






手势识别和手势关键点检测是计算机视觉领域中的一个重要研究方向,涉及到从图像或视频中检测人手的位置和姿态信息,并推断出手势的意义。以下是一些可能用到的方法和技术:
手势识别
-
基于深度学习的手势识别手势识别(Gesture
Recognition)是一种复杂的技术,它涉及多种技术和算法来理解和解析人类手部动作的含义。近年来,随着深度学习技术的发展,尤其是卷积神经网络(CNNs)和递归神经网络(RNNs)的应用,手势识别的准确性和实时性有了显著提升。例如,可以构建包含多个卷积层和全连接层的深度网络架构,通过训练来识别各种手势类别。其中,3D
CNNs能有效利用空间和时间维度的信息,对于视频中的连续手势识别特别有用。 -
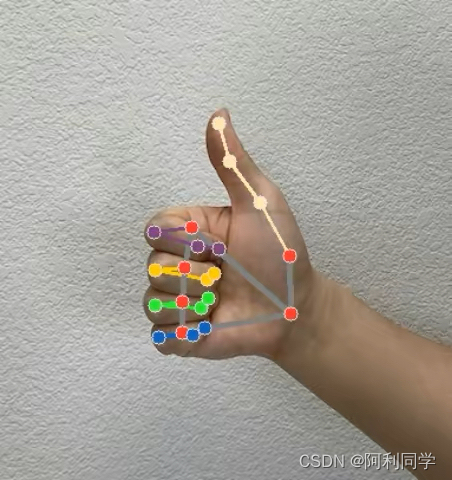
在基于深度学习的手势识别中,关键点检测扮演着至关重要的角色。通过训练如OpenPose之类的模型,系统能够定位手部乃至整个身体的关键骨骼点,进而依据关键点间的几何关系确定手势的具体形态。例如,模型可以从图像中预测出每根手指的弯曲程度和指向方向,以及手掌相对于其他肢体部位的空间位置,这些信息共同构成手势的表达内容。
-
此外,为了增强手势识别系统的鲁棒性和准确性,常常会引入传感器辅助数据。例如,在智能穿戴设备中集成陀螺仪和加速度计等传感器,能够捕获手部细微的运动变化,尤其是在光线条件差或者背景复杂的情况下,传感器数据与视觉信息相结合,可极大地改善手势识别性能。
. 
在训练阶段,可以使用大规模手势数据集(如MSR Action3D、NTU RGB+D等)来训练深度学习模型。在测试阶段,可以将测试图像或视频输入到深度学习模型中,然后根据输出结果推断出手势的意义。
基于传统机器学习的手势识别
- 除了深度学习方法,还可以使用传统机器学习方法进行手势识别。这种方法通常使用手工设计的特征提取器(如HOG、SIFT等)来提取手势的特征,然后将这些特征输入到分类器(如SVM、随机森林等)中进行分类
基于关键点检测的手势识别
- 手势识别通常需要先进行手势关键点检测,即从图像或视频中检测出手的位置和姿态信息。这可以通过使用深度学习模型(如OpenPose、HandNet等)来实现。
- 其不仅限于手势识别,也涵盖了人体整体的姿态估计。姿态识别技术不仅可以应用于手势理解,还在虚拟现实、运动分析、医疗康复等诸多领域有着重要应用价值。例如,人体关键点检测模型,如OpenPose,能够同时估计整个人体的多个关键点,进而构建人体骨架模型,精确捕捉人体各部分的位置和姿态变化。
- 在人体姿态识别的代码示例中,首先进行了人脸检测,随后针对检测到的人脸区域进行姿态估计。这里使用了深度学习模型对输入图像进行前向传播,并解析输出以获得关键点坐标,最后在图像中标记出这些关键点,实现了对人脸姿态的实时估计。

在手势关键点检测阶段,深度学习模型通常被训练用于检测手的关键点位置(如手指、掌心等),然后根据这些关键点的空间关系推断出手的姿态信息。
结合传感器的手势识别
除了使用图像或视频作为输入,还可以结合其他传感器(如陀螺仪、加速度计等)来提高手势识别的准确性和鲁棒性。这些传感器通常用于捕捉手的运动信息,从而帮助更准确地识别手势。

部分代码
model = HandPoseModel(num_keypoints=num_keypoints).to(device)
model.load_state_dict(torch.load(model_path))
model.eval()
# 图像预处理
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(input_size),
transforms.ToTensor(),
])
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
# 图像预处理
image = transform(frame).unsqueeze(0).to(device)
with torch.no_grad():
# 前向传播
output = model(image)
# 解析关键点
keypoints = output.squeeze().cpu().numpy()
keypoints = (keypoints * input_size[0]).astype(int)
# 可视化关键点
for i in range(num_keypoints):
x, y = keypoints[i]
cv2.circle(frame, (x, y), 4, (0, 255, 0), -1)
cv2.imshow("Hand Keypoints", frame)
# 按q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
姿态识别(Pose Estimation):
姿态识别是指从图像或视频中检测和估计人体或物体的姿态信息,包括位置、角度、姿势等。姿态识别可以用于人体动作分析、运动捕捉、交互界面设计等领域。常见的姿态识别任务包括人体关键点检测、人体姿势估计等。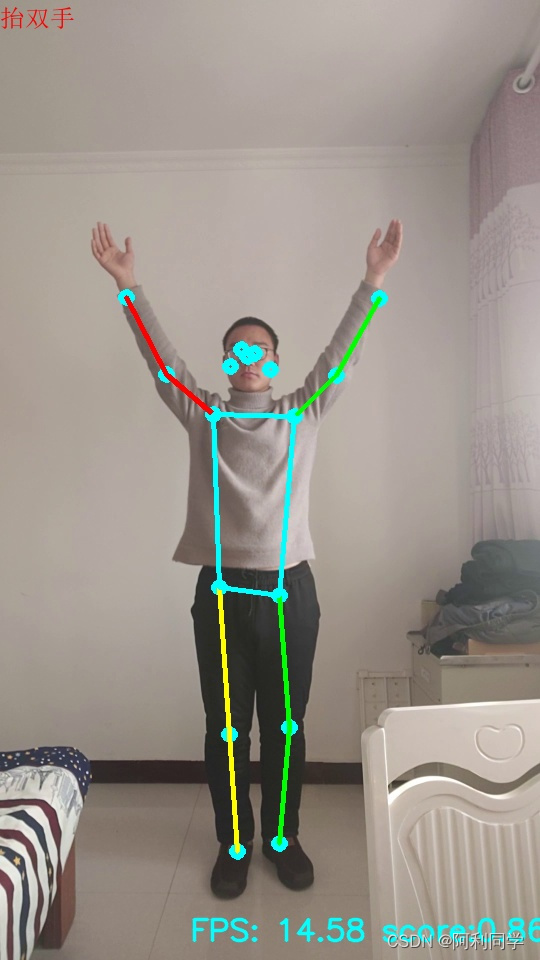
人体关键点检测:人体关键点检测是指从图像或视频中检测出人体的关键点位置,如头部、肩膀、手腕、膝盖等。通常使用深度学习模型(如Hourglass、OpenPose等)进行训练和推断,通过回归或分类的方式预测每个关键点的位置。
人体姿势估计:人体姿势估计是指从图像或视频中估计出人体的姿势信息,即人体各个关节之间的相对位置和角度关系。这可以通过关键点检测的结果来实现,进一步推断出人体的姿势信息。常见的方法包括基于图模型的姿势估计方法、基于深度学习的姿势估计方法等。

部分代码
#qq130939183
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 对每个检测到的人脸进行姿态估计
for (x, y, w, h) in faces:
face_roi = frame[y:y+h, x:x+w]
blob = cv2.dnn.blobFromImage(face_roi, 1.0, (224, 224), (104.0, 177.0, 123.0), swapRB=True, crop=False)
pose_model.setInput(blob)
outputs = pose_model.forward()
# 解析输出,获取姿态信息
# 姿态信息的获取方法因模型而异,请根据使用的姿态估计模型进行调整
# 这里仅作为示例,输出了关键点的坐标
for i in range(0, 68):
x = int(outputs[0, 0, i, 0] * w)
y = int(outputs[0, 0, i, 1] * h)
cv2.circle(face_roi, (x, y), 1, (0, 0, 255), -1)
# 在原图上绘制人脸框和姿态信息
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(frame, 'Pose', (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2, cv2.LINE_AA)
# 显示结果
cv2.imshow('Face and Pose Detection', frame)
# 按下ESC键退出
if cv2.waitKey(1) == 27:
break
# 释放摄像头并关闭窗口
cap.release()
cv2.destroyAllWindows()
人脸识别(Face Recognition):
人脸识别是指从图像或视频中检测和识别出人脸,并对其进行身份认证或验证。人脸识别技术在安防、人机交互、社交网络等方面有着广泛的应用。主要包括人脸检测、人脸对齐和特征提取等步骤。
人脸识别(Face Recognition)则是另一种密切相关的计算机视觉任务,它的主要目的是识别人脸的身份,但同样涉及到了关键点检测和特征提取等步骤。现代人脸识别系统通常包括人脸检测、对齐、特征提取和匹配等阶段。通过高精度的人脸特征表示,如基于深度学习的FaceNet模型提取的嵌入向量,可以高效准确地完成人脸验证和识别任务。

- 人脸检测:人脸检测是指从图像或视频中检测出人脸的位置和边界框。人脸检测通常使用基于机器学习或深度学习的方法,如Haar级联检测器、基于卷积神经网络(CNN)的人脸检测等。
- 人脸对齐:人脸对齐是指将检测到的人脸调整为标准化的形状和姿态,以便后续的特征提取和比对。常见的方法包括基于关键点的人脸对齐和基于变换的人脸对齐等。
- 特征提取:特征提取是指从经过对齐的人脸图像中提取出具有区分性的特征表示。常用的特征提取方法包括局部二值模式(Local Binary
Patterns, LBP)、主成分分析(Principal Component Analysis,
PCA)和深度学习模型(如卷积神经网络、人脸识别模型等)。

总结,计算机视觉、图像处理、毕业辅导、作业帮助、代码获取,远程协助,代码定制,私聊会回复!
姿态识别和人脸识别是计算机视觉领域中非常重要的研究方向。它们通过使用深度学习或传统机器学习方法,从图像或视频中提取出人体或人脸的关键信息,以实现不同的应用场景。
手势识别和手势关键点检测是计算机视觉领域中的一个重要研究方向。它可以使用基于深度学习或传统机器学习的方法来实现,并且可以结合传感器来提高识别精度。

















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











