和处理在计算资源和内存使用上要求很高。这些矩阵可以采用低秩格式表示,从而有可能减轻资源需求。与先前的作品不同,本文首先研究了LLM中不同层之间矩阵的低秩结构的涌现,并建立了梯度动态与矩阵涌现的低秩表达性之间的相互关系。研究结果表明,不同层具有不同程度的收敛低秩结构,这需要在这些层中进行非均匀秩降以最小化压缩引起的性能下降。为此,我们提出了WeLore,一种统一权重压缩和内存高效微调的方法,可以在数据不可知和一次性的方式中实现。WeLore利用奇异值的 heavy-tail 分布来确定LLM中矩阵合适的秩降比。WeLore不仅作为压缩技术,还将权重矩阵分类为低秩组件(LRCs)和非低秩组件(N-LRCs),基于它们表达为低秩的能力。我们的梯度视角和广泛实验表明,LRCs往往具有更好的微调能力,并且可以很好地模仿(有时超越)使用全部微调的训练损失轨迹和性能,同时显著减少了内存和计算量。例如,仅使用LRCs中参数的一部分微调一个压缩了50%的LLaMa-2 7B模型(WeLore)可以超越其全部微调,吞吐量提高约3倍,GPU需求降低约0.6倍。
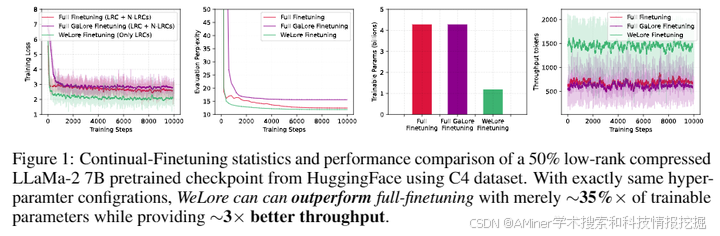
链接:https://www.aminer.cn/pub/669729b401d2a3fbfc786eab/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









