







文章目录
一、技术选型的道与术
1、什么是技术选型
根据实际业务管理的需要,对硬件、软件以及所要用到的技术进行规格的选择。
狭义上的技术选型:团队决定选用哪种技术去解决业务问题。(某种语言、某种框架去开发项目)
广义上的技术选型:泛指项目实施过程中的各种技术决策。(制定技术AB方案选其中一套,每个技术决策都是技术选型)
在决定采纳某个技术之前,一定要做好调研,并尝试小规模引入,积累经验,经过验证后再大规模采用。
2、技术选型的误区
(1)不尊重需求
任何技术决策都是为业务去服务的,满足需求是一切的前提,如果需求都不能很好的满足,而是采用了更好用的技术。做了再厉害的技术方案,也是白搭的。
这个道理非常的简单,但实际上呢,有很多的架构师在做技术选型的时候,却过于站在技术人员的立场,导致业务需求都不能很好的满足。
(2)盲目追求流行技术
再流行、再主流的技术,也无法满足所有团队的需求,适合自己的才是最好的。
比如说小项目强行使用微服务。
(3)面向简历选型
有些架构师做决策的时候,不去结合当前团队和业务的情况,而是什么技术牛叉用什么。
主要是将该公司当成了跳板,为了丰富自己的简历经验。
这种现象并不少见,可谓是损人利己。
(4)过度考虑
不可否认,我们都希望自己的系统都是高可用可扩展,可以完成任意的后续功能的组合,但是呢,这种考虑也要有个度。
过度考虑通用性、灵活性、扩展性,往往会导致工作量以及复杂度的猛增。
架构是逐步演进的,不是一蹴而就的。
(5)把看到的当事实
现在网上有很多技术文章,里面携带着各种观点,往往只会呈现出技术的其中一面,而不是全面的分析一个技术。还是要全面了解,才不会走进一个大坑。
比如说响应式编程有多好、性能多高,只口不提它本身的学习曲线是多么的陡峭。
3、技术选型的步骤
(1)总览
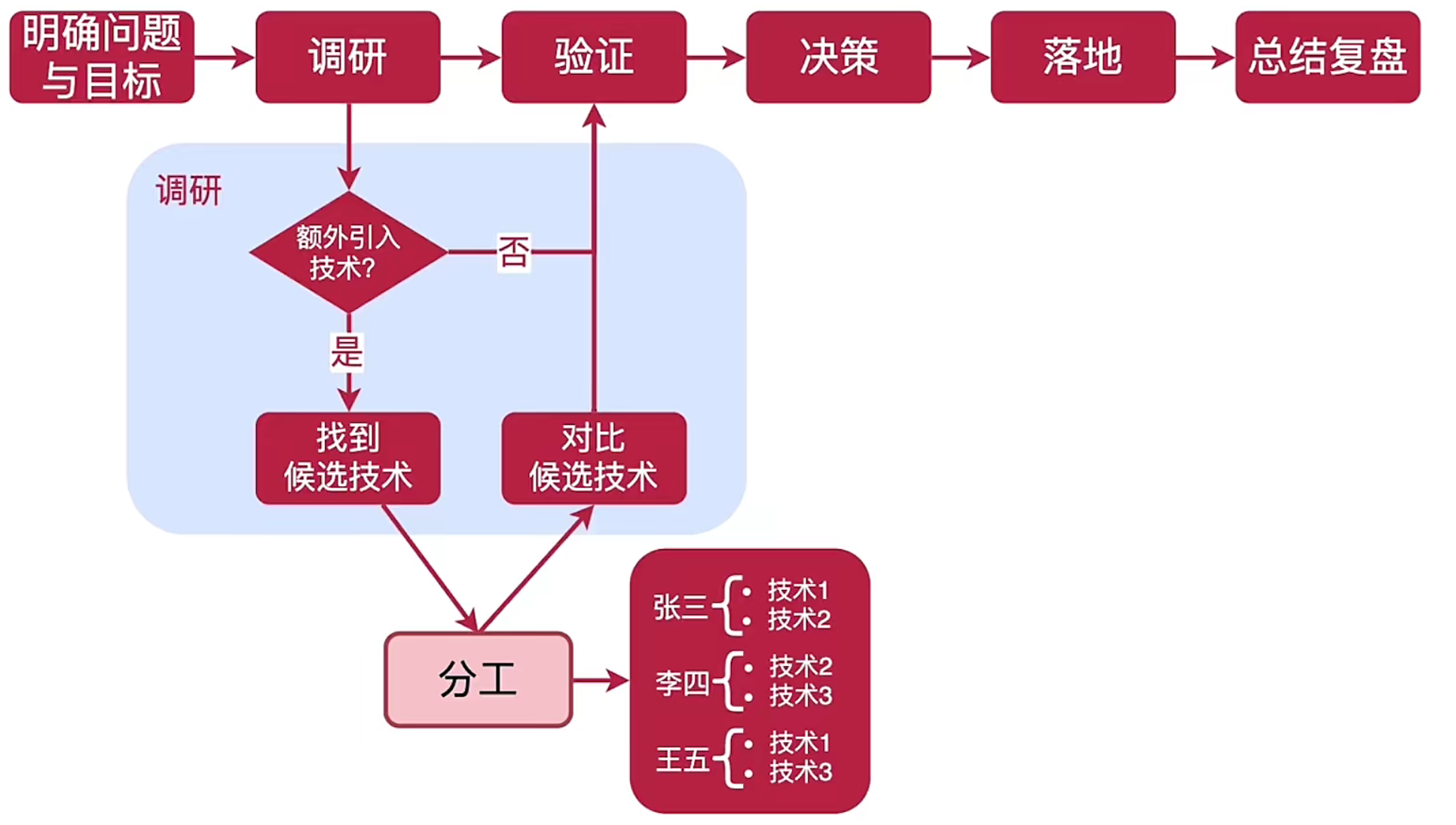
(2)明确问题与目标
首先搞清楚,当前遇到的问题是什么?(性能不佳?原来的技术无法满足需求?)
技术选型的目标是什么?(提升开发效率?提升性能?降低成本?解决业务问题?)
多个目标排列优先级。
(3)调研
首先识别:是否需要采用额外的技术?(为了解决问题而引入额外的技术,引入额外的技术也是一种技术选型)
有时候,技术选型是一个伪需求,引入任何技术都是有成本的,比如说学习成本、运维成本、团队适应成本、项目复杂度等等。
一般来说,如果能在现有技术的基础上想办法实现目标,就不要贸然去引入新的技术。
奥卡姆剃刀原理:如无必要,勿增实体。
多个技术选择,比对技术有哪些风险,是不是可控的。
实施的成本高不高。(时间成本、开发成本、硬件成本、采购成本)
比对技术各自的优缺点。
(4)找到候选技术
可以通过团队内部交流。一般来说,每个团队总有几个对技术有追求,并且有主见的小伙伴,不妨参考一下他们的意见。
网上搜索。
日常积累。见附一。
(5)验证
选择1-3中能够满足需求的技术小规模验证。一个技术合不合适,只有用了之后才会知道。
(6)决策
召集所有相关人员,组织一个评审会议,大家提出意见和建议,做出最终决策。
技术决策是有不确定性的,即使最终决策也是有翻车的可能。
(7)落地
在落地时,初期可以小规模试水,积累一定经验后,再逐步推广,降低落地失败的风险。
(8)总结与复盘
总结一下技术选型的简单过程;解决了那些问题;是否达到了预期;哪些地方是值得改进的。
如果落地失败,总结失败的原因是什么;总结如何防止再犯;完善技术选型的机制。
4、技术的比对
(1)因素加权法
结合项目里面关注的因素,为每个因素设置一个权重,并进行加权处理。
因素加权法一般只能用在选择具体的技术上,对于宏观层面的技术选型,比方说选择使用哪个技术方案或者更加高层的决策因素,因素加权法一般是无能为力的。
技术相关的因素:
1、官方活跃度 - 决定了如果在使用的过程中遇到bug能否得到官方支持。(软件发布周期、提交记录、README、Issue解决速度)
2、社区活跃度 - 决定了今后在使用中遇到问题,是否能够很快地得到帮助。(搜索引擎词条数、百度指数、谷歌趋势、GitHub Star数、第三方社区活跃度)
3、可维护性 - 如果维护性不好,千万不要使用!(比如低代码开发平台,需求复杂、变更频繁时慎用)
4、学习曲线 - 结合当前团队的技术特点以及熟练程度来考虑。(开发难度、学习难度)
5、性能 - 响应时间、TPS、存储容量、带宽等。(用性能测试工具评估)
6、安全性 - 检查它有多少的安全补丁以及严重程度,尤其是短期的安全补丁。可以借助一些漏洞扫描工具进行扫描。
7、优先选用熟悉的技术 - 而非高端的技术,接地气,了解熟悉。
技术以外的因素:
1、大规模采纳并成功的案例。侧面论证技术的成熟性、实践证明了能用在生产。
2、是否能够快速招募到人才。
3、考虑并平衡各方面利益。如果做技术选型的过程中,某个利益相关的发言人没有参加过,就可能会导致不考虑他们的决策。
4、法律问题。商用解决方案(花钱) or 开源解决方案(License问题,详见附二)
5、识别炒作。不要尽信别人的结果、文章,勤动手,以亲测结果为准。
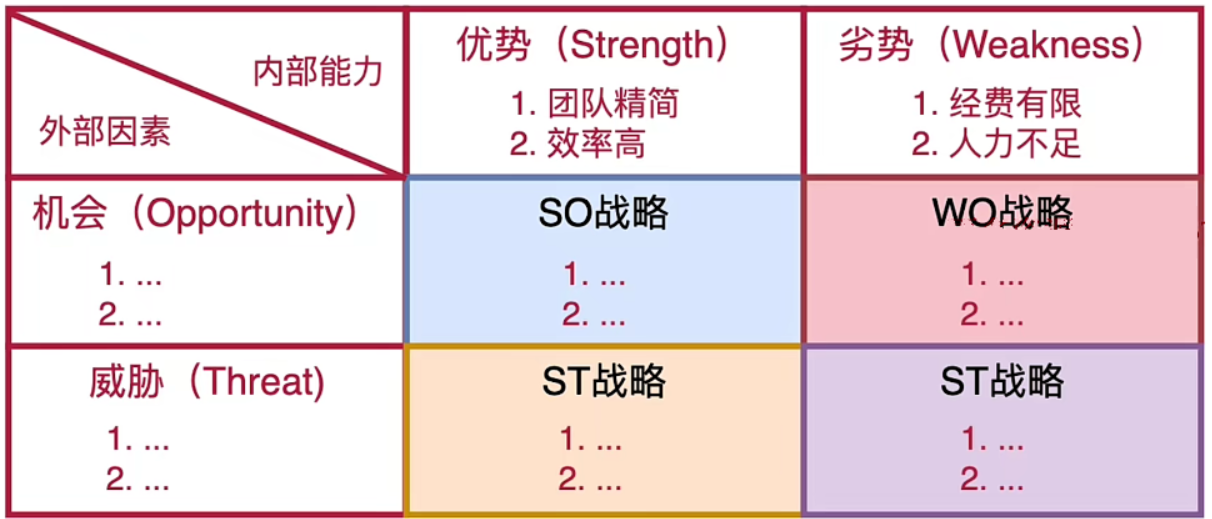
(2)SWOT分析法
SWOT分析法比较适合做一些宏观层面的技术选型。
适合做一些更上层、更加抽象的技术选型,比如说确定公司未来五年的技术方向是用云原生技术体系还是传统的技术体系?
SWOT是一个比较通用的分析框架,不仅仅可以用来做技术上的一些决策,还可以做企业的战略规划、分析竞争对手、个人的职业发展等等。
从优势(Strength)、劣势(Weakness)、机会(Opportunity)、威胁(Threat)这四个维度分析问题。
优势、劣势是内部的能力,而机会和威胁则是外部因素。

5、项目、团队、技术选型的映射关系
(1)项目生命周期 - 短生命周期
建议选择门槛低、简单易上手、开发速度快的技术。(糙快猛)
开发过程也可以相对自由。
这是因为项目一旦结束,代码就会直接被抛弃,精雕细琢的意义并不大。
(2)项目生命周期 - 长生命周期
首先考虑可维护性,优先考虑成熟稳定的技术。
(3)项目地位 - 边缘性项目
影响面相对较小,有一定的故障容忍度。
可以作为项目的技术试验田,尝试比较新颖的技术或者方案,从中积累经验和教训。
(4)项目地位 - 核心项目
稳定优先,做相对保守的技术选型。
同时也要考虑可维护性。
优先选用比较成熟,团队内部已积累足够经验,同时有比较好的技术支持的技术。
(5)项目新旧 - 新项目
相对更加灵活。技术选型也很自由。
(6)项目新旧 - 老项目
优先选择能和现有技术体系无缝融合的技术。(降低学习成本、降低项目风险、便于后期沉淀到技术体系中)
(7)项目类型 - 探索型项目
探索型项目初期,希望迅速出成果,快速试错,试错不成功的话,就会成为一个短周期项目。如果试错非常成果,就有可能进化为长周期项目,甚至核心项目。
探索型项目不确定性高。
所以既要快速,也要考虑可维护性。
优先保障简单性,不做太多预留。(需求不稳定,预留的扩展点,后续可能都用不上,甚至可能会成为负担)
但是,目前很多公司,初期只考虑快,等到项目爆发增长了之后,再把中心往可维护性偏移。(不建议这样做,出来混总是要还的,技术债总是要还的)
所以,探索型项目,非常考验架构师CTO的业务敏感度、技术嗅觉、直觉,做技术上的预判。
(8)项目类型 - 守成型项目
稳定优先,不要轻易引入新的技术。
如果要引入新技术,则引入能够无缝地融入当前技术体系,且有人精通的技术。
守成型的项目,格局已经顶下来了,投入需求也不会有一个特别大的变化,投入产出比不高,不值得我们做特别大的改造。
(9)项目维度 - 总结
低价值的项目,优先考虑门槛低,速度快的技术;
高价值的项目,尽早进行投资性的技术积累,考虑天花板高、比较成熟的技术,并融入企业现有技术体系,
(10)团队技术实力 - 较强
可结合项目的情况,一定程度上选择相对新颖的技术。
并且新技术往往代表技术趋势,代表更高的生产力。
(11)团队技术实力 - 薄弱
建议继续在现有的技术体系之下发展,不要做过多的折腾。
技术选型尽量平滑,控制在现有技术体系的范围之内,减少适应成本,降低风险。
还可以增强团队交付记录,定好技术上的约束。(编程规约)
还是需要走出技术薄弱的困境,定期组织团队内技术分享、组织技术比赛、1带n树立技术榜样。
(12)团队规模 - 小规模
优先考虑技术的简单性、实施成本和效率。
(13)团队规模 - 大规模
大团队的问题:
团队人员的能力参差不齐,很难照顾到所有人的情况。
不同人的想法不同,对技术的偏好、技术方向也可能不一样,很难听取每个人的建议和意见。
很难做出符合所有人利益的决定。
大规模团队沟通噪声很大。
解决方案一:
通过领域驱动设计等思想,细分问题域,一个大问题拆分成若干个小问题。
把细分出来的问题,分给多个小规模的团队去承接。
将问题交给各个团队自治,由各个团队主导去做技术选型。
大团队拆成小团队。
解决方案二:
如果大团队无法拆成小团队,
需要制定战略方向、战术方向、技术方向。
定好 规约,把技术选型局限到一定的范围内。(比如只允许使用java、只允许使用spring生态)
制定好团队的技术规范,让大家知道什么是不允许的。(比如,禁止使用多个微服务共享1个数据库的方案、远程通信必须使用轻量级且能跨平台的协议)
但是也要设置特权机制,特殊原因特殊对待。(技术评审通过才可以)
(14)团队 - 组织架构
康威定律:组织沟通方式会通过系统设计表达出来。
项目架构其实是团队沟通协作方式而产生的一个结果。
(比如,公司前后端都是一个人搞,很可能不会做前后端分离。想要做前后端分离,就要前后端分工)
所以,需要结合当前团队组织架构的特点,考虑选用的技术在最终技术架构中的位置、与当前团队沟通结构的匹配程度。
(15)团队 - 总结
需要客观认识自己的团队,了解团队内部特点。
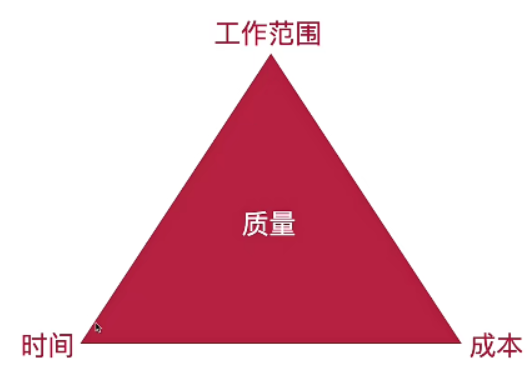
(16)项目管理四要素
四要素:质量、工作范围、时间、成本。
理想情况:好、多、快、省。(实际上这四个项目是互相制约的)
考虑到多数情况,质量是不能妥协的,所以就有下面的模型:
(17)总结
做技术选型,是一个需要综合考虑的事情,具体问题需要具体分析,这需要架构师拥有大量的经验,从日常工作中逐步积累经验,才能做好技术选型。
6、如何选择技术栈的版本
(1)概述
软件版本是很多技术人员会忽视的东西,但是确实应该重视起来。
选择不同的版本,可能会有使用上的差异(比如Angular1.x和Angular2.x)、功能上的差异(JDK各个版本新特性)、版本升级的差异(Springboot1.x升级到2.x改动非常大)
(2)常用版本命名方式1 - 语义化的版本命名
Semantic Versioning官网:https://semver.org/lang/zh-CN/
比如:1.2.3.RELEASE
1:主版本(Major),表示做了不兼容的修改。
2:次版本(Minor),表示向下兼容的功能性新增。
3:增量版本(Patch),一般表示向下兼容的bug修复。
RELEASE:里程碑(Milestone),表示版本状态(SNAPSHOT-开发版、RC-正式版的候选版、CR-正式版的候选版、RELEASE-正式版、Final-正式版)
(3)常用版本命名方式2 - 版本代号
比如:SpringCloud、SpringData、Android、Ubuntu、macOS……
比如说SpringCloud的Hoxton.SR9版本,但是现在基本放弃这种版本了,改用日历化版本的命名方式。
(4)常用版本命名方式3 - 日历化
Calendar Versioning官网:https://calver.org/overview_zhcn.html
比如:2024.0.1.RELEASE
2024表示主版本(Major),表示发布年。
0:次版本(Minor),表示功能新增。
1:微版本(Micro),表示最终编号,有时表示“补丁”。
RELEASE:修饰符(Modifier),表示版本状态。
(5)版本选择原则
1 - 新旧版本不兼容,优先用新版:
老版本早晚会废弃,跟随官方的步伐与软件发展的规律,否则得自己维护了。
2 - 最新的次版本可以观望:
最新的次版本不建议直接用在生产,还不是很稳定。建议观望3个月以上,看看有没有什么明显的bug。
3 - 总是使用BOM:
BOM:Bill of Materials,定义一整套jar包版本的集合。从而让应用引入jar包依赖的时候,只要引入这个bom就可以放心的使用依赖包了,不需要自己去指定版本号,这些jar包的升级都会由bom的维护方去负责,并且bom的维护方会保证定义的jar包版本之间的一个兼容性。
Maven中BOM
4 - 尽量使用正式版
正式版都比较稳定,但是也有例外,有时候正式版有一些奇怪的bug,在非正式版做了修复。
5 - 尽量选用LTS版本
LTS(Long Term Support,长期支持版本)。
比如jdk8、11、17是LTS版本。比如说Ubuntu偶数年的4月份发行的版本是LTS版本,比如14.04、16.04
6 - 关注软件间的兼容性关系
比如说Springboot与SpringCloud之间的兼容性关系。
(6)如何找版本?
官网。
wiki。
软件安装指南、quick start。
7、技术选型失败如何补救?
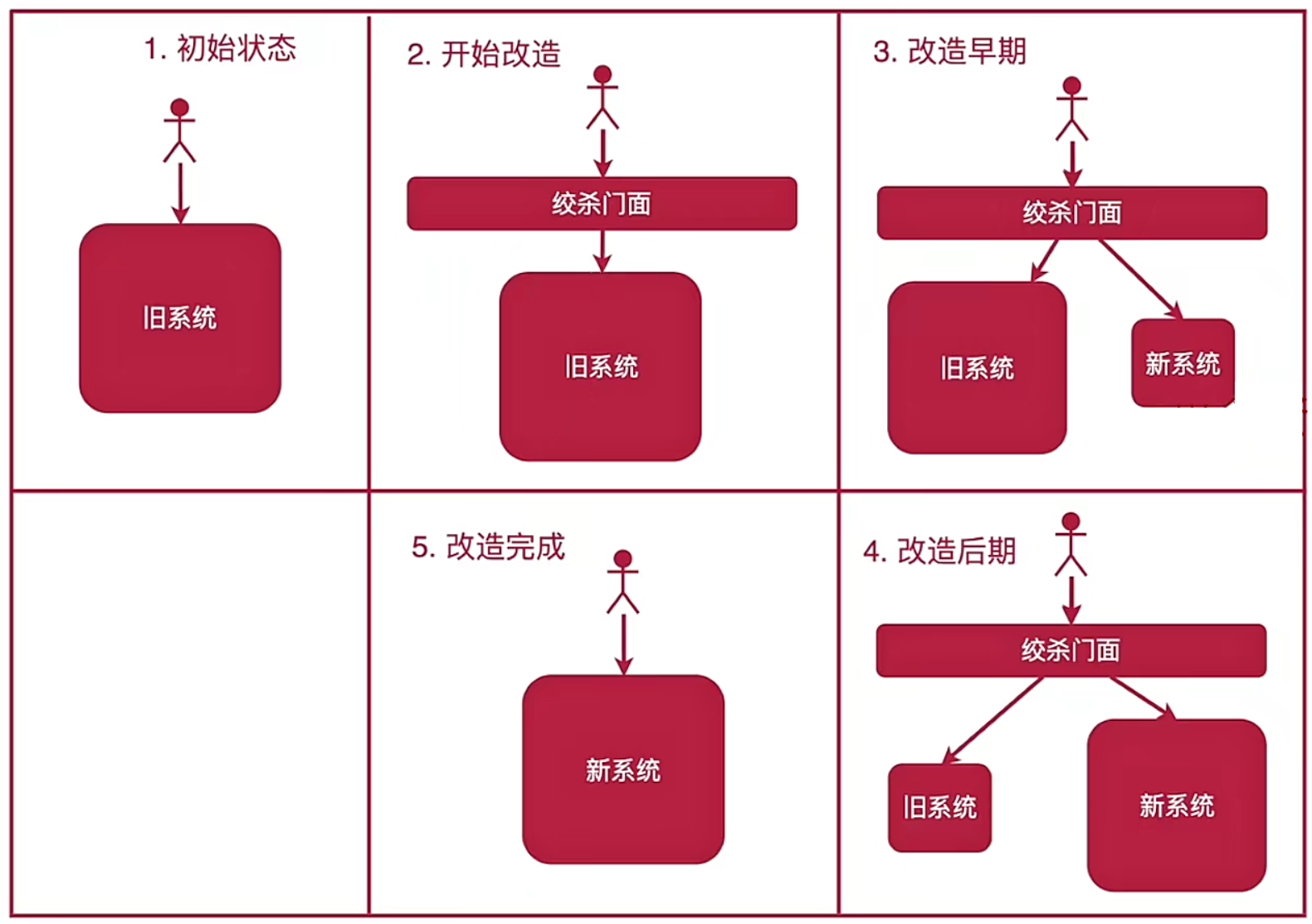
(1)绞杀者模式
在旧的系统外围,将新功能用新的方式构建,随着时间的推移,新的部分逐步绞杀旧的系统。
适合重构技术栈完全不同的应用,适合重构大型复杂的旧应用。
不适合无法拦截前往旧系统的请求,不适合局部修改就能达到目标。
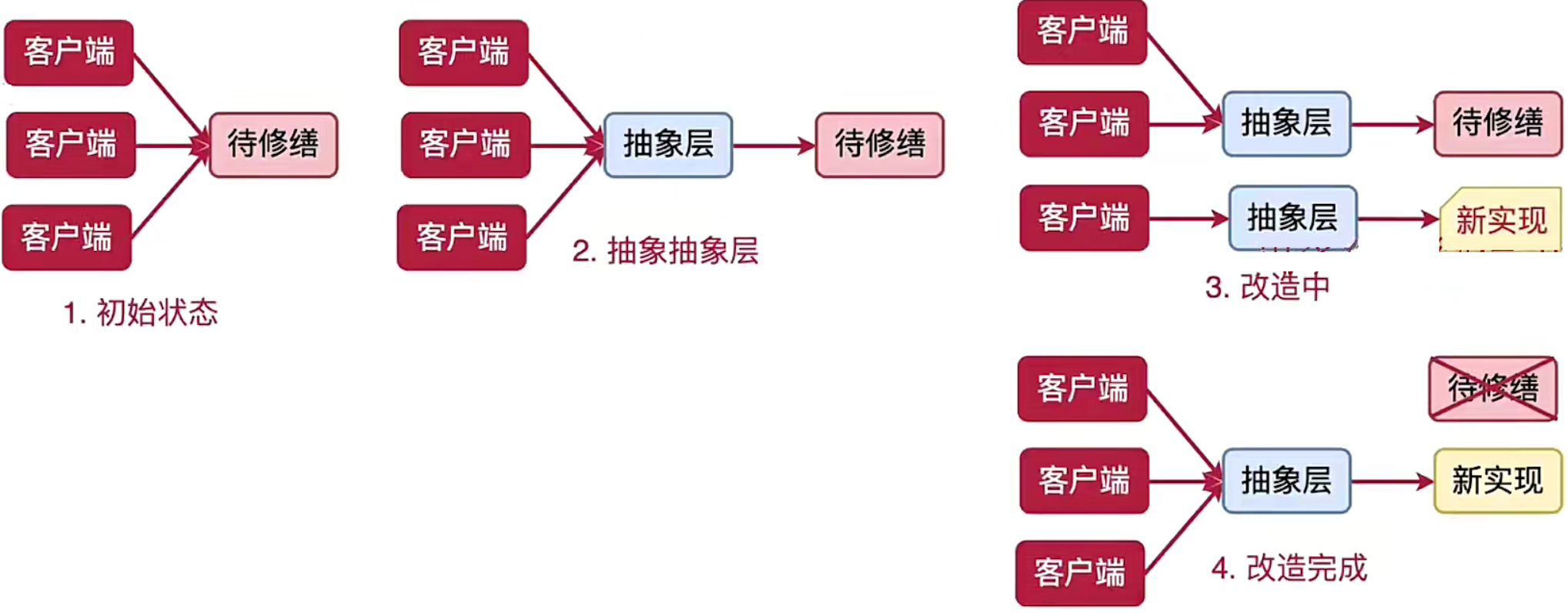
(2)修缮者模式
像修房或修路一样,将系统中待修缮的部分隔离起来,用新的方式对其进行单独修缮。
适合能够局部改造的场景,不适合需要全盘改造的场景。
二、基于业务量级的技术选型
1、单机应用
(1)概述
多为个人项目,企业项目用的不多。
原则:选择快和省,妥协好和多。

(2)单体应用技术选型
(GitHub、Gitee……)搜索是否有现成的产品,如果有的话,可以直接用。
用最熟悉的技术、最快的速度上线。
如果有经费:考虑商业化解决方案。
前端技术选型:
列出当下能够找到的所有流行选项;
使用排除法过滤掉和自己期望不匹配的选项;
针对其中符合条件的选项上手测试,并做出最终选择。
2、应用服务、数据服务分离
(1)概述
企业级应用的起步阶段,通常是这种技术模式。
应用起步阶段,需要选择合适的技术实现项目的落地,为项目未来的发展方向定好基调。
(2)要考虑的问题
运行平台的选择(windows、linux、java、php)。
商业解决方案还是开源解决方案。
确定项目研发模式。(前后端分离、开发运维协作)
确定具体使用的技术。
工期紧张,经费充足:商用解决方案。
技术实力强,工期不紧张:技术上的投资,选新颖的技术。
经费足,某领域技术沉淀少:局部领域商用。
(3)本阶段技术选型的特点
非常灵活,限制很少。
团队人数较少,比较容易达成一致。
不一定会按照前面介绍的步骤按部就班。
3、引入缓存系统
(1)背景
数据量的增大,导致数据库响应 比较慢。
并发较高,数据库压力非常大。
访问速度慢。
(2)要考虑的问题
在哪个位置使用缓存。采用什么类型的缓存。采用哪种缓存模式。具体用什么缓存组件。
1.客户端缓存 - 页面、APP;2.网络中的缓存 - nginx、CDN;3.服务端缓存
通常情况下,没有性能瓶颈暂不考虑缓存,哪里慢就在哪里用缓存
内存缓存 - 速度快,但是数据可能会丢失,适用于速度要求非常高,容忍数据丢失的场景。
磁盘缓存 - 性能比内存缓存差,数据不会丢失,适用于需要持久化的场景。
堆内缓存 - 不需要序列化、反序列化,性能很好,但是会对GC造成影响,容量受限于堆内存大小,一般用软引用或弱引用存储,适合存储非常热的数据。
堆外缓存 - 不对GC造成影响,只受机器内存大小的限制,不受堆内存限制,可以在多个进程之间共享,减少JVM之间的对象复制。需要实现序列化和反序列化。适用于存储生命周期长的对象,适合同一台服务器部署多个进程,并且需要共享内存。
本地缓存 - 一级缓存
分布式缓存 - 二级缓存
Cache Aside模式 - 首先访问缓存,如果缓存命中,就直接访问缓存的数据;否则,就从数据库里取数据,并存储到缓存里面去。(平时用的最多)
read through模式 - 读操作只会经过缓存,由缓存去从数据库加载数据。当缓存请求的key在缓存里面不存在时,缓存会用加载器自动从数据库读取数据;下次缓存请求相同的key时,则会从缓存直接返回,无需用加载器到数据库里取数据。
write through模式 - 类似于read through,只是作用于写操作。写操作都会经过缓存,每次向缓存写数据时,缓存会把数据持久化到数据库。
write behind模式 - 类似于write-through,但不是实时写入数据库,而是异步的。
(3)缓存框架
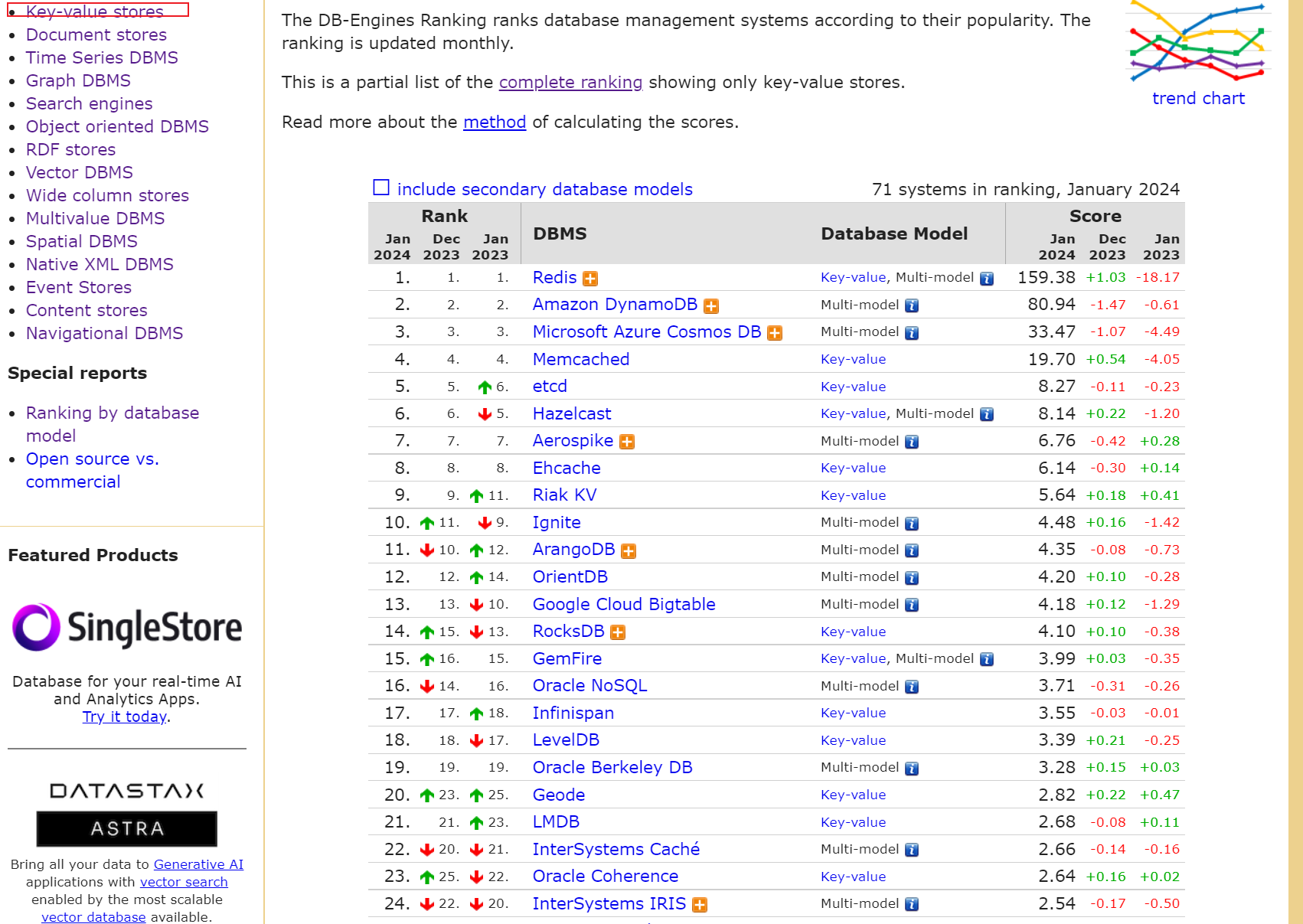
EhCache、Guava Cache、Redission、Caffine、JetCache、Redis、Hazelcast、Memcached、Infinispan等。
可以从DB engines 查看k-v数据库排行榜
4、负载均衡
(1)概述
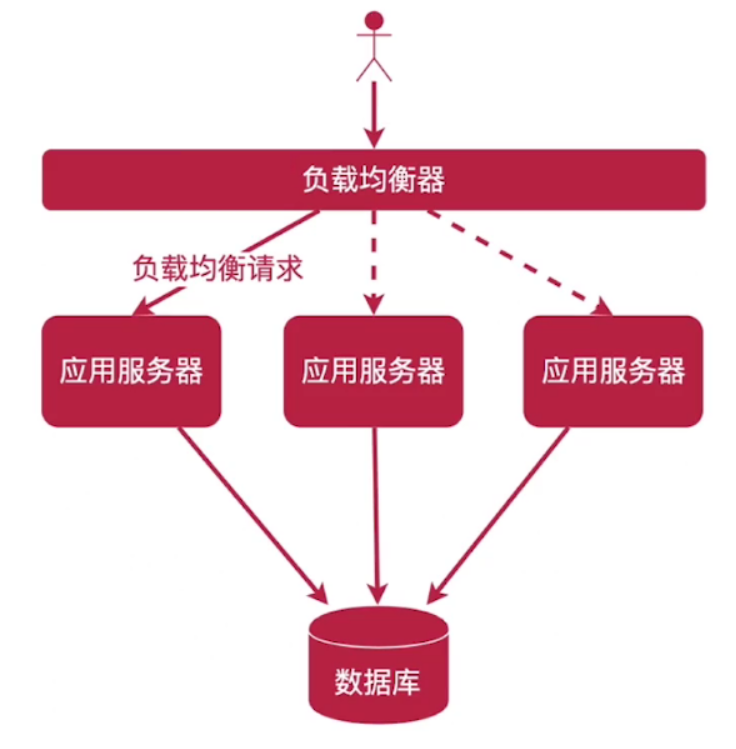
(2)基于DNS的负载均衡
在DNS服务器上为多个地址配置相同的解析记录,这样在域名解析时,DNS就会根据负载均衡算法计算出一个地址返回,也可以根据地域来返回ip。
配置DNS负载均衡:https://docs.dnspod.cn/dns/help-round-robin/

优点:
把负载均衡的工作交给了DNS服务器,减少了网站管理的维护工作。
技术实现比较灵活方便、简单、成本低。
适用面广,能适用于大多数TCP/IP应用。
缺点:
一般不能反映服务器当前运行状态。(服务挂掉不会自动剔除)
某台服务器下线之后,即使修改了DNS记录,要想让记录生效可能需要很长时间,有缓存。
所以使用DNS负载均衡,保证DNS解析指向的目标地址的高可用,地址不会经常修改。一般来说,大型网站会使用DNS作为一级负载均衡。
DNS指向的IP,对应的并不是一台机器,而是高可用的服务器集群,比如说LVS集群。
可以使用dig查看dns的记录。
(3)基于反向代理的负载均衡
请求经过反向代理,由反向代理组件提供负载均衡算法,计算出一个服务器地址返回。
代表实现:Nginx、HAProxy、Apache。
(4)基于特定协议的负载均衡
比如:基于NAT的负载均衡。(在请求的时候把外部IP转化为内部IP,再在内部IP对应的机器上进行处理,处理完成之后再转换回去并返回,比如LVS)
(5)如何选择负载均衡组件
确定好用什么类型的负载均衡器之后,搜索该类型下的负载均衡器实现,并通过因素加权法获得结果。
项目初期:nginx。
项目中期:节课Keepalived实现nginx的高可用。
之后,再搭载LVS或者F5,从而扩展多个nginx。
如果一个LVS集群顶不住的话,会再结合DNS扩展LVS。
5、有状态vs无状态
状态:是指服务器是否要存储用户的登录状态。(服务器端是否要维护用户的会话)
(1)粘性会话
当客户端在一台Web Server上登录之后,以后的请求都会绑定到该WebServer实例。
优点:无需引入额外组件,实现简单,只需要在负载均衡器配置iphash即可。
缺点:存在单点问题,存在负载不均衡的问题。所以,在实现粘性会话时,往往需要实现故障转移,session额外存储进一个session store。
实际项目中很少会采用这种方式,如果非要用的话,一般就是用nginx+ipHash的方式。
(2)会话共享
应用使用session保持会话,多个应用实例存储到一个中央存储中去。
需要额外引入组件,即使任意web应用崩溃依然可用。
一旦session store崩溃,所有会话丢失,所以需要实现session store的高可用。
可以考虑使用spring session。
(3)会话复制
web server实例之间互相复制会话。
无需实现故障转移、无需引入额外组件。
会话复制消耗带宽和内存,建议在小规模集群中使用。(实例不超过3)
一般由web容器自身提供,比如tomcat cluster就可以实现。
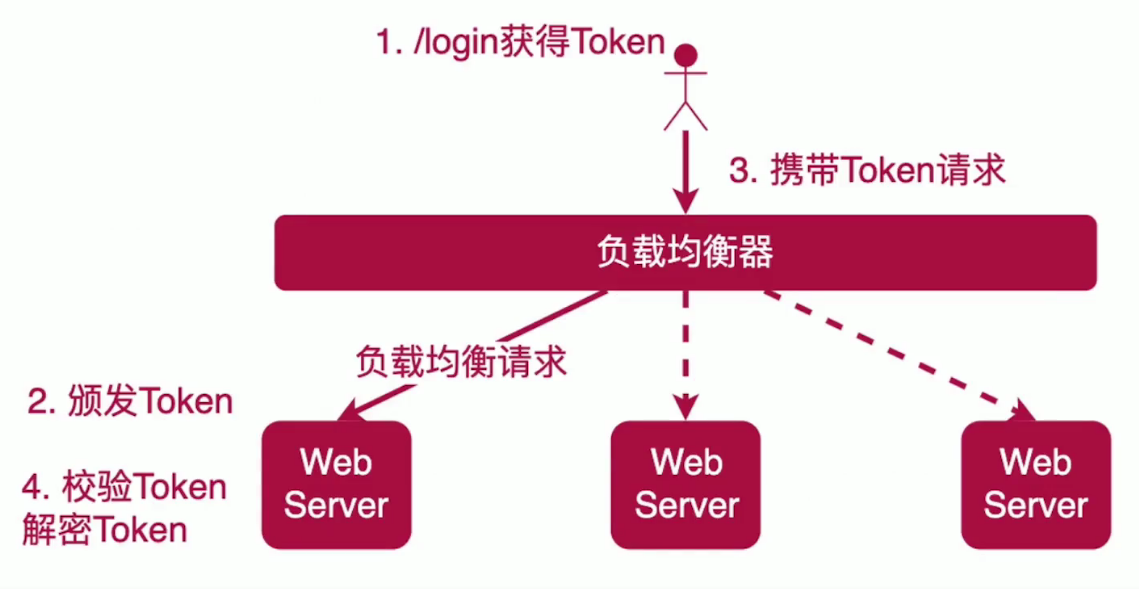
(4)无状态
服务器端不去记录用户的登录状态。(服务器端不去维护会话)
用户登录时,颁发一个token,这个token一般是加密的。
之后每个请求都会带上这个token(放在header、url参数、cookie中传递)。
服务器端拿到token后,校验token是否合法,是否过期。
可以在token中存储一些不太敏感的用户信息,解密token就可以获取。
token也可以进行存储,比如说存入redis,但是这又像是有状态了。
所以,有状态和无状态,需要结合使用。
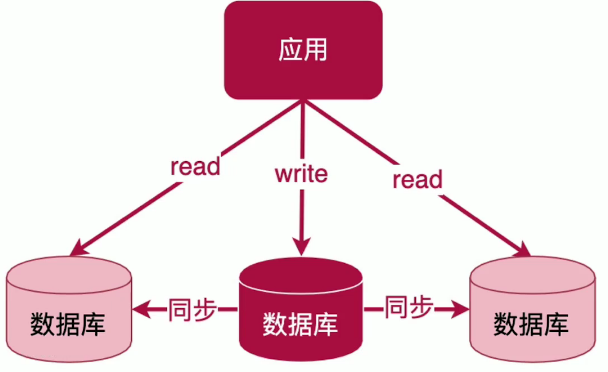
6、读写分离
主节点写入,从节点读取。
7、数据垂直、水平拆分
(1)垂直分表
将字段较短,访问频率较高的字段尽量放在一张表。
将字段较长,访问频率较低的字段尽量放在一张表。
把经常一起组合查询的字段尽量放在一张表。
经验之谈:单表字段尽量不要超过30个。

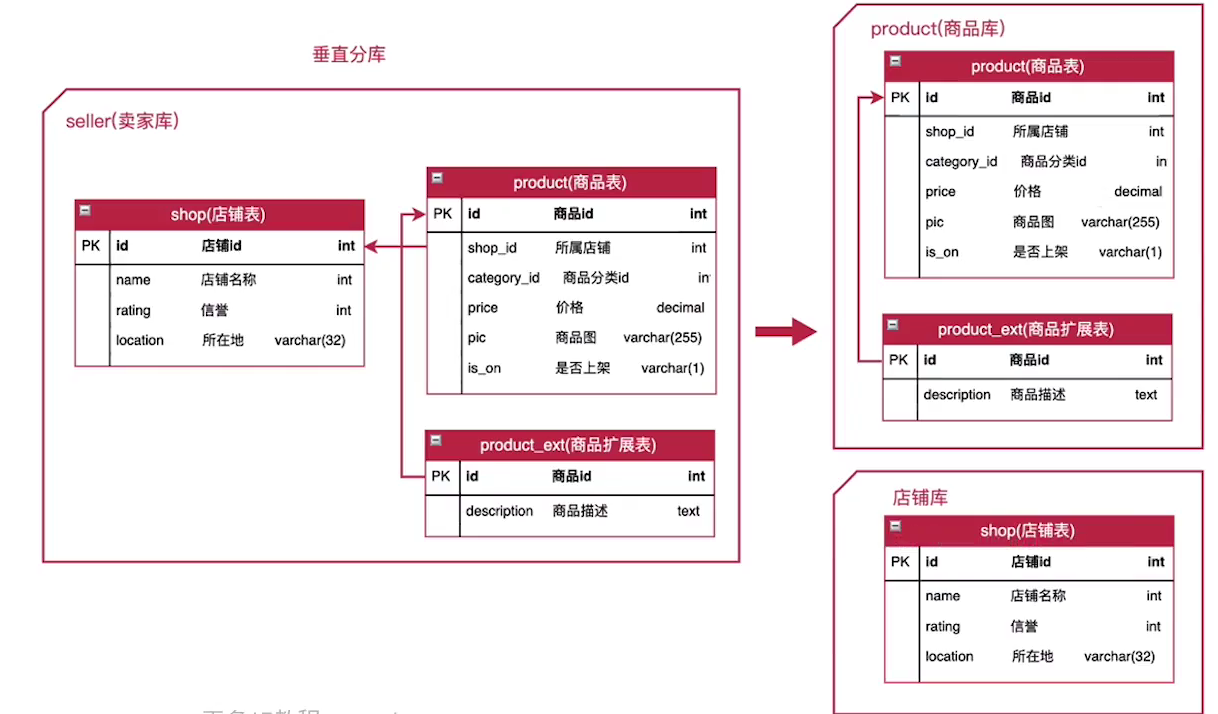
(2)垂直分库
按业务分类,把不同业务分布到不同数据库上。
优点:
业务层解耦,业务边界比较清晰。
把数据分布到不同的数据库上,多个数据库可以分担压力。
能对不同的业务数据进行分级处理、分别维护、分别扩展。
可以提升单个库实例的IO、连接数,降低单机硬件资源的瓶颈。
缺点:
很难实现跨数据库实例的JOIN,即使实现,性能也不理想。
如果原先使用了JOIN,需要进行代码改造 - 分次查询、冗余同步。
所以,拆分的库应该相对独立。
(3)水平分库
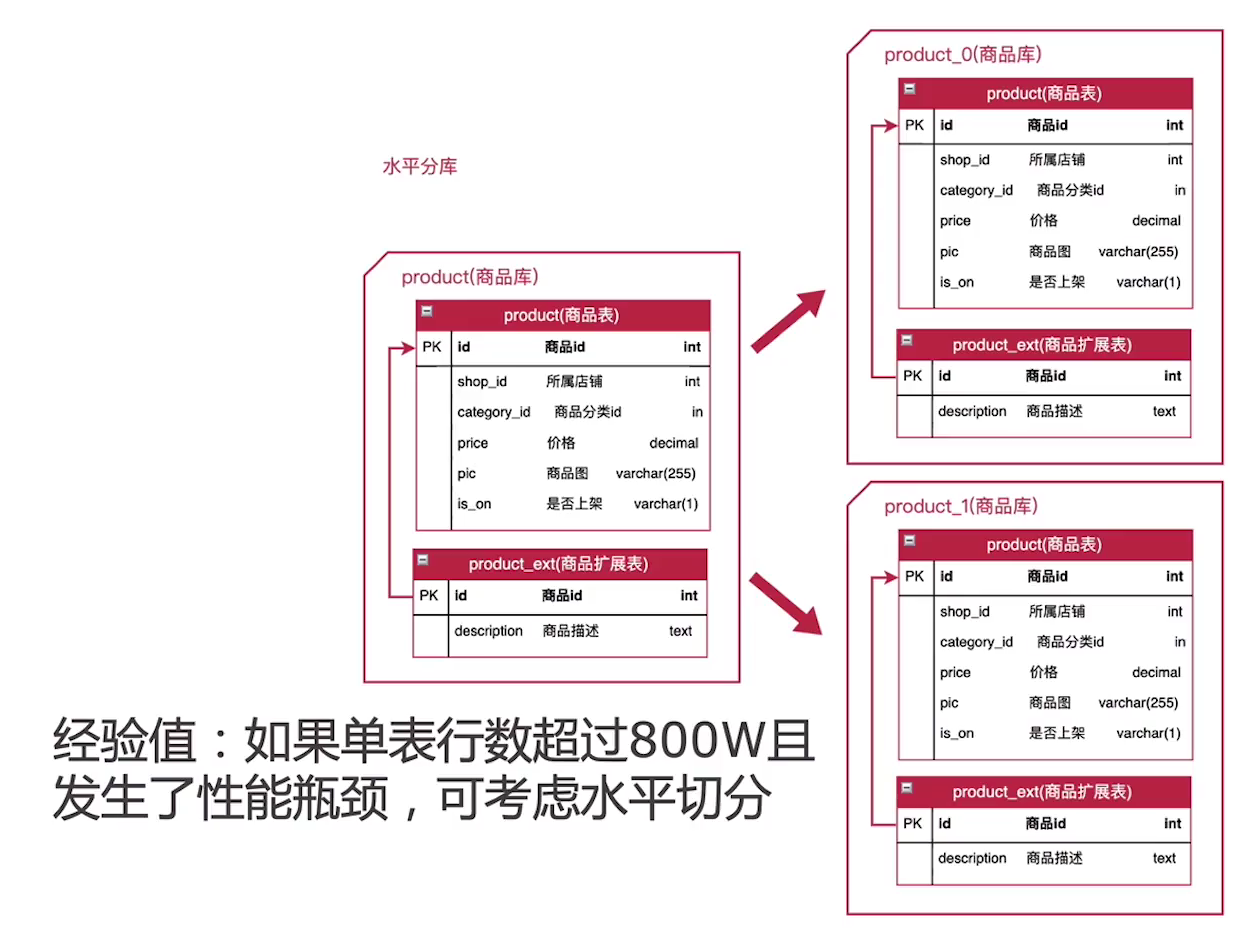
适用场景:
单表数据量非常大的场景。
(4)水平分表
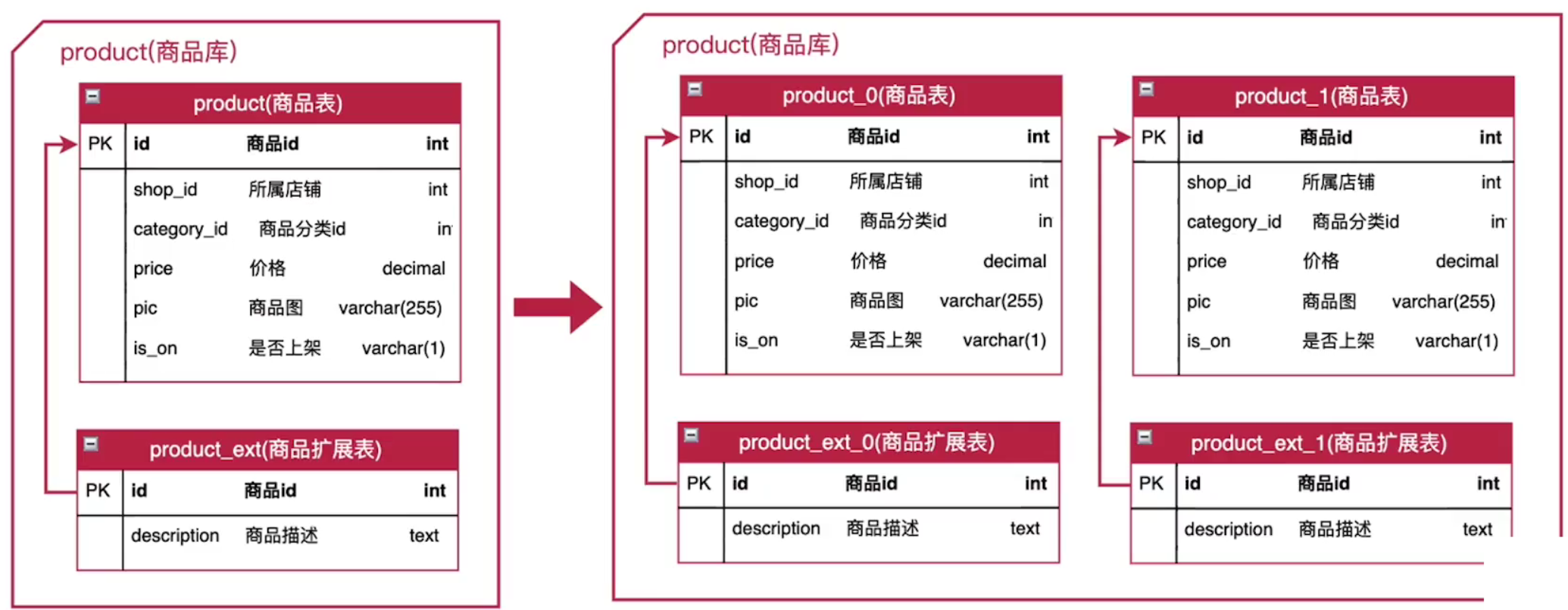
(5)水平切分最佳实践
切分后,每个子表数据量不是很大。(MySQL:单表800W以内)
查询能够在一个或者少数几个子表里面完成。
切分规则1 - 枚举
根据某个字段的值,按照枚举进行分片。(country 值0、1、2……)
切分规则2 - 取模
某个/些字段进行hash,取模。
切分规则3 - 范围
根据某个字段的值的范围分片。(id 1-200w,200w-400w……)
在系统涉及阶段,根据业务的耦合程度就需要确定一个初步的垂直分库、垂直分表的方案。(业务发展过程中,动态调整)
在数据量大、访问压力大时,先考虑索引优化、读写分离、表结构优化、缓存等方案;再考虑水平分库水平分表方案;如果也无法解决,考虑使用非关系型数据库。
(6)分库分表中间件选型
MyCAT、Sharding-Sphere、Sharding-JDBC、Sharding-Proxy、Sharding-Sidecar。
8、分布式文件系统
(1)应用与文件资源不分离
项目初期,由于时间紧迫,各种资源比较有限,我们常常采用应用和文件资源不分离的方式,直接在应用服务器的某一个目录创建一个文件夹,或者在该目录下建立不同子目录区分类型。
再或者,将blob数据存储到数据库中。
优点:简单、方便。
缺点:文件和代码/数据库耦合。文件占用资源,影响应用/数据库运行。
(2)应用与文件资源分离
优点:应用服务器可专注于自身业务,文件服务器专门存储文件。
缺点:单台机器容灾能力差,单台文件服务器可能有性能瓶颈。
(3)分布式文件系统
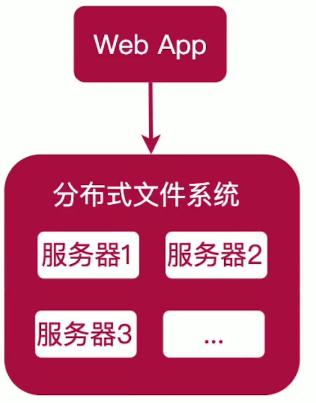
分布式文件系统组成:
文件存储子系统 - 负责文件存储;
文件仲裁子系统 - 负责按照一定算法决定文件存储的位置,相当于分布式文件系统的大脑;
文件容灾子系统 - 容灾能力,可用性得到了显著增强。
优点:容灾能力、高可用性显著增强;扩展能力得到改善,增加或缩减存储,或者想删除某些资源时,都无需中断系统。
缺点:需要更多服务器,复杂度、运维成本增加。
(4)如何选择分布式文件系统
参考资料:https://www.cnblogs.com/yswenli/p/7234579.html
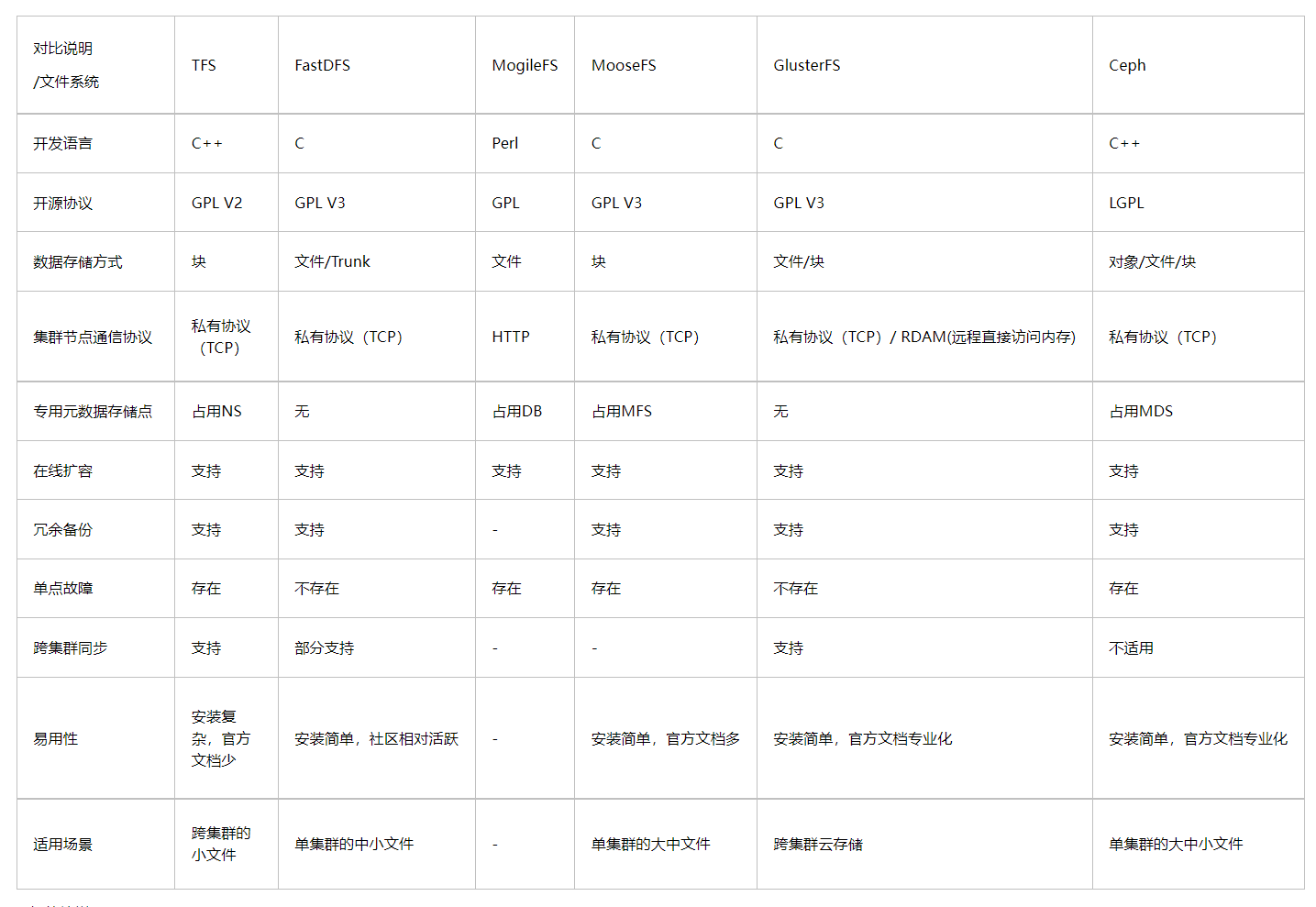
(5)各种文件存储方案适用场景
| 存储方式 | 本地存储 | 数据库存储 | 文件服务器+定期备份 | 文件服务器+Raid | 分布式文件系统 |
|---|---|---|---|---|---|
| 方式 | 个人项目/起步 | 对查询性能无要求的企业项目 | 非核心小型企业项目 | 中小型企业项目 | 大中型企业项目 |
| 原因 | - | 该模式会影响数据库性能 | 部分数据丢了能够容忍,定期备份即可 | 有一定容灾需求,单台服务器即可承载文件 存取 | - |
9、CDN
(1)概述
CDN对于静态文件(html、css、js)的加速和发布有非常好的效果,但是对于动态数据效果很差。
由于CDN的这种特性,为了用好CDN,我们常常会动态内容静态化(动态网页渲染成静态HTML)、动静分离。
(2)CDN组成原理
CDN是一种组合技术,最简单的CDN网络由一个DNS服务器和几台缓存服务器组成。
假设客户端是一个浏览器,用户点击一个网站的URL,DNS会根据客户请求的来源(地域、网络商),把请求转发到最近的或者最快的缓存服务器。缓存服务器为用户提供站点的资源,如果缓存服务器已经缓存了想要的访问的资源,就直接返回。所以,使用CDN可以做静态文件的缓存。
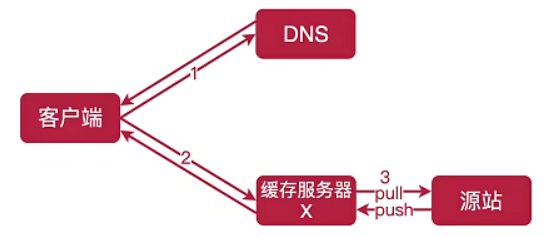
(3)CDN技术选型
优先使用商用CDN,商用CDN满足不了业务需求,再考虑自建。
自建CDN需要投入很多的服务器、宽带、运维的成本。
大部分企业都达不到自建CDN的程度,像小米、快手、大众点评等,都是使用商用CDN。
(4)自建CDN
总体来说就三个问题:用什么DNS系统?用什么缓存系统?用什么反向代理软件?
(5)淘宝CDN系统架构
https://wenku.baidu.com/view/0bdaedddec3a87c24128c435.html
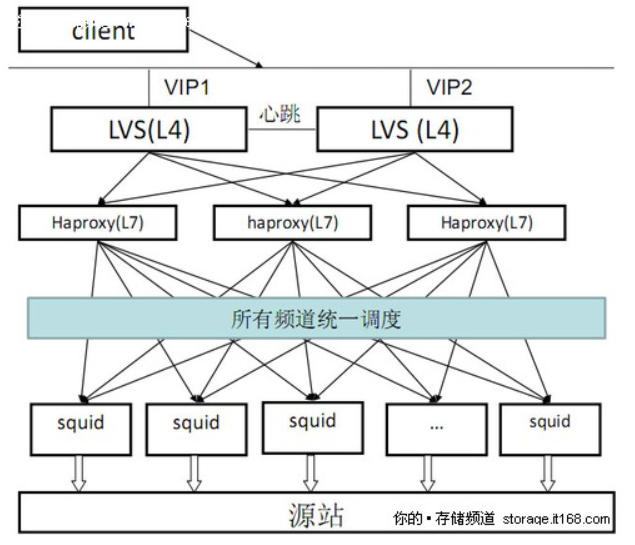
(6)商用CDN
Fikker:https://www.fikker.com/
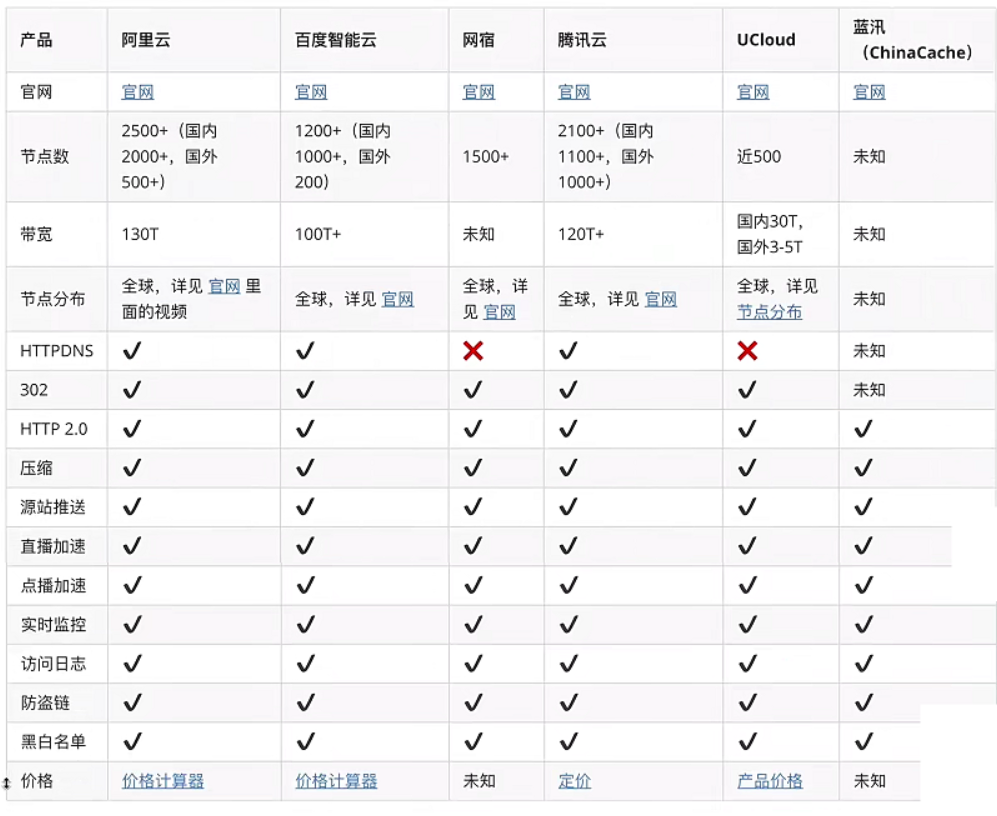
商用CDN考虑因素:
速度(节点数、带宽能力、节点分布,查询网站:https://cdn.chinaz.com/)
功能(加速优化、监控统计、安全性)
价格(按带宽峰值计费、按流量计费)
https://www.hostucan.cn/cdn
10、全文搜索
(1)概述
使用全文搜索,减轻了数据库查询压力,推升应用性能,提高用户体验。
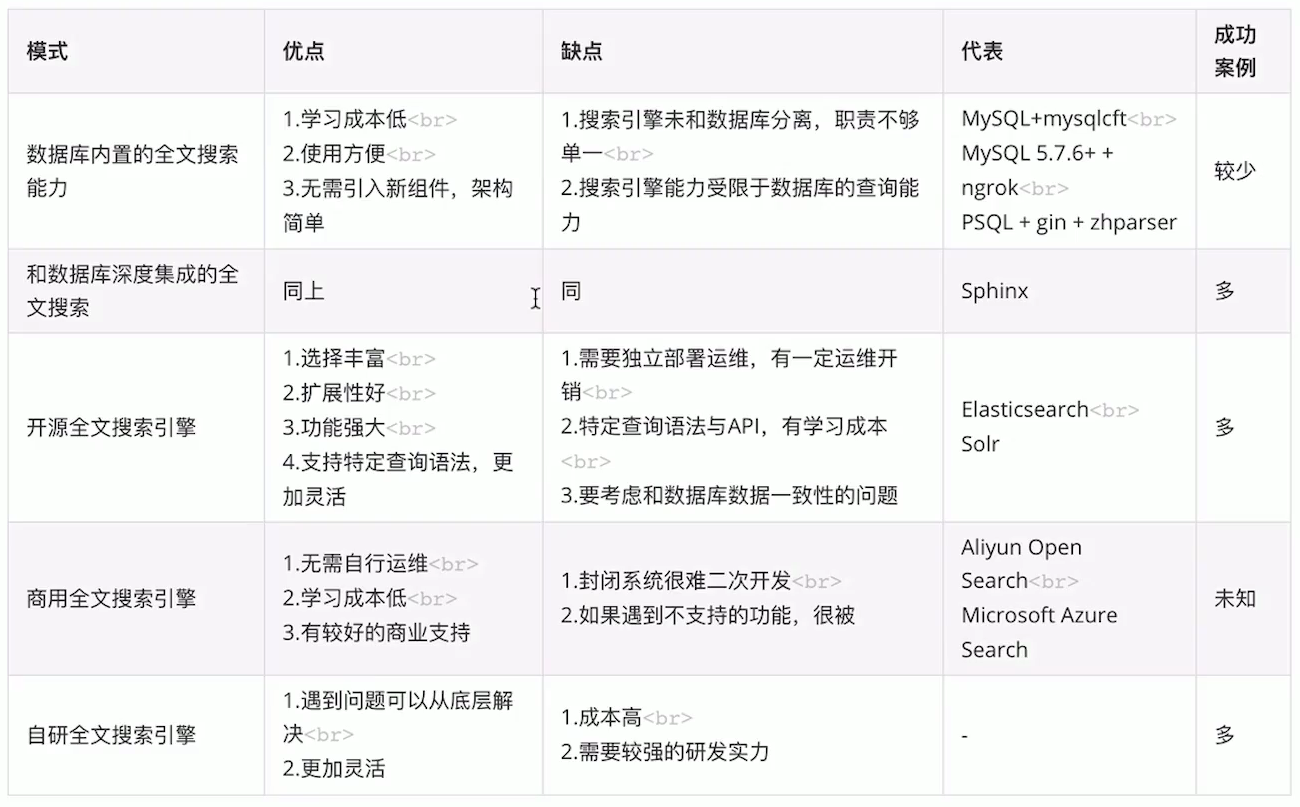
(2)使用数据库内置的全文搜索能力
MySQL的InnoDB、MyISAM都支持全文索引。
早期,mysql不支持中文,需要使用mysqlcft之类的插件,MySQL5.7.6之后,官方推出了ngrok,支持中文。
PostgreSQL:gin索引 + zhparser/pg_jieba。
优点:学习成本低,使用方便,不需要引入新组建,保持了架构上的简单性。
缺点:搜索引擎没有和数据库分离,数据库的职责不单一,全文搜索的能力会受限于数据库的查询能力。
数据库插件维护都不给力,最好不要用这种方式。
(3)使用和数据库深度集成的全文搜索
代表实现:Sphinx。
可独立运行,可与MySQL、PostgreSQL深度集成。
优点:成本低。
缺点:扩展性优先。
看中运维成本,并且对扩展性没有太高要求的话可以使用。
Sphinx相对于其他全文搜索引擎来说,功能并不是很强,国内文档也不多,并且越来越多的企业正在弃用这种方案。
(4)使用开源全文搜索引擎
目前最主流的方式,选择丰富,扩展性强。
缺点:
需要独立部署搜索引擎;
需要使用搜索引擎特有语法,有学习成本,但是更灵活,支持更加复杂查询;
数据库与搜索引擎数据一致问题。(双写、cdc方案)
可以考虑使用该方案。
(5)使用商用全文搜索引擎
例如 阿里云的Open Search,微软的Microsoft Azure Search,但是使用该方案的并不多。
商用产品有良好的服务,省事省心,可放心使用。
但是商用产品的封闭性带来的影响,只能使用固定的功能,无法二次开发。
(6)自研全文搜索引擎
核心技术在自己手上,更灵活,遇到问题可以从底层调整与优化。
但是对团队的技术要求很高,成本高。
技术实力强、资金实例强的企业可以尝试。
(7)总结
搜索引擎排名:https://db-engines.com/en/ranking/search+engine
三、特定领域的技术选型
1、电商领域
略
2、互联网金融领域
借贷、保险、证券。
互联网金融比传统金融,满足更广泛群体的金融需求,增强金融普惠性,提高金融服务效率。
互联网金融领域近十年蓬勃发展,比如花呗、借呗、微粒贷、余额宝。
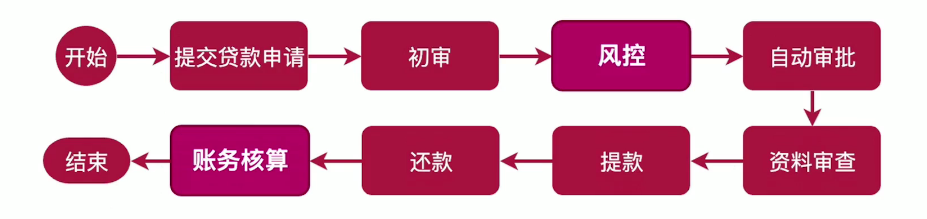
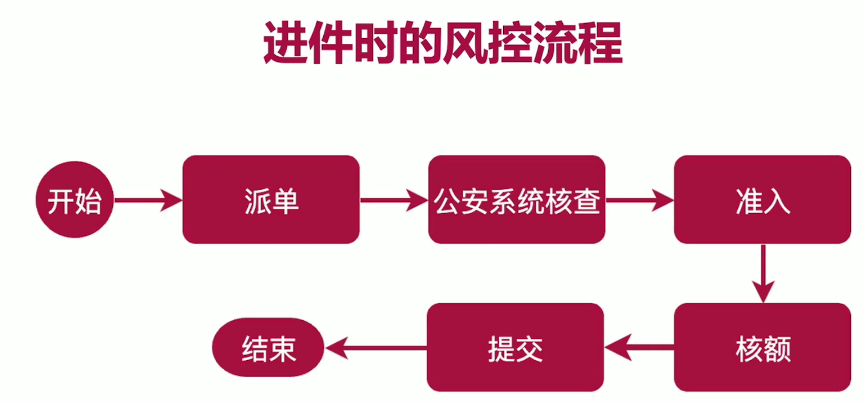
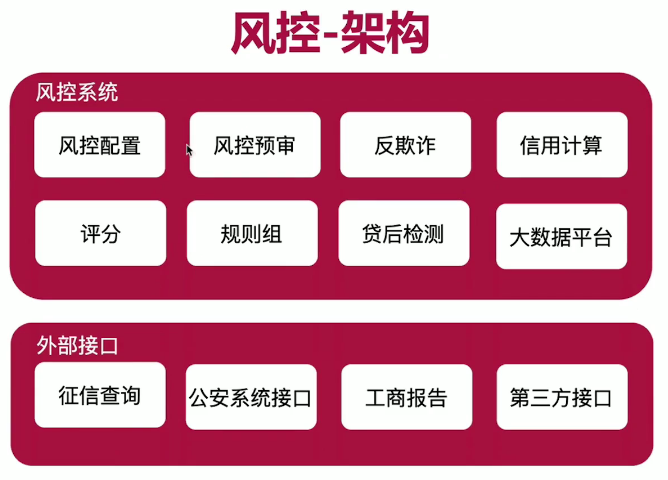
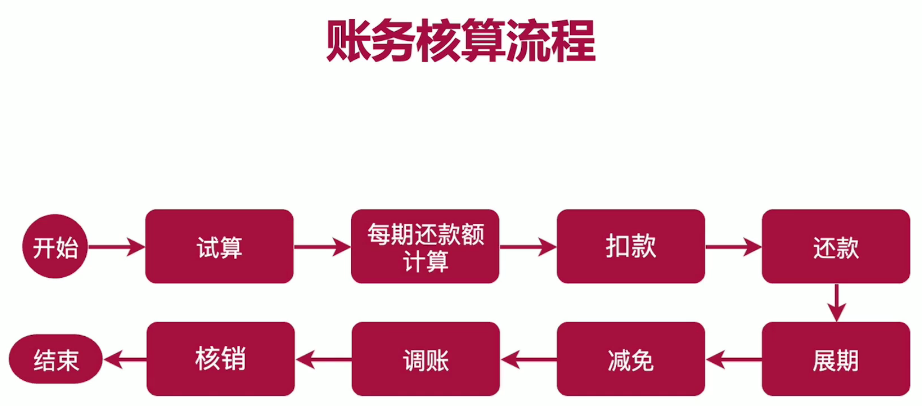

技术 体系:SpringCloud、Dubbo、SOFA、以Kubernetes为中心交付。
蚂蚁金服11.11:支付宝和蚂蚁花呗的技术架构及实践:
https://www.infoq.cn/article/technical-architecture-of-alipay-and-ant-check-later/
陆金所金融平台的架构大升级:
https://blog.csdn.net/gv7lzb0y87u7c/article/details/79674604
从宜人贷系统架构看互联网高并发对金融系统架构的挑战:
https://www.cnblogs.com/kms1989/p/5649387.html
支付宝的技术架构及实践——阅读心得:
https://www.cnblogs.com/ssyh/p/10631784.html
3、物流领域
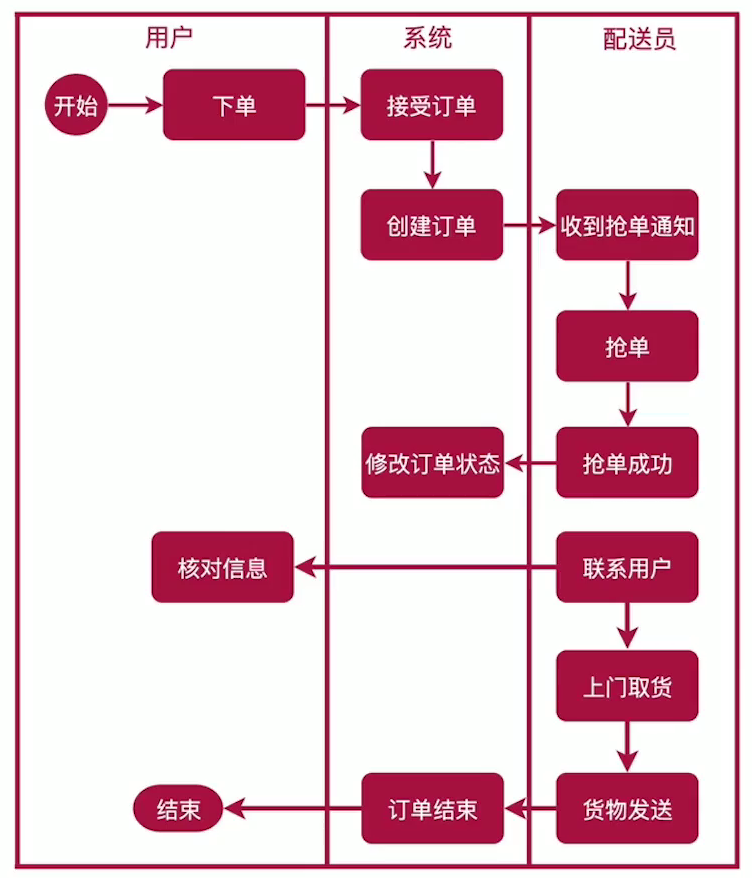

架构都是大差不差。
达达CTO:达达物流技术架构之路与技术分享
https://www.ttlsa.com/linux/dada-cto-share-tech/
菜鸟物流大数据技术架构
https://wenku.baidu.com/view/7c3f85a351e2524de518964bcf84b9d528ea2ccb.html
顺丰快递物流设计方案
https://wenku.baidu.com/view/7de81d674228915f804d2b160b4e767f5bcf8029.html
美团即时物流的分布式系统架构设计
https://tech.meituan.com/2018/11/22/instant-logistics-distributed-system-architecture.html
4、社交领域
(1)社交领域
熟人社交:QQ、微信。
短视频社交:抖音、快手。
直播社交:虎牙、斗鱼。
陌生人社交:陌陌、soul。
职场社交:钉钉、飞书、脉脉。
问答社交:知乎、百度知道。
婚恋社交:珍爱网、世纪佳缘。
社交媒体:Facebook、微博、Twitter。
儿童社交:小天才手表。
(2)直播社交
推流:是指将采集阶段封包好的内容传输到服务器的过程。
拉流:从直播服务器拉取直播内容的过程。(观众观看直播的过程)
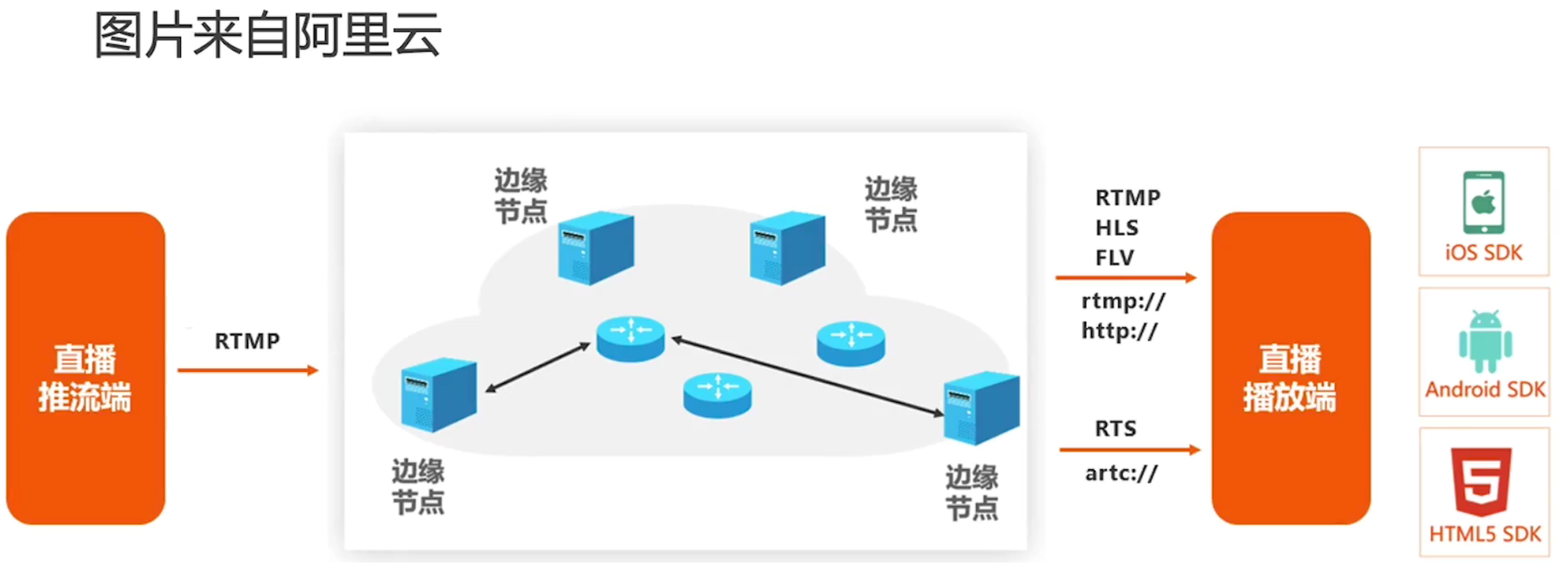

直播平台架构:
https://www.processon.com/special/template/5ce763fbe4b0240bd852ec96#map
直播平台的技术架构揭秘:
https://www.cnblogs.com/luojunwu/p/13099063.html
直播平台整体架构:
https://blog.csdn.net/kingmax54212008/article/details/84307500
斗鱼已公开的运维技术和架构分析:
https://www.cnblogs.com/pythonal/p/6561828.html
5、国际化领域
国际化环境下系统架构演化:
https://www.cnblogs.com/wintersun/p/8097592.html
阿里巴巴全球化技术架构:
https://myslide.cn/slides/21015
来膜拜下 Google 的全球化网站架构:
https://www.sohu.com/a/251204208_464000
全球级的分布式数据库 Google Spanner原理:
https://www.cnblogs.com/jpfss/p/10818890.html
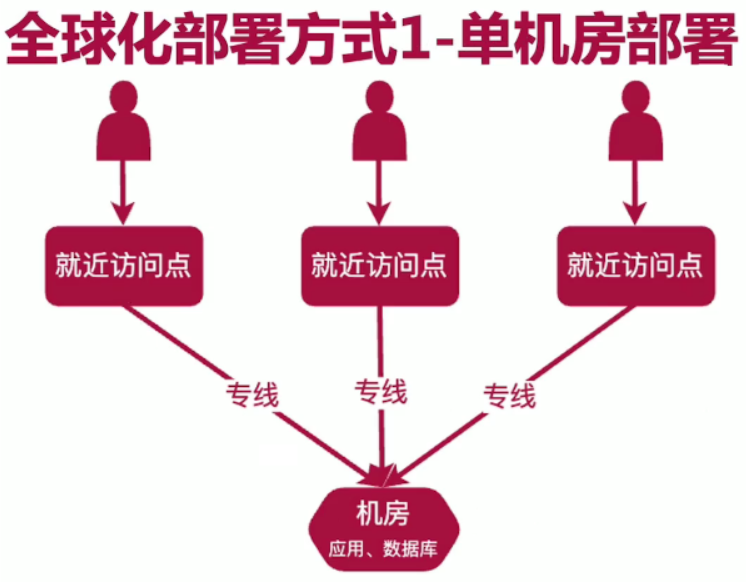
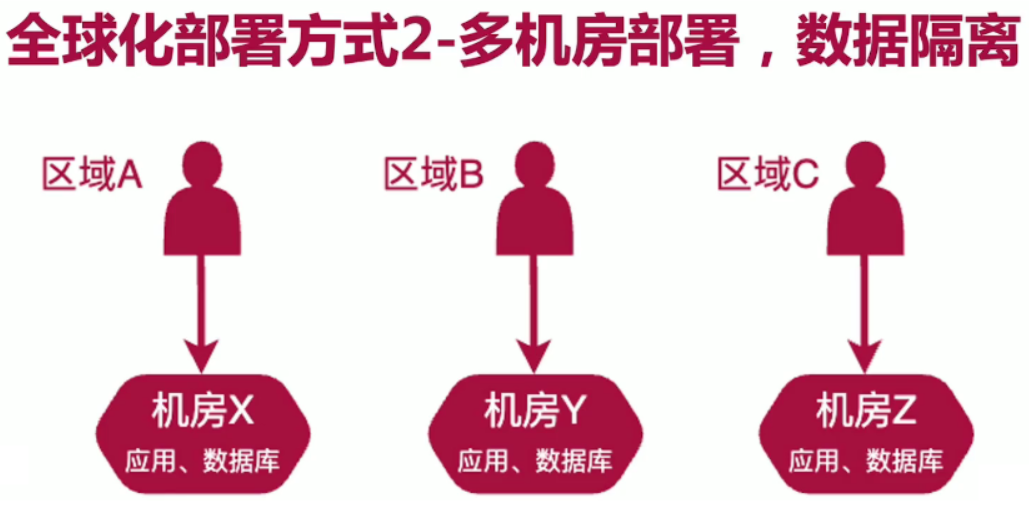
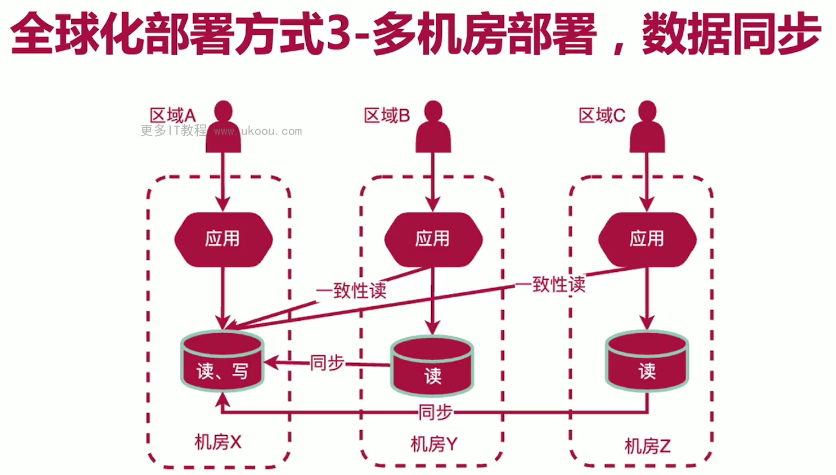
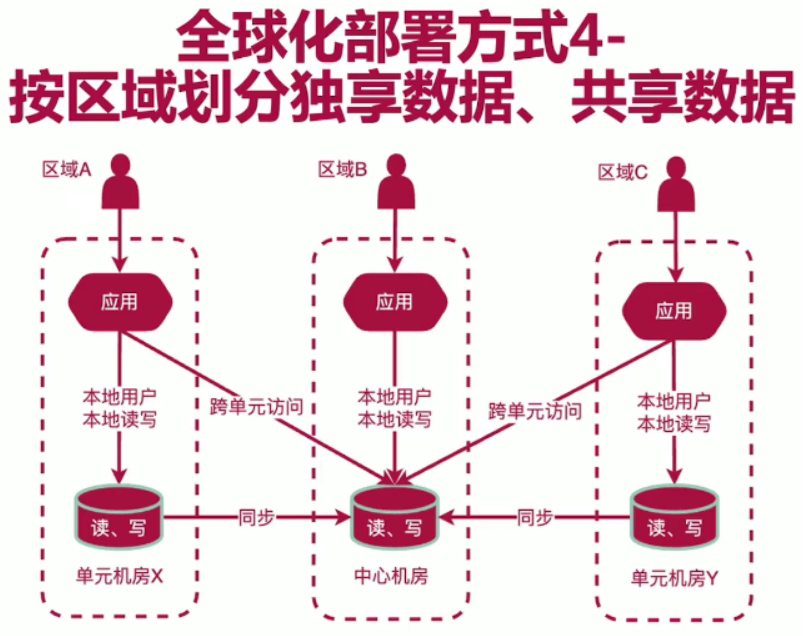
i18n的处理:
Springboot使用不同的配置获取不同的语言。
使用数据库配置。
前端页面配置。
附一:拓展自己的技术视野
开源中国软件更新栏目:https://www.oschina.net/news/project
技术雷达:https://www.thoughtworks.com/zh-cn/radar/techniques
ITeye:https://www.iteye.com/
spring4all:https://spring4all.com/
DockOne:https://dockone.io/
Jdon(解道):https://www.jdon.com/
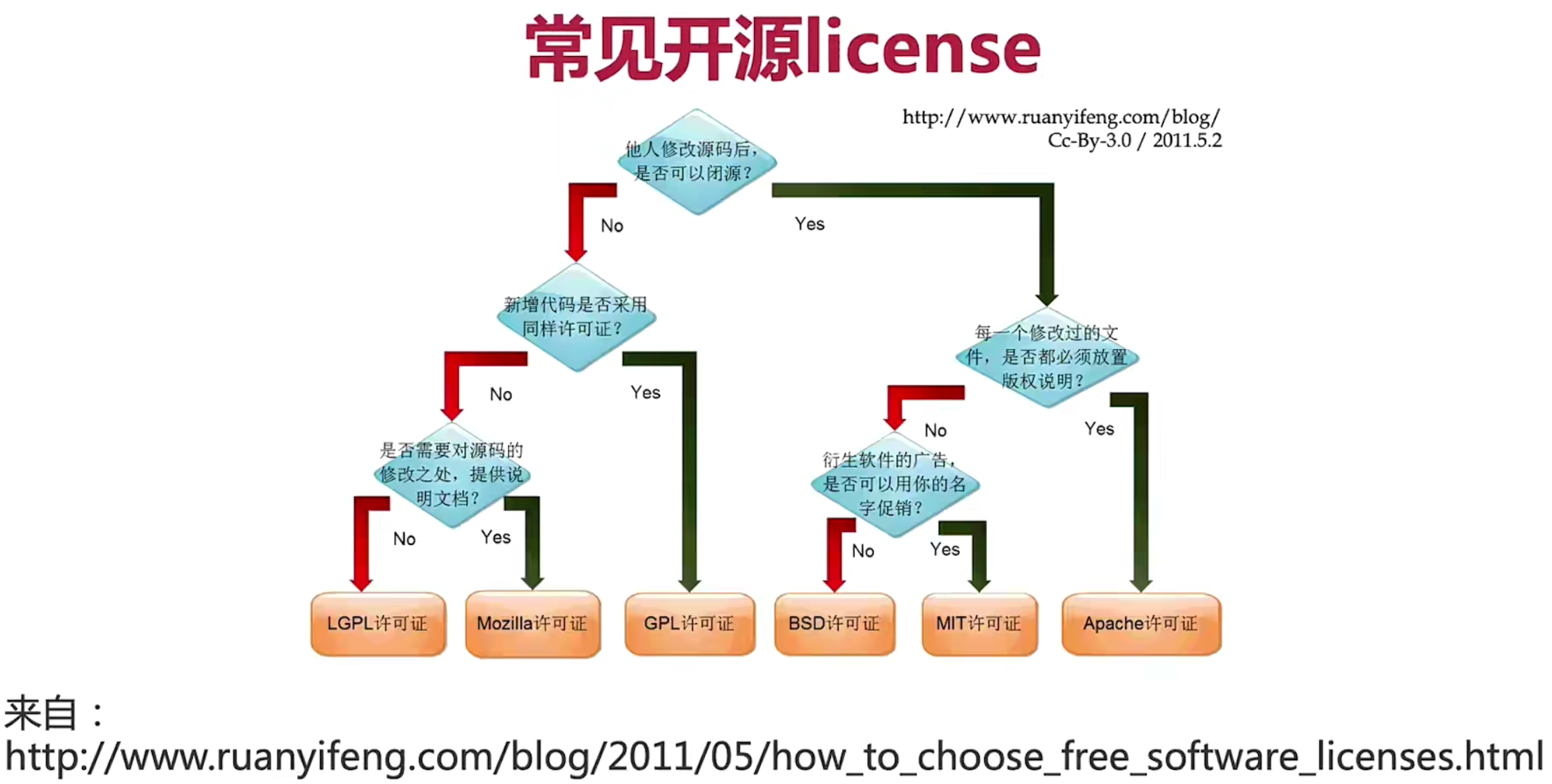
附二:常见开源License
附三:开发语言与数据库排行榜
TIOBE开发语言排行
https://www.tiobe.com/tiobe-index/
DB engines数据库排行
https://db-engines.com/en/ranking


















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











