




 探讨半监督学习在有限标注数据下的高效应用,介绍其在生成模型、SVM及平滑假设等方面的优势,以及如何利用未标注数据提升模型性能。
探讨半监督学习在有限标注数据下的高效应用,介绍其在生成模型、SVM及平滑假设等方面的优势,以及如何利用未标注数据提升模型性能。
半监督学习
Introduction

对于猫狗分类问题,如果只有一部分data有label,还有其他很大一部分data是unlabeled,那么我们可以认为unlabeled data对我们网络的训练是无用的吗?

Q:Why semi-supervised learning helps ?
(为什么semi-supervised learning会有效?)

A:如图所示,图中灰色圆点表示unlabeled data,其他圆点表示labeled data。如果没有unlabeled data,此时可以用一条竖直的线将猫狗进行分类,boundary为竖直的那条线;但unlabeled data的分布也可以告诉我们一些信息,对我们的训练也是有帮助的,有了unlabeled data,此时的boundary为斜直线
Semi-supervised Learning for Generative Model
Supervised Generative Model
不考虑unlabeled data,只有labeled data

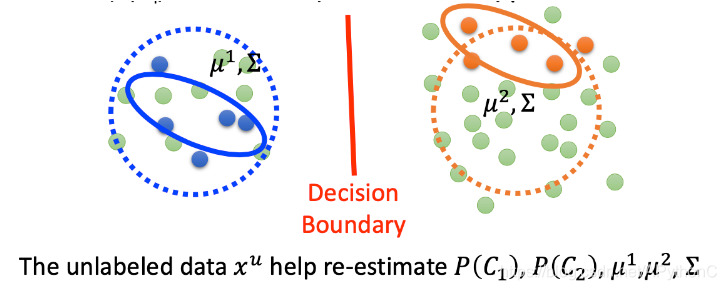
Semi-supervised Generative Model
如果把unlabeled data也考虑进来,此时的boundary 也发生了变化
Formulation

不同的maximum likelihood对比

Low-density Separation Assumption
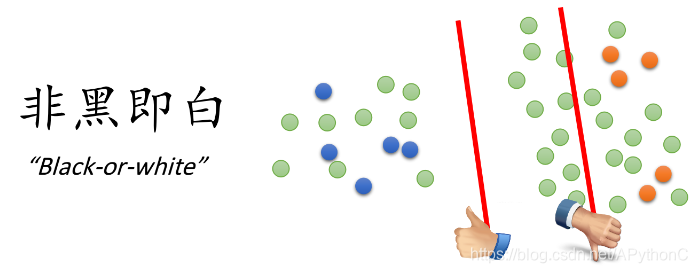
假设这个世界是非黑即白的,在两个class的交界处data的密度(density)是很低的,它们之间会有一道明显的鸿沟,此时unlabeled data(下图绿色的点)就是帮助你在原本正确的基础上挑一条更好的boundary
Self Training
有labeled data和unlabeled data,重复以下过程:
- 从labeled data中tarin了模型 f ∗ f^* f∗
- 将 f ∗ f^* f∗应用到unlabeled data,得到带label的数据,称为Pseudo-label
- 从unlabeled data中移出这部分data,并加入labeled data;要移除哪部分data,要根据具体的限制条件而定
- 有了更多的label data,就可以继续训练我们的模型,返回第一步

注:该方法对Regression是不适用的
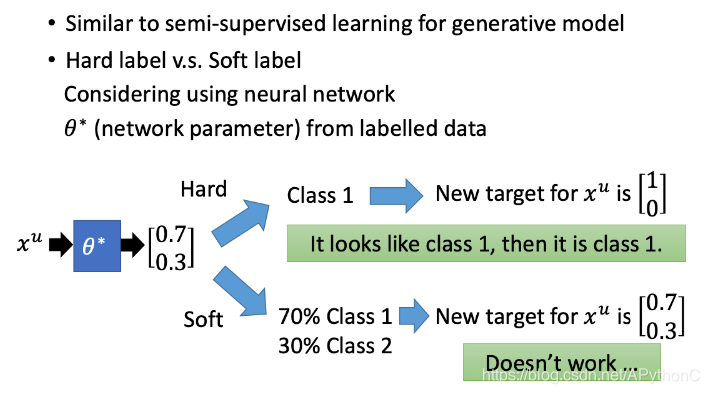
Hard label v.s. Soft label
self-training用的是hard label;generative model用的是soft label
Entropy-based Regularization
如果输出的每个类别的概率是相近的,那么这个模型就比较bad;输出的类别差距很大,比如某个类别的概率为1,其他都是0

现在就可以重新设计loss function,用cross entropy来估计差距
Semi-supervised SVM
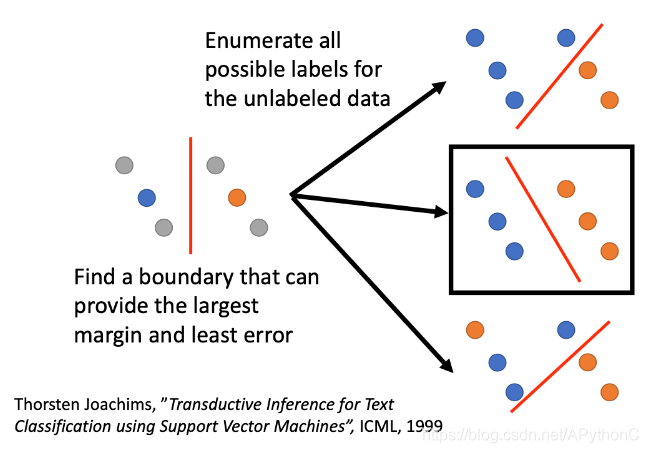
SVM要做的是,给你两个class的data,去找一个boundary:
- 要有最大的margin,让这两个class分的越开越好
- 要有最小的分类错误
对unlabeled data穷举所有可能的label,下图中列举了三种可能的情况;然后对每一种可能的结果都去算SVM,再找出可以让margin最大,同时又minimize error的那种情况,下图中是用黑色方框标注的情况
Smoothness Assumption
Introduction
smoothness assumption的基本精神是:近朱者赤,近墨者黑
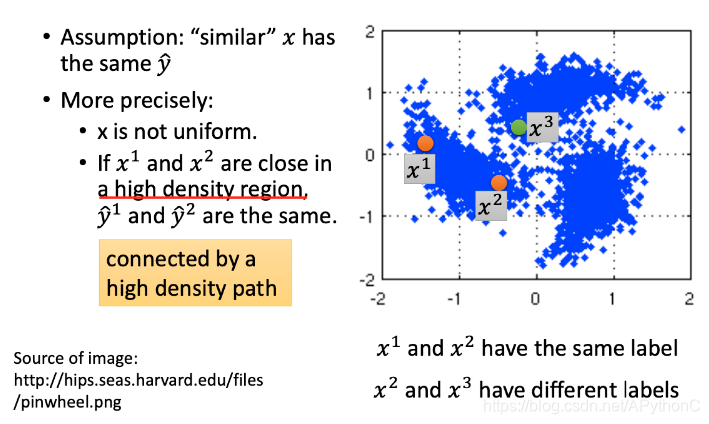
假设:如果x是similar的,那么他们的y也是一样的
这样的假设是非常不精确的,下面我们做出一个更加精确的假设:
- x是分布不均匀的,有的地方很密集,有的地方很稀疏
-
x
1
x^1
x1,
x
2
x^2
x2中间有个high density region,那么label
y
1
y^1
y1,
y
2
y^2
y2就很可能是一样的;但
x
2
x^2
x2,
x
3
x^3
x3中间没有high density region,其label相同的概率就非常小
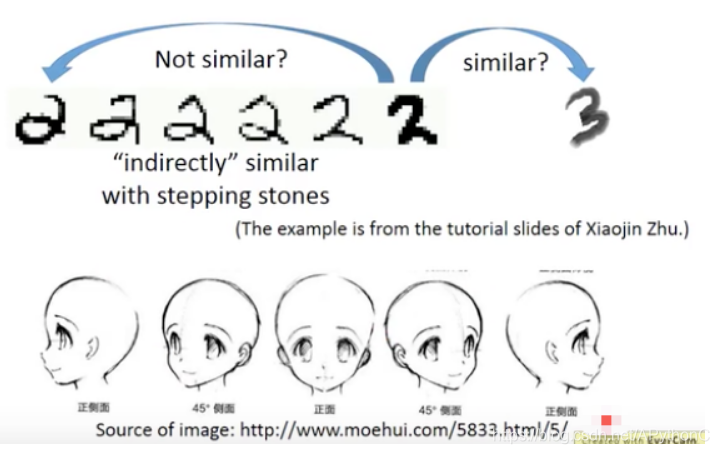
对于下图中的数字,2之间是有过渡形态的,所以这两个图片是similar的;而2与3之间没有过渡形态,因此是不similar的
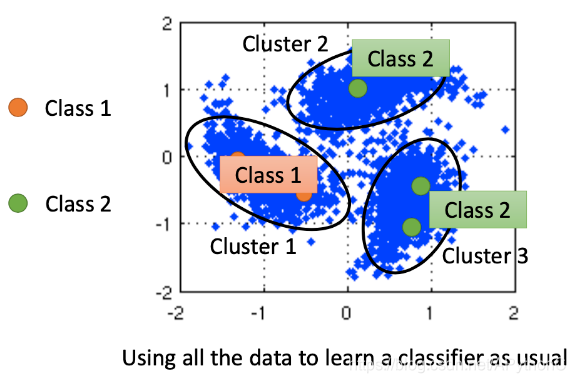
比较直观的做法是先进行cluster,再进行label
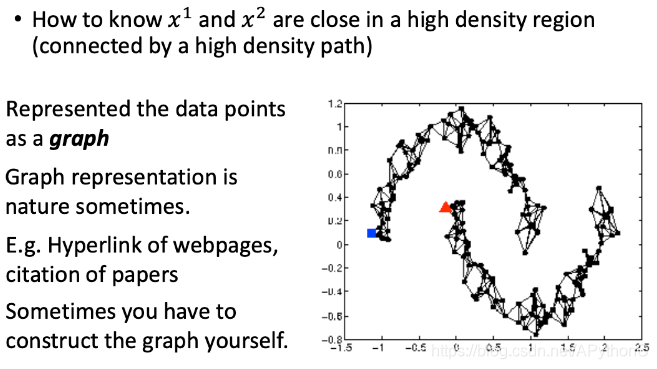
Graph-based Approach
我们可以把data point用图来表示,图的表示有时是比较nature,有时需要我们自己找出来point之间的联系
Graph Construction
通过以下两个算法来添加edge:
- KNN,对于图中红色的圆点,与其最相近的三个(k=3)neighbor相连接
- e-Neighborhood,对于周围的neighbor,只有和他相似度大于1的才会被连接起来
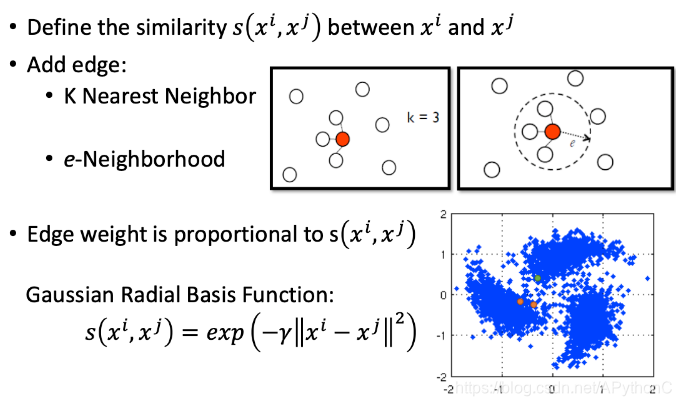
edge并不是只有相连和不相连两种选择而已,也可以给edge一些weight,让这个weight和这两个point之间的相似度成正比
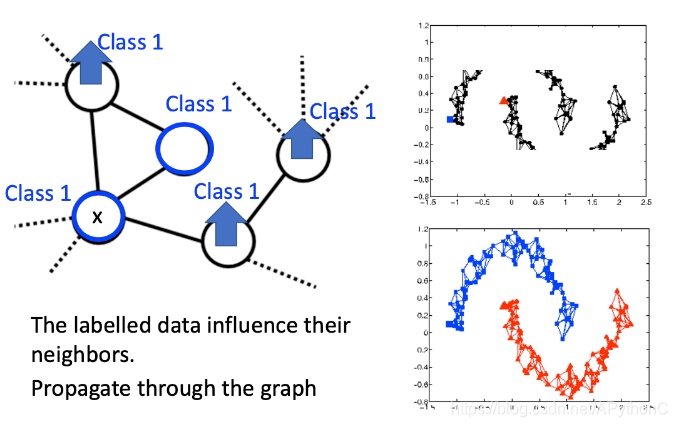
labeled data会影响他的邻居,如果这个point是class1,那么他周围的某些point也可能是class1
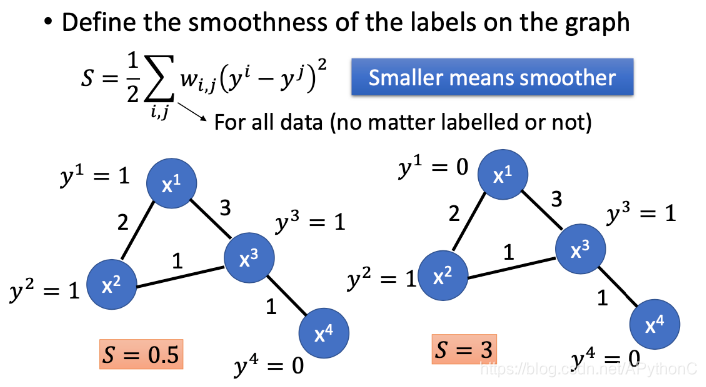
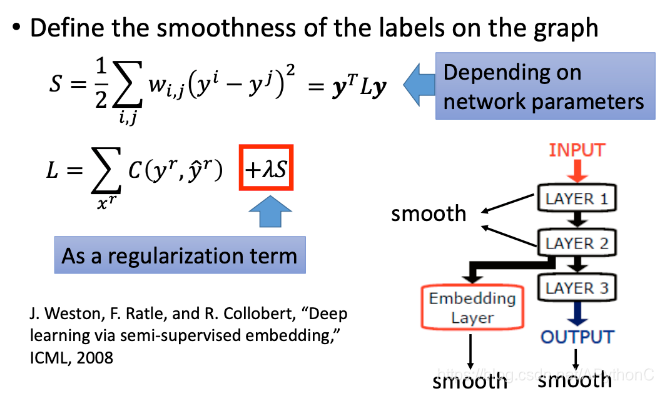
我们期望smooth的值越小越好
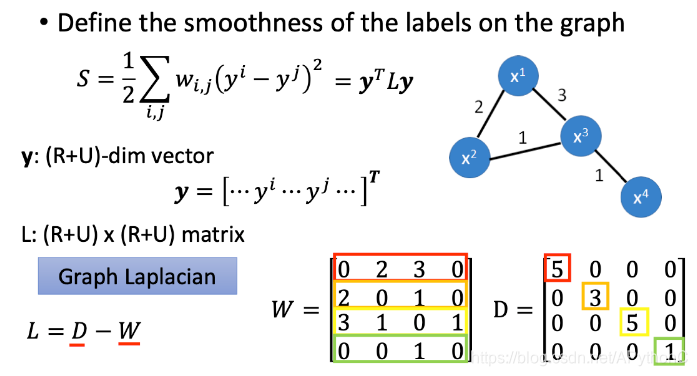
Better Representation
Better Representation的精神是化繁为简
本文图片来自李宏毅老师课程PPT,文字是对李宏毅老师上课内容的笔记或者原话复述,在此感谢李宏毅老师的教导。

















 2078
2078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









