









一、背景介绍
政府间气候变化委员会 IPCC(Intergovernmental Panel on Climate Chang)是世界气象组织(WMO)及联合国环境规划署(UNEP)于1988年联合建立的政府间机构。
IPCC在1997年和2000年分别发布了《1996 年 IPCC 国家温室气体清单指南修订本》和《国家温室气体清单优良作法指南和不确定性管理》。在《1996年指南》中,IPCC主要使用了排放因子法来进行温室气体估算。后续,在《2006 年 IPCC 国家温室气体清单指南》中IPCC介绍了质量平衡法,还提到通过持续排放监测来测量、计算排放因子或者温室气体的排放量。
此外,很多组织基于IPCC提出的计算方法推出了不同的文件来指导温室气体的盘查,包括计算公式、缺省因子等。本文主要介绍IPCC内的三种计算方法,即排放因子法、质量平衡法和实测法。
二、温室气体计算方法介绍
排放因子法
1.特点
排放因子法是目前适用范围最广、应用最为普遍的一种碳核算办法,有成熟的核算公式、活动数据和排放因子数据库,且有大量的应用实例可供参考,但在排放系统自身较为复杂或多变的情况下处理能力相对较差。
2.计算公式
排放因子法有一个基础的通用公式:
温室气体排放量(Σ)= 活动数据(AD)×排放因子(EF)×全球变暖潜值(GWP)
其中,AD(Activity Data)是产生温室气体的活动或设施消耗的活动数据,如非清洁能源的消耗量、净购入的电量、货物运输的里程数等。EF(Emission Factor)是与活动数据对应的因子。每一种温室气体都需要一个对应的因子来进行计算。我们可以从《2006年指南》中寻找因子,也可以使用特定国家排放因子来进行替代。
小贴士:需要注意的是,在《2006年指南》中,有效排放因子有时需要经过计算来获得,这是因为温室气体的排放过程存在差异,为获取精度更高的温室气体排放量,需要对因子做细化。这一点会在后文中进行举例示意。
需要注意的是,在《2006年指南》中,有效排放因子有时需要经过计算来获得,这是因为温室气体的排放过程存在差异,为获取精度更高的温室气体排放量,需要对因子做细化。这一点会在后文中进行举例示意。
GWP(Global Warming Potential)全球变暖潜能值是温室效应的一个衡量指数,指在100年的时间框架内,某种温室气体产生的温室效应对应于相同效应的二氧化碳的质量。二氧化碳被作为参照气体,是因为其对全球变暖的影响最大。GWP越大表示该温室气体在单位质量单位时间内产生的温室效应越大。通过GWP的换算,我们可以得到不同的温室气体对应的二氧化碳当量。可以通过IPCC发布的气候变化评估报告,找到不同的温室气体对应的GWP值。
3、适用范围
该方法适用于国家、省份、城市等较为宏观的核算层面,可以粗略地对特定区域的整体情况进行宏观把控。在实际工作中,由于地区能源品质差异、机组燃烧效率不同等原因,各类能源消费统计及碳排放因子测度容易出现较大偏差,导致碳排放核算结果出现误差,因此主要适用于排放源较为稳定、简单的情况。排放因子法由于其适用场景广泛、实施难度较小,是现在主流的估算温室气体排放量的方式。
质量平衡法
质量平衡法的核心原理是根据化学反应原理和物料守恒定律,对进入和离开过程的所有物质流进行跟踪和计量。在此基础上,可以计算出系统的总碳排放量质量平衡法主要有两种应用:
► 温室气体在经过一定时间或过程之后,前后质量发生了变化。这种情况下,可以通过质量差异来估算出温室气体的排放量,并应用相应的GWP值计算出该过程所产生的二氧化碳当量。
► 在农业、林业和其他土地利用的过程中,通过估算碳在一定时间内的变化(有增加和减少),进而计算出该过程所产生的二氧化碳当量。
实测法
实测法基于排放源实测基础数据,通过汇总得到相关碳排放量。实测法依靠实际测算,暂无计算公式,主要包括两种具体方法,即现场测量和非现场测量。
► 现场测量一般是在烟气排放连续监测系统(CEMS)中搭载碳排放监测模块,通过连续监测浓度和流速直接测量其排放量;
► 非现场测量是通过采集样品送到有关监测部门,利用专门的检测设备和技术进行定量分析。
二者相比,由于非现场实测时采样气体会发生吸附反映、解离等问题,现场测量的准确性要明显高于非现场测量。
实测法应用历史较长,方法缺陷小,但数据获取最为困难,因此应用范围相较于前面两种方法更为狭窄,主要适用于小区域下简单生产的碳排放源或有能力获取一手监测数据的自然排放源。
三、排放因子法实例:锅炉使用的天然气的温室气体排放计算
1. 确定活动/设施涉及温室气体种类、范畴
在这个实例中,首先明确锅炉使用的天然气属于固定源燃烧的范畴,涉及的温室气体包括二氧化碳、甲烷、氧化亚氮等。
2. 确定公式
在《IPCC 2006年指南》中,可以找到第2卷-能源中的公式2.1是关于固定源燃烧产生的温室气体排放:

3. 确定排放因子
再通过《IPCC 2006年指南》第2卷-能源中的表2.3(续),我们可以查阅到不同行业的固定源燃烧的缺省排放因子。本例使用了制造工业的缺省因子。
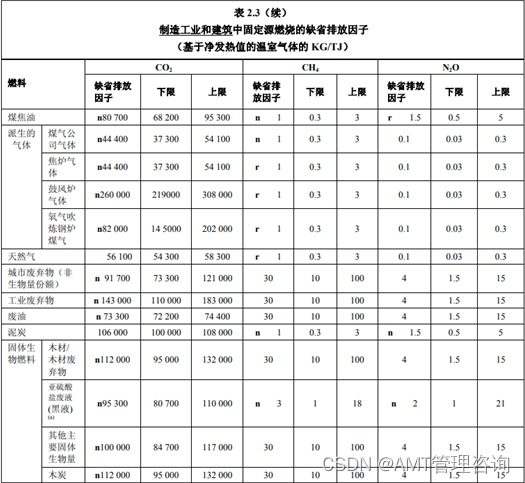
4. 目确定需要计算的活动数据
公式中的燃料消耗量是以TJ为单位的,实际操作中,企业往往会以m³购入和记录天然气的量,因此我们还需要将m³换算为TJ。这里我们使用《中国能源统计年鉴2020》中的天然气热值:38931kj/m³。
5. 计算各温室气体的消耗量
假设企业在盘查中消耗了1万m³天然气,天然气全部被锅炉使用,所产生的温室气体计算方法如下:
二氧化碳排放量
=天然气消耗量*天然气热值*排放因子=100,000m³*38,931KJ/m³*5.61x10-5kg
CO2/KJ=218,402.91kg CO2
甲烷排放量
=天然气消耗量*天然气热值*排放因子=100,000m³*38,931KJ/m³*1x10-9kg
CH4/KJ=3.8931kg CH4
氧化亚氮排放量
=天然气消耗量*天然气热值*排放因子=100,000m³*38931KJ/m³*1x10-10kg
N20/KJ=0.38931kg N2O
6. 确定温室气体的GWP值
根据IPCC发布的《IPCC-GWP-AR6》,其中二氧化碳GWP为1,甲烷GWP为27.9,氧化亚氮GWP为273。
7. 计算最终的温室气体排放当量
最终的二氧化碳排放当量=二氧化碳排放量*二氧化碳GWP+甲烷排放量*甲烷GWP+氧化亚氮排放量*氧化亚氮
GWP=218,402.91*1+3.8931*27.9+0.38931*273=218,617.80912kg CO2e。
小结
碳放核算是有效开展各项碳减排工作、促进经济绿色转型的基本前提,是积极参与应对气候变化国际谈判的重要支撑。碳排放量的计算方法各有特点,适用范围不尽相同。在实际应用中,需要根据具体情况选择合适的方法,通过量化碳排放的数据并分析各环节碳排放的数据,找出潜在的减排环节和方式,对碳中和目标的实现、碳交易市场的运行至关重要。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









