







1. 快速开始一个Go程序
以一个示例程序为开始:程序下载地址:http://labfile.oss.aliyuncs.com/courses/834/sample.zip
程序架构
这个程序分成多个不同步骤,在多个不同的goroutine里运行。
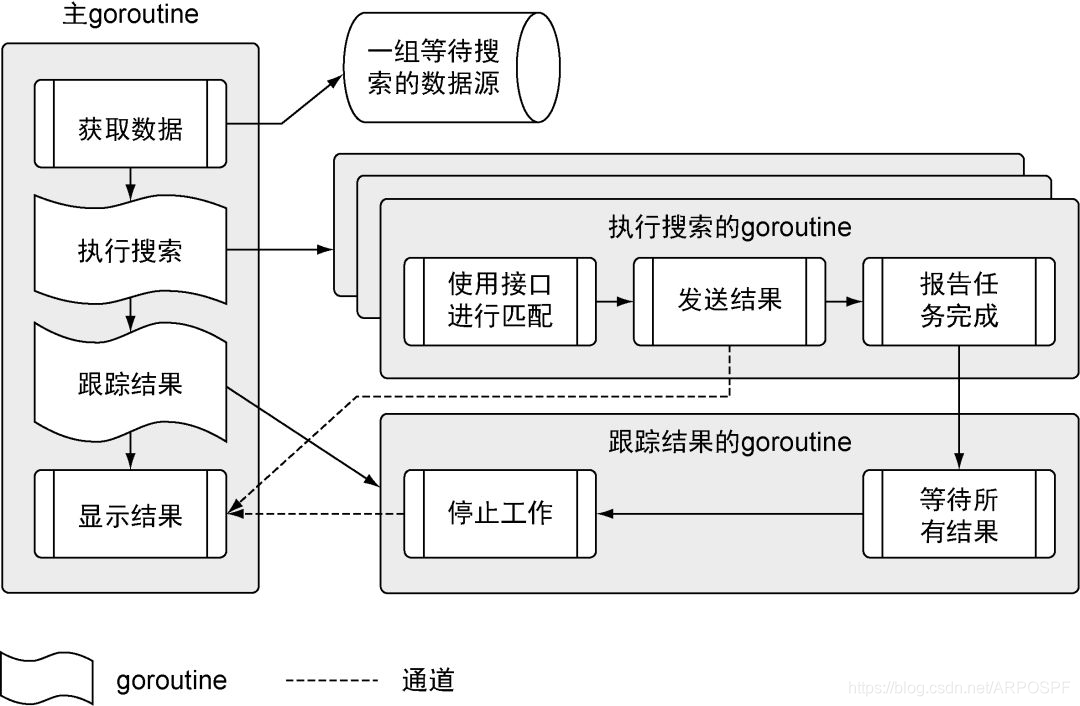
按照流程展示代码,从主goroutine开始,一直到执行搜索的goroutine和跟踪结果的goroutine,最后回到主goroutine。
程序的项目结构如下:
- sample
- data
data.json -- 包含一组数据源
- matchers
rss.go -- 搜索rss源的匹配器
- search
default.go -- 搜索数据用的默认匹配器
feed.go -- 用于读取json数据文件
match.go -- 用于支持不同匹配器的接口
search.go -- 执行搜索的主控制逻辑
main.go -- 程序的入口
这个应用的代码使用了4个文件夹,按字母顺序列出。文件夹data中有一个JSON文档,其内容是程序要拉取和处理的数据源。文件夹matches中包含程序里用于支持搜索不同数据源的代码。文件夹search中包含使用不同匹配器进行搜索的业务逻辑。最后,父级文件夹sample中有个main.go文件。这是整个程序的入口。
main包
package main
import (
"log"
"os"
- "matchers"
"search"
)
// init 在main之前调用
func init(){
// 将日志输出到标准输出
log.SetOutput(os.Stdout)
}
// main是整个程序的入口
func main(){
// 使用特定的项做搜索
search.Run("president")
}
==Go语言的每个代码文件都属于一个包。==一个包定义一组编译过的代码,包的名字类似命名空间,可以用来间接访问包内声明的标识符。所有处于同一个文件夹里的代码文件,必须使用同一个包名。
注意:导入的路径前面有一个下划线。这个技术是为了让Go语言对包做初始化操作,但是并不使用包里的标识符。Go编译器不允许声明导入某个包却不适用。下划线让编译器接受这类导入,并且调用对应包内的所有代码文件里定义的init函数。
==程序中每个代码文件里的init函数都会在main函数执行前调用。一旦编译器发现init函数,它就会给这个函数优先执行的权限,保证其在main函数之前被调用。==上述init函数将标准库里日志类的输出,从默认的标准错误(stderr),设置为标准输出(stdout)设备。
search包
search.go
package search
import (
"log"
"sync"
)
// 注册用于搜索的匹配器的映射
var matchers = make(map[string]Matcher) // 声明变量,而且声明为Matcher类型的映射(map),并且使用赋值运算符和特殊的内置函数make初始化了变量
sync包提供同步goroutine的功能。
在Go语言里,标识符要么从包里公开,要么不从包里公开。当代码导入一个包时,程序可以直接访问这个包中任意一个公开的标识符。这些标识符以大写字母开头。以小写字母开头的标识符是不公开的,不能被其他包中的代码直接访问。但是,其他包可以间接访问不公开的标识符。
注意:
make(map[String]Matcher)
map是Go语言里的一个引用类型,需要使用make来构造。如果不先构造map并将构造后的值赋值给变量,会在试图使用这个map变量时受到出错信息。这是因为map变量默认的零值是nil。
在Go语言中,所有变量都被初始化为其零值。对于数值类型,零值是0;对于字符串类型,零值是空字符串;对于布尔类型,零值是false;对于指针,零值是nil。对于引用类型,所引用的底层数据结构会被初始化为对应的零值,但是被声明为其零值的引用类型的变量,会返回nil作为其值。
package search
import (
"log"
"sync"
)
// 注册用于搜索的匹配器的映射
var matchers = make(map[string]Matcher)
// Run执行搜索逻辑
func Run(searchTerm string) {
// 获取需要搜索的数据源列表
feeds, err := RetrieveFeeds() // 返回切片
if err != nil {
log.Fatal(err)
}
// 创建一个无缓冲的通道,接收匹配后的结果
results := make(chan *Result)
// 构造一个waitGroup,以便处理所有的数据源
var waitGroup = sync.WaitGroup
// 设置需要等待处理
// 每个数据源的goroutine的数量
waitGroup.Add(len(feeds))
// 为每个数据源启动一个goroutine来查找结果
for _, feed := range feeds {
// 获取一个匹配其用于查找
matcher, exists := matchers[feed.Type]
if !exists {
matcher = matchers["default"]
}
// 启动一个goroutine来执行搜索
go func(matcher Matcher, feed *Feed) {
Match(matcher, feed, searchTerm, results)
waitGroup.Done()
}(matcher, feed)
}
// 启动一个goroutine来监控是否所有的工作都做完了
go func() {
// 等候所有任务完成
waitGroup.Wait()
// 用关闭通道的方式,通知Display函数
// 可以退出程序了
close(results)
}()
// 启动函数,显示返回的结果,并且在最后一个结果显示完后返回
Display(results)
}
Go语言使用关键字func函数,关键字后面紧跟着函数名,参数以及返回值。
feeds, err := RetrieveFeeds() 返回两个值,第一个返回值是一组Feed类型的切片。切片是一种实现了一个动态数组的引用类型。在Go语言里可以用切片来操作一组数据。
简化变量声明运算符(:=),这个运算符用于声明一个变量,同时给这个变量赋予初始值。==编译器使用函数返回值的类型来确定每个变量的类型。==这个运算符声明的变量和其他使用关键字var声明的变量没有任何区别。
results := make(chan *Result)使用make函数创建了一个无缓冲的通道。在调用make的同时声明并初始化该通道变量。根据经验,如果需要声明初始值为零值的变量,应该使用var关键字声明变量;如果提供确切的非零值初始化变量或者使用函数返回值创建变量,应该使用简化变量声明运算符。
在Go语言中,通道(channel)和映射(map)与切片(slice)一样,也是引用类型。通道本身实现的是一组带类型的值,这组值用于在goroutine之间传递数据。通道内置同步机制,从而保证通信安全。
// 构造一个waitGroup,以便处理所有的数据源
var waitGroup = sync.WaitGroup
// 设置需要等待处理每个数据源的goroutine的数量
waitGroup.Add(len(feeds))
Go程序终止时,还会关闭所有之前启动且还在运行的goroutine。写并发程序的时候,最佳做法是,在main函数返回前,清理并终止所有之前启动的goroutine。上述程序使用sync包的WaitGroup跟踪所有启动的goroutine。推荐使用WaitGroup来跟踪goroutine的工作是否完成。WaitGroup是一个计数信号量,可以利用它统计所有的goroutine是不是都完成了。初始时将WaitGroup变量的值设置为将要启动的goroutine的数量。每个goroutine完成其工作后,就会递减WaitGroup变量的计数值,当这个值递减到0时,所有的工作就都做完了。
使用for range对feeds切片做迭代。==关键字range可以用于迭代数组、字符串、切片、映射和通道。==使用for range迭代切片时,每次迭代会返回两个值。第一个值是迭代的元素在切片里的索引位置,第二个值是元素值的一个副本。
for _, feed := range feeds {这里的下划线标识符的作用是占位符,占据了保存range调用返回的索引值的变量的位置。如果要调用的函数返回多个值,而又不需要其中的某个值,就可以使用下划线标识符将其忽略。
查找map里的键时,有两个选择,要么赋值给一个变量,要么为了精确查找,赋值给两个变量。赋值给两个变量时第一个值和赋值给一个变量时的值一样,是map查找的结果值。如果指定了第二个值,就会返回一个布尔标志,来表示查找的键是否存在于map里。如果这个键不存在,map会返回其值类型的零值作为返回值,如果这个键存在,map会返回键所对应值的副本。
// 启动一个goroutine来执行搜索
go func(matcher Matcher, feed *Feed) { // 启动了一个匿名函数作为goroutine,接受两个参数,一个类型为Matcher,另一个是指向Feed类型值的指针
Match(matcher, feed, searchTerm, results)
waitGroup.Done()
}(matcher, feed)
一个goroutine是一个独立于其他函数运行的函数。使用关键字go启动一个goroutine,并对这个goroutine做并发调度。匿名函数是指没有明确声明名字的函数。匿名函数也可以接受声明时指定的参数。指针变量可以方便地在函数之间共享数据。使用指针变量可以让函数访问并修改一个变量的状态,而这个变量可以在其他函数甚至是其他goroutine的作用域里声明。
在Go语言中,所有的变量都是以值的方式传递。因为指针变量的值是所指向的内存地址,在函数间传递指针变量,是在传递这个地址值,所以依旧被看作以值的方式在传递。
注意:WaitGroup的值没有作为参数传入匿名函数,但是匿名函数依旧访问到了这个值。Go语言支持闭包,这里就应用了闭包。==因为有了闭包,函数可以直接访问到那些没有作为参数传入的变量。匿名函数并没有拿到这些变量的副本,而是直接访问外层函数作用域中声明的这些变量本身。==所有的goroutine都会因为闭包共享同样的变量,除非以函数参数的形式传值给函数。
feed.go
package search
import(
"encoding/json"
"os"
)
const dataFile = "data/data.json"
注意:json包提供了编解码JSON的功能,OS包提供了访问操作系统的功能。导入json包的时候需要指定encoding路径。声明一个叫做dataFile的变量,使用内容是磁盘上根据相对路径指定的数据文件名的字符串做初始化。因为Go编译器可以根据赋值运算符右边的值来推到类型,声明常量的时候不需要根据指定类型。此外,常量的名称使用小写字母开头,表示它只能在search包内的代码里直接访问,而不是暴露到包外面。
// Feed包含需要处的数据源的信息
type Feed struct{
Name string `json:"site"`
URI string `json:"link"`
Type string `json:"type"`
}
上面的代码声明了一个叫做Feed的结构类型。每个字段的声明最后`引号里的部分被称作标记(tag)。这个标记里描述了JSON解码的元数据,用于创建Feed类型值的切片。每个标记将结构类型里字段对应到JSON文档里指定名字的字段。
// RetrieveFeeds读取并反序列化数据文件
func RetrieveFeeds() ([]*Feed, error) {
// 打开文件
file, err := os.Open(dataFile)
if err != nil {
return nil, err
}
// 当函数返回时,关闭文件
defer file.Close()
// 将文件解码到一个切片里, 这个切片的每一项是一个指向一个Feed类型值的指针
var feeds []*Feed
err = json.NewDecoder(file).Decode(&feeds)
// 这个函数不需要检查错误,调用者会做这件事
return feeds, err
}
函数有两个返回值,第一个返回值是一个切片,其中每一项指向一个Feed类型的值。第二个返回值是一个error类型的值,用来表示函数是否调用成功。
使用os包打开了数据文件。以相对路径调用Open方法,并得到两个返回值。第一个返回值是一个指针,指向File类型的值,第二个返回值是error类型的值,检查Open调用是否成功。
==关键字defer会安排随后的函数调用在函数返回时才执行。==使用完文件后,需要主动关闭文件。使用关键字defer来安排调用Close方法,可以保证这个函数一定被调用。哪怕函数意外崩溃终止,也能保证关键字defer安排调用的函数被执行。关键字defer可以缩短打开文件和关闭文件之间间隔的代码行数。
根据Decode方法的声明,该方法可以接受任何类型的值。
func (dec *Decoder) Decode(v interface{}) error
Decode方法接受一个类型为interface{}的值作为参数。这个类型在Go语言里很特殊,一般会配合reflect包里提供的反射功能一起使用。
match.go/default.go
// 为每个数据源启动一个goroutine来查找结果
for _, feed := range feeds {
// 获取一个匹配其用于查找
matcher, exists := matchers[feed.Type]
if !exists {
matcher = matchers["default"]
}
// 启动一个goroutine来执行搜索
go func(matcher Matcher, feed *Feed) {
Match(matcher, feed, searchTerm, results)
waitGroup.Done()
}(matcher, feed)
这段代码起作用的关键是这个架构使用一个接口类型来匹配并执行具有特定实现的匹配器。
package search
import(
"log"
)
// Result保存搜索的结果
type Result struct{
Field string
Content string
}
// Matcher定义了要实现的新搜索类型的行为
type Matcher interface{
Search(feed *Feed, searchTerm string)([]*Result, error)
}
interface关键字声明了一个接口,这个接口声明了结构类型或者具名类型需要实现的行为。一个接口的行为最终由在这个接口类型中声明的方法决定。
命令接口的时候,也需要遵守Go语言的命名惯例。==如果接口类型中只包含一个方法,那么这个类型的名字以er结尾。==如果接口类型内部声明了多个方法,其名字需要与其行为关联。
如果要让一个用户定义的类型实现一个接口,这个用户定义的类型要实现接口类型里声明的所有方法。
package search
// defaultMatcher实现了默认匹配器
type defaultMatcher struct{}
// init函数将默认匹配器注册到程序里
func init() {
var matcher defaultMatcher
Register("default", matcher)
}
// Search实现了默认匹配器的行为
func (m defaultMatcher) Search(feed *Feed, searchTerm string) ([]*Result, error) {
return nil, nil
}
==空结构在创建实例时,不会分配任何内存。==这种结构很适合创建没有任何状态的类型。
如下,Search方法的声明也声明了defaultMatcher类型的值的接收者:
func (m defaultMatcher) Search
==如果声明函数的时候带有接收者,则意味着声明了一个方法。这个方法会和指定的接收者的类型绑在一起。==这意味着可以使用defaultMatcher类型的值或者指向这个类型值的指针来调用Search方法。无论是使用接收者类型的值来调用这个方法,还是使用接收者类型值的指针来调用这个方法,编译器都会正确地引用或者解引用对应的值,作为接收者传递给Search方法。
调用方法的例子
// 方法声明为使用defaultMatcher类型的值作为接收者
func (m defaultMatcher) Search(feed *Feed, searchTerm string)
// 声明一个指向defaultMatcher类型值的指针
dm := new(defaultMatcher)
// 编译器会解开dm指针的引用,使用对应的值调用方法
dm.Search(feed, "test")
// 方法声明为使用指向defaultMatcher类型值的指针作为接收者
func (m *defaultMatcher) Search(feed *Feed, searchTerm string)
// 声明一个defaultMatcher类型的值
var dm defaultMatcher
// 编译器会自动生成指针引用dm值,使用指针调用方法
dm.Search(feed, "test")
因为==大部分方法在被调用后都需要维护接收者的值的状态,所以,一个最佳实现是,将方法的接收者声明为指针。==与直接通过值或者指针调用方法不同,如果通过接口类型的值调用方法,规则有很大不同。使用指针作为接收者声明的方法,只能在接口类型的值是一个指针的时候被调用。使用值作为接收者声明的方法,在接口类型的值为值或者指针时,都可以被调用。
接口方法调用所受限制的例子
// 方法声明为使用指向defaultMatcher类型值的指针作为接收者
func (m *defaultMatcher) Search(feed *Feed, searchTerm string)
// 通过interfacce类型的值来调用方法
var dm defaultMatcher
var matcher Matcher = dm //将值赋值给接口类型
matcher.Search(feed, "test") // 使用值来调用接口方法
> go build
> cannot use dm (type defaultMatcher) as type Matcher in assignment
// 方法声明为使用defaultMatcher类型的值作为接收者
func (m defaultMatcher) Search(feed *Feed, searchTerm string)
// 通过interface类型的值来调用方法
var dm defaultMatcher
var matcher Matcher = &dm // 将指针赋值给接口类型
matcher.Search(feed, "test") //使用指针来调用接口方法
> go build
Build Successful
从这段代码之后,不论时defaultMatcher类型的值还是指针,都满足Matcher接口,都可以作为Matcher类型的值使用。
// Match函数,为每个数据源单独启动goroutine来执行这个函数, 并发地执行搜索
func Match(matcher Matcher, feed *Feed, searchTerm string, results chan<- *Result) {
// 对特定的匹配器执行搜索
searchResults, err := matcher.Search(feed, searchTerm)
if err != nil {
log.Println(err)
return
}
// 将结果写入通道
for _, result := range searchResults {
results <- result
}
}
// Display从每个单独的goroutine接收到结果后在终端窗口中输出
func Display(results chan *Result) {
// 通道会一直被阻塞,直到有结果写入,一旦通道被关闭,for循环就会终止
for result := range results {
fmt.Println("%s:\n%s\n\n", result.Field, result.Content)
}
}
当通道被关闭时,通道和关键字range的行为,使这个函数在处理完所有结果后才会返回。
// Register调用时,会注册一个匹配器,提供给后面的程序使用
func Register(feedType string, matcher Matcher) {
if _, exists := matchers[feedType]; exists {
log.Fatalln(feedType, "Matcher already registered")
}
log.Println("Register", feedType, "matcher")
matchers[feedType] = matcher
}
这个函数的职责是将一个Matcher值加入到保存注册匹配器的映射中。所有这种注册都应该在main函数被调用前完成。使用init函数可以非常完美地完成这种初始化注册的任务。
RSS匹配器
RSS匹配器的结构与默认匹配器的结构类似。每个匹配器为了匹配接口,Search方法的实现都不同,因此匹配器之间无法互相替换。
RSS匹配器的实现会下载这些RSS文档,使用搜索项来搜索标题和描述域,并将结果发送给results通道。
package matchers
import (
"encoding/xml"
"errors"
"fmt"
"log"
"net/http"
"regexp"
"../search"
)
type (
// item 根据item字段的标签,将定义的字段与rss文档的字段关联起来
item struct {
XMLName xml.Name `xml:"item"`
PubDate string `xml:"pubDate"`
Title string `xml:"title"`
Description string `xml:"description"`
Link string `xml:"link"`
GUID string `xml:"guid"`
GeoRssPoint string `xml:"georss:point"`
}
// image 根据image字段的标签,将定义的字段与rss文档的字段关联起来
image struct {
XMLName xml.Name `xml:"image"`
URL string `xml:"url"`
Title string `xml:"title"`
Link string `xml:"link"`
}
// channel 根据channel字段的标签,将定义的字段与rss文档的字段关联起来
channel struct {
XMLName xml.Name `xml:"channel"`
Title string `xml:"title"`
Description string `xml:"description"`
Link string `xml:"link"`
PubDate string `xml:"pubDate"`
LastBuildDate string `xml:"lastBuildDate"`
TTL string `xml:"ttl"`
Language string `xml:"language"`
ManagingEditor string `xml:"managingEditor"`
WebMaster string `xml:"webMaster"`
Image image `xml:"image"`
Item []item `xml:"item"`
}
// rssDocument定义了与rss文档关联的字段
rssDocument struct {
XMLName xml.Name `xml:"rss"`
Channel channel `xml:"channel"`
}
)
这里的结构与任意一个数据源的RSS文档结构对应。下面代码是rssMatcher类型的声明,因为不需要维护任何状态,因此使用了一个空结构来实现Matcher接口。
// rssMatcher实现了Matcher接口
type rssMatcher struct{}
匹配器init函数的实现:
// init 将匹配器注册到程序里
func init() {
var matcher rssMatcher
search.Register("rss", matcher)
}
init函数将rssMatcher类型的值注册到程序里,以备后用。在看一次main.go代码中的导入部分:
- "matchers"
"search"
使用下划线标识符作为别名导入matchers包,完成了这个调用。这种方法可以让编译器在导入未被引用的包时不报错,而且依旧会定位到包内的init函数。
实现Matcher接口的两个方法:
// retrieve发送HTTP Get请求获取rss数据源并解码
func (m rssMatcher) retrieve(feed *search.Feed) (*rssDocument, error) {
if feed.URI == "" {
return nil, errors.New("No rss feed uri provided")
}
// 从网络获得rss数据源文档
resp, err := http.Get(feed.URI)
if err != nil {
return nil, err
}
// 一旦从函数返回,关闭返回的响应链接
defer resp.Body.Close()
// 检查状态码是不是200,这样就能知道是不是收到了正确的响应
if resp.StatusCode != 200 {
return nil, fmt.Errorf("HTTP Response Error %d\n", resp.StatusCode)
}
// 将rss数据源文档解码到我们定义的结构类型里,不需要检查错误,调用者会做这件事
var document rssDocument
err = xml.NewDecoder(resp.Body).Decode(&document)
return &document, err
}
使用http包,Go语言可以很容易地进行网络请求。当Get方法返回后,可以得到一个指向Response类型值的指针。这里使用xml包并调用了同样叫NewDecoder的函数,这个函数会返回一个指向Decoder值的指针。之后调用这个指针的Decode方法,传入rssDocument类型的局部变量document的地址,最后返回这个局部变量的地址和Decode方法调用返回的错误值。
// Search在文档中查找特定的搜索项
func (m rssMatcher) Search(feed *search.Feed, searchTerm string) ([]*search.Result, error) {
var results []*search.Result // 使用关键字var声明一个值为nil的切片
log.Printf("Search Feed Type[%s] Site[%s] For Uri[%s]\n", feed.Type, feed.Name, feed.URI)
// 获取要搜索的数据
document, err := m.retrieve(feed) //调用retrieve方法返回了一个指向rssDocument类型值的指针以及一个错误值
if err != nil {
return nil, err
}
for _, channelItem := range document.Channel.Item {
// 检查标题部分是否包含搜索项
matched, err := regexp.MatchString(searchTerm, channelItem.Title) // 使用regexp包里的MatchString函数对channelItem值里的Title字段进行搜索,查找是否有匹配的搜索项。
if err != nil {
return nil, err
}
// 如果找到匹配的项,将其作为结果保存
if matched { //如果为真,则使用内置的append函数,将搜索结果加入到results切片里。
results = append(results, &search.Result{
Field: "Title",
Content: channelItem.Title,
})
}
// 检查描述部分是否包含搜索项
matched, err = regexp.MatchString(searchTerm, channelItem.Description)
if err != nil {
return nil, err
}
// 如果找到匹配的项,将其作为结果保存
if matched {
results = append(results, &search.Result{
Field: "Description",
Content: channelItem.Description,
})
}
}
return results, nil
}
这里使用关键字var声明了一个值为nil的切片,切片每一项都是指向Result类型值的指针。如果调用MatchString方法返回的matched的值为真,则使用内置的append函数,将搜索结果加入到results切片里。append这个内置函数会根据切片需要,决定是否要增加切片的程度和容量。这个函数的第一个参数是希望追加到的切片,第二个参数是要追加的值。在本例中,追加到切片的第一个值是一个指向Result类型值的指针。这个值直接使用字面声明的方式,初始化为Result类型的值。之后使用取地址运算符(&)获得这个新值的地址。最终将这个指针存入了切片。
总结
- 每个代码文件都属于一个包,而包名应该与代码文件所在的文件夹同名;
- Go语言提供了多种声明和初始化的方式。如果变量的值没有显示初始化,编译器会将变量初始化为零值;
- 使用指针可以在函数间或者goroutine间共享数据;
- 通过启动goroutine和使用通道完成并发和同步;
- Go语言提供了内置函数来支持Go语言内部的数据结构;
- 标准库包含很多包,能做很多有用的事情;
- 使用Go接口可以编写通用的代码和框架。
参考资料:《Go语言实战》



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











