






模型的定义
专用模型:只能针对特定的任务,一个模型解决一个问题
通用大模型:一个模型应对多种任务 & 多种模态
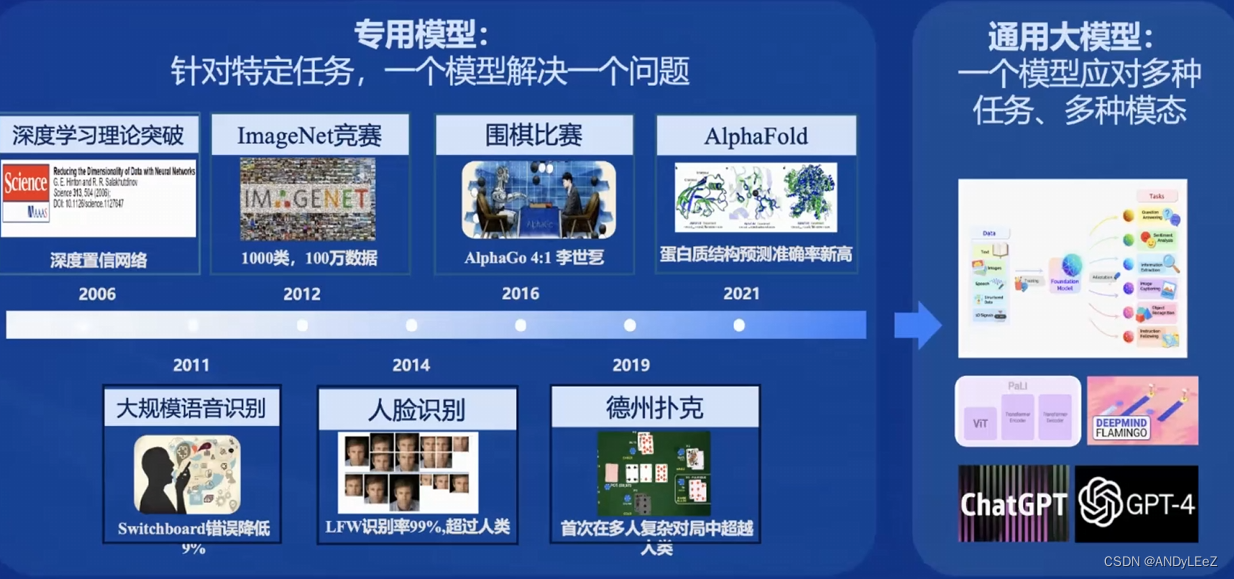
书生模型的发展进程

Internl M2版本差异
根据不同用户需求使用不同大小的模型

新旧版本的InternLM的区别

书生浦语2.0(InternLM2)主要亮点
超长上下文:模型在20万token上下文中,几乎完美实现”大海捞针“
综合性能全面提升:推理、数学、代码提升显著InternLM2-Chat-20B在重点评测上比肩ChatGPT
优秀的对话和创作体验:精准指令跟随,丰富的结构化创作,在AlpacaEval2超越GPT3.5和Gemini Pro
工具调用能力整体升级:可靠支持工具多轮调用,复杂智能体搭建
突出的数理能力和使用的数据分析功能:强大的内生计算能力,加入代码解释后,在GSM8K和MATH达到和GPT-4相仿水平
书生模型的应用升级


模型应用经典流程

书生·浦语开源链条
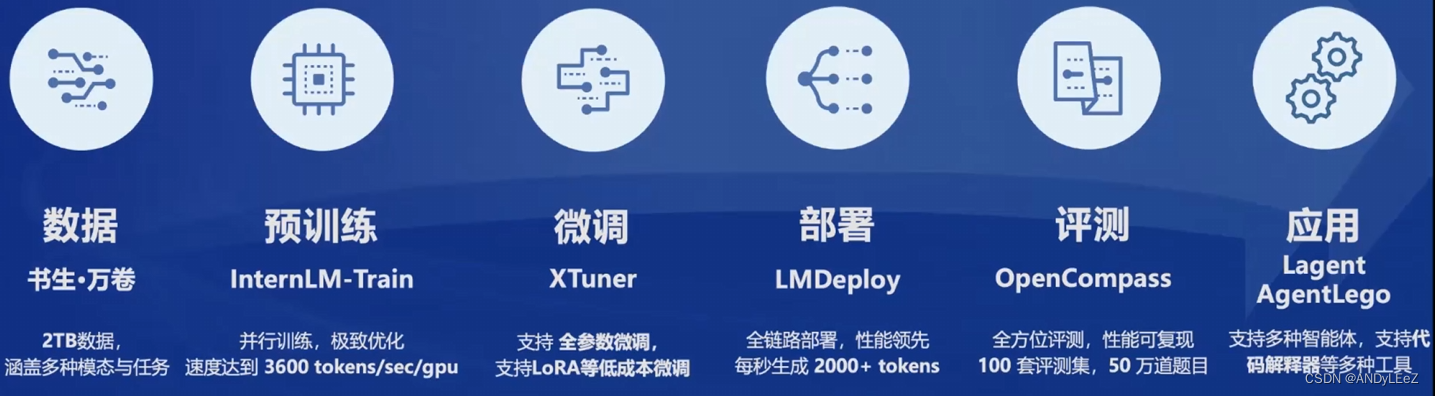
书生数据集

预训练框架

微调框架

开发了多种微调算法,多种微调策略与算法,覆盖各类SFT场景
适配多种开源生态,支持加载HuggingFace、ModelScope模型或数据集
自动优化加速,开发者无需关注复杂的显存优化与计算加速细节。并且能够适配多种硬件,最低只需要8GB显存就能微调7B模型
国内大模型的GAP

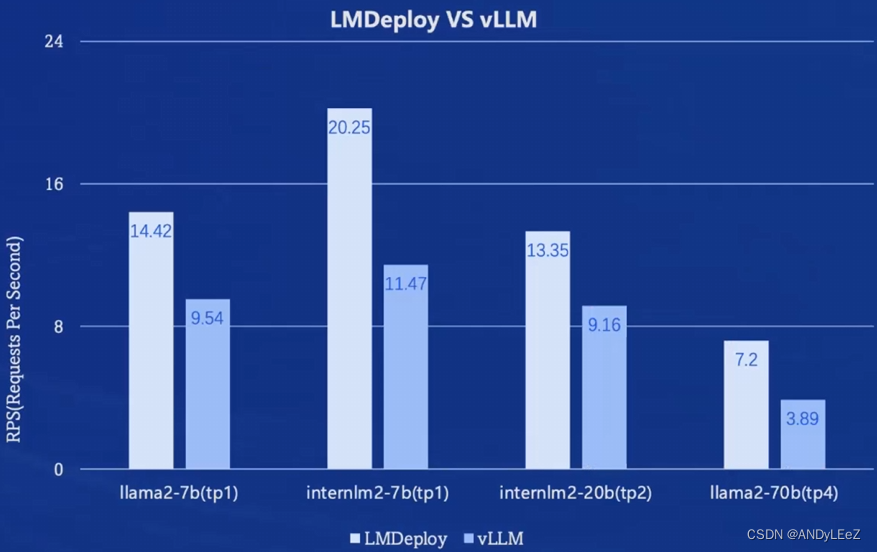
模型部署

部署推理性能对比
InternLM2 技术报告
预训练:
应用了群组查询注意力机制( Group Query Attention,GQA )在推断长序列时能够实现更小的内存占用。预训练阶段使用4k的上下文文本进行训练,然后将训练语料转换为高质量的32k文本进行进一步训练
fine-tune:
经过长文本的预训练后,使用监督微调(SFT)以及人类反馈的强化学习(RLHF)确保模型很好地遵守人类指令并与人类值保持一致。引用了条件在线RLHF (COOL RLHF),采用条件奖励模型来协调不同但可能相互冲突的偏好,并在多轮中执行近端策略优化(PPO),以减轻每个阶段出现的奖励黑客行为
创新点:
1、开源了InternLM2
2、具有200k上下文窗口的设计
3、完善的数据准备指导
4、创新的RLHF训练工具 —— COOL RLHF
Infrastructure
设置了一个高效的预训练框架——InternEvo,允许模型在数千个GPU上进行扩展,通过结合数据并行、张量并行、序列并行和流水线并行,以及各种内存优化技术,提高了训练效率。此外,InternLM2在模型结构上采用了LLaMA架构的设计原则,通过合并权重矩阵和调整矩阵布局来提高训练速度和灵活性。
Pre-train
预训练数据:预训练数据包括从网页、论文、专利和书籍等来源收集的文本数据。这些数据经过标准化、分类、过滤和质量筛选等步骤,以确保数据的丰富性、安全性和高质量。
数据处理:数据首先被转换成指定的格式,然后通过一系列处理步骤,包括规则基础的过滤、数据去重、安全过滤和质量过滤,最终获得高质量的预训练数据。
预训练的设置包括文本化(tokenization)和预训练超参数的选择。InternLM2采用了高效的文本化方法,并根据模型大小调整了学习率和批量大小等超参数。
预训练阶段:
1、4k文本训练,大约90%的训练步骤中,使用长度不超过4096个标记的数据进行训练。如果数据长度超过4096,会将其强制截断,并使用剩余部分进行训练。
2、4k文本训练后过渡到32k上下文数据训练,在长文本训练阶段,调整了Rotary Positional Embedding(RoPE)的基础,以确保对长文本的有效位置编码。
3、通过收集高质量的检索数据和开源数据,对模型进行了特定能力增强训练。这包括推理、数学问题解决和知识记忆等能力。通过这一阶段的训练,模型在编码、推理、问答和考试等方面的性能得到了显著提升。















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









