







Spark Local模式安装
一、实验目的
1.了解Spark的六种运行模式
2.准确理解Spark Local模式运行原理
3.熟练掌握Spark Local模式的安装流程
二、实验原理
目前Apache Spark主要支持三种分布式部署方式:分别是standalone、Spark on mesos和spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以与其他计算框架,比如MapReduce共用一个集群资源,最大的好处是降低运维成本和提高资源利用率(资源按需分配)。
1.Spark运行模式概述
在实际应用中,Spark应用程序的运行模式取决于传递给SparkContext的MASTER环境变量的值,个别模式还需要依赖辅助的程序接口来配合使用,目前所支持的MASTER环境变量由特定的字符串或URL所组成,如下所示。
(1)Local[N]:本地模式,使用多个线程。
(2)Local cluster[worker, core, Memory]:伪分布式模式,可以配置所需要启动的虚拟工作节点的数量,以及每个工作节点所管理的CPU数量和内存尺寸。
(3)Spark://hostname:port:Standalone模式,需要部署Spark到相关节点,URL为Spark Master主机地址和端口。
(4)Mesos://hostname:port:Mesos模式,需要部署Spark和Mesos到相关节点,URL为Mesos主机地址和端口。
(5)YARN standalone/Yarn cluster:YARN模式一,主程序逻辑和任务都运行在YARN集群中。
(6)YARN client:YARN模式二,主程序逻辑运行在本地,具体任务运行在YARN集群中。
此外还有一些用于调试的URL,因为和应用无关,我们在这里就不列举了。
2.Local模式部署及程序运行
Local模式,顾名思义就是在本地运行,如果不加任何配置,Spark默认设置为Local模式。以SparkPi为例,Local模式下的应用程序的启动命令如下:
./bin/run-example org.apache.spark.examples.SparkPi local
在SparkPi代码的具体实现中,是根据用户传入的参数来选择运行模式的,如果需要自己在代码中指定运行模式,可以通过在代码中配置Master为Local来实现,如以下程序所示。
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf()
.setMaster(“local”)
.setAppName(“My application”)
.set(“spark.executor.memory”, “1g”)
val sc = new SparkContext(conf)
当然,为了使应用程序能够更灵活地在各种部署环境下使用,不建议把与运行环境相关的设置直接在代码中写死。
3.Local本地模式内部实现原理
Local本地模式使用LocalBackend配合TaskSchedulerImpl,内部逻辑结构如下图所示:
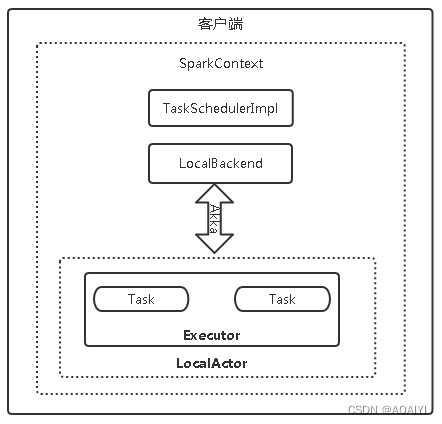
LocalBackend响应Scheduler的receiveOffers请求,根据可用的CPU核的设定值[N]直接生成CPU资源返回给Scheduler,并通过Executor类在线程池中依次启动和运行Scheduler返回的任务列表,其核心事件循环由内部类LocalActor以Akka Actor的消息处理形式来实现。
三、实验环境
Linux Ubuntu 16.04
jdk-7u75-linux-x64
四、实验内容
在已经安装有jdk1.7的Linux系统的环境下,进行Spark local模式安装。
五、实验步骤
1.Spark的运行依赖jdk以及scala环境。在此已默认安装jdk1.7。
2.首先在linux上创建目录/data/spark1,用于存储所需文件。
mkdir -p /data/spark1
切换目录到/data/spark1目录,上传安装包。(由于小AO有点懒上传安装包到本文,需要的可以私聊小AO)
此处建议使用scala-2.10.4版本。官网中指出,若使用scala2.11.x版本,需要重新编译Spark,并且编译时,需要指定Scala版本的类型。
关于Spark版本,没有严格要求。所以我们使用Spark1.6版本。
3.安装scala。切换目录到/data/spark1目录下,将scala-2.10.4.tgz解压缩到/apps目录下。
cd /data/spark1/
tar -xzvf /data/spark1/scala-2.10.4.tgz -C /apps/
切换目录到/apps目录下,将解压后的目录名改为/apps/scala。
cd /apps
mv /apps/scala-2.10.4/ /apps/scala
使用vim打开用户环境变量~/.bashrc。
vim ~/.bashrc
将scala的bin目录,追加到用户环境变量中,然后保存退出。
#scala
export SCALA_HOME=/apps/scala
export PATH=$SCALA_HOME/bin:$PATH
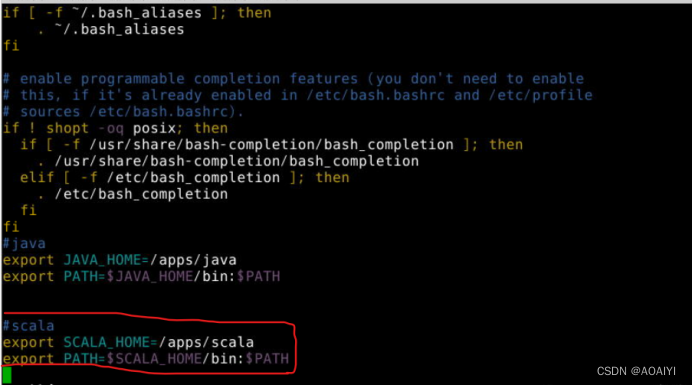
执行source命令,使系统环境变量生效。
source ~/.bashrc
4,切换目录到/data/spark1目录下,将spark的安装包spark-1.6.0-bin-hadoop2.6.tgz,解压缩到/apps目录下。
cd /data/spark1
tar -xzvf /data/spark1/spark-1.6.0-bin-hadoop2.6.tgz -C /apps/
切换目录到/apps/目录下,并将解压后的目录名重命名为spark。
cd /apps/
mv /apps/spark-1.6.0-bin-hadoop2.6/ /apps/spark
使用vim打开用户环境变量~/.bashrc。
vim ~/.bashrc
将Spark的配置信息追加到用户环境变量中,然后保存退出。
#spark
export SPARK_HOME=/apps/spark
export PATH=$SPARK_HOME/bin:$PATH
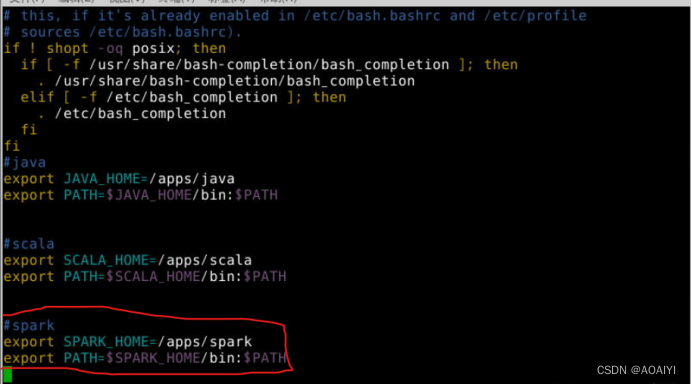
执行source命令,使用户环境变量生效。
source ~/.bashrc
5,下面不需要对spark进行任何配置,就可以启动spark-shell进行任务处理了。
切换目录到/apps/spark/bin目录下,启动spark shell,验证安装完的spark是否可用。
执行
cd /apps/spark/bin/
spark-shell
或者执行
spark-shell local
可以启动本地模式。
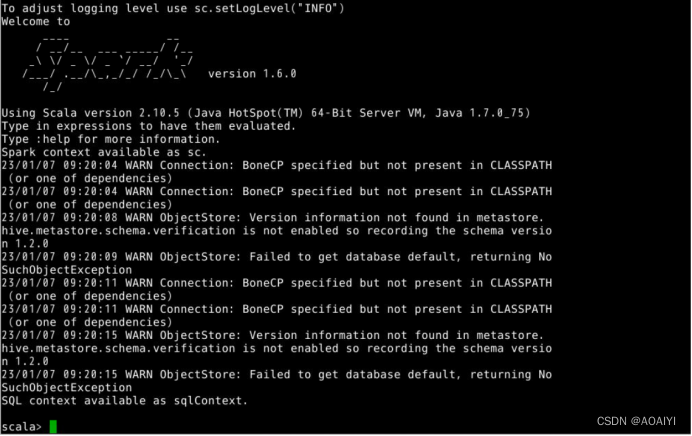
6,执行测试。在Spark Shell中,使用Scala加载Spark安装目录下,文件README.md,并转变为rdd。
val rdd = sc.textFile("/apps/spark/README.md")
对rdd进行算子操作,统计文件的行数。
rdd.count()
可以看到输出为:

表明安装正确。
完整效果为:




















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











